Nature子刊:AI生成医学图像掩码,分割性能飙升20%!
包含数据生成模型和医学图像分割模型,数据生成模型基于条件生成对抗网络(GANs),由掩码到图像生成器和判别器组成,生成器具有可学习的神经架构,以分割掩码为输入生成对应医学图像,判别器区分合成与真实医学图像;分割模型具有可学习权重参数和固定架构。数据生成采用反向机制:从专家标注的分割掩码开始,先应用旋转、翻转等基本图像增强操作生成增强掩码,再输入深度生成模型生成对应医学图像,生成的图像-掩码对作为分
·

- 论文标题:Generative AI enables medical image segmentation in ultra low-data regimes
- 作者:Li Zhang、Basu Jindal、Ahmed Alaa、Robert Weinreb、David Wilson、Eran Segal、James Zou、Pengtao Xie
- 机构:
- 美国加利福尼亚大学圣地亚哥分校
- 美国匹兹堡大学
- 以色列魏茨曼科学研究所
- 美国斯坦福大学
- 论文地址:https://www.nature.com/articles/s41467-025-61754-6
- 论文来源:《Nature Communications》
- 论文这里
2. 【论文速读】
医学图像的语义分割在疾病诊断和治疗规划中至关重要,尽管深度学习能有效实现其自动化,但在超低数据环境中因缺乏带注释的分割掩码而表现不佳。为此,加州福尼亚大学研究团队提出一种生成式深度学习框架,可生成高质量图像-掩码对作为辅助训练数据,其采用多级优化进行端到端数据生成,让分割性能指导生成过程,从而产生有助于改善分割结果的数据。该方法在11项医学图像分割任务和19个数据集上展现出强大泛化能力,涵盖多种疾病、器官和模态,在相同域和跨域场景中性能提升10%-20%(绝对值),且所需训练数据比现有方法少8-20倍,大大提高了深度学习在数据有限的医学成像场景中的可行性和成本效益。
3.【背景及相关工作】
3.1 研究背景
- 医学图像语义分割是疾病诊断、治疗规划的关键技术,需精准识别器官、病灶等区域。
- 深度学习在该领域表现优异,但依赖大量带注释的分割掩码数据。
- 实际场景中,医学数据标注成本高、样本量有限(尤其罕见病),导致超低数据环境下模型性能大幅下降,成为技术落地瓶颈。
3.2 相关工作
- 传统数据增强方法:通过旋转、裁剪等简单变换扩充数据,但难以突破原始数据分布限制,超低数据下效果有限。
- 半监督/弱监督学习:利用未标注或弱标注数据辅助训练,仍需一定量标注数据,对极端少样本场景适配性不足。
- 生成式模型应用:部分研究尝试用GAN等生成图像,但多将数据生成与模型训练分离,生成数据与分割任务的关联性较弱,难以针对性提升分割性能。
- 小样本学习方法:聚焦少样本场景下的模型适配,但在医学图像分割的复杂语义场景中,泛化能力和性能提升空间有限。
4.【研究方法论】
4.1 GenSeg框架概述
- 包含数据生成模型和医学图像分割模型,数据生成模型基于条件生成对抗网络(GANs),由掩码到图像生成器和判别器组成,生成器具有可学习的神经架构,以分割掩码为输入生成对应医学图像,判别器区分合成与真实医学图像;分割模型具有可学习权重参数和固定架构。
- 数据生成采用反向机制:从专家标注的分割掩码开始,先应用旋转、翻转等基本图像增强操作生成增强掩码,再输入深度生成模型生成对应医学图像,生成的图像-掩码对作为分割模型的训练样本。
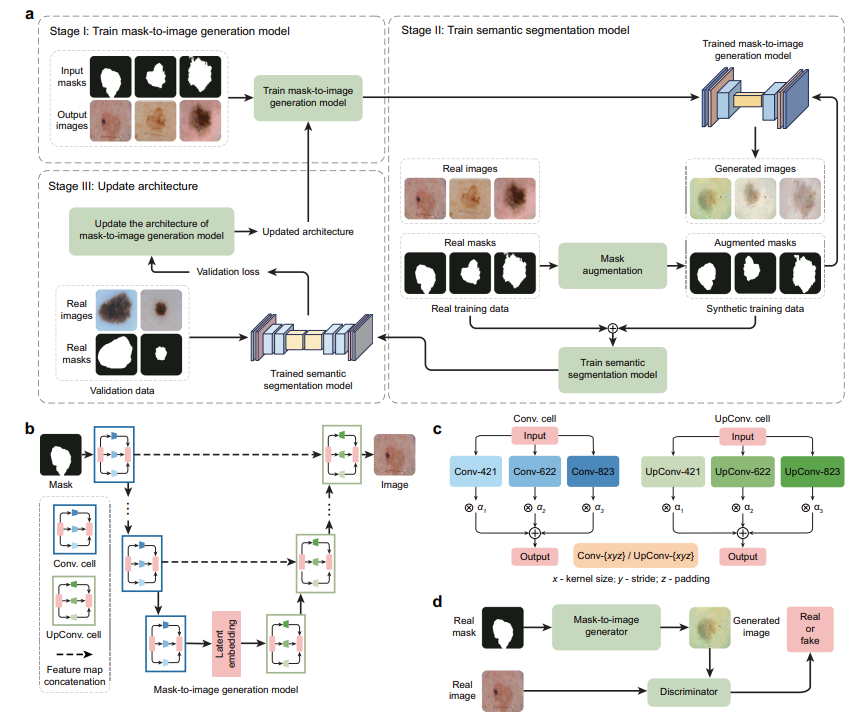
4.2 多级优化(MLO)框架
- 第一阶段:训练数据生成模型
- 固定生成器架构 A A A,训练生成器( G G G)和判别器( H H H)的权重参数。
- 构建新数据集 D g a n = { M n ( t r ) , I n ( t r ) } n = 1 N t r \mathcal{D}_{gan} = \{{M_n^{(tr)}, I_n^{(tr)}}\}_{n=1}^{N_{tr}} Dgan={Mn(tr),In(tr)}n=1Ntr,其中 M n ( t r ) M_n^{(tr)} Mn(tr)为输入, I n ( t r ) I_n^{(tr)} In(tr)为输出。
- 训练目标为最小化最大化问题: G ∗ ( A ) , H ∗ = a r g m i n G a r g m a x H L g a n ( G , A , H , D g a n ) G^{*}(A), H^{*} = argmin_G argmax_H L_{gan}(G, A, H, \mathcal{D}_{gan}) G∗(A),H∗=argminGargmaxHLgan(G,A,H,Dgan)。
- 第二阶段:训练语义分割模型
- 利用训练好的生成器生成合成训练样本 D ^ ( G ∗ ( A ) , D s e g t r ) \hat{\mathcal{D}}(G^{*}(A), \mathcal{D}_{seg}^{tr}) D^(G∗(A),Dsegtr)。
- 结合真实训练数据训练分割模型 S S S,优化目标为: S ∗ ( A ) = a r g m i n S L s e g ( S , D ^ ( G ∗ ( A ) , D s e g t r ) ) + γ L s e g ( S , D s e g t r ) S^{*}(A) = argmin_S L_{seg}(S, \hat{\mathcal{D}}(G^{*}(A), \mathcal{D}_{seg}^{tr})) + \gamma L_{seg}(S, \mathcal{D}_{seg}^{tr}) S∗(A)=argminSLseg(S,D^(G∗(A),Dsegtr))+γLseg(S,Dsegtr),其中 γ \gamma γ为权衡参数。
- 第三阶段:优化生成器架构
- 在验证数据集 D s e g v a l \mathcal{D}_{seg}^{val} Dsegval上评估分割模型性能,验证损失 L s e g ( S ∗ ( A ) , D s e g v a l ) L_{seg}(S^{*}(A), \mathcal{D}_{seg}^{val}) Lseg(S∗(A),Dsegval)反映生成数据质量。
- 通过最小化验证损失优化生成器架构: m i n A L s e g ( S ∗ ( A ) , D s e g v a l ) min_A L_{seg}(S^{*}(A), \mathcal{D}_{seg}^{val}) minALseg(S∗(A),Dsegval)。
- 整体MLO问题:整合上述三个阶段,形成相互依赖的优化问题,各层级输出和变量相互关联。
4.3 架构搜索空间
- 受DARTS启发,采用可微分搜索方法,搜索空间由一系列计算单元构成,每个单元形成有向无环图,包含输入节点、输出节点和中间节点,中间节点由卷积、转置卷积等 K K K种不同算子组成。
- 每个算子关联可学习的选择权重 α \alpha α(0到1之间),权重越高表示该算子越可能纳入最终架构。
- 候选算子包括Conv/UpConv-421、Conv/UpConv-622、Conv/UpConv-823( x x x为kernel大小, y y y为步长, z z z为填充),对于单元 i i i,输出 y i = ∑ k = 1 K α i , k o i , k ( x i ) y_i = \sum_{k=1}^{K} \alpha_{i,k} o_{i,k}(x_i) yi=∑k=1Kαi,koi,k(xi),生成器架构由所有选择权重 A = { α i , k } A = \{\alpha_{i,k}\} A={αi,k}描述,架构搜索即学习 A A A。
4.4 优化算法
- 采用基于梯度的方法求解MLO问题,通过一步梯度下降或上升更新近似各优化变量。
- 生成器参数近似: G ∗ ( A ) ≈ G ′ = G − η g ∇ G L g a n ( G , A , H , D g a n ) G^{*}(A) \approx G' = G - \eta_g \nabla_G L_{gan}(G, A, H, \mathcal{D}_{gan}) G∗(A)≈G′=G−ηg∇GLgan(G,A,H,Dgan),其中 η g \eta_g ηg为学习率。
- 判别器参数近似: H ∗ ≈ H ′ = H + η h ∇ H L g a n ( G , A , H , D g a n ) H^{*} \approx H' = H + \eta_h \nabla_H L_{gan}(G, A, H, \mathcal{D}_{gan}) H∗≈H′=H+ηh∇HLgan(G,A,H,Dgan),其中 η h \eta_h ηh为学习率。
- 分割模型参数近似: S ∗ ( A ) ≈ S ′ = S − η s ∇ S ( L s e g ( S , D ^ ( G ′ , D s e g t r ) ) + γ L s e g ( S , D s e g t r ) ) S^{*}(A) \approx S' = S - \eta_s \nabla_S (L_{seg}(S, \hat{\mathcal{D}}(G', \mathcal{D}_{seg}^{tr})) + \gamma L_{seg}(S, \mathcal{D}_{seg}^{tr})) S∗(A)≈S′=S−ηs∇S(Lseg(S,D^(G′,Dsegtr))+γLseg(S,Dsegtr)),其中 η s \eta_s ηs为学习率。
- 架构参数更新: A ← A − η a ∇ A L s e g ( S ′ , D s e g v a l ) A \leftarrow A - \eta_a \nabla_A L_{seg}(S', \mathcal{D}_{seg}^{val}) A←A−ηa∇ALseg(S′,Dsegval),其中 η a \eta_a ηa为学习率。
- 梯度计算: ∇ A L s e g ( S ′ , D s e g v a l ) = ∂ G ′ ∂ A ∂ S ′ ∂ G ′ ∂ L s e g ( S ′ , D s e g v a l ) ∂ S ′ \nabla_A L_{seg}(S', \mathcal{D}_{seg}^{val}) = \frac{\partial G'}{\partial A} \frac{\partial S'}{\partial G'} \frac{\partial L_{seg}(S', \mathcal{D}_{seg}^{val})}{\partial S'} ∇ALseg(S′,Dsegval)=∂A∂G′∂G′∂S′∂S′∂Lseg(S′,Dsegval),其中包含二阶导数项。
5.【实验结果】
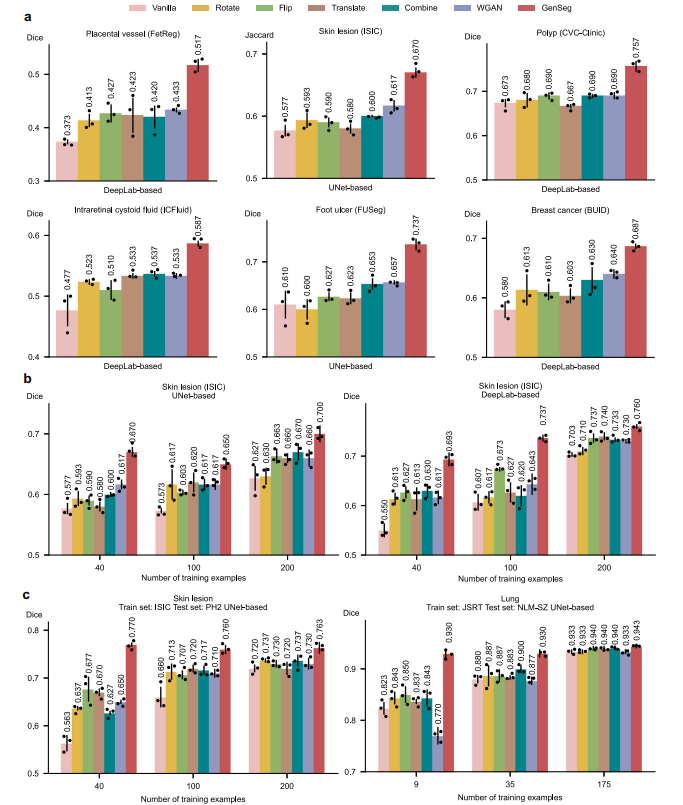
5.1 GenSeg在超低数据场景下提升分割精度
- 在胎盘血管、皮肤病变等11项任务中,使用50-100个训练样本时,GenSeg-DeepLab和GenSeg-UNet较基线模型(DeepLab、UNet)性能提升10%-20.6%(绝对百分比)。
- 以胎盘血管分割为例,GenSeg-DeepLab在50个训练样本下Dice得分0.52,远超DeepLab的0.42;皮肤病变分割中,GenSeg-UNet在40个样本下Jaccard指数提升9.6%。
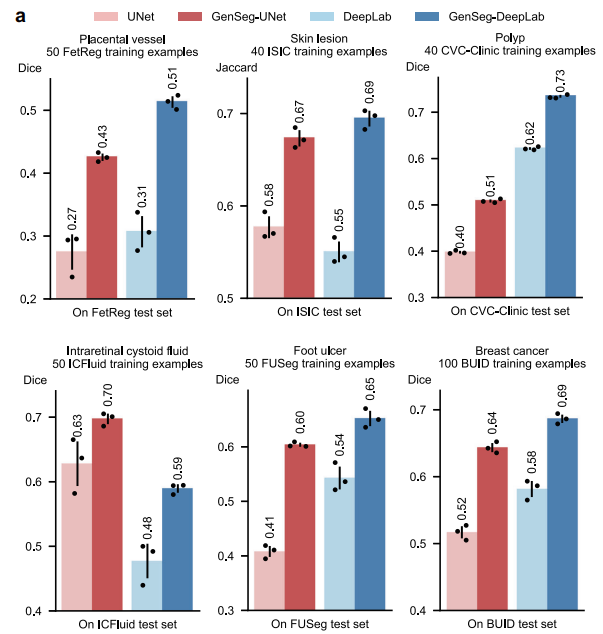
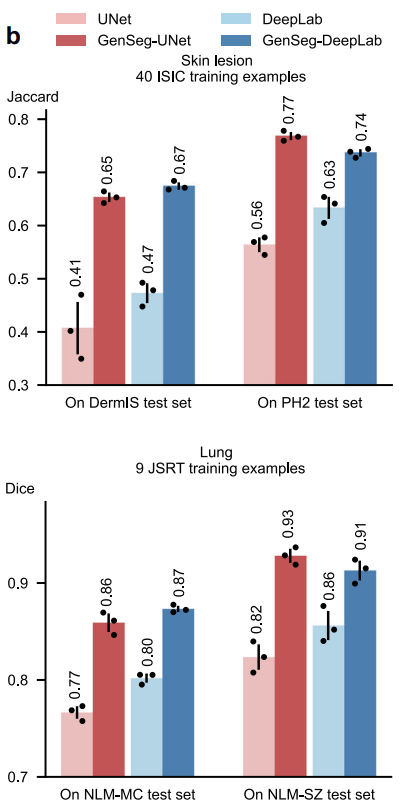
5.2 增强跨域泛化能力
- 在皮肤病变(ISIC训练,DermIS/PH2测试)和肺部(JSRT训练,NLM-SZ/MC测试)任务中,GenSeg在仅40或9个训练样本时,跨域性能显著优于基线。
- 例如,GenSeg-UNet在肺部跨域分割中Dice得分0.93,高于UNet的0.82;皮肤病变跨域Jaccard指数提升24%。
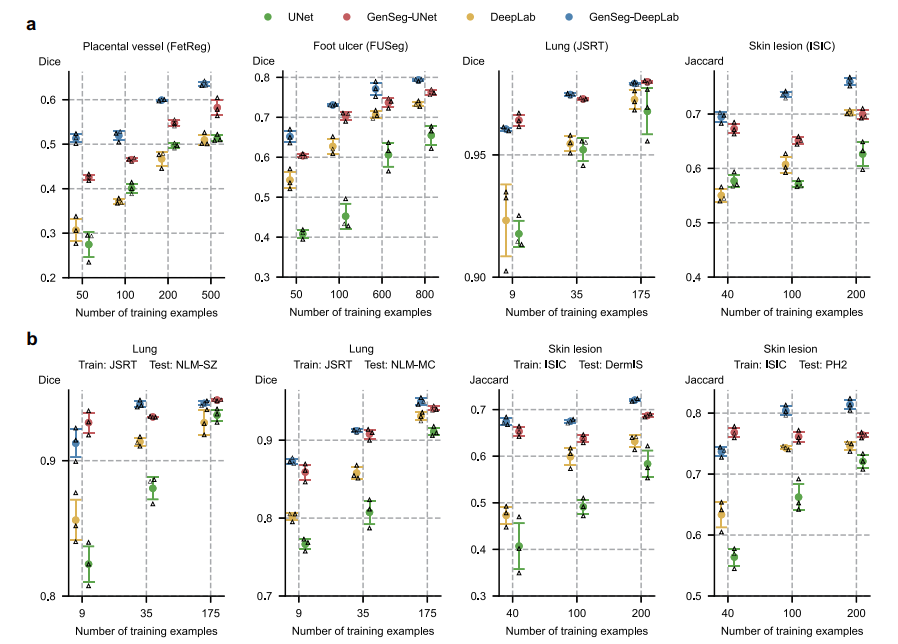
5.3 数据效率优势显著
- 达成与基线相当的性能时,GenSeg所需训练数据减少8-20倍。
- 如肺部分割中,GenSeg-UNet仅需9个样本达到Dice 0.97,而UNet需175个;足部溃疡分割中,GenSeg-UNet用50个样本实现0.6的Dice得分,UNet需600个。
5.4 优于现有数据增强与生成方法
- 在同域任务中,GenSeg在足部溃疡分割(UNet)中Dice得分0.74,高于WGAN的0.66;息肉分割(DeepLab)中得分0.76,优于Flip等方法的0.69。
- 跨域场景下,皮肤病变分割(PH2测试)中GenSeg Dice 0.77,超过Flip的0.68。
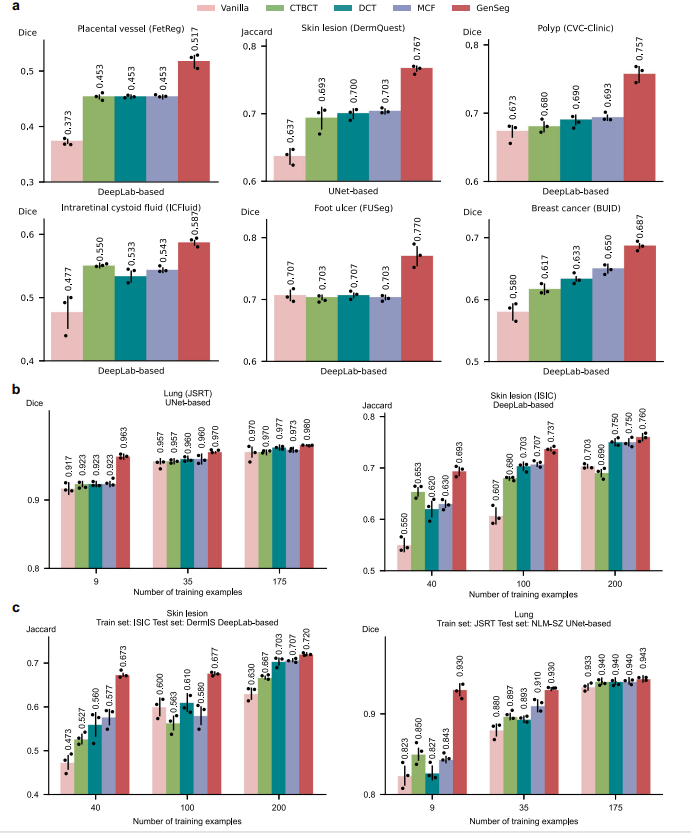
5.5 超越半监督与主流分割方法
- 无需额外无标签数据,GenSeg在息肉分割中Dice 0.76,优于半监督方法MCF的0.69;跨域皮肤病变分割中得分0.67,高于MCF的0.58。
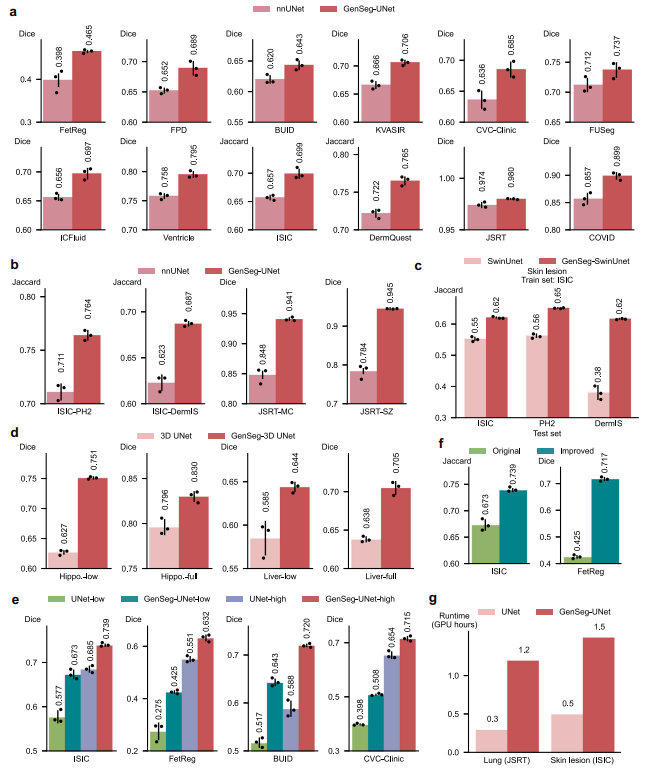
- 相较nnUNet,GenSeg-UNet在同域任务中性能提升1%-7%,跨域提升5%-16%,如肺部分割Dice达94.5%,远超nnUNet的78.4%。
5.6 适配多模型与3D场景
- 与UNet、DeepLab、SwinUnet等结合均有提升,如GenSeg-SwinUnet在皮肤病变分割中Jaccard指数提升7%-24%。
- 3D分割任务(海马体、肝脏)中,GenSeg在40个训练样本下性能优于基线3D UNet,尤其超低数据场景增益显著。
5.7 在高数据场景仍有效
- 全量数据训练时,GenSeg-UNet-high性能优于UNet-high;GenSeg-UNet-low(40-100样本)性能接近UNet-high(1000+样本),验证其在不同数据量下的通用性。
6.【总结展望】
6.1 总结
- GenSeg是一种生成式深度学习框架,可在超低数据环境下实现医学图像分割,通过多级优化进行端到端数据生成,使分割性能指导数据生成过程,生成的高质量图像-掩码对能有效提升分割模型性能。
- 在11项医学图像分割任务和19个数据集上验证显示,其在相同域和跨域场景中性能提升10%-20%(绝对值),所需训练数据比现有方法少8-20倍,且在高数据场景同样有效,还能适配多种分割模型及3D分割任务。
- 相比传统数据增强、生成技术及半监督方法,GenSeg无需额外无标签数据,通过端到端机制和生成数据多样性实现更优性能。
6.2 展望
- 改进合成数据生成质量,以更好地表现复杂解剖结构和不同成像模态的变异性,可通过优化多级优化过程或融入先进神经架构实现。
- 应用域适应技术,提升在与训练数据差异大的数据集或新成像技术下的稳健性,增强在实际临床场景的可靠性。
- 拓展应用范围,从分割任务延伸至异常检测、图像配准等其他医学影像挑战,结合临床专家反馈提高合成数据的临床相关性。
- 开展生成掩码变异性与专家标注差异的对比研究,利用多标注者数据集评估生成数据的临床真实性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)