AI基础学习周报八
本周聚焦知识增强推理与计算机视觉技术。深入研读ICLR 2024论文《Think-on-Graph》,解析其创新的"LLM⊗KG"紧耦合范式如何通过动态图搜索解决大模型幻觉问题,实现多跳推理与知识溯源;系统学习OpenCV核心功能,掌握图像处理、视频分析及形态学操作等关键技术,构建了从理论创新到工程实践的技术体系。
摘要
本周聚焦知识增强推理与计算机视觉技术。深入研读ICLR 2024论文《Think-on-Graph》,解析其创新的"LLM⊗KG"紧耦合范式如何通过动态图搜索解决大模型幻觉问题,实现多跳推理与知识溯源;系统学习OpenCV核心功能,掌握图像处理、视频分析及形态学操作等关键技术,构建了从理论创新到工程实践的技术体系。
Abstract
This week centered on knowledge-augmented reasoning and computer vision techniques. Featured an in-depth study of the ICLR 2024 paper “Think-on-Graph”, analyzing its innovative “LLM⊗KG” paradigm that resolves model hallucinations through dynamic graph traversal for multi-hop reasoning. Systematically covered OpenCV core functionalities including image processing, video analysis, and morphological operations, establishing an integrated framework from theoretical innovation to engineering implementation.
1、Think-on-Graph: deep and responsible reasoning of large language model on knowledge graph
论文标题:Think-on-Graph: deep and responsible reasoning of large language model on knowledge graph
论文链接:https://arxiv.org/pdf/2307.07697.pdf
代码链接:https://github.com/IDEA-FinAI/ToG
发表会议:ICLR 2024
1.1 研究背景
-
LLM 的局限性:大型语言模型虽在多种任务中表现出色,但存在幻觉问题,尤其在需要深度推理的场景中:
- 难以处理超出预训练知识范围的问题或多跳推理问题;
- 缺乏可解释性和知识溯源能力,且知识更新成本高、速度慢。
-
现有LLM与KG结合的不足:传统“LLM ⊕ KG”范式中,LLM仅将问题转换为KG搜索命令(如SPARQL),不直接参与图推理,其效果依赖 KG 的完整性。若KG存在缺失关系(如“多数成分”),则无法生成正确答案。
-
新范式的提出:针对上述问题,提出“LLM ⊗ KG”紧耦合范式:LLM 作为智能代理,与KG协同工作,在推理的每一步动态探索KG中的实体和关系,补充彼此能力(例如通过KG中的三元组和LLM固有知识共同补全缺失信息)。
1.2 核心方法
ToG是“LLM ⊗ KG”范式的具体实现,通过LLM在KG上迭代执行波束搜索,动态探索推理路径,具体流程如下:
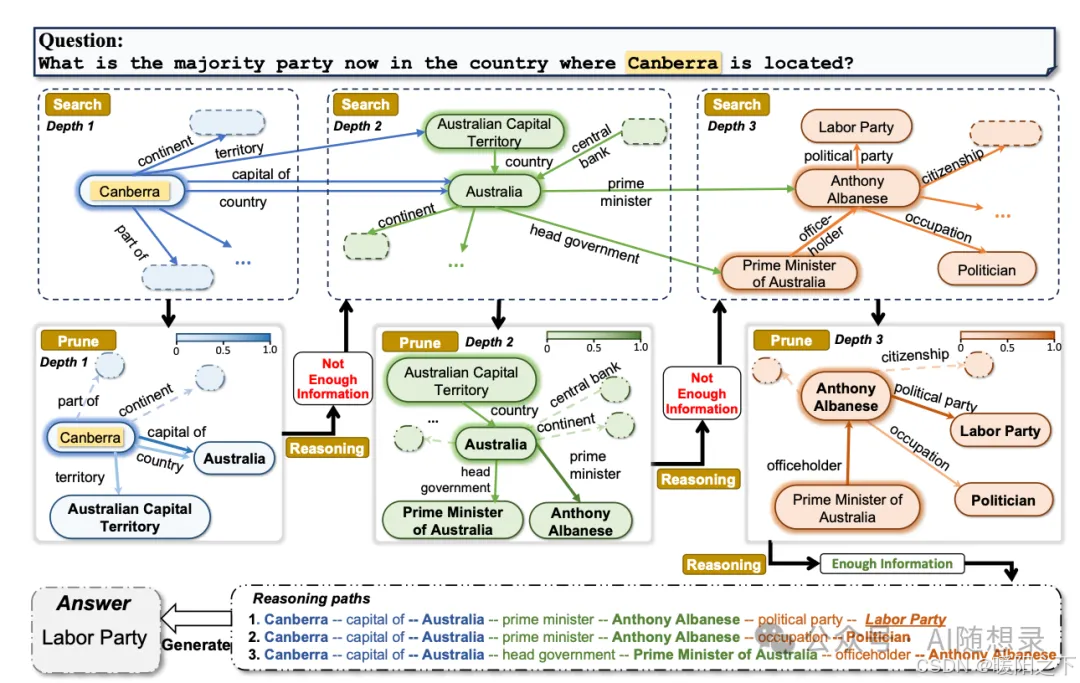
1.3 优缺点
1.3.1 优点
- 增强深度推理能力:ToG通过多跳推理路径,显著提升了LLM在复杂知识密集型任务中的表现。例如,在GraiQA和Zero-Shot RE数据集上,ToG的性能分别提升了51.8%和42.9%。
- 知识可追溯性:ToG提供了清晰的推理路径,使得推理过程可追溯、可解释,便于用户理解和修正错误,这种特性在需要高可信度的场景中尤为重要 。
- 灵活性和效率:ToG是一个插件式框架,可以与多种LLM和知识图谱兼容。它还通过波束搜索和剪枝策略,减少了不必要的计算开销,提高了推理效率 。
- 无需额外训练:ToG不需要对LLM进行额外的微调,即可在现有模型上部署,降低了部署成本 。
- 提升性能:在多个基准数据集上,ToG的性能显著优于传统方法,如Chain-of-Thought和Self-Consistency等。例如在CWQ数据集上,ToG的表现比CoT提高了17.47%。
1.3.2 缺点
- 计算成本较高:尽管ToG通过波束搜索和剪枝策略优化了效率,但其多跳推理过程仍然需要较高的计算资源。特别是在大规模知识图谱上,推理路径的生成和评估可能非常耗时。
- 知识图谱的不完整性:ToG的性能依赖于知识图谱的质量和完整性。如果知识图谱中存在缺失或错误的信息,可能会导致推理路径的偏差或错误。
- 对LLM的依赖性:ToG的性能在很大程度上依赖于LLM的推理能力。如果LLM本身存在局限性(如幻觉问题),则ToG的输出也可能受到影响。
- 路径选择的不确定性:虽然ToG通过波束搜索生成多个推理路径,但最终答案的选择仍然依赖于评分模型。如果评分模型不够强大,可能会导致错误的答案被选中。
1.4 总结
ToG通过“LLM ⊗ KG”范式实现了LLM与KG的深度协同,提升了LLM的深度推理能力、可解释性和知识更新效率。其免训练、低成本、高性能的特点,为解决LLM幻觉问题和知识密集型任务提供了新方案。
2、OpenCV
2.1 基本语法
import cv2
读取与显示图像
读取:imread
显示:waitKey
img = cv2.imread("test.jpg")
cv2.imshow("原图", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
视频读写
VideoCapture:读取摄像头或视频文件
VideoWriter:保存视频
cap = cv2.VideoCapture(0)
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi', fourcc, 20.0, (640,480))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
out.write(frame)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
out.release()
cv2.destroyAllWindows()
2.2 常用方法
色彩空间转换
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
图像阈值处理
_, th = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
ad_th = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2)
滤波与平滑
blur = cv2.blur(img, (5,5))
gaussian = cv2.GaussianBlur(img, (5,5), 0)
median = cv2.medianBlur(img, 5)
bilateral = cv2.bilateralFilter(img, 9, 75, 75)
边缘检测
edges = cv2.Canny(gray, 50, 150)
形态学操作
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5,5))
eroded = cv2.erode(th, kernel, iterations=1)
dilated = cv2.dilate(th, kernel, iterations=1)
opened = cv2.morphologyEx(th, cv2.MORPH_OPEN, kernel)
轮廓检测
contours, _ = cv2.findContours(th, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img, contours, -1, (0,255,0), 2)
几何变换
resized = cv2.resize(img, (320,240))
M = cv2.getRotationMatrix2D((cx,cy), 45, 1.0)
rotated = cv2.warpAffine(img, M, (w,h))
绘制函数
cv2.line(img, (0,0), (100,100), (255,0,0), 2)
cv2.rectangle(img, (50,50), (200,200), (0,255,0), 3)
cv2.circle(img, (300,300), 50, (0,0,255), -1)
cv2.putText(img, "OpenCV", (10,450),
cv2.FONT_HERSHEY_SIMPLEX, 1.2, (255,255,255), 2)
总结
本周在知识推理领域,重点解析了ToG框架的迭代式波束搜索机制——LLM作为智能代理动态探索知识图谱实体关系,通过路径评分模型解决复杂查询,显著提升推理深度与可解释性;在计算机视觉方向,系统实践了OpenCV的图像处理全流程:从色彩空间转换到特征提取,再到形态学操作及几何变换。下周将深入图神经网络与LLM的协同优化、OpenCV实时目标检测集成,以及知识图谱学习。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)