佳文赏读 || LPMRL~时间序列分类:语言预训练引导掩蔽表征学习(2025 AAAI: 即插即用模块)
选文针对时间序列数据的复杂性、时空性和连续性所带来的自监督表征学习挑战,提出了一种新的方法——语言预训练引导掩蔽表征学习(LPMRL)。该方法通过自然语言描述引导掩蔽编码器自适应采样语义时空块,显著提高了潜在表征的可区分性。此外,LPMRL引入了对比学习机制,通过生成高质量的难负样本,进一步优化表征的可区分性,从而提高模型的分类性能。通过在106个基准数据集上的实验验证,LPMRL显著优于现有的最

简介:由于时间序列数据的复杂性、时空性和连续性,其自监督表征学习比结构化数据更具挑战性。现有的对比学习和掩蔽自编码器方法在时间序列表征学习中存在固有限制,例如无效的增强和掩蔽策略。选文提出了一种新的方法——语言预训练引导掩蔽表征学习(LPMRL),用于时间序列分类。该方法通过自然语言描述引导掩蔽编码器自适应采样语义时空块,显著提高了潜在表征的可区分性。选文不仅提出了新的技术框架,还在106个基准数据集上验证了其有效性,为时间序列分类提供了新的解决方案。
论文题目:时间序列分类:语言预训练引导掩蔽表征学习 (英文:Language Pre-training Guided Masking Representation Learning for Time Series Classification)
第一作者:Liaoyuan Tang
通讯作者:Zheng Wang
通讯单位:School of Artificial Intelligence, Optics and Electronics (iOPEN), Northwestern Polytechnical University
发表时间:2025年
论文地址:https://ojs.aaai.org/index.php/AAAI/article/download/33377/35532
目录:
一、引言
1.1 时间序列表征学习的研究背景
1.2 研究动机与贡献
二、LPMRL方法
2.1 语言引导掩蔽编码器
2.2 对比学习机制
三、实验与结果
3.1 实验设置
3.2 实验结果分析
四、结束语
🚀 读完本文,你将获得以下超实用技能和知识储备:
- 时间序列表征学习的背景与挑战:了解时间序列数据在多个领域的广泛应用,以及其高维性、无结构性和时间性所带来的挑战。
- LPMRL的设计与实现:掌握语言预训练引导掩蔽表征学习(LPMRL)的设计原理,包括如何利用自然语言描述生成掩蔽策略,以及如何通过交叉注意力机制选择语义丰富的时空块进行掩蔽,从而提升模型的自监督学习能力。
- 对比学习机制的应用:理解对比学习机制如何通过生成高质量的难负样本,捕获时间序列数据的局部和全局信息,进一步优化表征的可区分性,从而提高模型的分类性能。
- 模型实现与评估:学会在PyTorch框架中实现LPMRL模型,并使用t-SNE可视化工具评估模型的分类性能,验证模型在不同数据集上的有效性和鲁棒性。
一、引言
1.1 时间序列表征学习的研究背景
时间序列数据在多个领域中被广泛应用,例如工业故障诊断、机器剩余使用寿命预测和分类等。然而,由于时间序列数据的高维性、无结构性和时间性,隐藏在长序列中的大量信息模式难以被人类观察到,这严重限制了时间序列数据的应用。随着深度学习技术的发展,基于表征学习的方法被广泛用于使时间序列数据更具可解释性。
1.2 研究动机与贡献
现有的对比学习和掩蔽自编码器方法在时间序列表征学习中存在固有限制,例如无效的增强和掩蔽策略。选文提出了一种新的方法——语言预训练引导掩蔽表征学习(LPMRL),用于时间序列分类。LPMRL通过自然语言描述引导掩蔽编码器自适应采样语义时空块,显著提高了潜在表征的可区分性。此外,选文还引入了**对比学习机制,**以进一步提高表征的可区分性。通过在106个基准数据集上的实验验证,LPMRL显著优于现有的最先进方法。
二、LPMRL方法
2.1 语言引导掩蔽编码器
LPMRL的核心是语言引导掩蔽编码器,它通过自然语言描述生成掩蔽策略,自适应地采样语义时空块。具体来说,LPMRL使用预训练的语言编码器生成时间序列标签的文本嵌入,然后通过交叉注意力机制计算时间序列块与文本嵌入之间的相似性,从而选择具有丰富语义信息的块进行掩蔽。这种方法不仅提高了掩蔽策略的有效性,还增强了模型的自监督学习能力。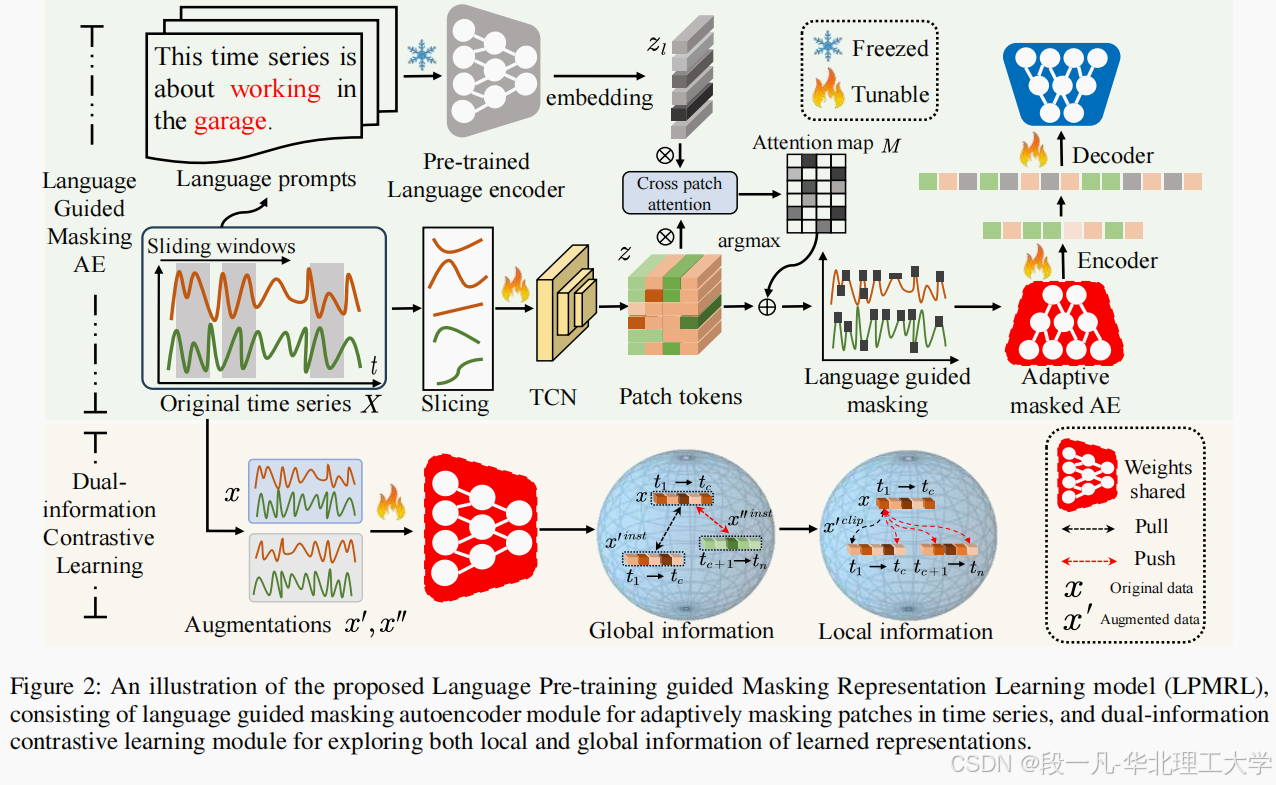
2.2 对比学习机制
LPMRL引入了对比学习机制,以捕获时间序列数据的局部和全局信息。通过精心设计高质量的难负样本,对比学习机制能够进一步提高表征的可区分性。具体来说,LPMRL在片段级别和实例级别生成难负样本,分别用于捕获局部和全局信息。这种方法不仅提高了模型的鲁棒性,还显著提升了分类性能。
三、实验与结果
3.1 实验设置
实验使用了UCR时间序列数据集,这是一个广泛使用的基准数据集。为了验证LPMRL的有效性,作者选择了106个具有代表性和挑战性的数据集进行实验。实验使用了SVM分类器,并将所有方法的表征维度配置为320。实验结果表明,LPMRL在所有106个数据集上均取得了最佳分类性能,平均准确率达到85.1%,并在60个数据集上取得了最高准确率。
3.2 实验结果分析
实验结果表明,LPMRL在不同比例的数据集上均取得了显著优于基线方法的分类性能。具体来说,LPMRL在小样本数据集上表现尤为出色,这表明LPMRL在处理时间序列数据时具有较强的鲁棒性和泛化能力。此外,通过t-SNE可视化工具,作者展示了LPMRL在多个数据集上的分类性能,进一步验证了其有效性。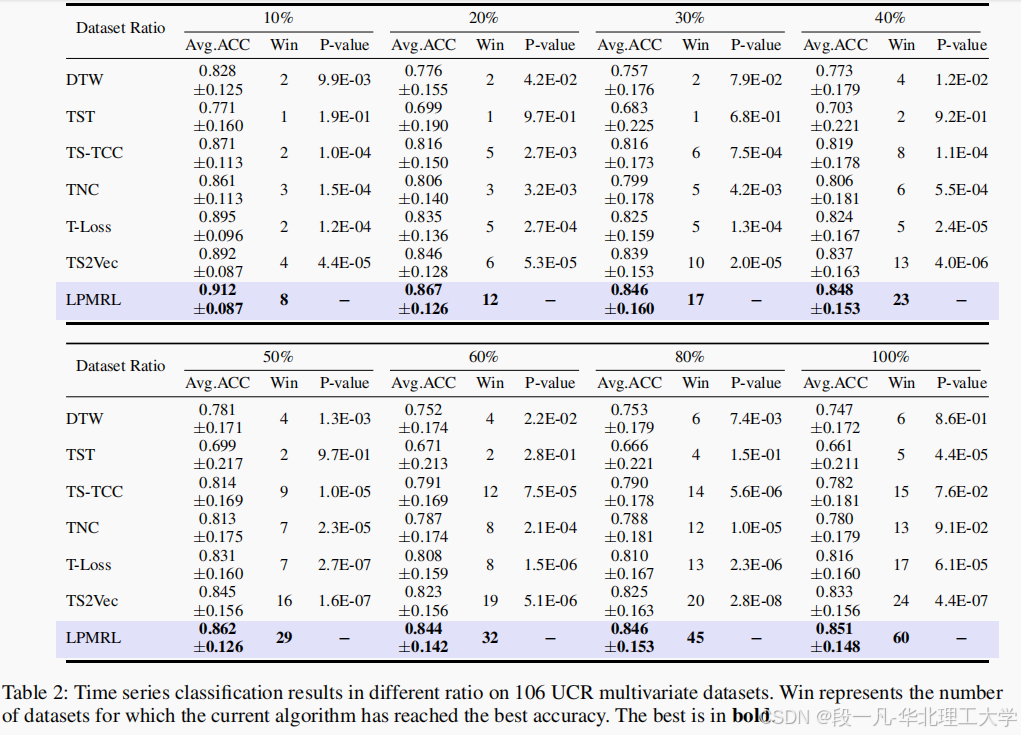

四、结束语
选文提出了一种新的时间序列表征学习方法——语言预训练引导掩蔽表征学习(LPMRL)。LPMRL通过自然语言描述引导掩蔽编码器自适应采样语义时空块,并引入对比学习机制以进一步提高表征的可区分性。通过在106个基准数据集上的实验验证,LPMRL显著优于现有的最先进方法。希望本文能够帮助读者更好地理解和应用LPMRL方法,提升时间序列分类的性能。
最后,感谢你的阅读!如果你觉得本文对你有帮助,不妨点赞和关注,我会继续分享更多关于工业大数据与人工智能工业应用领域的佳文鉴赏系列。🚀
关注专栏,每周更新,带你持续了解更多前沿性科研报道。
版权归文章作者所有,本文为对原文的翻译性总结介绍与解读,或有不当之处,敬请指正!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)