亚马逊-商品详情页违禁词检查_实在智能RPA源码解读
·
一、项目简介
本项目是一款基于实在智能RPA技术的亚马逊商品详情页违禁词检查工具。该工具能够自动遍历指定的亚马逊商品链接列表,提取商品标题、图片和描述信息,并检查其中是否包含预设的违禁词。工具支持自定义违禁词库,检查结果会自动导出到Excel文件中,方便用户查看和处理。
二、项目结构
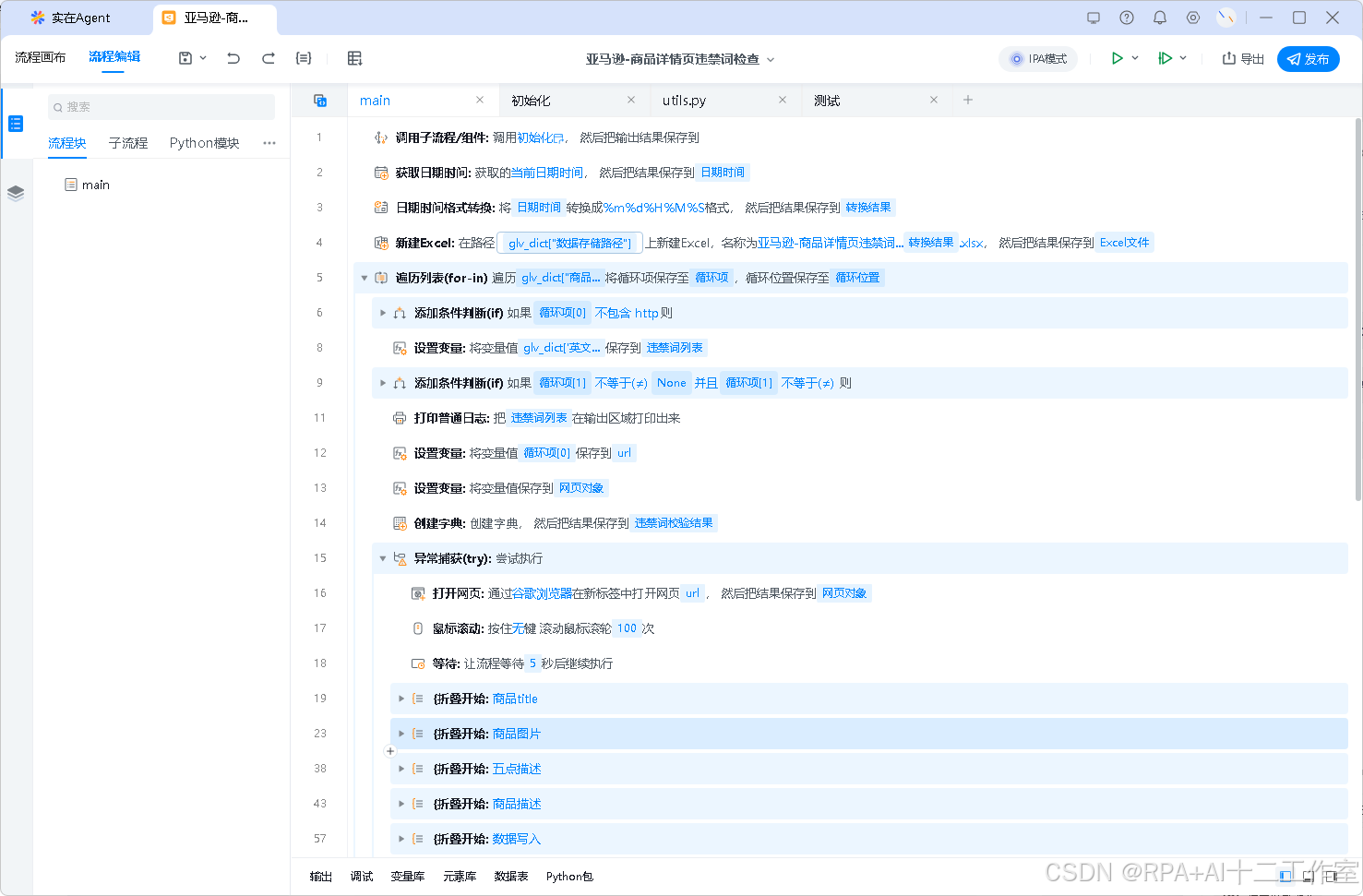
/
├── components_var_type.json
├── config.json
├── customConfig/
├── diaFile/
├── edit-state.json
├── elements.json
├── extensions/
├── fileList.json
├── file_index_700.json
├── file_sourcemap.json
├── globalVariable
├── log/
├── main.sz
├── process.template.json
├── project.flow
├── projects/
│ ├── child_modules/
│ │ ├── IB7A5.py
│ │ └── g6cCz.py
│ ├── code_modules/
│ │ └── utils.py
│ ├── dependency_modules/
│ ├── flow.py
│ ├── flow_modules/
│ │ └── io5cd.py
│ ├── global_data.py
│ ├── gpt_modules/
│ ├── old_custom_components/
│ ├── requirements.txt
│ └── rpaRoot.py
├── res/
├── szrpa.json
├── variableInfo
├── 商品图片/
└── 商品描述/
三、项目特点和核心代码
1. 自动化流程控制
项目使用流程队列管理任务执行,确保检查过程稳定可靠:
# projects/flow.py
FLOW_QUEUE = []
# 开始
def flow_node_hsxAW():
FLOW_QUEUE.append("flow_node_io5cd")
# 启动流程
def main(rpa):
flow_node_hsxAW()
while len(FLOW_QUEUE) > 0:
flowName = FLOW_QUEUE.pop(0)
eval(flowName + "()")
2. 核心检查逻辑
工具能够自动打开网页、提取信息并进行违禁词检查:
# projects/flow_modules/io5cd.py
for 循环位置,循环项 in get_list(globalVar['glv_dict']["商品链接列表"],0, 1,-1, version="1"):
if ("http" not in 循环项[0]):
continue
违禁词列表 = Basic.SetVariable(SZEnv['rpa'], globalVar['glv_dict']['英文默认违禁词库'], var_ret=0, var_names=["违禁词列表"])
url = Basic.SetVariable(SZEnv['rpa'], 循环项[0], var_ret=0, var_names=["url"])
网页对象 = WebBrowser.CreateV3(SZEnv['rpa'], "chrome", url, 0, "", "61619", "", 1, 1)
# 提取商品标题并检查
商品title = Element.GetElementInfo(SZEnv['rpa'], elementsFormatNew(SHIZAI_ELEMENT_DICT["cUVy16G8Sh"]["selector"]), 1, 网页对象, "gettext")
商品title违禁词 = run_module({ "module_path": "code_modules.utils" }, "check_forbidden_words", 商品title, 违禁词列表)
# 提取商品图片并检查
商品图片链接 = Element.GetElementInfo(SZEnv['rpa'], elementsFormatNew(SHIZAI_ELEMENT_DICT["LP8xJ6NRRf"]["selector"]), 1, 网页对象, "attr", 0, "data-a-dynamic-image")
# ...更多代码...
3. 违禁词检查算法
项目实现了智能违禁词检查函数,支持英文单词完全匹配:
# projects/code_modules/utils.py
def check_forbidden_words(text: str, forbidden_words: list) -> str:
"""
检查文本中是否包含违禁词
@param text: 文本
@param forbidden_words: 违禁词列表
@return: 违禁词列表
"""
hit_words = [item for item in forbidden_words if item in text]
def _check_english_word(word: str) -> bool:
# 如果命中的违禁词是英文单词,则需要判断完全匹配
if not re.match(r'^[a-zA-Z ]+$', word):
return True
return re.search(r'(^|[^a-zA-Z])' + re.escape(word) + r'($|[^a-zA-Z])', text)
return ",".join(filter(_check_english_word, hit_words))
四、适用场景
- 亚马逊卖家:检查自己的商品详情页是否包含亚马逊平台禁止的关键词,避免因违规导致商品下架或账号处罚。
- 跨境电商运营人员:批量检查多个商品链接,提高工作效率。
- 电商代运营公司:为客户提供合规性检查服务,确保所有上架商品符合平台规则。
- 商品内容审核人员:辅助人工审核,减少漏检和误检。
- 电商培训人员:作为教学工具,展示如何使用RPA技术进行合规性检查。
五、常见问题与建议
1. 网页加载超时
问题:网络不稳定时,网页加载可能超时导致检查失败。
建议:增加重试机制和等待时间,可在config.json中配置合适的延迟参数。
2. 违禁词误报
问题:某些英文单词可能因为是其他单词的一部分而被误报。
建议:使用提供的check_forbidden_words函数中的正则表达式匹配方法,确保英文单词完全匹配。
3. 图片文字识别不准确
问题:OCR识别图片中的文字可能存在误差,导致违禁词漏检或误检。
建议:优化图片下载质量,使用更高精度的OCR模型,或增加人工复核环节。
4. 商品链接格式错误
问题:输入的商品链接格式不正确,导致无法打开网页。
建议:在导入商品链接前进行格式校验,确保链接包含"http"或"https"。
六、源码下载
- 应用市场:可在实在智能RPA应用市场搜索"亚马逊-商品详情页违禁词检查"进行下载。
- 私聊:联系博主。
七、后续扩展方向
- AI增强:集成自然语言处理模型,提高违禁词识别准确率,支持语义分析和模糊匹配。
- 实时监控:开发定时任务功能,定期自动检查指定商品链接,发现问题及时通知用户。
- 报表生成:增加数据可视化功能,生成违禁词统计报表和趋势分析图表。
八、相关推荐
- 作者:RPA+AI十二工作室
- CSDN博客:RPA+AI十二工作室-CSDN博客
欢迎关注我的CSDN博客,获取更多RPA自动化开发技巧和项目源码。如有问题或合作意向,可私聊我。
版权声明:本文档内容仅供学习交流使用,未经作者允许,请勿用于商业用途。
如果觉得本文对你有帮助,欢迎分享给更多朋友,关注我的CSDN博

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 54
54 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)