ICLR 2015 对抗样本解释利用Adversial Examples ReadingNotes
注:本文为个人阅读论文精读,学术译文及其注解,或有瑕疵
笔记整理作者@永生之月
以下提供原文链接 https://arxiv.org/abs/1412.6572

文章目录
- 解释和利用对抗样本 (EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES)
-
- 摘要 (ABSTRACT)
- 1 引言 (INTRODUCTION)
- 2 相关工作 (RELATED WORK)
- 3 对抗样本的线性解释 (THE LINEAR EXPLANATION OF ADVERSARIAL EXAMPLES)
- 4 非线性模型的线性扰动 (LINEAR PERTURBATION OF NON-LINEAR MODELS)
- 5 线性模型的对抗训练与权重衰减(ADVERSARIAL TRAINING OF LINEAR MODELS VERSUS WEIGHT DECAY)
- 6 深度网络的对抗训练 (ADVERSARIAL TRAINING OF DEEP NETWORKS)
- 7 不同类型的模型容量 (DIFFERENT KINDS OF MODEL CAPACITY)
- 8 为什么对抗样本会泛化? (WHY DO ADVERSARIAL EXAMPLES GENERALIZE?)
- 9 替代假设 (ALTERNATIVE HYPOTHESES)
- 10 总结与讨论 (SUMMARY AND DISCUSSION)
- 致谢 (ACKNOWLEDGMENTS)
- 参考文献 (REFERENCES)
- 附录A 垃圾类样本 (A RUBBISH CLASS EXAMPLES)
解释和利用对抗样本 (EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES)
摘要 (ABSTRACT)
多个机器学习模型,包括神经网络,持续错误分类对抗样本——通过对数据集中的样本施加微小但有意的最坏情况扰动形成的输入,使得扰动后的输入导致模型以高置信度输出错误答案。早期解释这一现象的尝试聚焦于非线性和过拟合。我们相反地论证,神经网络对对抗扰动脆弱性的主要原因是它们的线性特性。这一解释得到了新的定量结果的支持,同时首次解释了关于对抗样本最引人入胜的事实:它们在不同架构和训练集之间的泛化能力。此外,这一观点产生了一种简单快速的对抗样本生成方法。使用这种方法为对抗训练提供样本,我们降低了最大输出网络(maxout network)在MNIST数据集上的测试集误差。
本文对对抗样本(adversarial examples) 现象提出了新的解释和利用方法:
- 核心观点:对抗样本的存在不是因为模型"过于非线性",而是因为模型"过于线性"——高维空间中的线性行为是导致对抗样本的根本原因
- 理论贡献:首次从线性角度解释对抗样本的跨模型泛化现象,揭示了不同架构模型学习相似函数时的一致性
- 方法贡献:提出快速梯度符号方法(Fast Gradient Sign Method, FGSM) ,能够快速高效地生成对抗样本
- 实践贡献:证明对抗训练(adversarial training) 可作为有效的正则化手段,甚至比dropout提供更强的正则化效果
- 实验验证:在MNIST数据集上使用maxout网络取得当时最佳结果,测试误差降至0.782%
- 核心洞察:对抗样本揭示了当前机器学习模型的根本局限——它们并未真正"理解"任务,而是建立了一个在自然数据上有效但在分布外数据上脆弱的"波将金村庄",这为设计更鲁棒的模型和训练方法指明了方向
1 引言 (INTRODUCTION)
Szegedy等人(2014b) 做出了一个引人入胜的发现:几种机器学习模型,包括最先进的神经网络,容易受到对抗样本的攻击。也就是说,这些机器学习模型会错误分类那些与从数据分布中正确分类的样本只有微小差异的样本。在许多情况下,具有不同架构、在训练数据的不同子集上训练的各种模型都会错误分类同一个对抗样本。这表明对抗样本暴露了我们训练算法中的基本盲点。
这些对抗样本的成因是一个谜,推测性解释认为这是由于深度神经网络的极端非线性造成的,可能结合了不充分的模型平均和纯监督学习问题的不充分正则化。我们表明这些推测性假设是不必要的。高维空间中的线性行为足以导致对抗样本。这一观点使我们能够设计一种快速生成对抗样本的方法,使对抗训练变得实用。我们展示了对抗训练可以提供除了单独使用dropout (Srivastava等人,2014)之外的额外正则化益处。通用正则化策略如dropout、预训练和模型平均并不能显著降低模型对对抗样本的脆弱性,但改用非线性模型族如RBF网络可以做到这一点。
我们的解释表明,在设计由于线性而易于训练的模型与设计使用非线性效应来抵抗对抗扰动的模型之间存在根本性张力。从长远来看,可能通过设计更强大的优化方法来逃脱这种权衡,这些方法能够成功训练更多的非线性模型。
引言部分总结了对抗样本研究的背景和本文的主要贡献:
- 问题发现:Szegedy等人(2014b) 发现机器学习模型(包括最先进的神经网络)容易受到对抗样本攻击——微小扰动导致高置信度的错误分类
- 现象特点:对抗样本具有跨模型泛化特性,不同架构、不同训练集的模型会对同一对抗样本产生相同的错误分类,暴露了训练算法的基本盲点
- 传统解释:以往研究认为对抗样本源于深度神经网络的极端非线性、模型平均不足和纯监督学习的正则化不足
- 本文观点:高维空间中的线性行为足以导致对抗样本,无需依赖复杂的非线性假设
- 方法贡献:提出快速对抗样本生成方法,使对抗训练变得实用,并展示其比单独使用dropout更强的正则化效果
- 技术对比:通用正则化策略(dropout、预训练、模型平均)无法显著降低对抗脆弱性,但非线性模型族如RBF网络可以抵抗对抗攻击
- 根本张力:揭示了易于训练的线性模型与抵抗对抗扰动的非线性模型之间的根本矛盾
- 未来展望:指出需要开发更强大的优化方法来训练更多非线性模型,以解决这一根本张力
"高维空间中的线性行为"是本文的核心概念。
简而言之,就是一个"积少成多"的效应:单个维度的微小线性响应在高维空间中累积成显著的整体效应。(下文会讲到)
“模型平均”即集成学习。
2 相关工作 (RELATED WORK)
Szegedy等人(2014b) 展示了神经网络和相关模型的各种引人入胜的特性。与本文最相关的包括:
- 盒约束L-BFGS可以可靠地找到对抗样本。
- 在一些数据集上,如ImageNet (Deng等人,2009),对抗样本与原始样本如此接近,以至于差异对人眼来说是不可区分的。
- 同一个对抗样本经常被具有不同架构或在训练数据的不同子集上训练的各种分类器错误分类。
- 浅层softmax回归模型也容易受到对抗样本的攻击。
- 在对抗样本上训练可以正则化模型——然而,这在当时并不实用,因为需要在内循环中进行昂贵的约束优化。
这些结果表明,基于现代机器学习技术的分类器,即使在测试集上获得优异性能,也没有学习到决定正确输出标签的真正潜在概念。相反,这些算法构建了一个波将金村庄(Potemkin village),在自然发生的数据上工作良好,但当访问数据分布中不具有高概率的空间点时,就暴露为假象。这特别令人失望,因为计算机视觉中的一种流行方法是使用卷积网络特征作为欧几里得距离近似感知距离的空间。如果在网络表示中,具有不可测量的小感知距离的图像对应于完全不同的类别,这种相似性显然是有缺陷的。
这些结果经常被解释为深度网络特有的缺陷,尽管线性分类器也有同样的问题。我们将对这一缺陷的了解视为修复它的机会。实际上,Gu & Rigazio (2014) 和 Chalupka等人(2014) 已经开始了设计抵抗对抗扰动的模型的第一步,尽管还没有模型能够在保持清洁输入上的最先进准确性的同时成功做到这一点。
相关工作部分总结了对抗样本研究的前期发现和发展现状:
Szegedy等人(2014b)的核心发现:
- 盒约束L-BFGS可以可靠地找到对抗样本
- 在ImageNet等数据集上,对抗样本与原样本极其相似,人眼无法区分
- 跨模型泛化:同一对抗样本可以愚弄不同架构或不同训练数据的多个分类器
- 浅层softmax回归模型也容易受到对抗样本攻击
- 对抗训练可以正则化模型,但当时因需要昂贵的约束优化而不实用
重要问题揭示:
- 现代机器学习分类器并未学到决定正确输出标签的真正潜在概念
- 模型构建了"波将金村庄(Potemkin village) "——在自然数据上表现良好,但在分布外数据上暴露缺陷
- 计算机视觉中使用卷积网络特征作为感知距离空间的方法存在根本缺陷
传统误解:
- 这些问题经常被误解为深度网络特有的缺陷
- 实际上线性分类器也有同样问题
研究机遇与进展:
- 将缺陷认知转化为修复机会
- Gu & Rigazio (2014) 和Chalupka等人(2014) 已开始设计抵抗对抗扰动的模型
- 但尚未有模型能在保持最先进准确性的同时成功抵抗对抗攻击
研究意义:为理解和解决对抗样本问题奠定了基础,指明了后续研究方向
3 对抗样本的线性解释 (THE LINEAR EXPLANATION OF ADVERSARIAL EXAMPLES)
我们从解释线性模型中对抗样本的存在开始。
在许多问题中,单个输入特征的精度是有限的。例如,数字图像通常每像素只使用8位,因此它们丢弃了动态范围的1/255以下的所有信息。由于特征的精度有限,如果扰动η的每个元素都小于特征的精度,分类器对输入x和对抗输入 x ~ = x + η x̃ = x + η x~=x+η响应不同是不合理的。形式上,对于具有良好分离类别的问题,我们期望分类器将同一类别分配给x和x̃,只要 ∥ η ∥ ∞ \|\eta\|_\infty ∥η∥∞ < ε ε ε,其中ε足够小,可以被与我们问题相关的传感器或数据存储设备丢弃。
考虑权重向量 w w w和对抗样本x̃之间的点积:
w T x ~ = w T x + w T η w^T\tilde{x} = w^Tx + w^T\eta wTx~=wTx+wTη
对抗扰动使激活增长 w T η w^Tη wTη。我们可以通过将 η = s i g n ( w ) η = sign(w) η=sign(w)来最大化这种在η上的最大范数约束下的增长。如果 w w w有 n n n个维度,权重向量的一个元素的平均幅度为 m m m,那么激活将增长 m n mn mn。由于 ∣ ∣ η ∣ ∣ ∞ ||\eta||_\infty ∣∣η∣∣∞不随问题的维数增长,但由η扰动引起的激活变化可以与n线性增长,因此对于高维问题,我们可以对输入进行许多无穷小的改变,这些改变累积成对输出的一个大改变。我们可以将此视为一种"意外隐写术",其中线性模型被迫专门关注与其权重最紧密对齐的信号,即使存在多个信号并且其他信号具有更大的幅度。
这一解释表明,如果简单线性模型的输入具有足够的维数,它就可能有对抗样本。先前对对抗样本的解释调用了神经网络的假设特性,如它们所谓的高度非线性特性。我们基于线性的假设更简单,也可以解释为什么softmax回归容易受到对抗样本的攻击。
关键洞察: ∣ ∣ η ∣ ∣ ∞ ||\eta||_\infty ∣∣η∣∣∞不随问题维数增长,但η扰动引起的激活变化可以与n线性增长,因此对于高维问题可以进行许多无穷小改变累积成对输出的一个大改变。
∥ η ∥ ∞ \|\eta\|_\infty ∥η∥∞ 是无穷范数(infinity norm)或最大范数(max norm)的表示。
具体含义:
- 对于向量 η = [η₁, η₂, …, ηₙ]
- ∥ η ∥ ∞ = max { ∣ η 1 ∣ , ∣ η 2 ∣ , … , ∣ η n ∣ } \|\eta\|_\infty = \max\{|\eta_1|, |\eta_2|, \ldots, |\eta_n|\} ∥η∥∞=max{∣η1∣,∣η2∣,…,∣ηn∣}
- 即向量中绝对值最大的元素的绝对值
在对抗样本的语境中:
- 用来约束扰动的大小,确保每个维度上的扰动都不超过某个阈值ε
- ∣ ∣ η ∣ ∣ ∞ < ε ||\eta||_{\infty} < \varepsilon ∣∣η∣∣∞<ε 意味着扰动向量η的每个分量的绝对值都小于ε
- 这样可以保证对抗样本与原始样本在每个特征维度上的差异都很小
- 从而确保对抗样本在感知上与原始样本几乎无法区分
这种约束方式比其他范数(如L2范数)更直观,因为它直接限制了每个像素或特征的最大变化量。
4 非线性模型的线性扰动 (LINEAR PERTURBATION OF NON-LINEAR MODELS)
对抗样本的线性观点建议了一种快速生成它们的方法。我们假设神经网络过于线性,无法抵抗线性对抗扰动。LSTM (Hochreiter & Schmidhuber, 1997)、ReLU (Jarrett等人,2009;Glorot等人,2011)和maxout网络(Goodfellow等人,2013c)都有意设计为表现得非常线性,以便更容易优化。更多非线性模型如sigmoid网络被仔细调整,以在大部分时间内花费在非饱和、更线性的区域,出于同样的原因。这种线性行为表明,线性模型的廉价分析扰动也应该损害神经网络。
设θ为模型的参数, x x x为模型的输入, y y y为与 x x x相关的目标(对于有目标的机器学习任务), J ( θ , x , y ) J(θ,x,y) J(θ,x,y)为用于训练神经网络的成本。我们可以在θ的当前值周围线性化成本函数,得到最优最大范数约束扰动:
η = sign ( ∇ x J ( θ , x , y ) ) \eta = \text{sign} (\nabla_x J(\theta, x, y)) η=sign(∇xJ(θ,x,y))
我们将此称为生成对抗样本的"快速梯度符号方法"。注意所需的梯度可以使用反向传播高效计算。
我们发现这种方法可靠地使各种模型错误分类它们的输入。参见图1在ImageNet上的演示。我们发现使用 ε = .25 ε = .25 ε=.25,我们使浅层softmax分类器在MNIST测试集¹上具有99.9%的错误率,平均置信度为79.3%。在相同设置下,maxout网络以97.6%的平均置信度错误分类89.4%的对抗样本。类似地,使用ε = .1,当在CIFAR-10(Krizhevsky & Hinton, 2009)测试集²的预处理版本上使用卷积maxout网络时,我们获得87.15%的错误率和96.6%的分配给错误标签的平均概率。生成对抗样本的其他简单方法也是可能的。例如,我们也发现将x在梯度方向上旋转一个小角度可靠地产生对抗样本。
这些简单、廉价的算法能够生成错误分类样本的事实,作为支持我们将对抗样本解释为线性结果的证据。这些算法也作为加速对抗训练甚至仅仅分析训练网络的有用方法。
提出核心假设:神经网络过于线性,无法抗击线性对抗扰动,这为快速生成对抗样本提供了理论基础
解释神经网络的线性特性:LSTM、ReLU、maxout网络都被有意设计为非常线性的行为方式,以便更容易优化;即使是sigmoid网络也被调整在非饱和、更线性的区域运行
提出快速梯度符号方法(fast gradient sign method):通过线性化成本函数得到最优的最大范数约束扰动公式: η = ε sign ( ∇ x J ( θ , x , y ) ) \eta = \varepsilon \text{sign}(\nabla_x J(\theta, x, y)) η=εsign(∇xJ(θ,x,y))
所需梯度可以使用反向传播高效计算,这使得该方法在计算上非常实用
实验验证该方法的有效性:
- 在MNIST上:浅层softmax分类器错误率达到99.9% ,maxout网络错误分类89.4% 的对抗样本
- 在CIFAR-10上:卷积maxout网络获得87.15% 的错误率
- 在ImageNet上成功演示(如图1所示的熊猫被误分类为长臂猿)
提及其他简单的对抗样本生成方法:将输入 x x x沿梯度方向旋转小角度也能可靠产生对抗样本
这些简单、廉价算法能够生成错误分类样本的事实支持了对抗样本源于线性特性而非非线性的解释
该方法的实用价值:可用于加速对抗训练或训练网络的分析

图1: 应用于GoogLeNet (Szegedy等人,2014a)在ImageNet上的快速对抗样本生成演示。通过添加一个感知上不可察觉的小向量,其元素等于成本函数相对于输入的梯度元素的符号,我们可以改变GoogLeNet对图像的分类。这里我们的ε为.007,对应于GoogLeNet转换为实数后8位图像编码的最小位的幅度。
5 线性模型的对抗训练与权重衰减(ADVERSARIAL TRAINING OF LINEAR MODELS VERSUS WEIGHT DECAY)
我们可以考虑的最简单的模型可能是逻辑回归。在这种情况下,快速梯度符号方法是精确的。我们可以使用这种情况来获得对抗样本如何在简单设置中生成的一些直觉。参见图2获得指导性图像。
如果我们训练单个模型来识别标签 y ∈ { − 1 , 1 } y \in \{-1, 1\} y∈{−1,1},其中 P ( y = 1 ) = σ ( w T x + b ) P(y = 1) = \sigma(w^Tx + b) P(y=1)=σ(wTx+b),其中 σ ( z ) \sigma(z) σ(z)是逻辑sigmoid函数,那么训练包括在以下函数上的梯度下降:
E x , y ∼ p d a t a ζ ( − y ( w T x + b ) ) E_{x,y \sim p_{data}} \zeta(-y(w^Tx + b)) Ex,y∼pdataζ(−y(wTx+b))
其中 ζ ( z ) = log ( 1 + exp ( z ) ) \zeta(z) = \log(1 + \exp(z)) ζ(z)=log(1+exp(z)) 是softplus函数。我们可以基于梯度符号推导在x的最坏情况对抗扰动而不是x本身上训练的简单解析形式。注意梯度的符号就是 − sign ( w ) -\text{sign}(w) −sign(w),且 w T sign ( w ) = ∣ ∣ w ∣ ∣ 1 w^T\text{sign}(w) = ||w||_1 wTsign(w)=∣∣w∣∣1。因此,逻辑回归的对抗版本是最小化:
E x , y ∼ p d a t a ζ ( y ( ε ∣ ∣ w ∣ ∣ 1 − w T x − b ) ) E_{x,y \sim p_{data}} \zeta(y(\varepsilon||w||_1 - w^Tx - b)) Ex,y∼pdataζ(y(ε∣∣w∣∣1−wTx−b))
这在某种程度上类似于 L 1 L^1 L1 正则化。然而,有一些重要差异。最重要的是, L 1 L^1 L1 惩罚在训练期间从模型的激活中减去,而不是添加到训练成本中。这意味着如果模型学会做出足够自信的预测使得 ζ \zeta ζ 饱和,惩罚最终可以开始消失。这不能保证发生——在欠拟合情况下,对抗训练会简单地恶化欠拟合。因此我们可以将 L 1 L^1 L1 权重衰减视为比对抗训练更"最坏情况",因为它在良好边际的情况下无法去激活。
如果我们从逻辑回归转向多类softmax回归, L 1 L^1 L1 权重衰减变得更加悲观,因为它将softmax的每个输出视为独立可扰动的,而实际上通常不可能找到与所有类别权重向量对齐的单个 η \eta η。在深度网络有多个隐藏单元的情况下,权重衰减更进一步高估了扰动可能造成的损害。因为 L 1 L^1 L1 权重衰减高估了对手可以造成的损害量,有必要使用比与我们特征精度相关的 ε \varepsilon ε 更小的 L 1 L^1 L1 权重衰减系数。在MNIST上训练maxout网络时,我们使用 ε = 0.25 \varepsilon = 0.25 ε=0.25 的对抗训练获得了良好结果。当对第一层应用 L 1 L^1 L1 权重衰减时,我们发现即使0.0025的系数也太大,导致模型在训练集上卡在超过5%的错误率。较小的权重衰减系数允许成功训练但没有提供正则化益处。
1. 逻辑回归中的对抗训练
- 在逻辑回归中,快速梯度符号方法是精确的
- 对抗训练的目标函数变为:
E x , y ∼ p data ζ ( y ( ∥ w ∥ 1 − w T x − b ) ) \mathbb{E}_{x,y \sim p_{\text{data}}} \zeta(y(\|w\|_1 - w^T x - b)) Ex,y∼pdataζ(y(∥w∥1−wTx−b))
- 这与L¹正则化在某种程度上相似
2. 对抗训练与L¹权重衰减的关键差异
- L¹惩罚在训练期间从模型激活中减去,而不是加到训练成本中
- 如果模型学会做出足够自信的预测使得损失函数饱和,L¹惩罚可能会消失
- L¹权重衰减比对抗训练更"最坏情况",因为它在良好边距情况下未能停用
3. 多类情况下的问题
- 在多类softmax回归中,L¹权重衰减变得更加悲观
- 它将每个输出视为独立可扰动的,但实际上很难找到与所有类权重向量对齐的单个扰动
- 在深度网络中,权重衰减甚至更高估了扰动可能造成的损害
4. 实验结果
- 使用 ϵ = 0.25 \epsilon = 0.25 ϵ=0.25 的对抗训练在MNIST上获得良好结果
- L¹权重衰减需要比特征精度相关的 ϵ \epsilon ϵ 更小的系数
- 即使0.0025的L¹系数也太大,导致训练集错误率超过5%
- 更小的权重衰减系数虽然允许成功训练,但没有正则化益处
核心洞察:
这一节揭示了对抗训练相比传统正则化方法的优势:它能够自适应地在模型需要时提供正则化,而不是像L¹权重衰减那样过度悲观地估计威胁。
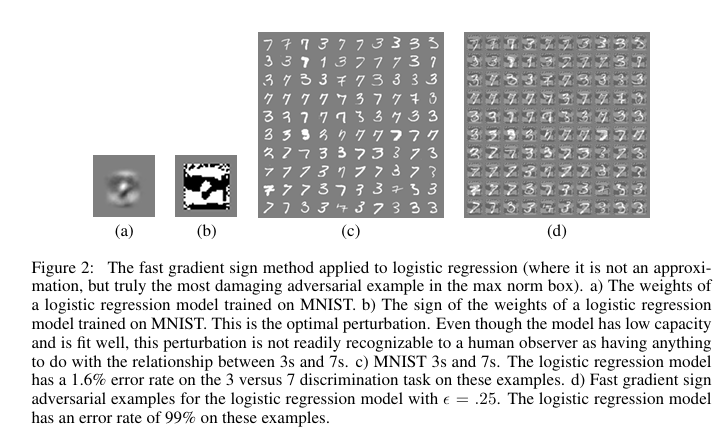
图2: 应用于逻辑回归的快速梯度符号方法(在这里它不是近似,而是真正的最大范数盒中最具破坏性的对抗样本)。a) 在MNIST上训练的逻辑回归模型的权重。b) 在MNIST上训练的逻辑回归模型权重的符号。这是最优扰动。尽管模型具有低容量且拟合良好,但人类观察者不能轻易识别这种扰动与3和7之间关系有任何关联。c) MNIST的3和7。逻辑回归模型在这些样本的3对7判别任务上有1.6%的错误率。d) 逻辑回归模型ε = .25的快速梯度符号对抗样本。逻辑回归模型在这些样本上有99%的错误率。
6 深度网络的对抗训练 (ADVERSARIAL TRAINING OF DEEP NETWORKS)
将深度网络批评为容易受对抗样本攻击在某种程度上是误导的,因为与浅层线性模型不同,深度网络至少能够表示抵抗对抗扰动的函数。通用逼近定理(Hornik等人,1989)保证具有至少一个隐藏层的神经网络可以以任意精度表示任何函数,只要其隐藏层被允许有足够的单元。浅层线性模型无法在训练点附近保持常数,同时为不同的训练点分配不同的输出。
当然,通用逼近定理并没有说训练算法是否能够发现具有所有期望特性的函数。显然,标准监督训练没有指定所选函数应该抵抗对抗样本。这必须以某种方式编码在训练过程中。
Szegedy等人(2014b) 表明,通过在对抗样本和清洁样本的混合上训练,神经网络可以在某种程度上被正则化。在对抗样本上训练与其他数据增强方案有所不同;通常,人们用预期在测试集中实际出现的变换(如平移)来增强数据。这种形式的数据增强相反使用不太可能自然发生但暴露模型概念化其决策函数方式缺陷的输入。当时,这一过程从未被证明在最先进的基准上超越dropout。然而,这部分是因为基于L-BFGS的昂贵对抗样本使得广泛实验变得困难。
我们发现基于快速梯度符号方法的对抗目标函数训练是一个有效的正则化器:
J ~ ( θ , x , y ) = α J ( θ , x , y ) + ( 1 − α ) J ( θ , x + ε sign ( ∇ x J ( θ , x , y ) ) ) \tilde{J}(\theta, x, y) = \alpha J(\theta, x, y) + (1 - \alpha)J(\theta, x + \varepsilon \text{sign} (\nabla_x J(\theta, x, y))) J~(θ,x,y)=αJ(θ,x,y)+(1−α)J(θ,x+εsign(∇xJ(θ,x,y)))
在我们所有的实验中,我们使用 α = 0.5 \alpha = 0.5 α=0.5。其他值可能工作得更好;我们对这个超参数的初始猜测工作得足够好,我们没有觉得需要进一步探索。这种方法意味着我们持续更新我们的对抗样本供应,使它们抵抗模型的当前版本。使用这种方法训练也用dropout正则化的maxout网络,我们能够将错误率从没有对抗训练的0.94%降低到有对抗训练的0.84%。
我们观察到我们没有在训练集上的对抗样本上达到零错误率。我们通过做两个改变解决了这个问题。首先,我们使模型更大,每层使用1600个单元而不是原始maxout网络为这个问题使用的240个。没有对抗训练,这导致模型轻微过拟合,在测试集上获得1.14%的错误率。有了对抗训练,我们发现验证集错误随时间趋于平稳,进展非常缓慢。原始maxout结果使用早停,在验证集错误率100个epoch没有下降后终止学习。我们发现虽然验证集错误非常平坦,但对抗验证集错误不是。因此我们使用对抗验证集错误的早停。使用这个标准来选择训练的epoch数,我们然后在所有60,000个样本上重新训练。使用不同种子进行随机数生成器以选择训练样本的小批量、初始化模型权重和生成dropout掩码的五次不同训练运行导致四次试验各自在测试集上有0.77%的错误率,一次试验有0.83%的错误率。平均0.782%是在MNIST的排列不变版本上报告的最佳结果,尽管在统计上与通过用dropout微调DBM获得的结果(Srivastava等人,2014)的0.79%无法区分。
模型也变得在某种程度上抵抗对抗样本。回想没有对抗训练,这种类型的模型在基于快速梯度符号方法的对抗样本上有89.4%的错误率。有了对抗训练,错误率降至17.9%。对抗样本在两个模型之间是可转移的,但对抗训练的模型显示出更大的鲁棒性。通过原始模型生成的对抗样本在对抗训练模型上产生19.6%的错误率,而通过新模型生成的对抗样本在原始模型上产生40.9%的错误率。当对抗训练模型确实错误分类对抗样本时,其预测不幸仍然高度自信。错误分类样本的平均置信度为81.4%。我们还发现学习模型的权重发生了显著变化,对抗训练模型的权重显著更加局部化和可解释(见图3)。
对抗训练过程可以被视为当数据被对手扰动时最小化最坏情况错误。这可以解释为学会玩对抗游戏,或作为最小化在噪声样本上期望成本的上界,噪声来自添加到输入的 U ( − ε , ε ) U(-\varepsilon, \varepsilon) U(−ε,ε)。对抗训练也可以被视为主动学习的一种形式,其中模型能够请求新点上的标签。在这种情况下,人类标注者被启发式标注者替代,该标注者从附近点复制标签。
我们也可以通过在 ε \varepsilon ε 最大范数盒内的所有点上训练,或在这个盒内采样许多点,来正则化模型对小于 ε \varepsilon ε 精度的特征变化不敏感。这对应于在训练期间添加最大范数 ε \varepsilon ε 的噪声。然而,零均值和零协方差的噪声在防止对抗样本方面非常低效。任何参考向量与这种噪声向量之间的期望点积为零。这意味着在许多情况下噪声基本上没有效果,而不是产生更困难的输入。实际上,在许多情况下噪声实际上会导致更低的目标函数值。我们可以将对抗训练视为在噪声输入集合中进行困难样本挖掘,以便通过仅考虑那些强烈抵抗分类的噪声点来更高效地训练。作为对照实验,我们训练了基于随机向每个像素添加 ± ε \pm\varepsilon ±ε 或向每个像素添加 U ( − ε , ε ) U(-\varepsilon, \varepsilon) U(−ε,ε) 中的噪声的maxout网络。这些在快速梯度符号对抗样本上分别获得86.2%的错误率(置信度97.3%)和90.4%的错误率(置信度97.8%)。
因为符号函数的导数在任何地方都是零或未定义,基于快速梯度符号方法的对抗目标函数上的梯度下降不允许模型预期对手将如何对参数变化做出反应。如果我们相反基于小旋转或添加缩放梯度的对抗样本,那么扰动过程本身是可微的,学习可以考虑对手的反应。然而,我们从这个过程中没有发现几乎同样强大的正则化结果,也许是因为这些类型的对抗样本不那么难以解决。
一个自然的问题是扰动输入还是隐藏层还是两者都扰动更好。这里的结果是不一致的。Szegedy等人(2014b) 报告说,当应用于隐藏层时,对抗扰动产生最佳正则化。这个结果是在sigmoid网络上获得的。在我们使用快速梯度符号方法的实验中,我们发现具有激活无界的隐藏单元的网络简单地通过使其隐藏单元激活非常大来响应,因此通常最好只扰动原始输入。在饱和模型如Rust模型上,我们发现输入的扰动与隐藏层的扰动性能相当。基于旋转隐藏层的扰动通过使加性扰动通过比较变得更小来解决无界激活增长的问题。我们能够成功训练具有隐藏层旋转扰动的maxout网络。然而,这没有产生几乎如输入层加性扰动那样强的正则化效果。我们对对抗训练的观点是,只有当模型有能力学会抵抗对抗样本时,它才明显有用。这只有在通用逼近定理适用时才明显如此。因为神经网络的最后一层,线性-sigmoid或线性-softmax层,不是最终隐藏层函数的通用逼近器,这表明当对最终隐藏层应用对抗扰动时,人们可能遇到欠拟合问题。我们确实发现了这种效应。我们使用隐藏层扰动训练的最佳结果从未涉及最终隐藏层的扰动。
主要观点:深度网络相比浅层线性模型具有更强的表示能力,理论上能够学习抵抗对抗扰动的函数。**通用逼近定理**保证了具有足够隐藏单元的神经网络可以表示任何函数,但标准监督训练并不会自动学习到抗对抗的函数,需要在训练过程中明确编码。
**通用逼近定理**简单来说就是:神经网络理论上可以学会任何函数。
数学表述:对于任何连续函数 f: K → R(其中 K ⊆ R^n 是紧致集),存在一个具有足够多神经元的单隐藏层网络,可以在任意小的误差 ε > 0 内逼近该函数
关键条件:激活函数必须是非多项式的(如 sigmoid、ReLU 等),这样网络才能充当"通用逼近器"
核心方法:提出了基于快速梯度符号方法的对抗目标函数:
J ~ ( θ , x , y ) = α J ( θ , x , y ) + ( 1 − α ) J ( θ , x + ϵ sign ( ∇ x J ( θ , x , y ) ) ) \tilde{J}(\theta, x, y) = \alpha J(\theta, x, y) + (1-\alpha) J(\theta, x + \epsilon \text{sign}(\nabla_x J(\theta, x, y))) J~(θ,x,y)=αJ(θ,x,y)+(1−α)J(θ,x+ϵsign(∇xJ(θ,x,y)))
其中使用 α = 0.5,持续更新对抗样本来抵抗当前版本的模型。
实验结果:在MNIST上,将maxout网络的错误率从0.94%降至0.84%。通过增大模型容量(1600个单元/层)和使用对抗验证集早停,最终达到0.782%的测试错误率。对抗样本错误率从89.4%降至17.9%,显著提高了模型的鲁棒性。
关键发现:
- 权重可视化改善 - 对抗训练后的模型权重更加局部化和可解释
- 扰动位置的影响 - 对于无界激活的网络,扰动输入层效果更好;对于饱和模型,输入扰动与隐藏层扰动效果相当;避免扰动最终隐藏层以防止欠拟合
- 与噪声训练的对比 - 对抗训练比随机噪声训练更有效,可视为"硬样本挖掘"
理论意义:对抗训练可解释为最小化最坏情况错误、学习对抗游戏或主动学习的形式,强调了模型容量与抗对抗能力之间的权衡关系,为后续对抗防御研究奠定了基础。
对抗训练具体流程:
第1步:生成对抗样本
- 拿一个正常的输入(比如一张猫的图片)
- 计算模型当前的预测梯度
- 按照梯度方向添加微小的噪声,生成"对抗样本"
- 这个对抗样本看起来几乎和原图一样,但会让模型犯错
第2步:混合训练
使用这个目标函数进行训练:损失 = α × 正常样本损失 + (1-α) × 对抗样本损失
- 一半时间用正常图片训练(学习正确识别)
- 一半时间用对抗样本训练(学习抵抗攻击)
第3步:循环优化
- 每轮训练都重新生成对抗样本(针对当前模型状态)
- 持续更新模型参数
- 模型逐渐变得既能识别正常图片,又能抵抗对抗攻击

图3: 在MNIST上训练的maxout网络的权重可视化。每行显示单个maxout单元的滤波器(filters) 。左图)朴素训练模型。右图)对抗训练模型。
7 不同类型的模型容量 (DIFFERENT KINDS OF MODEL CAPACITY)
对抗样本的存在可能看起来反直觉的一个原因是我们大多数人对高维空间的直觉很差。我们生活在三维中,所以我们不习惯数百个维度中的小效应累积起来产生大效应。还有另一种方式我们的直觉为我们服务不佳。许多人认为低容量的模型无法做出许多不同的自信预测。这是不正确的。一些低容量的模型确实表现出这种行为。例如,具有以下形式的浅层RBF网络:
p ( y = 1 ∣ x ) = exp ( ( x − μ ) T β ( x − μ ) ) p(y = 1 | x) = \exp \left( (x - \mu)^T \beta (x - \mu) \right) p(y=1∣x)=exp((x−μ)Tβ(x−μ))
只能自信地预测正类在 μ \mu μ 附近存在。在其他地方,它们默认预测类不存在,或有低置信度预测。
RBF网络天然免疫对抗样本,从它们在被愚弄时具有低置信度的意义上。没有隐藏层的浅层RBF网络在使用快速梯度符号方法和ε = .25生成的对抗样本上在MNIST上获得55.4%的错误率。然而,其在错误样本上的置信度只有1.2%。其在清洁测试样本上的平均置信度为60.6%。我们不能期望如此低容量的模型在空间的所有点都得到正确答案,但它确实通过在不"理解"的点上显著降低其置信度来正确响应。
RBF单元不幸地对任何重要变换都不是不变的,所以它们不能很好地泛化。我们可以将线性单元和RBF单元视为精确度-召回权衡曲线上的不同点。线性单元通过响应某个方向上的每个输入来实现高召回,但由于在不熟悉的情况下响应过强,可能具有低精确度。RBF单元通过仅响应空间中的特定点来实现高精确度,但这样做牺牲了召回。受这个想法的启发,我们决定探索涉及二次单元的各种模型,包括深度RBF网络。我们发现这是一个困难的任务——每个具有足够二次抑制以抵抗对抗扰动的模型在用SGD训练时都获得了高训练集错误。
核心观点:人们对高维空间的直觉很差,不习惯数百维中的小效应累积成大效应。更重要的是,许多人错误地认为低容量模型无法做出许多不同的置信预测,但这是不正确的。
低容量模型是指模型的表达能力、复杂度或灵活性相对有限的机器学习模型。
模型容量的两种表现:
- 线性单元:通过响应某个方向的每个输入实现高召回率,但可能因在不熟悉情况下响应过强而具有低精确度
- RBF单元:通过只响应空间中特定点实现高精确度,但牺牲了召回率
RBF网络的独特性质:
浅层RBF网络具有天然的对抗样本免疫性:
p ( y = 1 ∣ x ) = exp ( ( x − μ ) T β ( x − μ ) ) p(y = 1 | x) = \exp((x - \mu)^T \beta(x - \mu)) p(y=1∣x)=exp((x−μ)Tβ(x−μ))
- 只能在μ附近置信地预测正类存在
- 在其他地方默认预测类不存在或给出低置信度预测
- 实验显示:在ε=0.25的对抗样本上错误率55.4%,但置信度仅1.2%
- 清洁样本上平均置信度60.6%
RBF网络的局限性:
- 对重要变换不具有不变性,泛化能力差
- 用SGD训练具有足够二次抑制的深度RBF网络很困难,容易出现高训练误差
精确度-召回率权衡:
作者将线性单元和RBF单元视为精确度-召回率权衡曲线上的不同点,启发性地探索了包含二次单元的各种模型,包括深度RBF网络,但发现训练困难。理论意义:这一节为理解不同模型架构的表达能力和局限性提供了重要视角,说明了为什么简单的线性模型容易受到对抗攻击,而某些非线性模型(如RBF网络)天然具有抗对抗性质。
8 为什么对抗样本会泛化? (WHY DO ADVERSARIAL EXAMPLES GENERALIZE?)
对抗样本的一个引人入胜的方面是为一个模型生成的样本经常被其他模型错误分类,即使它们具有不同的架构或在不相交的训练集上训练。此外,当这些不同的模型错误分类对抗样本时,它们经常在其类别上彼此一致。基于极端非线性和过拟合的解释不能轻易解释这种行为——为什么多个具有过量容量的极端非线性模型会以相同方式一致地标记分布外点?从认为对抗样本像实数中的有理数一样精细平铺空间的假设来看,这种行为特别令人惊讶,因为在这种观点中,对抗样本是常见的,但只出现在非常精确的位置。
在线性观点下,对抗样本出现在广阔的子空间中。方向η只需要与成本函数的梯度有正点积,ε只需要足够大。图4展示了这种现象。通过追踪ε的不同值,我们看到对抗样本出现在由快速梯度符号方法定义的1-D子空间的连续区域中,而不是在精细的口袋中。这解释了为什么对抗样本丰富,以及为什么被一个分类器错误分类的样本有相当高的先验概率被另一个分类器错误分类。
为了解释为什么多个分类器将同一类分配给对抗样本,我们假设用当前方法训练的神经网络都类似于在同一训练集上学习的线性分类器。这个参考分类器能够在训练集的不同子集上训练时学习大致相同的分类权重,简单地因为机器学习算法能够泛化。潜在分类权重的稳定性反过来导致对抗样本的稳定性。
为了测试这个假设,我们在深度maxout网络上生成对抗样本,并使用浅层softmax网络和浅层RBF网络对这些样本进行分类。在被maxout网络错误分类的样本上,RBF网络有16.0%的时间预测maxout网络的类分配,而softmax分类器54.6%的时间正确预测maxout网络的类。这些数字在很大程度上受到了不同模型的不同错误率的驱动。如果我们将注意力限制在被比较的两个模型都犯错误的情况,那么softmax回归84.6%的时间预测maxout的类,而RBF网络只能54.3%的时间预测maxout的类。作为比较,RBF网络能够53.6%的时间预测softmax回归的类,所以它确实对自己的行为有强烈的线性成分。我们的假设并不能解释maxout网络的所有错误或所有跨模型泛化的错误,但显然其中相当大的比例与线性行为是跨模型泛化的主要原因是一致的。
潜在分类权重的稳定性指的是不同模型在学习同一分类任务时,会收敛到相似的权重配置,这种相似性是稳定和可预测的。
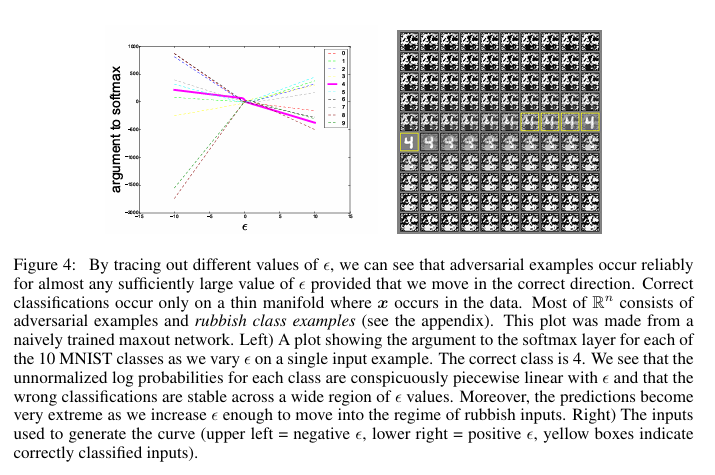
图4: 通过追踪ε的不同值,我们可以看到对抗样本可靠地出现在几乎任何足够大的ε值上,只要我们朝正确方向移动。正确分类只出现在数据中x出现的薄流形(manifold) 上。 R n \mathbb{R}^n Rn的大部分由对抗样本和垃圾类样本组成(见附录)。这个图是从朴素训练的maxout网络制作的。左图)显示了当我们在单个输入样本上变化ε时,10个MNIST类别中每个类别到softmax层的参数 (argument) 图。正确类别是4。我们看到每个类别的非标准化对数概率(log probabilities) 随ε呈明显的分段线性,并且错误分类在ε值的广泛区域内是稳定的。此外,当我们增加ε足够大以进入垃圾输入状态时,预测变得非常极端。右图)用于生成曲线的输入(左上 = 负ε,右下 = 正ε,黄色框表示正确分类的输入)。
9 替代假设 (ALTERNATIVE HYPOTHESES)
我们现在考虑并反驳对抗样本存在的一些替代假设。
首先,一个假设是生成训练可以为训练过程提供更多约束,或使模型学会区分"真实"和"虚假"数据,并仅在"真实"数据上保持自信。MP-DBM (Goodfellow等人,2013a)提供了一个测试这个假设的好模型。其推理过程在MNIST上获得良好的分类准确性(0.88%的错误率)。这个推理过程是可微的。其他生成模型要么具有不可微的推理过程,使得计算对抗样本更加困难,要么需要额外的非生成判别器模型来在MNIST上获得良好的分类准确性。在MP-DBM的情况下,我们可以确信生成模型本身正在响应对抗样本,而不是顶部的非生成分类器模型。我们发现该模型容易受到对抗样本的攻击。使用ε为0.25,我们在从MNIST测试集生成的对抗样本上发现97.5%的错误率。仍然可能某些其他形式的生成训练可以赋予抵抗力,但显然仅仅是生成的事实并不足够。
关于为什么对抗样本存在的另一个假设是个别模型有奇怪的怪癖,但在许多模型上平均可以使对抗样本被消除。为了测试这个假设,我们在MNIST上训练了十二个maxout网络的集成。每个网络使用不同的随机数生成器种子进行训练,用于初始化权重、生成dropout掩码和为随机梯度下降选择数据的小批量。集成在设计用于扰动整个集成的对抗样本上获得91.1%的错误率, ε = .25 ε = .25 ε=.25。如果我们相反使用设计用于仅扰动集成的一个成员的对抗样本,错误率降至87.9%。集成对对抗扰动提供的抵抗力有限。
10 总结与讨论 (SUMMARY AND DISCUSSION)
作为总结,本文做出了以下观察:
- 对抗样本可以解释为高维点积的特性。它们是模型过于线性而不是过于非线性的结果。
- 对抗样本在不同模型间的泛化可以解释为对抗扰动与模型权重向量高度对齐的结果,以及不同模型在训练执行相同任务时学习相似函数。
- 扰动的方向,而不是空间中的特定点,最重要。空间不是充满像有理数一样精细平铺实数的对抗样本口袋。
- 因为是方向最重要,对抗扰动在不同清洁样本间泛化。
- 我们引入了一系列快速生成对抗样本的方法。
- 我们证明了对抗训练可以导致正则化;甚至比dropout更进一步的正则化。
- 我们运行了对照实验,未能用更简单但效率较低的正则化器(包括L¹权重衰减和添加噪声)重现这种效果。
- 易于优化的模型易于扰动。
- 线性模型缺乏抵抗对抗扰动的能力;只有具有隐藏层的结构(通用逼近定理适用的地方)才应该被训练来抵抗对抗扰动。
- RBF网络抵抗对抗样本。
- 训练来建模输入分布的模型不抵抗对抗样本。
- 集成不抵抗对抗样本。
关于垃圾类样本的一些进一步观察在附录中呈现:
- 垃圾类样本无处不在且易于生成。
- 浅层线性模型不抵抗垃圾类样本。
- RBF网络抵抗垃圾类样本。
基于梯度的优化是现代AI的主力。使用设计得足够线性的网络——无论是ReLU或maxout网络、LSTM,还是被仔细配置不过度饱和的sigmoid网络——我们能够拟合我们关心的大多数问题,至少在训练集上。对抗样本的存在表明,能够解释训练数据甚至能够正确标记测试数据并不意味着我们的模型真正理解我们要求它们执行的任务。相反,它们的线性响应在数据分布中不出现的点上过度自信,这些自信的预测经常是高度不正确的。这项工作表明我们可以通过明确识别问题点并在每个这些点上纠正模型来部分纠正这个问题。然而,人们也可以得出结论,我们使用的模型族本质上是有缺陷的。优化的容易性是以容易被误导的模型为代价的。这激励了能够训练行为更局部稳定的模型的优化过程的发展。
致谢 (ACKNOWLEDGMENTS)
我们要感谢Geoffrey Hinton和Ilya Sutskever的有益讨论。我们也要感谢Jeff Dean、Greg Corrado和Oriol Vinyals对本文草稿的反馈。我们要感谢Theano(Bergstra等人,2010;Bastien等人,2012)、Pylearn2(Goodfellow等人,2013b)和DistBelief(Dean等人,2012)的开发者。
参考文献 (REFERENCES)
Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Bergstra, James, Goodfellow, Ian J., Bergeron, Arnaud, Bouchard, Nicolas, and Bengio, Yoshua. Theano: new features and speed improvements. Deep Learning and Unsupervised Feature Learning NIPS 2012 Workshop, 2012.
Bergstra, James, Breuleux, Olivier, Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Desjardins, Guillaume, Turian, Joseph, Warde-Farley, David, and Bengio, Yoshua. Theano: a CPU and GPU math expression compiler. In Proceedings of the Python for Scientific Computing Conference (SciPy), June 2010. Oral Presentation.
Chalupka, K., Perona, P., and Eberhardt, F. Visual Causal Feature Learning. ArXiv e-prints, December 2014.
Dean, Jeffrey, Corrado, Greg S., Monga, Rajat, Chen, Kai, Devin, Matthieu, Le, Quoc V., Mao, Mark Z., Ranzato, MarcAurelio, Senior, Andrew, Tucker, Paul, Yang, Ke, and Ng, Andrew Y. Large scale distributed deep networks. In NIPS, 2012.
Deng, Jia, Dong, Wei, Socher, Richard, jia Li, Li, Li, Kai, and Fei-fei, Li. Imagenet: A large-scale hierarchical image database. In In CVPR, 2009.
Glorot, Xavier, Bordes, Antoine, and Bengio, Yoshua. Deep sparse rectifier neural networks. In JMLR W&CP: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS 2011), April 2011.
Goodfellow, Ian J., Mirza, Mehdi, Courville, Aaron, and Bengio, Yoshua. Multi-prediction deep Boltzmann machines. In Neural Information Processing Systems, December 2013a.
Goodfellow, Ian J., Warde-Farley, David, Lamblin, Pascal, Dumoulin, Vincent, Mirza, Mehdi, Pascanu, Razvan, Bergstra, James, Bastien, Frédéric, and Bengio, Yoshua. Pylearn2: a machine learning research library. arXiv preprint arXiv:1308.4214, 2013b.
Goodfellow, Ian J., Warde-Farley, David, Mirza, Mehdi, Courville, Aaron, and Bengio, Yoshua. Maxout networks. In Dasgupta, Sanjoy and McAllester, David (eds.), International Conference on Machine Learning, pp. 1319–1327, 2013c.
Gu, Shixiang and Rigazio, Luca. Towards deep neural network architectures robust to adversarial examples. In NIPS Workshop on Deep Learning and Representation Learning, 2014.
Hochreiter, S. and Schmidhuber, J. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997.
Hornik, Kurt, Stinchcombe, Maxwell, and White, Halbert. Multilayer feedforward networks are universal approximators. Neural Networks, 2:359–366, 1989.
Jarrett, Kevin, Kavukcuoglu, Koray, Ranzato, Marc’Aurelio, and LeCun, Yann. What is the best multi-stage architecture for object recognition? In Proc. International Conference on Computer Vision (ICCV’09), pp. 2146–2153. IEEE, 2009.
Krizhevsky, Alex and Hinton, Geoffrey. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009.
Nguyen, A., Yosinski, J., and Clune, J. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images. ArXiv e-prints, December 2014.
Rust, Nicole, Schwartz, Odelia, Movshon, J. Anthony, and Simoncelli, Eero. Spatiotemporal elements of macaque V1 receptive fields. Neuron, 46(6):945–956, 2005.
Srivastava, Nitish, Hinton, Geoffrey, Krizhevsky, Alex, Sutskever, Ilya, and Salakhutdinov, Ruslan. Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1):1929–1958, 2014.
Szegedy, Christian, Liu, Wei, Jia, Yangqing, Sermanet, Pierre, Reed, Scott, Anguelov, Dragomir, Erhan, Dumitru, Vanhoucke, Vincent, and Rabinovich, Andrew. Going deeper with convolutions. Technical report, arXiv preprint arXiv:1409.4842, 2014a.
Szegedy, Christian, Zaremba, Wojciech, Sutskever, Ilya, Bruna, Joan, Erhan, Dumitru, Goodfellow, Ian J., and Fergus, Rob. Intriguing properties of neural networks. ICLR, abs/1312.6199, 2014b. URL http://arxiv.org/abs/1312.6199.
附录A 垃圾类样本 (A RUBBISH CLASS EXAMPLES)
与对抗样本相关的一个概念是来自"垃圾类"的样本概念。这些样本是退化输入,人类会将其分类为不属于训练集中的任何类别。如果我们称训练集中的这些类为"正类",那么我们希望小心避免垃圾输入上的假阳性——即,我们不想将退化输入分类为真实的东西。在为每个类别分别使用二元分类器的情况下,我们希望所有类别输出接近零的类别存在概率,在仅对正类别的多项分布情况下,我们更愿意分类器在类别上输出高熵(接近均匀)分布。减少对垃圾输入脆弱性的传统方法是向模型引入一个额外的、表示垃圾类的常数输出。Nguyen等人(2014) 最近在计算机视觉背景下以愚弄图像的名称重新普及了垃圾类概念。与对抗样本一样,存在一种误解,认为垃圾类假阳性很难找到,并且它们主要是深度网络面临的问题。
我们对对抗样本作为线性和高维空间结果的解释也适用于分析模型在垃圾类样本上的行为。线性模型在远离训练数据的点上比在接近训练数据的点上产生更极端的预测。为了为这样的模型找到高置信度垃圾假阳性,我们只需要生成一个远离数据的点,更大的范数产生更多的置信度。RBF网络不能在远离训练数据的地方自信地预测任何类别的存在,不会被这种现象愚弄。
我们从 N ( 0 , I 784 ) N(0, I_{784}) N(0,I784)生成10,000个样本,并将它们输入MNIST数据集上的各种分类器。在这种情况下,我们认为对任何类别分配大于0.5的概率是错误的。顶部有softmax层的朴素训练maxout网络在高斯垃圾样本上有98.35%的错误率,错误上的平均置信度为92.8%。将顶层改为独立的sigmoid将错误率降至68%,错误上的平均置信度为87.9%。在CIFAR-10上,使用来自 N ( 0 , I 3072 ) N(0, I_{3072}) N(0,I3072)的1,000个样本,卷积maxout网络获得93.4%的错误率,平均置信度为84.4%。
这些实验表明Nguyen等人(2014) 采用的优化算法是过度的(或也许只在ImageNet上需要),并且他们愚弄图像中的丰富几何结构是由于其搜索过程中编码的先验,而不是这些结构uniquely能够引起假阳性。
尽管Nguyen等人(2014) 将注意力集中在深度网络上,浅层线性模型有同样的问题。softmax回归模型在垃圾样本上有59.8%的错误率,错误上的平均置信度为70.8%。如果我们相反使用不像线性函数那样行为的RBF网络,我们发现错误率为0%。注意当错误率为零时,错误上的平均置信度是未定义的。
Nguyen等人(2014) 专注于为特定类别生成愚弄图像的问题,这比简单地找到网络自信地分类为属于任何一个类别但有缺陷的点更难的问题。上述在MNIST和CIFAR-10上的方法倾向于在类别上有非常倾斜的分布。在MNIST上,朴素训练maxout网络的假阳性中45.3%被分类为5,没有被分类为8。同样,在CIFAR-10上,卷积网络的假阳性中49.7%被分类为青蛙,没有被分类为飞机、汽车、马、船或卡车。
为了解决Nguyen等人(2014) 引入的为特定类别生成愚弄图像的问题,我们提出将 ∇ x p ( y = i ∣ x ) \nabla_x p(y = i | x) ∇xp(y=i∣x)添加到高斯样本x作为生成分类为类别i的愚弄图像的快速方法。如果我们重复这个采样过程直到成功,我们有一个具有可变运行时间的随机算法。在CIFAR-10上,我们发现一个采样步骤对青蛙和卡车有100%的成功率,最难的类别是飞机,每个采样步骤的成功率为24.7%。平均在所有十个类别上,该方法有75.3%的平均每步成功率。因此我们可以用少量样本生成任何期望的类别,不需要特殊先验,而不是数万代进化。为了确认结果样本确实是愚弄图像,而不是由梯度符号方法渲染的真实类别图像,见图5。这种方法在生成类别i成员方面的成功率可能在具有更多类别的数据集上降低,因为在这种情况下意外增强不同类别j激活的风险增加。我们发现我们能够训练maxout网络在高斯垃圾样本上有零百分比错误率(它仍然容易受到通过对高斯样本应用快速梯度符号步骤生成的垃圾样本的攻击),对其分类清洁样本的能力没有负面影响。不幸的是,不像在对抗样本上训练,这没有导致模型测试集错误率的任何显著降低。
总之,似乎深度或浅层由线性部分构建的模型的随机选择输入绝大多数可能被错误处理,这些模型只在包含训练数据的非常薄的流形上合理表现。
图5: 为在CIFAR-10上训练的卷积网络随机生成的愚弄图像。这些样本通过从各向同性高斯中抽取样本,然后在增加"飞机"类概率的方向上进行梯度符号步骤生成。黄色框表示成功愚弄模型相信飞机以至少50%置信度存在的样本。"飞机"是在CIFAR-10上构造愚弄图像最难的类别,所以这个图表示了成功率方面的最坏情况。
这些实验表明Nguyen等人(2014) 采用的优化算法是过度的(或也许只在ImageNet上需要),并且他们愚弄图像中的丰富几何结构是由于其搜索过程中编码的先验,而不是这些结构唯一能够引起假阳性。
尽管Nguyen等人(2014) 将注意力集中在深度网络上,浅层线性模型有同样的问题。softmax回归模型在垃圾样本上有59.8%的错误率,错误上的平均置信度为70.8%。如果我们相反使用不像线性函数那样行为的RBF网络,我们发现错误率为0%。注意当错误率为零时,错误上的平均置信度是未定义的。
Nguyen等人(2014) 专注于为特定类别生成愚弄图像的问题,这比简单地找到网络自信地分类为属于任何一个类别但有缺陷的点更难的问题。上述在MNIST和CIFAR-10上的方法倾向于在类别上有非常倾斜的分布。在MNIST上,朴素训练maxout网络的假阳性中45.3%被分类为5,没有被分类为8。同样,在CIFAR-10上,卷积网络的假阳性中49.7%被分类为青蛙,没有被分类为飞机、汽车、马、船或卡车。
为了解决Nguyen等人(2014) 引入的为特定类别生成愚弄图像的问题,我们提出将 ∇ x p ( y = i ∣ x ) \nabla_x p(y = i | x) ∇xp(y=i∣x)添加到高斯样本x$作为生成分类为类别i的愚弄图像的快速方法。如果我们重复这个采样过程直到成功,我们有一个具有可变运行时间的随机算法。在CIFAR-10上,我们发现一个采样步骤对青蛙和卡车有100%的成功率,最难的类别是飞机,每个采样步骤的成功率为24.7%。平均在所有十个类别上,该方法有75.3%的平均每步成功率。因此我们可以用少量样本和无特殊先验生成任何期望的类别,而不是数万代进化。为了确认结果样本确实是愚弄图像,而不是由梯度符号方法渲染的真实类别图像,见图5。这种方法在生成类别i成员方面的成功率可能在具有更多类别的数据集上降低,因为在这种情况下意外增强不同类别j激活的风险增加。我们发现我们能够训练maxout网络在高斯垃圾样本上有零百分比错误率(它仍然容易受到通过对高斯样本应用快速梯度符号步骤生成的垃圾样本的攻击),对其分类清洁样本的能力没有负面影响。不幸的是,不像在对抗样本上训练,这没有导致模型测试集错误率的任何显著降低。
总之,似乎深度或浅层由线性部分构建的模型的随机选择输入绝大多数可能被错误处理,这些模型只在包含训练数据的非常薄的流形上合理表现。
以上为学术翻译和精读注解,希望对您有帮助

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)