AI应用开发技术架构
纯Prompt / Agent + Function Calling / RAG / Fine-tuning
一:纯Prompt问答
核心思想:
只依赖模型本身的预训练知识,通过精心设计 Prompt(提示词)来获得需要的答案
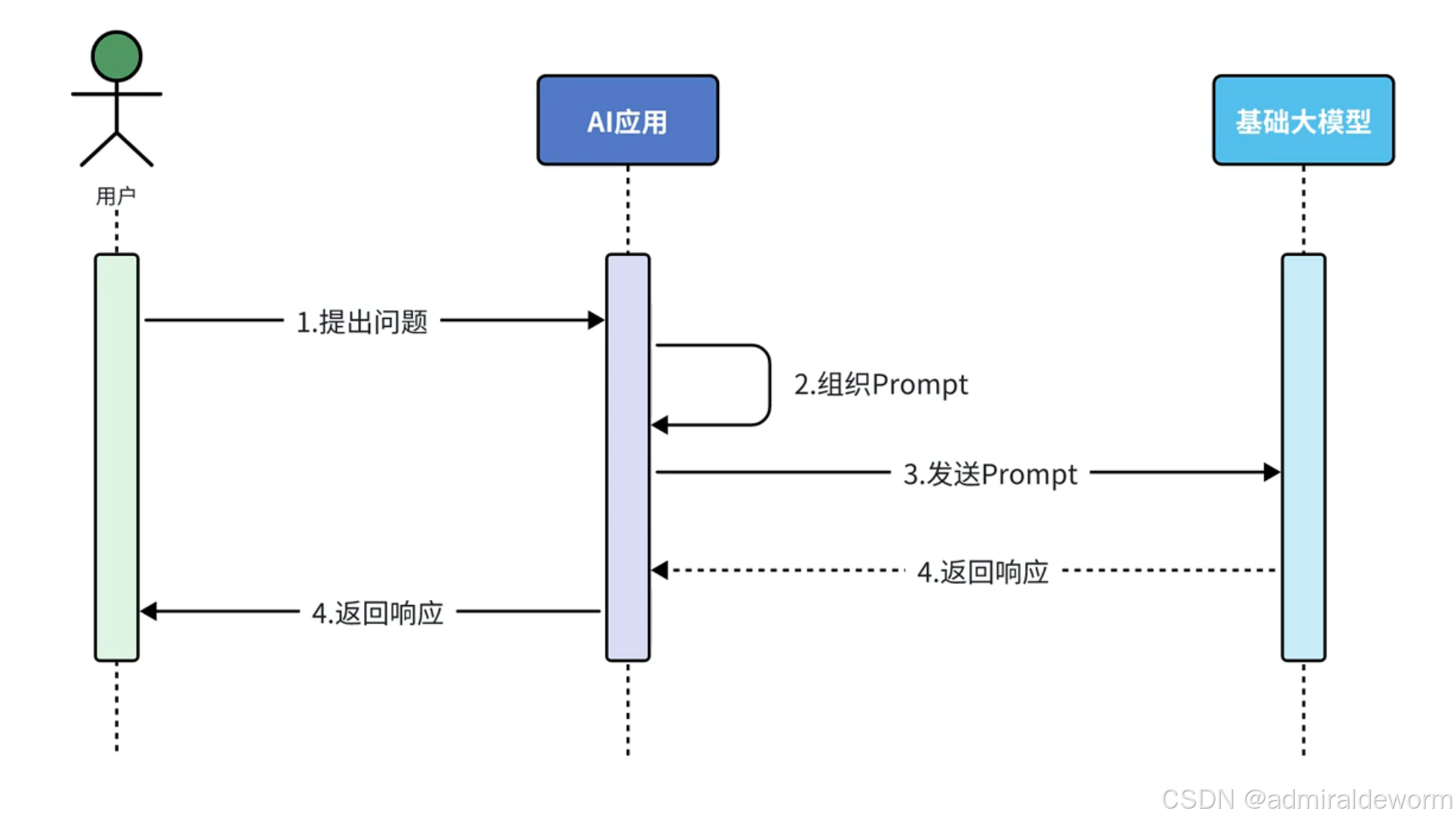
特点:
-
数据来源:模型训练时学到的知识(截止到训练时间)
-
优点:简单、无需额外部署数据库或训练
-
缺点:
-
不能访问最新信息(除非模型支持联网)
-
容易出现幻觉(hallucination)
-
不适合长尾企业知识问答
-
例子:
用户:请用 200 字介绍一下北极熊的生存现状
模型完全依靠自己的知识回答
应用场景:
• 文本摘要分析
• 舆情分析
• 坐席检查
• AI对话
二:Agent + Function Calling
核心思想:
让 AI 拥有“工具使用能力”,遇到任务时,AI 不是直接回答,而是决定调用哪些外部 API/函数获取数据,再加工生成结果
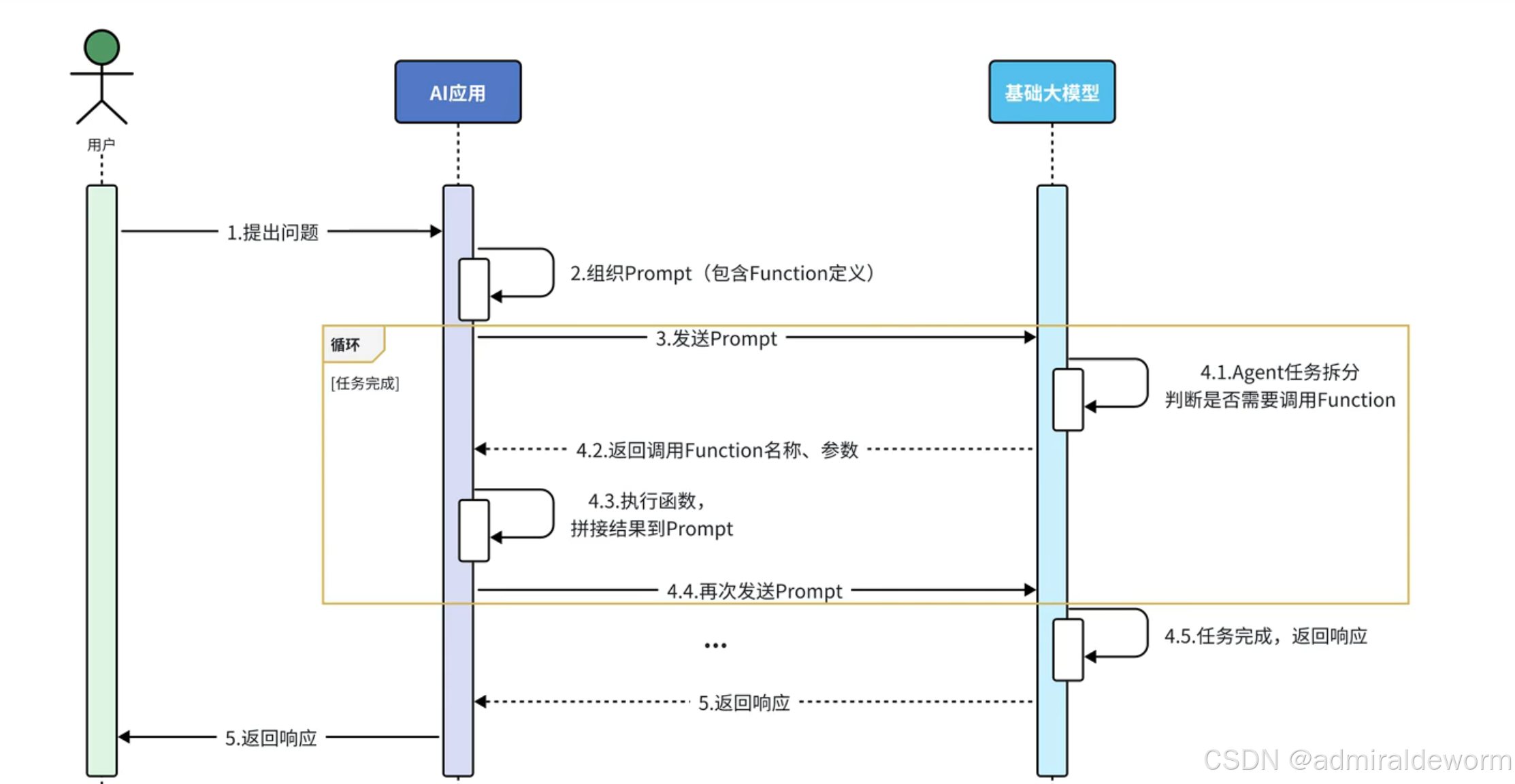
特点:
-
数据来源:模型知识 + 外部 API/数据库
-
优点:
-
能获取实时、专业数据
-
能执行操作(例如查天气、发邮件、调用数据库)
-
-
缺点:
-
要额外开发和维护 API/函数
-
模型需要理解工具使用场景(提示工程或专门训练)
-
例子:
用户:帮我查北京今天的天气
AI Agent:我应该调用 get_weather(city="北京") 这个函数
→ API 返回:26°C,晴
AI Agent:北京今天 26°C,晴天,适合出行。
应用场景:
• 旅行指南
• 数据提取
• 数据聚合分析 • 课程顾问
三:RAG (Retrieval Augmented Generation)
核心思想:
在生成回答前,先从外部知识库/向量数据库检索相关信息,把检索结果作为上下文喂给模型,让模型在回答时引用这些信息。
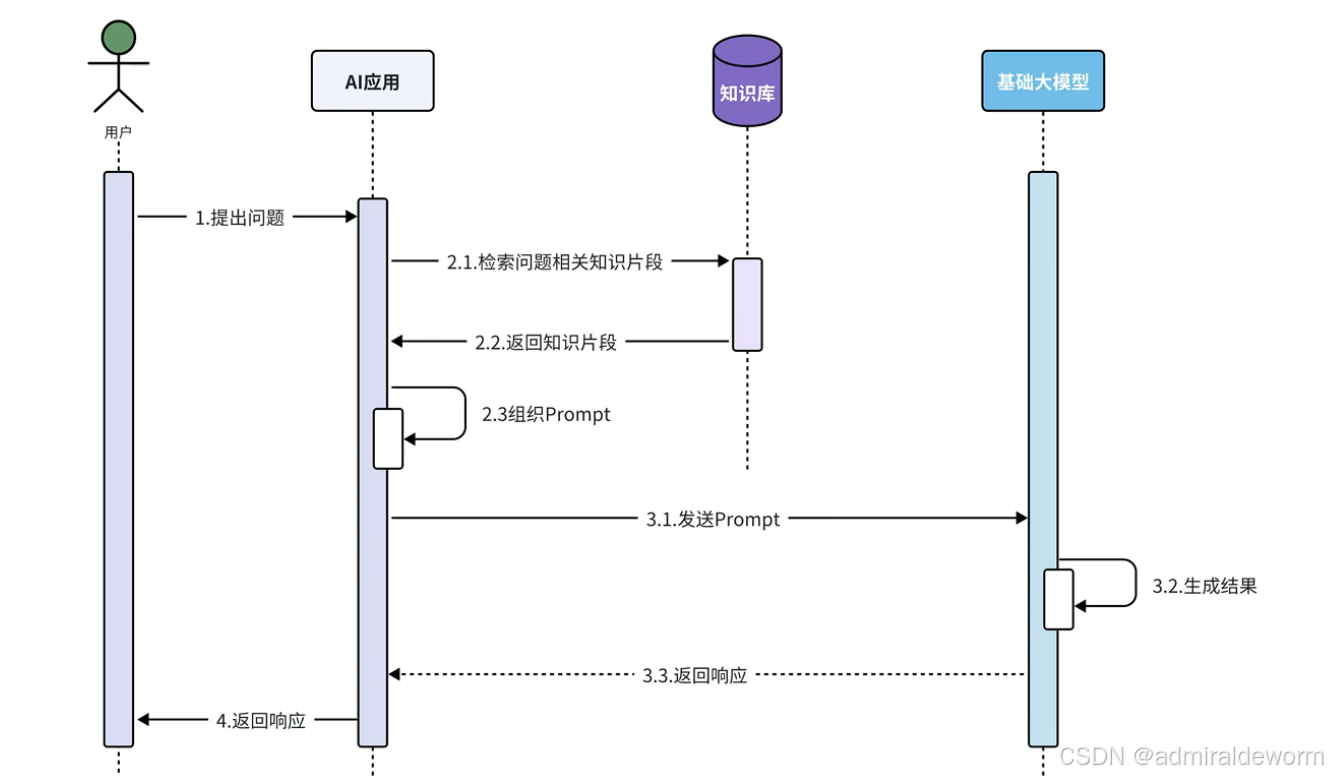
离线步骤:
① 文档加载
② 文档切分
③ 文档编码
④ 写入知识库
在线步骤:
① 获得用户问题
② 检索知识库中相关知识片段
③ 将检索结果和用户问题填入Prompt模版
④ 用最终获得的Prompt调用LLM
⑤ 由 LLM 生成回复
特点:
-
数据来源:向量数据库 + 模型
-
优点:
-
能接入企业私有知识(文档、FAQ、历史记录)
-
降低幻觉概率(模型基于真实资料回答)
-
知识可动态更新(无需重新训练模型)
-
-
缺点:
-
检索质量影响回答质量
-
架构比纯 Prompt 复杂(需要数据分片、嵌入、索引)
-
例子(企业知识问答):
用户:我们的退货政策是怎样的?
系统:从向量库检索到“退货需在30天内,且保持原包装”的文档
→ 模型结合检索内容回答:“我们支持30天内退货,需保持商品原包装。”
应用场景:
• 个人知识库
• AI客服助手
四:Fine-tuning(微调)
核心思想:
在预训练模型基础上,用特定领域的数据继续训练,使模型更适应特定任务或语言风格。
特点:
-
数据来源:你提供的标注数据
-
优点:
-
模型可以学习你的行业术语、文风、结构
-
长期效果好,推理时不需要外部检索
-
-
缺点:
-
需要标注数据(质量要求高)
-
训练和部署成本高
-
更新知识需要重新训练
-
例子:
-
把 GPT 微调成“律师助手”,学会法律术语和合同写作模板
-
把 LLaMA 微调成“游戏 NPC 对话模型”
总结对比表
| 技术路线 | 数据来源 | 实时性 | 架构复杂度 | 适用场景 |
|---|---|---|---|---|
| 纯 Prompt 问答 | 模型预训练知识 | ❌ | ★ | 一般性知识问答 |
| Agent + Function Calling | 模型 + API | ✅ | ★★ | 需要调用外部服务或实时数据 |
| RAG | 模型 + 向量数据库 | ✅(可更新库) | ★★★ | 企业知识库、文档问答 |
| Fine-tuning | 模型 + 标注数据 | ❌(需重训) | ★★★ | 固定领域任务、专业文风 |
技术选型:
首先判断最简单的Prompt问答方案是否可以解决问题,这是成本最低的方案,如果需要掉本地的业务接口实现操作,就选用Function Calling方案,如果还需要一些外挂的知识库,就选择RAG,以上都无法满足,只能用Fine-tuning来满足特定场景的需求

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 31
31 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)