Datawhale AI夏令营 「2025全球AI攻防挑战赛-赛道一:图片全要素交互认证-生成赛」的赛事项目实践
本次比赛的挑战在于:AIGC图片生成 :模型的挑战在于如何准确理解复杂的文本描述(Prompt),并生成出既美观又真实的图片。自然场景图片编辑 :编辑后的内容需要与原图在光影、透视和纹理上完美融合,不留痕迹。视觉文本编辑 :修改后的文字必须与原图中的文字在字体、大小、光影、背景融合度等方面保持高度一致,这要求模型具备强大的文字渲染与融合能力。Deepfake :需要将源人脸的身份特征自然地迁移到目
目录
一、Baseline方案分析
baseline方案优点与不足
在现有的Baseline方案基础上,可以尝试以下方法来进一步提升生成图片的质量:
-
Prompt 优化 :在AIGC图片生成任务中,Prompt是控制生成效果的关键。可以尝试添加更多细节描述词,比如“超高分辨率”、“电影级别光影”、“细节丰富”等,来引导模型生成更高质量的图片。
-
模型与API选择 :使用功能更全面的商业API,例如通义万相。这些模型在图像质量、细节丰富度和语义理解方面可能有更好的表现。
baseline方案修改思路
Baseline方案选择了成熟且易于集成的开源模型(如CogView4)和传统方法(如基于Dlib+OpenCV的换脸),这使得初学者能够快速理解和运行代码,作为参赛的起点。
方案中的模型和方法都是通用型的,没有针对各个子任务的特定难点进行深度优化。例如,在 视觉文本编辑 任务中,它没有专门处理文字在复杂背景下的融合问题;在 Deepfake 中,传统方法在处理非正面、光照复杂的人脸时,融合效果往往僵硬,有明显的拼接痕迹。
比赛的最终评分是基于主观视觉判断和客观指标的综合考量,但我们可以在本地模拟一个评估机制,帮助我们筛选出更好的生成结果。如下为一些参考指标:
-
Prompt一致性(Semantic Consistency): 图片是否准确表达了Prompt的语义。可以使用 CLIP Score 或其他视觉-语言模型来计算图片和Prompt的匹配程度。
-
图像质量(Perceptual Quality): 图片的清晰度、美观度和真实感。可以使用 FID(Frechet Inception Distance)或LPIPS(Learned Perceptual Image Patch Similarity) 等指标来评估。
-
身份一致性(Identity Preservation): 替换后的人脸是否保留了源人脸的身份特征。可以利用 人脸识别模型 来提取并比对源人脸和生成人脸的特征向量距离。
-
表情/姿态迁移(Expression & Pose Transfer): 新人脸是否保留了目标人脸的表情和姿态。这可以通过比较 面部关键点 或 3D姿态估计 来量化。
不要局限于一个模型。对于同一个Prompt,可以同时使用多个不同的模型或API(如SDXL、通义万相等)进行生成。利用本地评分函数对这些生成结果进行评估,选择得分最高的图片作为最终提交结果。这就像在进行一场小型的“模型A/B测试”。
二、赛题进阶要点分析
本次赛题的核心在于考察参赛者 利用和优化生成式AI技术,创造出高仿真度、难以被现有鉴伪系统识别的数字伪造内容 的能力。这不仅仅是简单地调用API或模型生成图片,更重要的是理解并掌握如何通过技术手段,在视觉上实现 “以假乱真” 。
参赛者需要对AIGC图片生成、图像编辑、视觉文本编辑和人脸替换(Deepfake)这四大核心任务有深入的理解。并非所有模型都能直接生成高质量结果。考察点在于你是否能通过调整 Prompt 、模型参数(如 guidance_scale 、 inference_steps )或结合 ControlNet 等辅助工具,来精准控制生成过程,从而提升图片质量和真实感。
三、进阶方法和思路分享
进阶思路1:AI图片识别方法
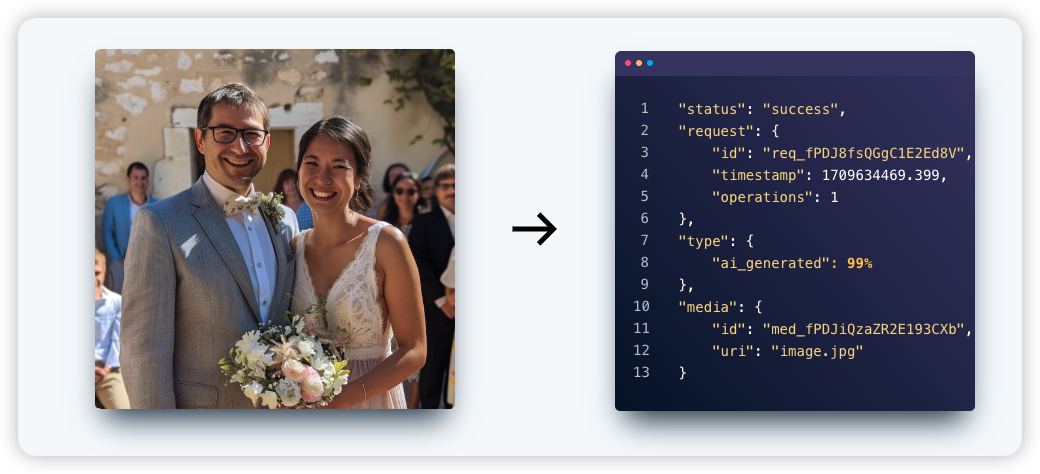
Identify if image has watermark using AI | Nyckel
AI生成图像与真实图像在频率分布上存在显著差异。AI生成图像在所有频率上都具有“分散的强度”,这意味着其傅里叶变换后的能量在整个频谱范围内分布较为均匀。相比之下,真实图像的强度则主要集中在中心频率,即能量主要集中在低频部分,反映出图像中平滑的过渡和整体结构。
此外,真实照片通常被描述为“混乱、无序和不平衡”的,它们捕捉了现实世界中固有的复杂性和随机性。而AI图片则可能因为其源自均匀随机噪声并经过逐步细化生成,而显得过于“平坦”或缺乏真实图像固有的复杂噪声特征。
通过CNN等二分类模型,可以将图片进行判断,是否为AI生成。
https://huggingface.co/umm-maybe/AI-image-detector
https://huggingface.co/mmanikanta/VIT_AI_image_detector
进阶思路2:DeepFake识别方法
结合CNN和循环神经网络(RNN,例如LSTM)的模型,可以捕捉视频中人脸运动、表情变化等时序上的不自然之处。例如,一些模型可以识别不自然的头部姿势变化或异常的眨眼模式。
https://huggingface.co/prithivMLmods/Deep-Fake-Detector-v2-Model
https://huggingface.co/dima806/deepfake_vs_real_image_detection
进阶思路3:Qwen-Image
Qwen-Image可用于通用图像生成的GenEval、DPG和OneIG-Bench,以及用于图像编辑的GEdit、ImgEdit和GSO。Qwen-Image在所有基准测试中均取得了最先进的性能,展现出其在图像生成与图像编辑方面的强大能力。
https://huggingface.co/Qwen/Qwen-Image
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
# Load the pipeline
if torch.cuda.is_available():
torch_dtype = torch.bfloat16
device = "cuda"
else:
torch_dtype = torch.float32
device = "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
positive_magic = {
"en": "Ultra HD, 4K, cinematic composition." # for english prompt,
"zh": "超清,4K,电影级构图" # for chinese prompt,
}
# Generate image
prompt = '''A coffee shop entrance features a chalkboard sign reading "Qwen Coffee 😊 $2 per cup," with a neon light beside it displaying "通义千问". Next to it hangs a poster showing a beautiful Chinese woman, and beneath the poster is written "π≈3.1415926-53589793-23846264-33832795-02384197". Ultra HD, 4K, cinematic composition'''
negative_prompt = " " # using an empty string if you do not have specific concept to remove
# Generate with different aspect ratios
aspect_ratios = {
"1:1": (1328, 1328),
"16:9": (1664, 928),
"9:16": (928, 1664),
"4:3": (1472, 1140),
"3:4": (1140, 1472),
"3:2": (1584, 1056),
"2:3": (1056, 1584),
}
width, height = aspect_ratios["16:9"]
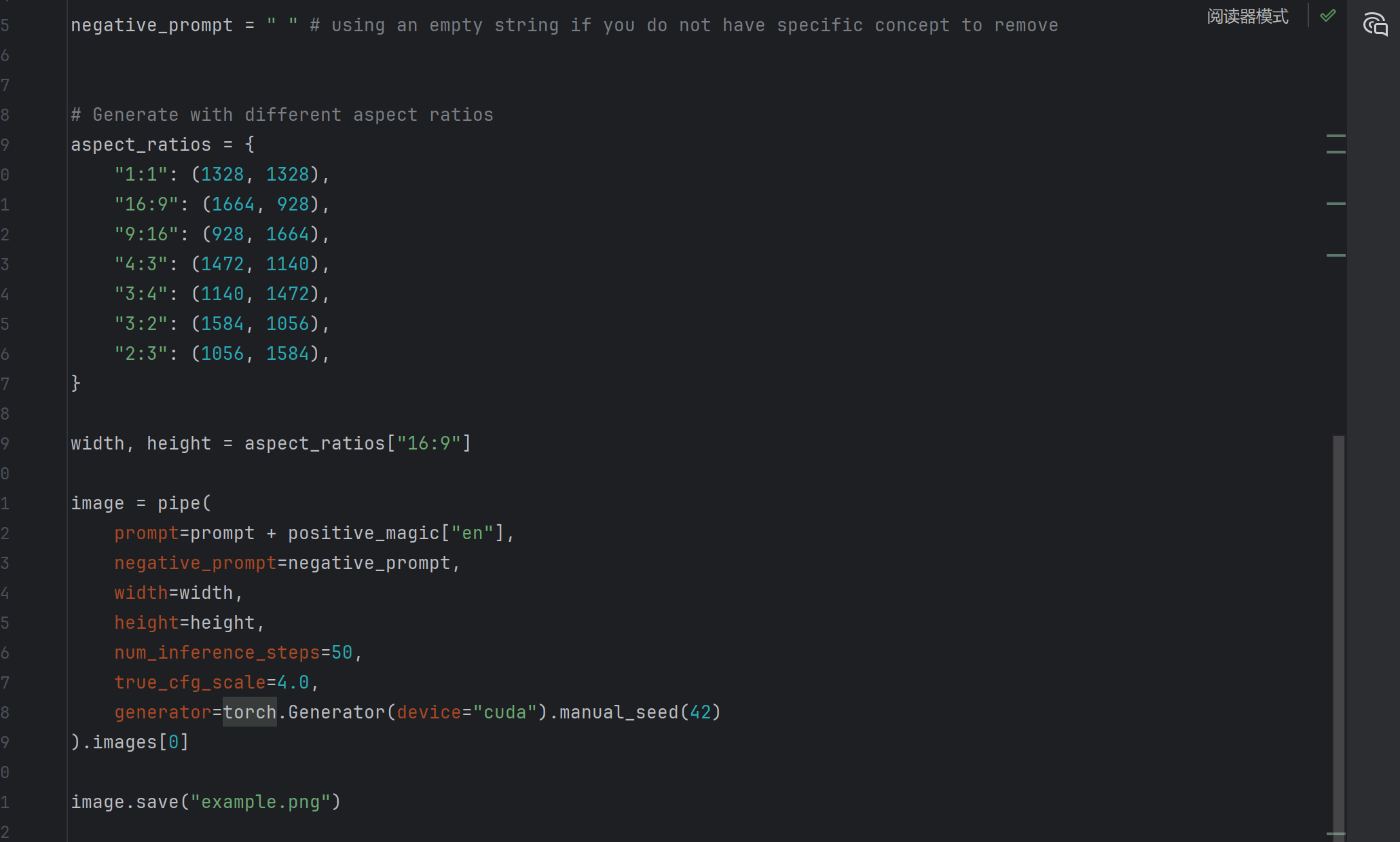
image = pipe(
prompt=prompt + positive_magic["en"],
negative_prompt=negative_prompt,
width=width,
height=height,
num_inference_steps=50,
true_cfg_scale=4.0,
generator=torch.Generator(device="cuda").manual_seed(42)
).images[0]
image.save("example.png")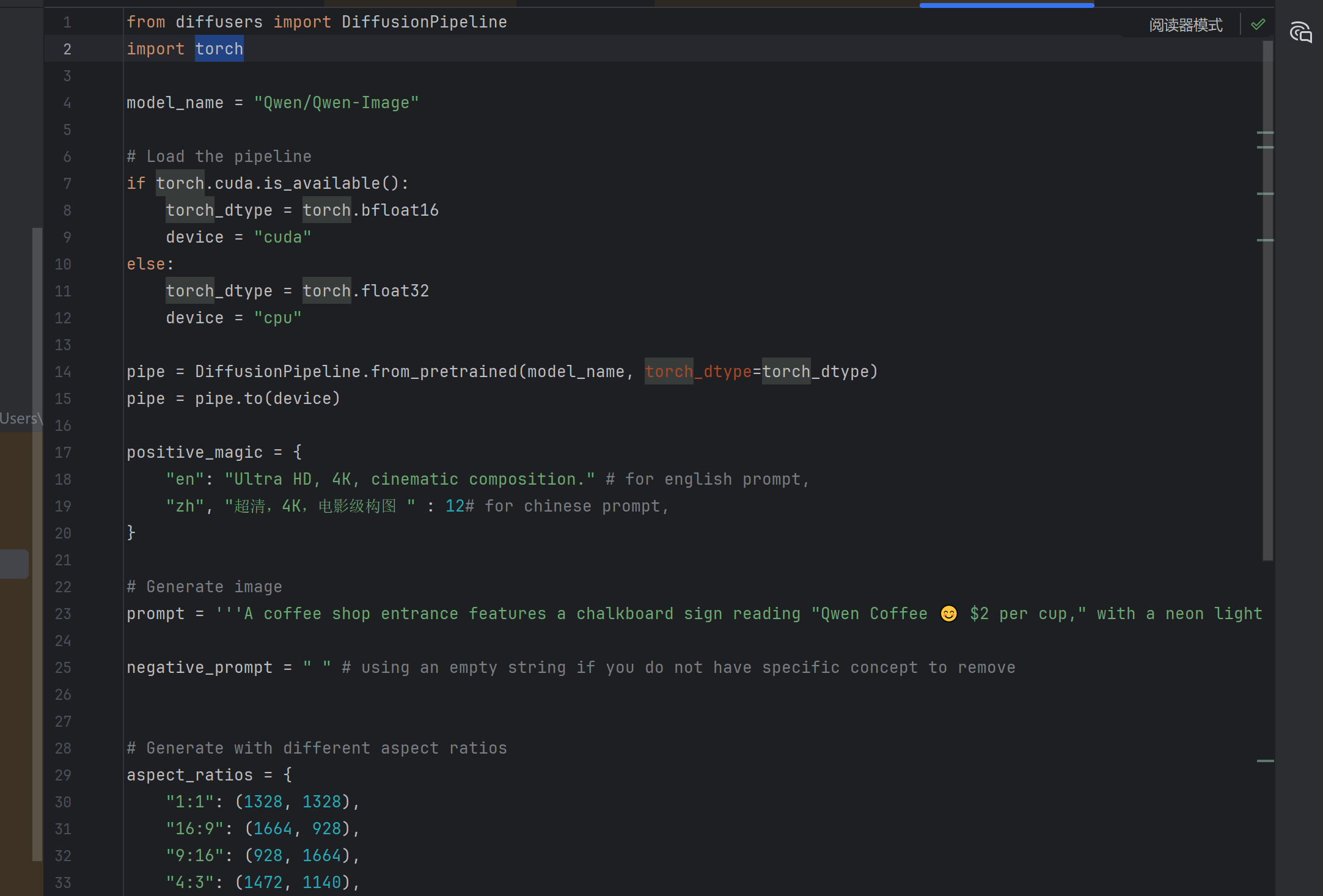
最后、祝大家上分愉快!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)