Creating Hardware Component Knowledge Bases with Training Data Generation and Multi-task Learning
本文提出了一种基于机器学习的方法,用于从硬件数据手册中自动构建组件数据库。传统人工创建数据库的方式耗时费力且容易出错。该方法通过结合多模态数据模型、弱监督、数据增强和多任务学习技术,有效解决了硬件数据手册中的三大挑战:关系型数据结构、专业术语使用以及PDF格式的复杂性。实验结果表明,该方法在三种硬件组件上平均达到77的F1分数,质量与人工创建的数据库相当。研究还展示了该方法如何显著改善硬件组件的选
硬件组件数据库[Hardware component databases]是设计嵌入式系统的重要资源。由于创建这些数据库需要数十万小时的人工数据录入,它们通常是专有的,提供的数据有限,并且存在随机的数据录入错误。我们提出了一种基于机器学习的方法,直接从数据手册中创建硬件组件数据库。
直接从数据手册[datasheets]中提取数据具有挑战性,原因如下:(1) 数据本质上是关系型的,并依赖于非局部上下文[non-local context];(2) 文档中充斥着技术术语[technical jargon];(3) 数据手册是PDF格式,这种格式将视觉上的局部性与文档中的局部性分离。
传统上,解决这种复杂性依赖于人工输入,这使得扩展成本高昂。我们的方法利用丰富的数据模型、弱监督、数据增强和多任务学习,在短短几天内创建这些知识库。我们在三类组件的数据手册上评估了该方法,平均获得了77的F1分数——其质量与现有人工策划的知识库相当。
我们进行了应用研究,展示了包括数值属性和图像在内的多种数据模态的提取。我们展示了不同来源的监督(例如启发式规则和人工标签)各自具有独特的优势,这些优势可以共同利用以提高知识库的质量。最后,我们通过一个案例研究展示了这种方法如何改变从业者创建硬件组件知识库的方式。
1 INTRODUCTION
创建嵌入式系统通常需要开发新的硬件。寻找最符合系统需求的组件占据了设计时间的很大一部分。下载数据手册很容易,但弄清楚应该下载哪个数据手册却很难。通常,所需信息隐藏在数据手册本身中,而数据手册是一种复杂的文档,标准搜索引擎无法解析。需求通常是多维且定量的,因此选择合适的组件需要考虑多个属性的范围,比如电压增益,以及非文本信息,如封装响应图[packaging response graphs]。
通常,一个组件有许多(比如数千个)不同版本,它们功能等效,但在成本、能耗或尺寸上存在差异。如今,硬件工程师通过访问许多不同的网络搜索引擎[web search engines]来进行组件搜索,仔细调整每个搜索引擎的参数以获得少量(不是零,也不是数百个)结果,然后手动汇总这些结果,再查看单个数据手册以获取这些搜索引擎无法提供的信息。这种繁琐的过程意味着设计硬件需要在头脑中建立一个组件库,而这个库是通过深厚的经验积累而成的。
如果没有这种经验,硬件设计仍然是一个巨大的挑战:创客论坛上有详细讨论如何选择合适的晶体管[the right transistor] [36],甚至整篇研究论文都依赖于仔细的组件选择 [17]。硬件组件选择的挑战与选择优秀软件库的轻松形成了鲜明对比。
软件库信息易于获取和搜索:搜索可以轻松找到诸如网络服务器、图形处理或数据分析等易于使用的库。由于搜索是基于文本的,因此可以通过爬取文档、包描述或社区论坛(如 Stack Overflow)轻松得到答案。任何给定的搜索通常只为特定目的返回少量维护良好的库;不会有数百个类似于 matplotlib 的绘图包,也不会有数百个类似于 libssl 的安全套接字库。
硬件组件数据库是硬件开发者的宝贵工具。如图 1 所示,应用程序和工具可以使用这些知识库来交叉验证现有数据库,以回答诸如“我应该使用哪些运算放大器来构建这个增益电路”之类的问题,甚至可以查询非文本数据,如产品缩略图。
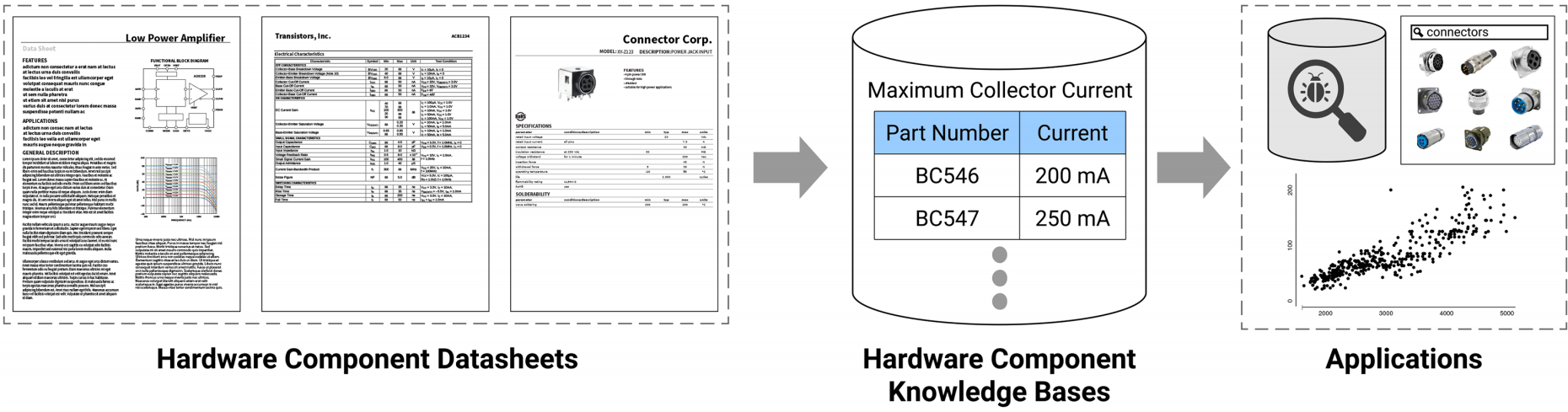
图1.硬件组件知识库由数据表填充,可提供有价值的应用,例如交叉验证、根据最佳电气特性选择组件或构建丰富的搜索界面。
诸如 Digi-Key、Mouser 和 Parts.io 等服务通过构建专有数据库来帮助硬件开发者;它们提供组件搜索页面,这些页面推动了数十亿美元的销售 [11]。然而,这些数据库通常是通过人工创建的。具有足够技术专长以理解数据手册的人(例如,在特定情况下 VCC 和 VDD 是否可以互换)手动输入数据。然而,人工数据录入容易产生随机错误以及基于个人偏见的错误 [14]。此外,这些数据库是不完整的。
数据录入的成本导致数据库仅包含可用信息的一个有限子集(例如,单个数据手册[a single datasheet]中几十个特性中的几个)。
1.1 Learning to Construct Component Databases
本文提出通过使用最先进的机器学习技术从数据手册中创建数据库,从而使硬件组件信息既易于获取又经济实惠。这个问题需要机器学习,因为数据手册是复杂且格式丰富的文档,它们依赖许多隐含的信号和结构来传达信息。解决数据手册的复杂性传统上需要人工手动干预。
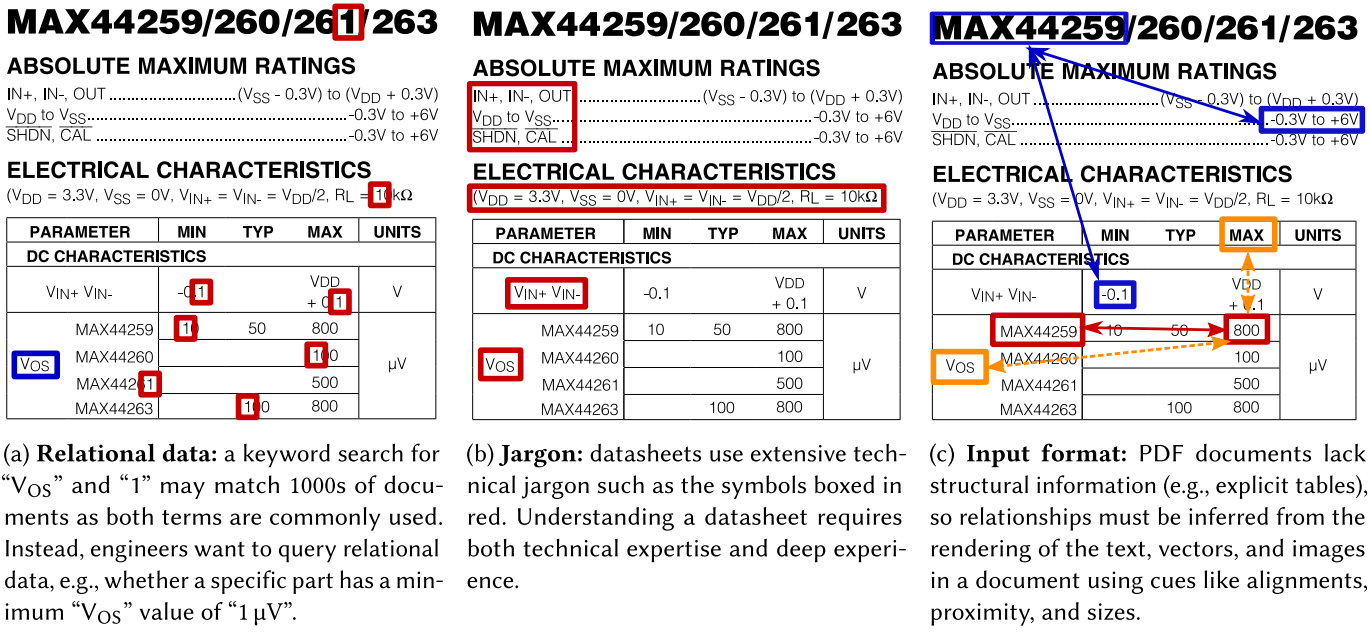
图2.一个突出显示从PDF数据表中提取信息的挑战的示例文档。
从数据手册中提取信息受到三个主要挑战的复杂影响:关系型数据、术语以及输入格式。图 2 展示了从一个示例数据手册中提取的这些挑战的例子。首先,硬件组件信息本质上是关系型的[relational]。以用户想要搜索各种电气特性的定量值的情况为例(图 2(a))。
这类查询使得传统搜索工具无效,因为仅靠基于文本的搜索无法充分表达这些复杂的关系。此外,关键词搜索通常会匹配到数千个文档。其次,数据手册以多种方式使用技术细节和术语来描述组件(见图 2(b))。提取它们的数据需要在学习系统中捕捉这一领域知识,并排除了依赖未经训练的众包服务[untrained crowdsourcing services](如 Amazon Mechanical Turk)的可能性。
第三,数据手册以便携式文档格式(PDF)分发,而不同供应商在如何使用文本、结构、表格和视觉提示来展示数据方面存在显著差异(图 2(c))。这些提示对人类来说是可以理解的,但对机器来说却难以解读。此外,这些提示的多样性和不统一性使得仅仅依靠启发式规则无法准确地处理它们。
1.2 Proposed Approach
我们提出了一种构建硬件组件知识库[hardware component knowledge bases]的方法。我们的方法通过将数千份多种类型组件的PDF数据手册[PDF datasheets]作为输入进行读取,并以填充关系型数据库[populates relational databases]作为输出,从而构建硬件组件知识库。
我们使用了三种机器学习技术来解决硬件数据手册的挑战。首先,我们没有将输入建模为非结构化文本,而是使用了一个丰富的数据模型,该模型能够捕捉PDF文档中提供的多种信息模态[the multiple modalities of information]。这使得我们能够基于文本、结构和视觉信息来编码特征。其次,我们采用系统化的训练数据生成方式,即通过弱监督和数据增强,将领域知识高效地转化为训练该任务机器学习模型所需的大量数据。弱监督和数据增强提供了多种方式来结合并利用各种信号,例如启发式规则和专家人工标注[heuristics and expert human annotations]。
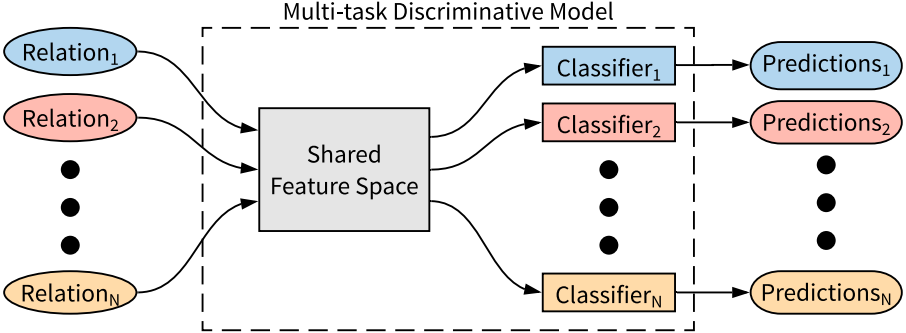
第三,我们训练了一个对硬件数据手册中数据多样性具有鲁棒性的多任务学习模型。这将使数据库错误从随机的人为错误转向更系统化的错误,而这类错误可以通过机器学习方法进行迭代式地处理和减少。此外,使用多任务学习方法通过在共享特征空间中共同训练这些提取任务,提高了从数据手册中提取多个特性的效率(第4.2.3节)。
其他领域已经采用自动化方法来创建知识库,以此作为使信息易于获取的解决方案 [28, 44]。然而,这些领域选择的自动化方法仅专注于非结构化文本。相比之下,硬件数据手册是为技术读者编制的,并包含大量通常以密集的数字、图形和图像格式呈现的数据。Fonduer 框架 [41] 提供了一个适用于格式丰富文档的通用数据模型,它对不同类型的文档一视同仁,试图将它们强行纳入单一框架[a single framework]中。
在这项工作中,我们基于 Fonduer,但采取了相反的方法。我们没有试图将文档强行纳入统一框架,而是在一开始就深入研究硬件数据手册的特性,然后仔细定制我们的方法以响应这些发现。例如,在一个数据手册中,不同的电气特性以高度相似的方式表达(例如,在具有相似表头和结构的表格[in tables with similar headers and structure]中);这从根本上符合多任务学习方法 [42]。因此,我们利用 Fonduer 作为捕捉多模态信息的工具,但我们对其进行修改以应对硬件数据手册的独特挑战,从而提取文本和非文本信息。
此外,我们使用多任务学习包 Emmental [40] 对其进行扩展,以利用数据的根本特性。关于这项工作相较于先前工作的完整贡献描述,请参见第2节。
1.3 Contributions
本文做出了以下主要贡献:
(1) 一种利用丰富的数据模型、弱监督、数据增强和多任务学习来创建硬件组件知识库的方法(第3节)。
(2) 在多种硬件组件上对该方法进行评估,在提取文本和非文本信息方面平均达到77 F1分数。我们在现有人工策划的知识库基础上平均提升了12个F1分数(第4节)。
(3) 应用研究,突出展示了这些数据库如何使硬件组件选择变得更加容易(第4.3节)。
2 BACKGROUND AND RELATED WORK
2.1 Knowledge Base Construction
知识库构建以文档作为输入,并输出一个带有用户定义模式的数据库,该数据库通过从输入文档中提取的信息进行填充。
我们将这一过程描述如下:
A mention,记为 ,代表一个名词,即现实世界中的一个人、地点或事物,它可以通过其提及类型
进行分组和识别。例如,“part number”(部件编号)是一个提及类型,而“BC546”是一个对应的提及。
个提及[mention]之间的关系是一个
-ary relation,记为
,它对应于一个模式(schema),记为
。
一个候选项是一个 n-ary tuple,记为,它表示关系 R 的一个可能正确的实例。例如,“part number”(部件编号)和“price”(价格)表示一个具有模式
的关系,其中“BC546”和“$1.00”表示一个 2 元关系
的候选项
。
为了实现知识库构建的自动化,基于机器学习的系统将这一过程建模为一个分类任务。从输入文档中提取候选项,并为每个候选项分配一个布尔随机变量[a Boolean random variable],其中真值[ a true value signals]表示该候选项是关系的有效实例。为了做出这一判断,每个候选项都被分配了一组特征,这些特征作为分类器应赋予哪个布尔值的信号。
然后,这些系统根据候选项的特征以及一组称为训练数据的示例,最大化正确分类每个候选项的概率。最终,一个监督式机器学习算法需要三个输入:(1) 候选项,(2) 它们的特征,以及 (3) 训练数据。然后,它为每个输入候选项输出一个边际概率[a marginal probability]。
最后,我们对输出概率设置一个阈值,使得概率超过阈值的候选项被分类为真,反之则为假。
2.2 Training Data Generation
2.3 Multi-task Learning
2.4 The Fonduer Framework
3 METHODOLOGY
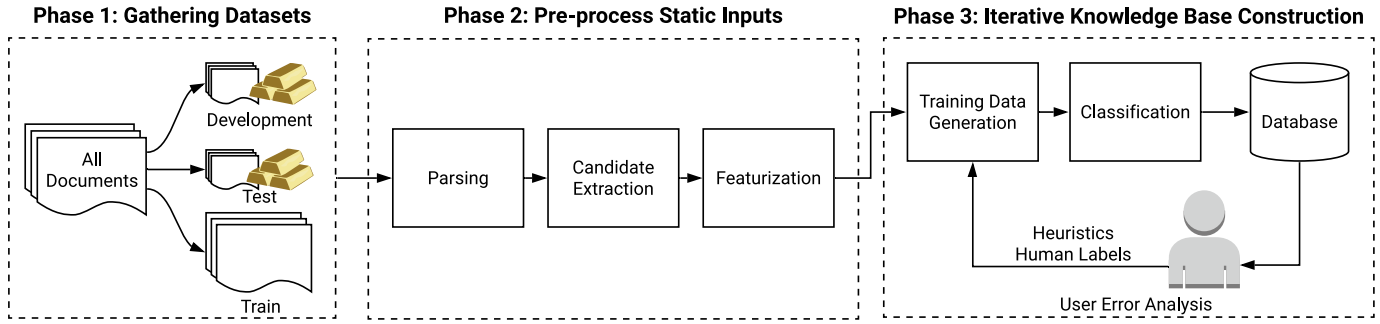
3.1 Phase 1: Gathering Datasets
3.2 Phase 2: Pre-process Static Inputs
第三个输入,即训练数据,将在第三阶段中迭代生成并优化。为了生成候选项和特征,我们必须:(1) 将输入语料库[the input corpus]解析为一个格式丰富的数据模型[formatted data model],(2) 提取候选项[extract candidates],以及 (3) 对每个候选项进行特征化[featurize each of these candidates]。在硬件数据手册领域,我们还必须考虑隐式信息,谨慎避免候选项的组合爆炸,并利用多模态特征。
Parsing.
制造商将数据手册以格式丰富的 PDF 文档形式分发,这些文档通过文本、结构、表格和视觉提示来传达信息。因此,在将这些文档解析为数据模型时,尽可能保留这些丰富的元数据至关重要。本方法中的每个后续步骤都依赖于该数据模型。如果输入文档被解析为非结构化文本[unstructured text],那么将缺少诸如表格或视觉对齐之类[tabular or visual alignments]的信息,而这些信息对于判断候选项是否正确至关重要。
Candidate Extraction.
回顾第 2 节,我们将candidates定义为提及(mention)的 -ary tuple,其中每个提及都属于特定的提及类型。为了提取候选项,我们首先为候选项中的每个提及定义提及类型[mention types],然后提取每种类型的所有提及的笛卡尔积,以形成候选项。由于这种笛卡尔积,候选项可能会出现组合爆炸,其中大多数候选项都是错误的。在处理硬件数据手册时尤其如此,因为其中的提及通常只是文档中的简单数值。为了应对这种类别不平衡并提高性能,我们在提及级别和候选项级别都应用了过滤器[filters]。
例如,如果某个提及类型[mention type]是数值[numerical value],则我们可以在提及级别通过将数值限制在特定范围内来进行过滤,但这需要领域专业知识来理解有效的数值范围。
在候选项级别,我们可以基于整个候选项进行过滤,例如,丢弃那些其所有组成部分提及[component mentions]都未出现在文档同一页上的候选项。这凸显了在优化系统性能与优化端到端质量之间的根本矛盾。
如果我们不过滤任何候选项,就会出现对负类候选项[negative candidates]的极端类别不平衡,从而降低端到端质量。通过减少考虑的候选项数量,过滤可以提高性能,并有助于减少类别不平衡。但是,在某一点之后,进一步的过滤会降低整体召回率,并因此也会降低端到端质量[end-to-end quality]。
此外,硬件数据手册中通常包含应作为候选项提取的隐式信息。例如,文档标题可能仅包含“BC546...8”,而不是明确列出“BC546、BC547、BC548”作为部件编号。我们扩展了 Fonduer 框架以支持隐式候选项,因此对于这种简单模式,我们可以将文本扩展为隐式候选项,这些候选项只有在通过所有过滤器后才会被存储。然而,更复杂的隐式信息仍然是一个挑战(第 6.2 节)。
Featurization.
接下来,我们使用 Fonduer [41] 提供的所有模态特征对每个提取的候选项进行特征化。Fonduer 利用其数据模型来计算捕捉多种信息模态信号的特征,例如结构、表格和视觉特征,以及标准的自然语言特征,如词性标注和命名实体识别标签。然后,它为每个候选项创建一个向量[a vector],指示该候选项表达了哪些特征[features]。
3.3 Phase 3: Iterative Knowledge Base Construction

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)