【Datawhale AI 夏令营】2025多模态RAG方向 - Task2 理解赛题重难点(用AI辅助理解!)
本文是DataWhale和科大讯飞AI夏令营多模态RAG方向的Task2学习笔记,<让AI读懂财报>赛题的重难点与实现方案。赛题要求构建能同时理解图文混排PDF的系统,解决多模态信息理解、跨模态检索、图文关联推理等核心问题。文章详细解读了输入输出格式、评分标准,并深入分析了PDF处理、多模态融合、检索优化、答案生成等关键技术挑战。最后简要介绍了Baseline方案的执行流程,包括预处理、检索和问答
本系列是参与DataWhale和科大讯飞合办的 AI夏令营【多模态RAG方向】的记录贴。根据夏令营课程安排,共分4个章节进行内容与我的学习笔记记录。 感谢DataWhale和科大讯飞~
序言:学习者手册 —— 了解项目
Task1:跑通Baseline,体验「让AI读懂财报PDF」
Task2:学习「让AI读懂财报PDF」的重难点 – 本篇
Task3:学习并实践更多进阶要点和思路
本文是Task2内容记录。 本次任务目标:
- 理解项目要求,从业务到实现。

TASK2、理解赛题重难点
1. 赛题原文
大赛地址:多模态RAG图文问答挑战赛
1.1 赛题背景
- 在信息爆炸的时代,人们获取知识的方式不再局限于纯文本,大量的信息存在于图文混排的文档、网页、报告甚至图片库中。传统的问答系统大多是基于纯文本的,难以有效处理需要结合图像内容进行推理的复杂问题。例如,用户可能想知道“这张图片里,左边那个设备的功能是什么?”或“根据图表显示,产品A的销售额在哪个季度开始下降?”。要回答这类问题,模型不仅需要理解自然语言问题,还需要“看懂”图像,并将两者关联起来进行推理。
1.2 赛题任务
1) 赛题任务
比赛将提供一个包含多个图文混排PDF文档的知识库,以及一系列包含文本和图像依赖性问题的测试查询。评估指标将侧重于答案的准确性、完整性、信息关联性以及可解释性(即是否能指明信息来源)。
参赛系统需要完成以下任务:
- 1)多模态信息理解:能够同时理解用户提出的自然语言问题以及知识库中的图像和文本内容。
- 2)跨模态检索:从给定的多个PDF文档中,高效地检索与用户查询相关的图像、图表、文本段落或它们的组合。
- 3)图文关联推理:将检索到的图像信息与文本信息进行有效关联和融合,进行深层次的逻辑推理,以回答需要多模态理解的问题。
- 4)答案生成:基于检索和推理的结果,生成准确、简洁、符合上下文的答案。答案中应清晰指出信息来源(例如,来自哪个PDF的哪一页,甚至哪个图表)。
2)赛题提供如下文件
- train.json为训练集
- test.json为测试集,其中每个提问的page、filename和answer需要选手预测
- 财报数据库.zip为财报PDF库
- sample_submit.json为提交格式
3).评审规则 该评分函数主要从三个方面对每个问题的回答进行评估,每个提问并计算一个综合分数: (满分0.5分):将字符交集大小除以并集大小,得到 Jaccard 相似系数,范围在 0 到 1 之间。
- a.页面匹配度(满分0.25 分)
- b.文件名匹配度(满分0.25 分)
- c.答案内容相似度
2. 赛题分析
- 任务核心: 需要建立能看懂图片+读懂文字的AI助手,应对真实世界中复杂的图文混排信息。 通过多个财报PDF,
2.1. 输入与输出解读
官方提供的材料
Input(输入文件)
比赛官方提供了3种材料。
1)财报数据库.zip
压缩包。解压可以看到包含100多个pdf文件,这些都是真实的公司财报,并且内容是比较复杂的 图文混排,不仅包含文字、数据表格、页眉页脚、以及各类图标(如柱状图、折线图、饼图等等)。
我们的所有答案都必须从这些pdf文件中寻找。
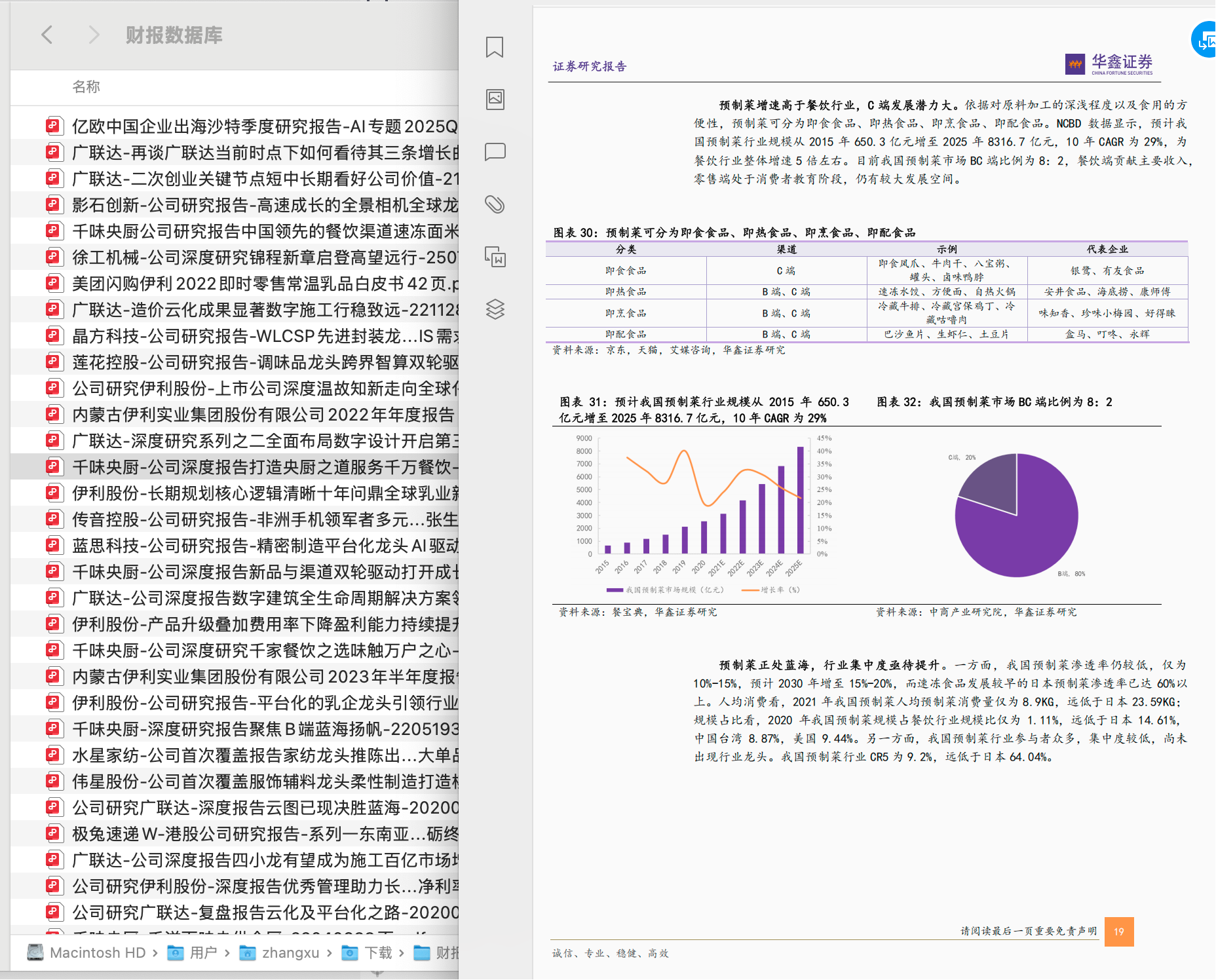
2) train.json - 训练集
JSON文件,提供“问题-答案”的示例。这是在开发过程中我们训练和验证的主要依据。
训练集提供了100多条示例数据。
[
{
"filename": "联邦制药-港股公司研究报告-创新突破三靶点战略联姻诺和诺德-25071225页.pdf",
"page": 4,
"question": "根据联邦制药(03933.HK)的公司发展历程,请简述其在2023年的重大产品临床进展。",
"answer": "根据联邦制药(03933.HK)的公司发展历程,2023年的重大产品临床进展如下:\n\n- **重磅产品临床**:\n - UBT251多个适应症进入临床阶段;\n - 司美格鲁肽注射液体重管理适应症获临床受理;\n - 利拉鲁肽注射液BLA;德谷胰岛素利拉鲁肽注射液获批临床。"
},
// ···
]
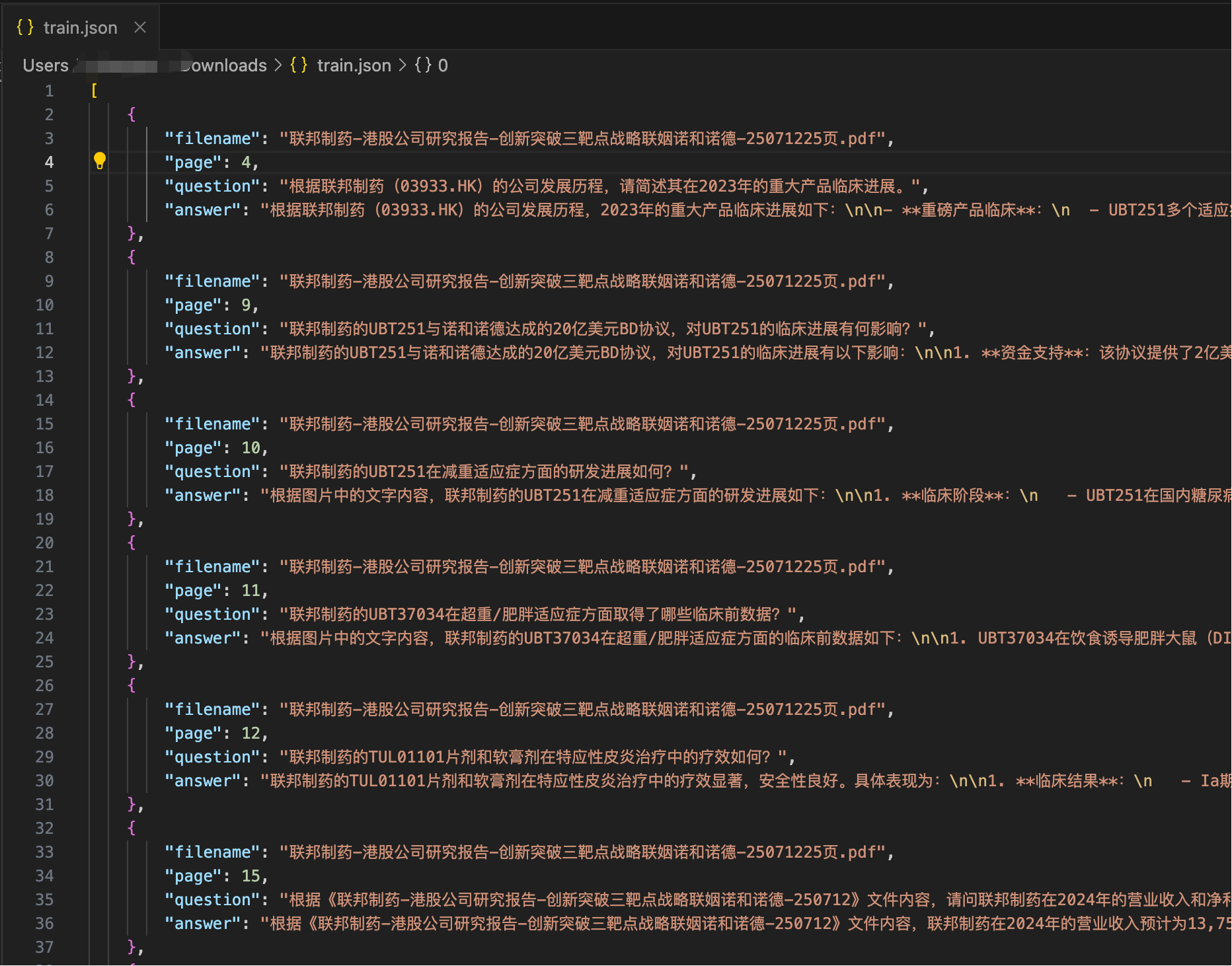
3) test.json
JSON文件。 包含的用于测试的问题。 只包含question字段,而answer、filename、page都是需要经过我们开发让大模型找到的。
[
{
"filename": "xx.pdf",
"page": 1,
"question": "广联达在苏中建设集团南宁龙湖春江天越项目中,具体运用了哪些BIM技术,并取得了哪些成果?",
"answer": "广联达在苏中建设集团南宁龙湖春江天越项目中,具体运用了哪些BIM技术,并取得了哪些成果?"
},
// ...
Output(输入文件)
根据赛题要求,我们需要提交一个json文件。这个json文件就是基于test.json中的每个问题,经过大模型解读预测后,填写了answer、filename、page字段后的数据。
- 官方提交文件示例
打开文件我们会发现,提交文件示例,和test.json文件一模一样。
此时我们的任务就非常明确了:我们需要生成一些结构化的核心数据,可以通过大模型搜索,获取答案、文件名、页码信息。
示例数据样式:
[
{
"content": "LLM可理解和搜索的内容文本描述信息, 并且经过向量化",
// 辅助获取对应文件夹和页码
"datasource":{
"filename": "来源文件名.pdf",
"page": 页码数字
}
}
]
2.2. 赛题重点
1) PDF文件处理
任务: 结构化提取图文混排pdf内容,有2个方案:
- pymupdf:基于规则的方式提取pdf里面的数据
- mineru:基于深度学习模型通过把PDF内的页面看成是图片进行各种检测,识别的方式提取。
考虑硬件资源,task1使用了pymupdf作为示例, 在后续会对mineru做介绍 |
2) 多模态信息的有效融合
说明: 一个问题的答案,需要同时依赖文字描述和图片/图表/表格。 (如,“xxx如下图所示”,“在表格xxx中提到的”)
挑战 : 检索模块需要足够智能,可以根据文本问题,同时召回相关的文本和图像信息。
- 要让系统理解跨模态的指代和依赖
- 不能将文本、图片、图片描述等作为单独知识来检索, 这样会丢失他们之间的关联性。
方案选择:
| 多模态方案 | 说明 | 特点 |
|---|---|---|
| 基于图片描述 | 对所有图片生成文本描述,将这些描述与原文的文本块统一处理 | 能将多模态问题简化为纯文本问题,最适合快速构建Baseline。 |
| 多模态分别嵌入 | 对文本和图片分别进行向量化,检索时结合文本和图片的相似度。 | 更精确,但实现也更复杂,而且召回图片与召回文本存在不相关情况,也需要比较多的处理。 |
| 多模态大模型端到端处理 | 将检索到的文本和原始图片一起交给多模态大模型(如Qwen-VL)进行端到端理解和生成 | 最前沿的方案,但也最消耗资源,因为一般的多模态模型推理能力要稍微差一些。 |
本方案选择1.
3)检索的准确性与召回率平衡
检索是后续工作的基础,如果检索出的结果里没有答案,那么后面的大模型无论如何也得不到正确答案。 (巧妇难为无米之炊。。。)
挑战:
- 语义模糊性: 不同报告、不同提问方式千差万别,而用户的文法与文档中的描写,措辞差异更大。 这对模型的语义理解能力有很大要求。
- 信息干扰:检索返回的结果中,如果存在过多无用信息(噪音),会严重感干扰大模型的判断。 因此优化检索策略(如重排技术),提高信噪比也是核心问题。
4) 答案生成的可控性与溯源精确性
大模型在生成答案时,有时会出现幻觉(hallucination),编造上下文中不存在的信息。(比如之前爆火的乱说西游···)。 同时,他也可能错误引用。
挑战:
- 忠诚度: 设计prompt强力约束LLM,使回答严格基于上下文,减少信息捏造。
- 溯源: 精心设计上下文格式和prompt指令, 使LLM精准定义关键信息的来源,并且能正确的输出到引用里。
5) 针对性评估指标的优化
根据任务要求, 评分由 文件名匹配度(0.25) + 页面匹配度(0.25)+答案内容相似度(0.5)组成。
也就是说,即使内容正确,但引用来源如果错误,那得分仍旧很低。 而即使答案错误,引用和来源正确也能得分。
挑战:
- 答案不能只关注文本之类, 溯源准确性同样重要。
6) 向量化方案
- Xinference: 将模型部署为服务,并通过兼容OpenAI的API来调用。服务化能让我们的Embedding模块与主应用逻辑解耦,更利于调试和未来的扩展。
3. BaseLine方案解读
3.1 Baseline执行流程
1. 预处理(离线完成)
- 批量解析pdf,得到结构化json数据
- 构造核心结构数据( "content"和"datasource"的数据结构)
- 调用Xinference,将文本转为向量
- 存入向量数据库,完成知识库构建
2. 在线推理 :
- 接收测试集的json文件中的一个 question 。
- 调用 Xinference 服务,将 question 向量化。-
- 在向量数据库中进行相似度搜索,召回Top-K个最相关的内容块。
- 将召回的内容块及其元数据,与 question 一同填入设计好的Prompt模板中。
- 将完整的Prompt交给一个大语言模型(LLM),生成最终的答案和来源信息。
3.2 BaseLine代码结构解析 (AI辅助版)
1)让AI帮忙梳理项目 – BaseLine 解读
在task1中,我们是通过阿里魔搭的线上notebook环境运行的代码。 这次我把代码拉取到了本地,并让Cursor帮我梳理了一下代码。
这是个很重要的技能哦,强烈建议编程,特别是学习编程的小伙伴们试试,下载的代码,示例,教程,都可以打开AI,请AI来梳理,功能清单、项目架构、业务流程、数据流向、组件关系,都可以让AI帮忙梳理。
我使用的是CurSor的自动模式,你可以通过任何AI代码编辑器来要求它生成, 可以制定生成mermaid流程图,更便于理解!。
我首先让AI为我解析了BaseLine代码块,可以看出解读的很细致,而且清晰易懂: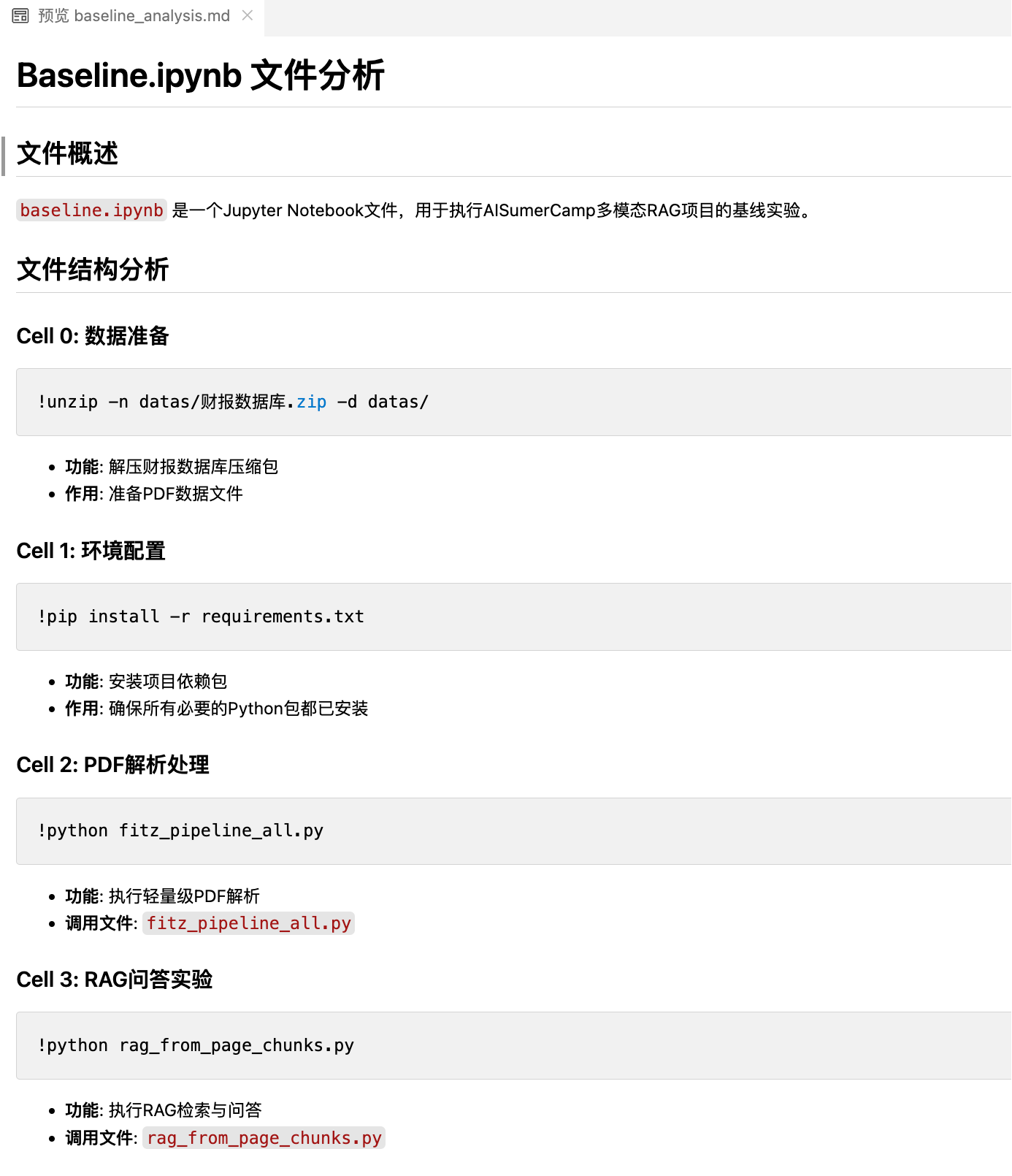
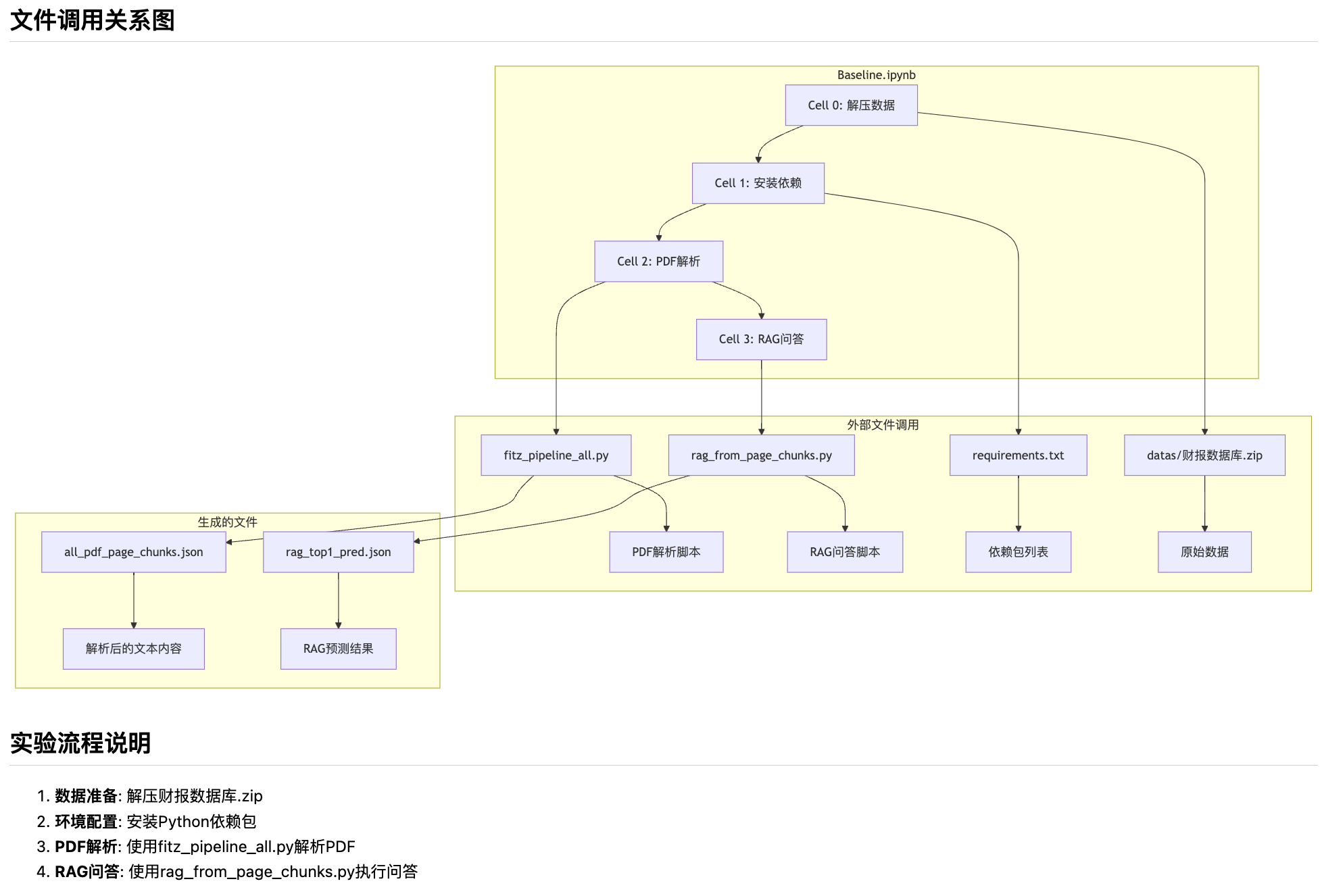
2)fitz_pipeline_all.py-- 解析pdf生成格式化数据集
可以看到baseline安装完依赖后,首先执行了这个文件,该文件调用外部pymupdf来解析所有的pdf文件,并最后生成符合我们预期的数据结构类型的知识文件。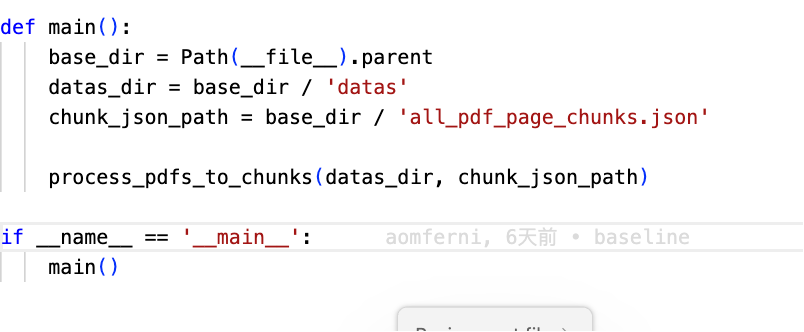
功能流程
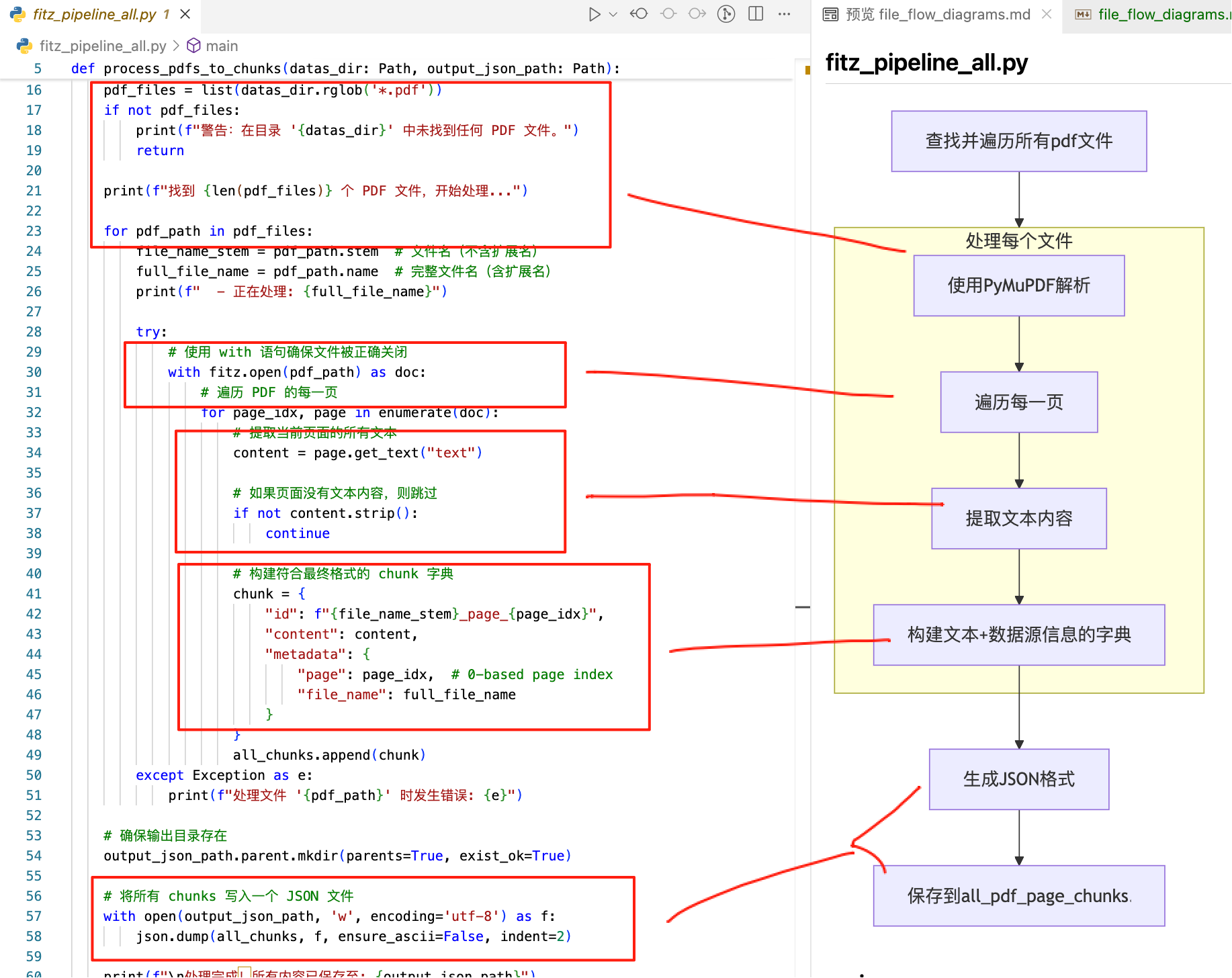
生成的文件
打开生成后的文件all_pdf_page_chunks.json, 可以看到生成了4000多个 “文件名+页码” 与文件内容的结构化数据。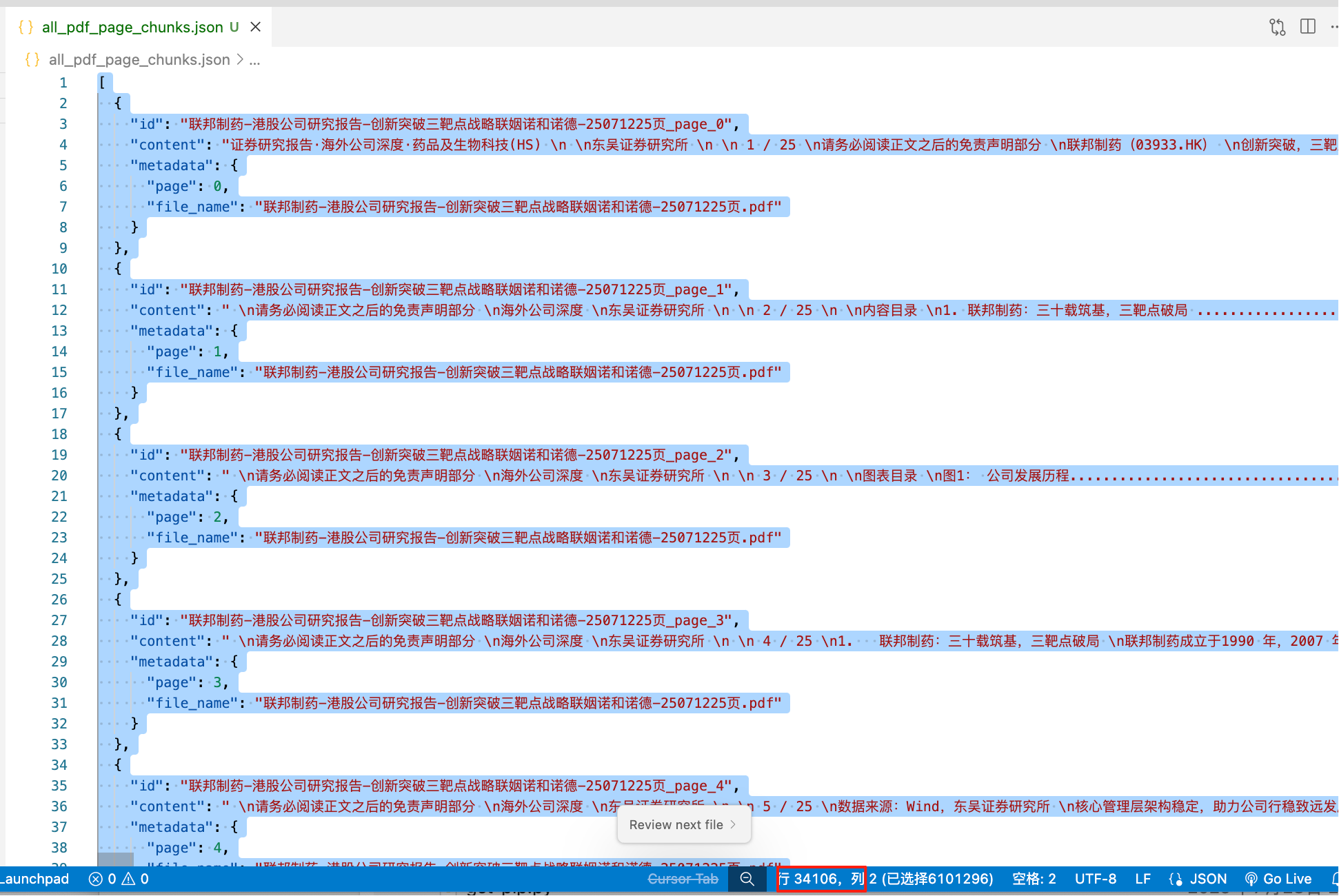
3)rag_from_page_chunks.py 处理数据集建立向量索引
AI解读文件概述
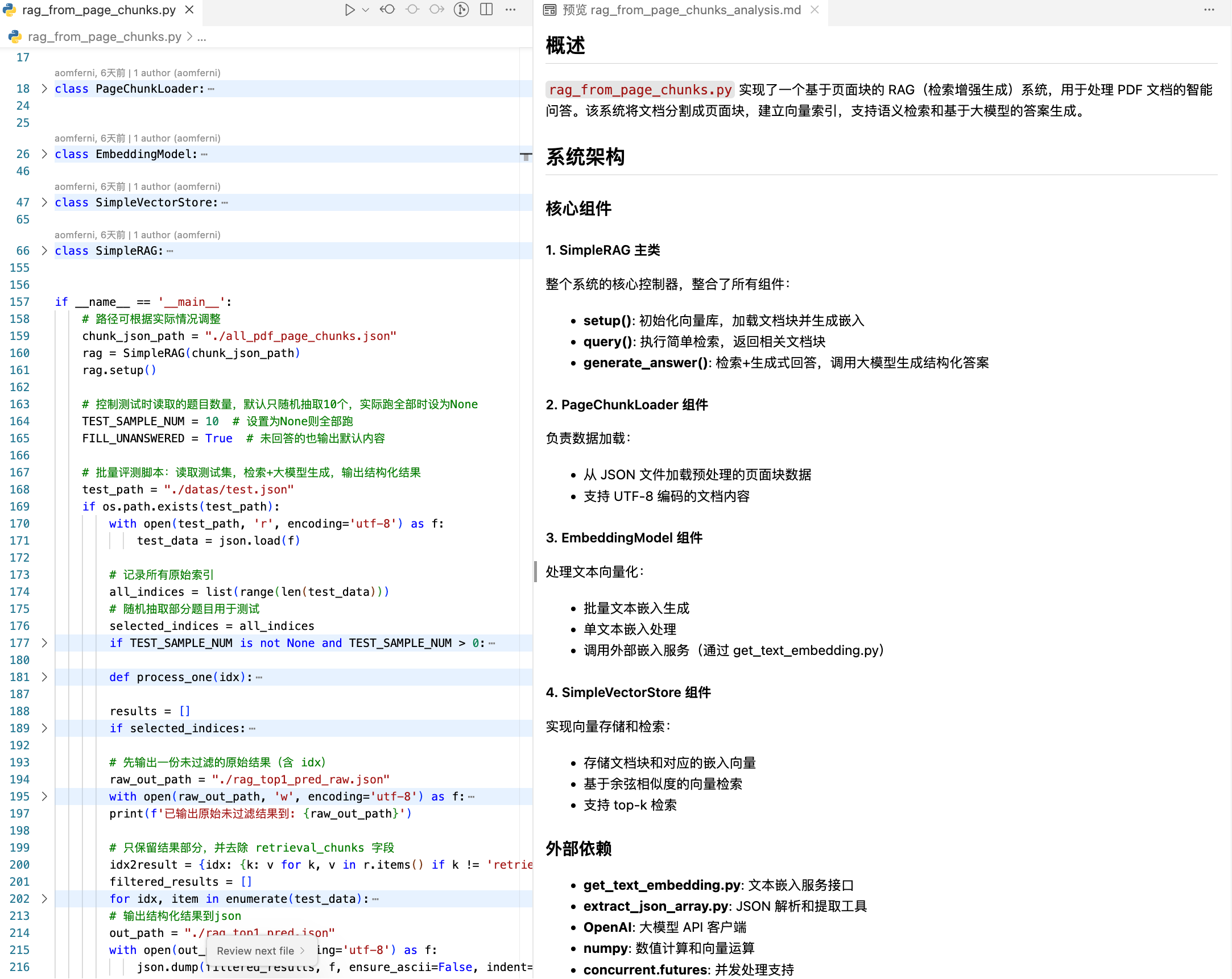
主程序main流程(这部分ai生成太复杂了,我做了修改)
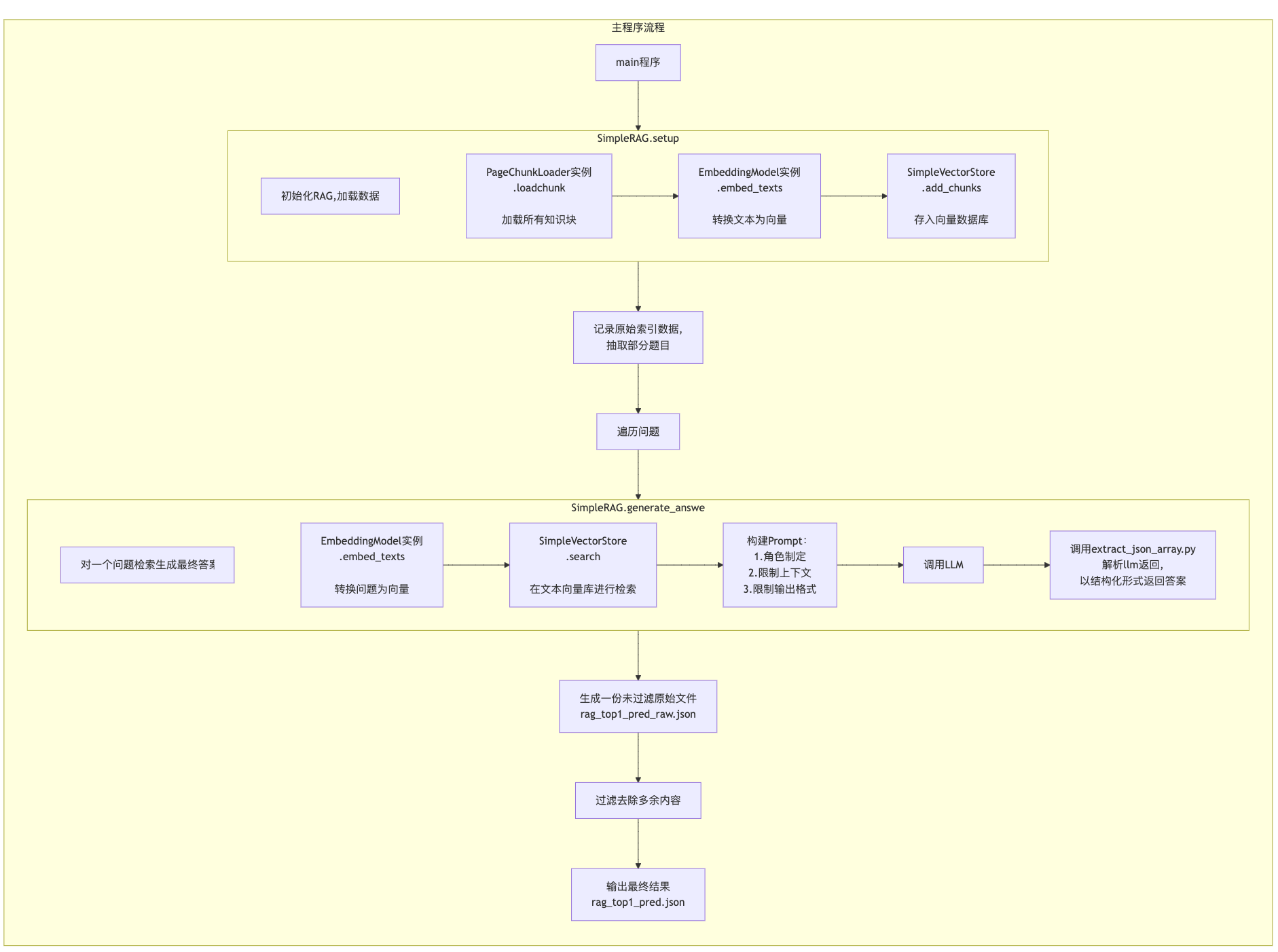
3.3 AI梳理的调用关系与项目架构
下面附上我用AI生成的其他解读
1)项目整体架构
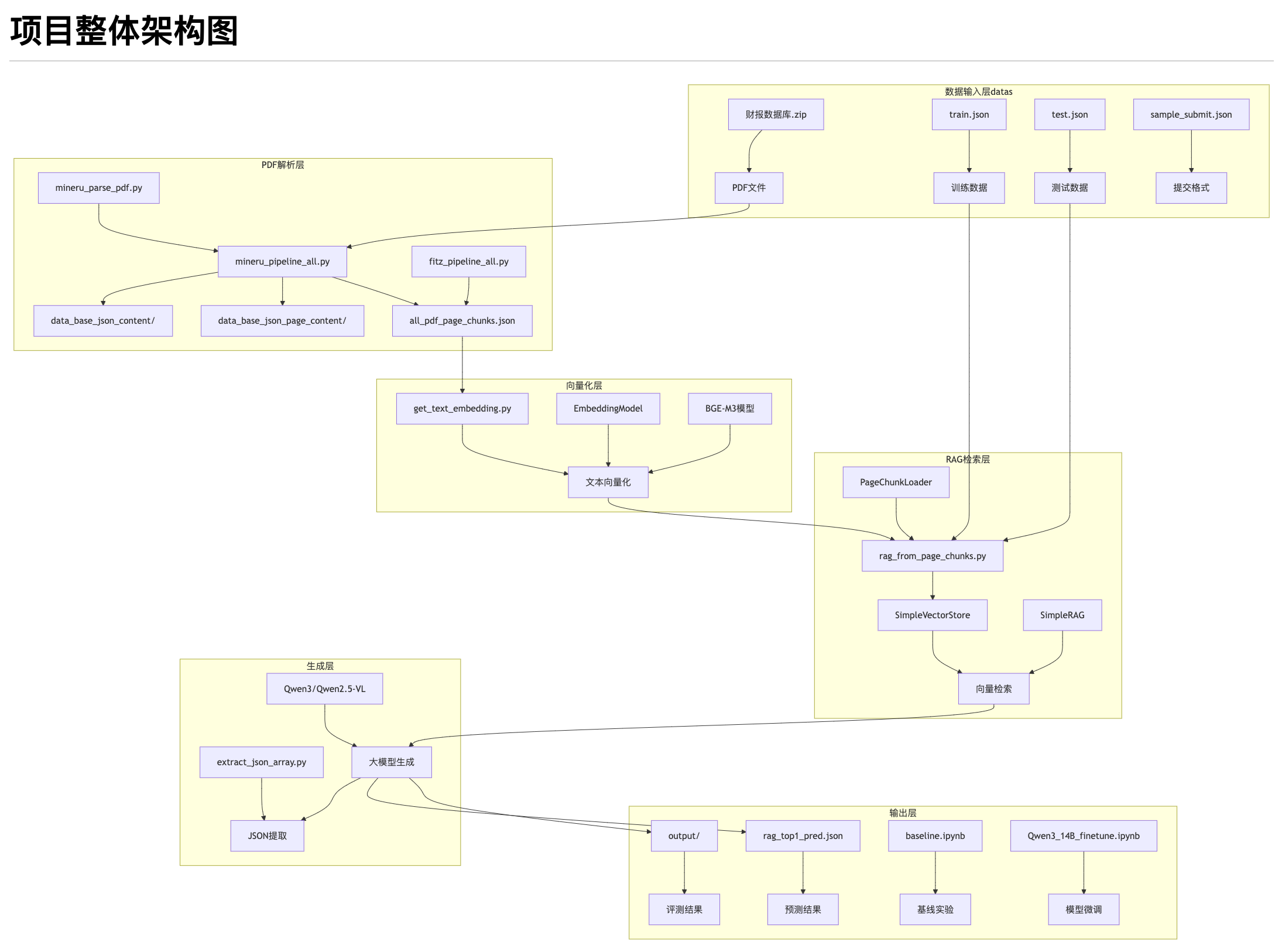
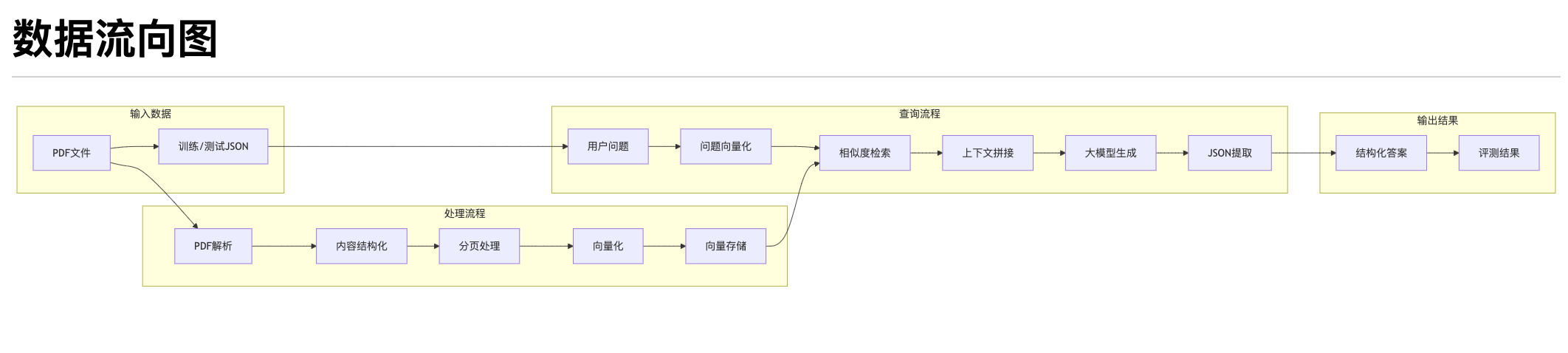
2)数据流向
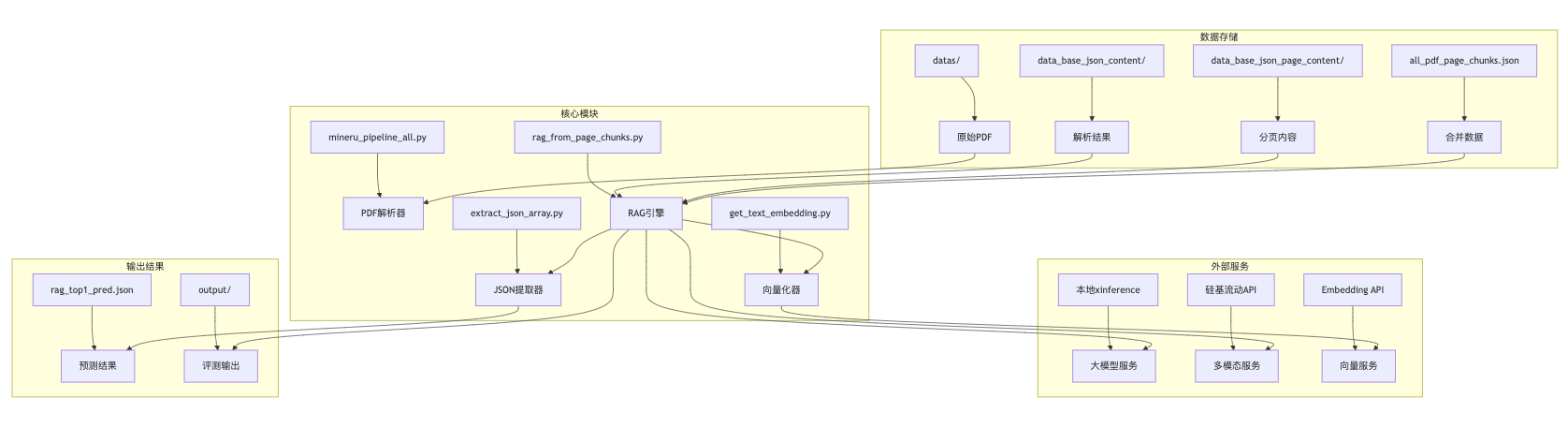
3)组件关系
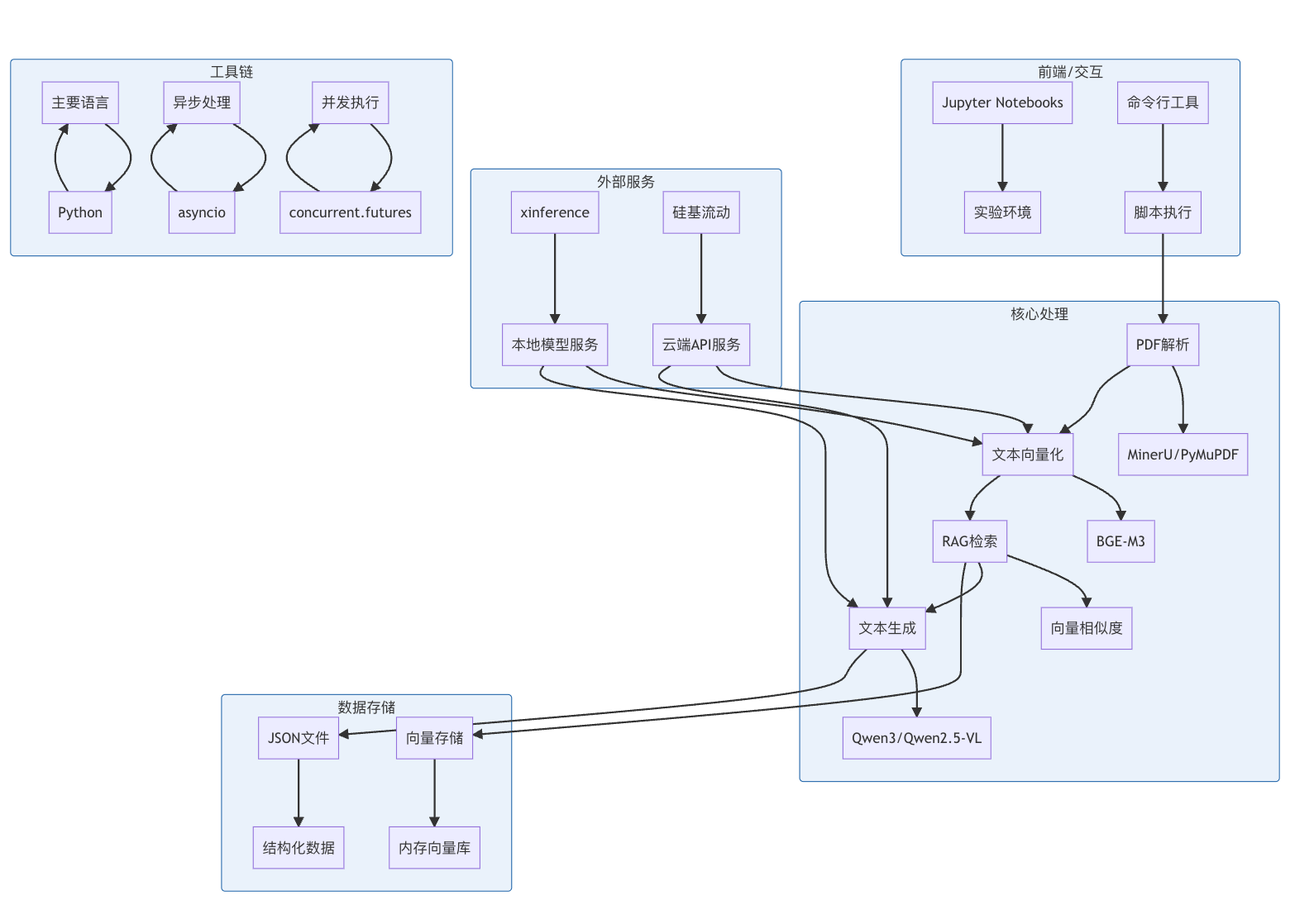
4)技术栈架构
附录:知识点与参考资料
知识点
RAG (Retrieval-Augmented Generation) : 检索增强生成。它是一种将外部知识库的检索能力与大语言模型的生成能力相结合的技术框架。其核心思想是,当LLM需要回答问题时,不直接让它凭空回答,而是先从一个庞大的知识库(如我们处理好的PDF内容)中检索出最相关的几段信息,然后将这些信息连同问题一起交给LLM,让它“参考”这些材料来生成答案。这极大地提高了答案的准确性、时效性,并解决了LLM的“幻觉”问题。
向量嵌入 (Vector Embeddings) : 这是让计算机理解文本语义的桥梁。Embedding模型(如本方案中的BGE-M3)可以将一段文本(一个词、一句话、一个段落)映射到一个高维的数学向量(比如一个包含1024个数字的列表)。在向量空间中,语义上相近的文本,其对应的向量在空间位置上也更接近。
向量数据库 (Vector Database) : 一个专门用于存储和高效查询海量向量的数据库。当我们把所有知识块都转换成向量后,就需要一个地方来存放它们。当一个新问题到来时,我们将其也转换为向量,然后去向量数据库中进行“相似度搜索”,快速找到与之最“近”的那些知识向量,从而实现语义检索。本Baseline为了简化,用一个内存列表( SimpleVectorStore )模拟了向量数据库的功能。
参考资料
| PDF文档解析 | MinerU | 功能强大的文档解析工具,能将PDF精准地转换为结构化的Markdown或JSON。 |
| PDF文档解析 | PyMuPDF | 一个高性能的Python PDF处理库。 |
| 模型部署与服务化 | Xinference | 一个强大的开源推理框架,能将各种大模型(包括文本、嵌入和多模态模型)部署为服务,并提供兼容OpenAI的API接口。 |
| 文本/多模态向量化模型 | FlagEmbedding (BGE模型) | 领先的中文文本向量化模型库。 |
| 文本/多模态向量化模型 | CLIP (Hugging Face实现) | 经典且强大的图文多模态向量化模型。 |
| 文本/多模态向量化模型 | 通义千问Qwen-VL (多模态) | 阿里巴巴开源的性能强大的多模态对话语言模型。 |
| 向量数据库与检索 | ChromaDB | 一个简单易用的开源向量数据库。 |
| 向量数据库与检索 | FAISS | 由Facebook AI Research开发的高性能向量检索引擎。 |
| RAG开发框架 | LlamaIndex | 一个主流的、用于构建和开发RAG应用的集成化框架。 |
| OCR | PaddleOCR | 强大的中文OCR工具库。 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)