[论文阅读] 人工智能 + 软件工程 | AI助力JSON Schema创建与映射:让非专家也能玩转结构化数据建模
本文介绍了一篇关于"AI辅助JSON Schema创建与映射"的论文。在很多领域,非专家难以创建标准化的数据模型(Schema),导致数据难以复用和分析;而纯LLM方法又存在可靠性等问题。论文提出的混合方案,通过LLM处理自然语言交互,结合确定性技术保证结果有效,集成在开源工具MetaConfigurator中。它支持用自然语言创建Schema,能自动转换JSON、CSV等异构数据,在化学领域的应
AI助力JSON Schema创建与映射:让非专家也能玩转结构化数据建模
论文:AI-assisted JSON Schema Creation and Mapping
arXiv:2508.05192
AI-assisted JSON Schema Creation and Mapping
Felix Neubauer, Jürgen Pleiss, Benjamin Uekermann
Comments: Accepted for Tools and Demonstrations Track of ACM/IEEE MODELS’25
Subjects: Software Engineering (cs.SE)
研究背景
想象一下,在化学实验室里,研究员们每天记录实验数据时,大多依赖电子笔记本或Excel表格。这些数据里藏着金属盐的用量、反应温度、产物纯度等关键信息,但它们就像杂乱堆放的零件——没有统一的"组装说明",其他研究员想复用这些数据时,得先花大量时间琢磨每个字段的含义;更麻烦的是,当需要用机器学习分析这些数据时,松散的结构会让算法"无从下手"。
这其实是很多领域的共性问题:模型驱动工程(MDE)强调用"模型"(通常以Schema形式呈现)来规范数据的结构和语义,有了它,数据验证、转换、可视化等工作才能高效开展。但现实是,多数科学领域缺乏标准化模型,非专家很难创建出合格的Schema。
有人想到用大语言模型(LLMs)帮忙,比如让ChatGPT把自然语言描述转成Schema。但这又带来新问题:LLM生成的内容可能无效,输出结果不好理解,处理复杂数据时容易"翻车",还得靠用户写精准的提示词才行。就像请了个天才助手,但它偶尔会犯低级错误,还不爱说清楚思路,让人又爱又恨。
主要作者及单位信息
- Felix Neubauer、Benjamin Uekermann,来自德国斯图加特大学并行与分布式系统研究所
- Jürgen Pleiss,来自德国斯图加特大学生物化学与技术生物化学研究所
创新点
这篇论文的核心亮点在于提出了一种"混合方案",就像给LLM配上了"安全气囊"和"导航系统",既发挥AI的灵活优势,又用确定性技术兜底:
- LLM与确定性技术结合:不再让LLM"单打独斗",通过预处理、后处理和规则执行机制,确保生成的Schema和映射规则可靠有效。
- 自然语言交互+可视化工具:非专家只需用日常语言描述需求(比如"创建一个记录MOF合成实验的Schema"),工具就能生成Schema并可视化展示,还支持直接修改。
- 映射规则"生成-执行"分离:用LLM生成数据转换规则,但用确定性方式执行,既利用了AI的创造力,又保证了大规模数据处理的稳定性。
研究方法和思路
1. AI辅助JSON Schema创建(像"智能填表向导")
- 步骤1:智能提示构建:工具自动给LLM"分配角色"(如"你是JSON Schema专家"),并把用户的自然语言描述转换成结构化提示,不用用户费心琢磨怎么跟AI沟通。
- 步骤2:精准上下文管理:处理大Schema时,只给LLM传输用户当前关注的部分,避免信息太多导致AI"分心"。
- 步骤3:即时验证与可视化:LLM生成内容后,工具立刻检查有效性,并用图形化界面展示,有问题一眼就能发现。
- 步骤4:人工纠错环节:如果AI输出不完美,用户可以直接手动修改,形成"AI生成+人类把关"的闭环。
2. AI辅助Schema映射(让不同格式数据"说同一种话")
- 步骤1:识别源数据结构:自动分析JSON、CSV、XML等输入数据,生成对应的源Schema。
- 步骤2:精简数据保留结构:如果数据太大,会智能截断数组和属性(比如数组最多留64项),同时保留完整的Schema信息,避免LLM"看不完"数据。
- 步骤3:生成转换规则:让LLM根据源数据和目标Schema,生成JSONata格式的映射规则(这是一种灵活的转换语言)。
- 步骤4:验证与执行:工具检查规则语法,用户确认后,用确定性方式执行转换,确保结果稳定可靠。
这些功能都集成在开源工具MetaConfigurator里,它原本就支持Schema可视化编辑、代码生成等功能,现在加上AI辅助,能力更全面了。
主要贡献
-
降低使用门槛:非专家不用学复杂的Schema语法,靠自然语言就能创建和修改数据模型,比如化学家能轻松把Excel里的实验数据转换成结构化JSON。
-
解决数据集成难题:支持JSON、CSV、XML、YAML等多种格式,自动生成转换规则,让分散在不同地方的数据能无缝对接。
-
兼顾灵活性与可靠性:用LLM处理自然语言和复杂映射,用确定性技术保证结果有效、可重复,就算处理大数据也不容易出错。
-
推动FAIR数据实践:让数据更易查找、访问、互操作和重用,为机器学习、知识图谱构建等下游工作打好基础。
-
一段话总结:本文提出了一种混合方法,将大型语言模型(LLMs) 与确定性技术相结合,用于JSON Schema的创建、修改和映射,并集成到开源工具MetaConfigurator中。该方法通过提示工程、上下文管理、验证可视化等手段,解决了纯LLM方法在模型有效性、可解释性等方面的局限,降低了非专家进行结构化数据建模和集成的门槛。同时,针对异构数据(JSON、CSV、XML、YAML),通过LLM生成映射规则并确定性执行,确保了数据集成的可靠性和可扩展性,其适用性在化学领域得到了验证。
- 思维导图:
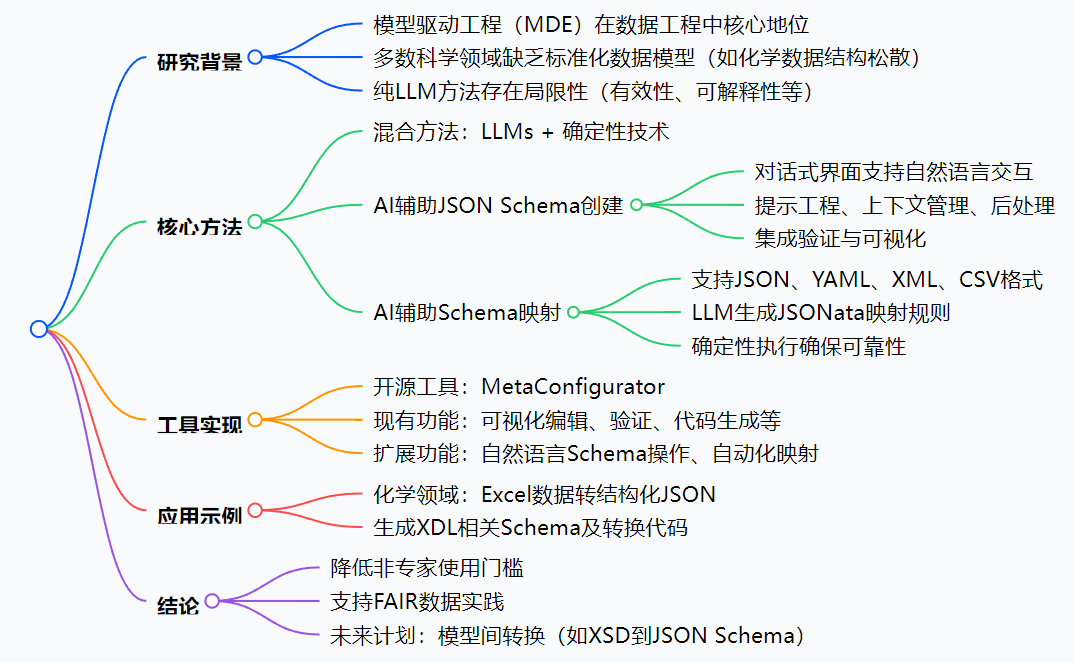
- 详细总结:
一、研究背景与动机
- 模型驱动工程(MDE)的重要性:MDE将模型置于系统和数据工程核心,研究数据中模型常以Schema形式定义数据集结构和语义,支持验证、转换、代码生成等关键功能,对数据质量、互操作性和可重用性至关重要。
- 现有问题:
- 多数科学领域(如化学)缺乏标准化数据模型,数据多存储于电子实验室笔记本(ELNs)或 spreadsheet,语义隐含而非显式结构化。
- CSV等格式局限于扁平结构,无法编码关系、约束等,限制互操作性和下游应用(如知识图谱构建)。
- 纯LLM方法存在局限:模型有效性无保证、输出可解释性低、处理复杂数据困难、依赖有效提示。
二、相关工作
| 类别 | 具体内容 |
|---|---|
| JSON及JSON Schema | JSON为广泛使用的数据格式,JSON Schema是描述其结构的事实标准,可作为建模语言 |
| JSON Schema创建工具 | 包括MetaConfigurator(开源、支持多格式、生成17种编程语言代码)、Adamant、Liquid Studio(付费),均需一定Schema知识 |
| Schema映射技术 | 现有工具(如Jolt、JSONata、jq)各有局限;自动化方法包括人工规则、传统算法及LLM辅助(需人机协作) |
| LLMs与提示工程 | LLMs可处理多种NLP任务,提示工程通过优化输入提升性能(如少样本学习、角色设定、任务拆分) |
三、设计与实现
-
AI辅助JSON Schema创建:
- 功能:通过对话式界面支持自然语言创建、修改和查询Schema。
- 关键技术:
- 提示工程:动态构建结构化提示(设定LLM角色、包含用户描述、指定输出格式)。
- 上下文管理:仅传输用户选择的子Schema,避免大Schema导致的LLM不准确。
- 后处理与验证:自动清理LLM输出(如移除代码围栏),生成Schema即时验证并可视化。
- 人机协作:允许用户手动修正LLM输出。
-
AI辅助Schema映射与数据集成:
- 支持格式:JSON、YAML、XML、CSV(CSV需转换为JSON)。
- 映射语言:采用JSONata,支持复杂逻辑(如运算符、聚合、函数等)。
- 流程:
- 为输入数据推断源Schema(使用jsonhero/schema-infer库)。
- 构建提示:包含映射指令、示例、用户输入及源Schema。
- 数据 truncation:递归截断数组和属性以控制大小(目标64KB),同时保留结构。
- 后处理与验证:清理LLM生成的JSONata规则,自动验证语法正确性,支持用户手动调整。
- 可靠性保障:映射规则生成与执行分离,确定性执行确保大规模数据处理的可靠性和可扩展性。
-
工具实现:基于开源工具MetaConfigurator扩展,该工具原支持可视化编辑、验证、代码/文档/表单生成,扩展后新增自然语言交互功能,LLM调用采用OpenAI API,使用gpt-4o-mini模型(平衡成本与性能)。
四、应用示例(化学领域)
- Excel数据转换:化学家的合成实验数据从Excel表格转换为JSON,自动推断的初始Schema存在缺陷(如product_purity为string而非boolean, ligand和metal_salt未独立成类),通过工具优化Schema并自动映射,得到结构化、AI就绪的数据。
- XDL相关应用:XDL 2.0缺乏正式Schema,通过工具导入XDL文档生成Schema,因结构差异无法直接映射,利用代码生成功能生成Python类及转换代码,为实验室机器人自动执行合成实验奠定基础。
五、结论与未来计划
- 成果:混合方法结合自然语言交互与确定性保障,显著降低非专家使用结构化数据建模和集成的门槛,支持FAIR(可查找、可访问、互操作、可重用)数据实践。
- 工具扩展功能:除Schema编辑和转换,还支持实例
总结
本文提出了一种结合大语言模型(LLMs)和确定性技术的混合方法,用于JSON Schema的创建、修改和映射,并将其集成到开源工具MetaConfigurator中。该方法通过提示工程、上下文管理、可视化验证等机制,解决了纯LLM方法在可靠性、可解释性上的不足;同时,通过"生成-执行分离"的映射策略,实现了异构数据的高效集成。
在化学领域的应用显示,它能把Excel中的实验数据转换成结构化、AI友好的数据格式,甚至能辅助生成化学实验标准语言XDL的Schema。这项研究显著降低了非专家使用结构化数据建模的门槛,为跨领域数据共享和复用提供了有力工具。
解决的主要问题:科学领域标准化数据模型缺乏、非专家难以创建Schema、异构数据集成复杂。
主要成果:构建了LLM与确定性技术结合的混合方法,扩展了MetaConfigurator的AI辅助功能,在化学领域验证了实用性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献116条内容
已为社区贡献116条内容

所有评论(0)