知识蒸馏:大模型对小模型的调控指南(详细流程介绍)
知识蒸馏是一种模型压缩技术,通过让学生模型模仿预训练教师模型的行为来实现高效学习。核心概念包括:logits(未经softmax处理的原始输出)、硬标签(确定性标注)和软标签(概率化分布)。知识蒸馏主要有三种方法:1)响应式蒸馏,直接学习教师模型的输出;2)特征蒸馏,匹配中间层特征表示;3)关系蒸馏,建模样本间关系。其中温度参数T是关键,它控制softmax输出的平滑度,平衡负标签信息利用与噪声干
目录
1. 响应式蒸馏(Response Distillation)
3. 关系蒸馏(Relation Distillation)
在介绍知识蒸馏前,先介绍一些基础的知识,,大家也可以看文章不懂的时候,返回来回顾这个概念
1. logits
在深度学习分类模型中,最后一层通常会输出一个向量,向量的维度等于类别数量(例如,识别 10 种动物的模型,输出向量维度为 10)。这个向量在经过 softmax 函数处理前,就被称为 logits。
- 举例:假设一个图像分类模型判断一张图片是 “猫”“狗”“鸟” 的 logits 分别为 [3.2, 1.5, -0.8],这三个值就是未经 softmax 转换的原始输出。
- 与概率的关系:logits 经过 softmax 函数后会转化为概率(如 [0.85, 0.12, 0.03]),但 logits 本身的数值大小反映了模型对每个类别的 “置信度倾向”,数值越大表示模型越倾向于该类别。
知识蒸馏的核心是让 “学生模型”(小模型)学习 “教师模型”(大模型)的知识,而 logits 是教师模型传递知识的关键载体,原因如下:
-
包含更丰富的信息:教师模型的 logits 不仅包含最终预测类别(如 “猫”)的信息,还包含对其他类别(如 “狗”“鸟”)的相对判断(例如 “虽然不是狗,但比鸟更像狗”)。这些信息比单纯的标签(如 “猫”)更全面,能帮助学生模型更好地学习类别间的差异。
-
提供 “软标签”(soft labels):logits 经过 softmax 转换后得到的概率分布(尤其是通过 “温度系数” 调整后的分布)被称为软标签。软标签比数据集的 “硬标签”(如独热编码 [1,0,0])更能体现教师模型的推理过程,学生模型通过学习软标签可以获得更细致的知识。
-
示例:假设教师模型对一张 “猫” 的图片输出 logits [5, 3, 1],经过 softmax 后得到软标签 [0.88, 0.11, 0.01]。学生模型学习这个软标签,不仅知道 “是猫”,还能学到 “更像狗而不是鸟”,这比直接学习硬标签 [1,0,0] 更有价值。
2、硬标签(Hard Labels)
硬标签是最常见的标签形式,指的是对样本类别的确定性标注,通常以独热编码(One-Hot Encoding)或整数形式呈现,直接指示样本的真实类别。
特点:
- 非此即彼的确定性:每个样本仅对应一个类别,标签中只有 “是” 或 “否” 两种状态(例如,对于 “猫、狗、鸟” 三类,“猫” 的硬标签为 [1,0,0])。
- 信息单一:仅包含样本的真实类别,不体现模型对其他类别的判断倾向(比如 “猫” 和 “狗” 的相似性)。
- 来自数据集标注:通常是人工标注或数据集自带的原始标签,代表 “ground truth”(真实标签)。
示例:
- 图像分类中,一张 “猫” 的图片,硬标签可能是整数 “0”(假设 “猫” 对应类别 0),或独热向量 [1,0,0](对应 “猫、狗、鸟” 三类)。
- 文本分类中,一篇 “体育新闻” 的硬标签可能是 [0,1,0](对应 “娱乐、体育、科技” 三类)。
3、软标签(Soft Labels)
软标签是一种概率分布形式的标签,通常由模型(如知识蒸馏中的 “教师模型”)输出,每个类别对应一个概率值,反映模型对样本属于各个类别的 “置信度”。
特点:
- 概率化的不确定性:标签是一个概率分布,所有类别的概率和为 1,例如 “猫、狗、鸟” 的软标签可能是 [0.85, 0.12, 0.03]。
- 信息丰富:不仅包含最可能的类别(如概率最高的 “猫”),还包含其他类别的相对可能性(如 “狗” 比 “鸟” 更接近),体现了类别间的关联性和模型的推理过程。
- 可通过温度系数调整:在知识蒸馏中,软标签通常由教师模型的 logits 经 softmax 函数(带温度系数 τ)转换得到。温度系数越高,概率分布越 “平滑”,次要类别的概率占比越高,信息更细致(例如 τ=10 时,软标签可能变为 [0.4, 0.35, 0.25])。
4. softmax函数
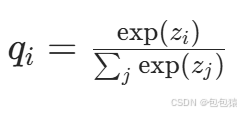
但要直接使用softmax层的输出值作为soft target, 这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。
下面的公式时加了温度这个变量之后的softmax函数:
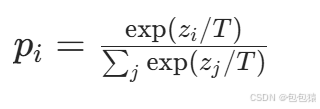
- 这里的T就是温度。
- 原来的softmax函数是T = 1的特例。 T越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
- 当T=1时,结果接近原始硬标签(概率集中在少数类别);
- 当T>1时,概率分布更 “软化”,能反映类别间的相似性(如 “猫” 和 “虎” 的概率更接近),包含更丰富的泛化信息。
以下是知识蒸馏介绍
一.基本概念
-
定义:知识蒸馏是一种重要的模型压缩技术,核心思想并非让小型模型直接从训练数据中学习标签,而是通过训练学生模型来模仿一个预训练好的、更大更复杂的模型的行为。
-
角色定位:“教师模型”(Teacher Model)通常是大规模、高性能的复杂模型;“学生模型”(Student Model)则是轻量化、低复杂度的目标模型。
-
关键机制:关键在于软标签的运用。教师模型在输出层会产生logits,这些logits经过带有温度参数T的Softmax函数处理后,得到一个平滑的概率分布,即软标签。相比于真实标签(硬标签,通常是one-hot编码),软标签保留了教师模型对于不同类别之间的相似性判断和置信度信息。
二. 知识蒸馏的具体方法
1. 响应式蒸馏(Response Distillation)
定义与核心思想
✅ 目标:让学生模型直接模仿教师模型的最终输出(如 logits 或软标签)。
✅ 关键:通过软标签传递类别间的置信度差异和相似性信息,而非仅依赖硬标签(One-Hot)。
✅ 优势:实现简单高效,适用于大多数分类任务。
实施步骤
| 步骤 | 操作描述 | 关键技术 |
|---|---|---|
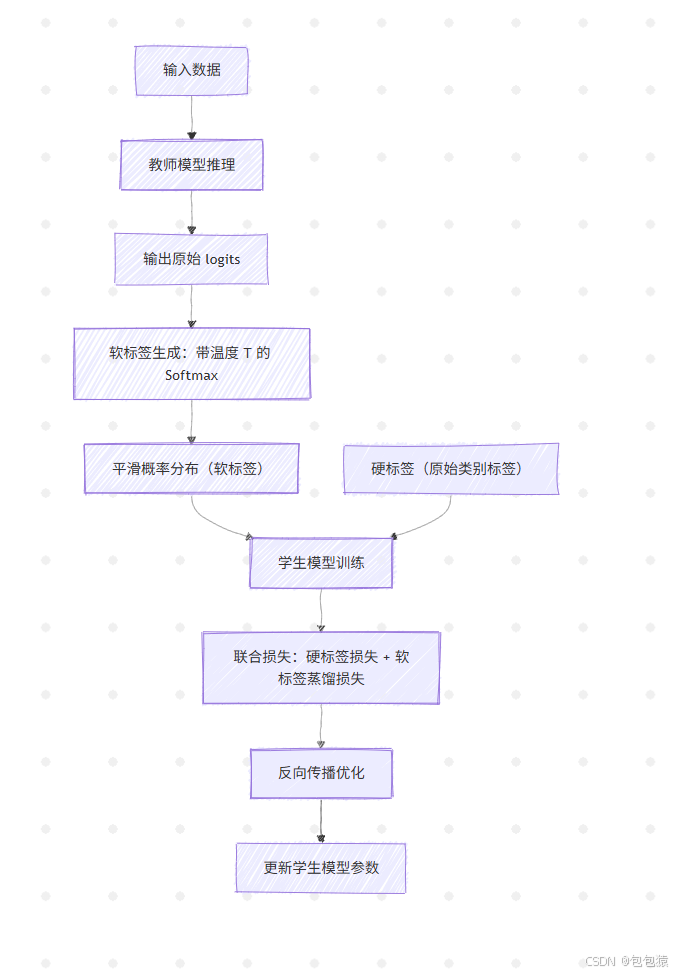
| 1. 教师模型推理 | 输入数据 → 教师模型 → 输出原始 logits | - |
| 2. 软标签生成 | 对 logits 应用带温度参数 T 的 Softmax → 平滑概率分布(软标签) | 温度系数 T(控制熵大小) |
| 3. 学生模型训练 | 学生模型同时学习:①硬标签的交叉熵损失;②与软标签的蒸馏损失(KL散度) | 联合损失函数:L = α·L_ce + β·L_distill |
| 4. 优化 | 反向传播更新学生模型参数 | SGD/Adam 等优化器 |
流程图描述
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 定义教师模型、学生模型(假设已预训练好教师模型)
teacher_model = TeacherNet() # 教师模型(固定参数,不更新)
student_model = StudentNet() # 学生模型(待训练)
# 2. 损失函数:硬标签损失 + 软标签蒸馏损失
ce_loss = nn.CrossEntropyLoss() # 硬标签损失(交叉熵)
def distill_loss(student_logits, teacher_logits, T=2.0):
# 软标签蒸馏损失(KL散度),T是温度系数
student_soft = nn.functional.softmax(student_logits/T, dim=-1)
teacher_soft = nn.functional.softmax(teacher_logits/T, dim=-1)
return nn.functional.kl_div(student_soft.log(), teacher_soft, reduction='batchmean')
# 3. 优化器
optimizer = optim.Adam(student_model.parameters(), lr=1e-4)
# 4. 训练循环(对应流程图的【学生模型训练→联合损失→反向传播】)
for data, hard_labels in train_loader:
# a. 教师模型推理(流程图:输入数据→教师推理→输出logits)
with torch.no_grad(): # 教师模型参数不更新
teacher_logits = teacher_model(data)
# b. 软标签生成(流程图:logits→带温度T的Softmax→软标签)
# (注:实际训练时,软标签直接用teacher_logits计算,无需单独保存“软标签”变量)
# c. 学生模型前向(流程图:学生模型训练)
student_logits = student_model(data)
# d. 联合损失计算(流程图:硬标签损失+软标签损失)
loss_hard = ce_loss(student_logits, hard_labels) # 硬标签损失
loss_soft = distill_loss(student_logits, teacher_logits, T=2.0) # 软标签蒸馏损失
loss_total = α * loss_hard + β * loss_soft # 联合损失(α、β是权重系数)
# e. 反向传播优化(流程图:反向传播→更新参数)
optimizer.zero_grad()
loss_total.backward()
optimizer.step()2. 特征蒸馏(Feature Distillation)
定义与核心思想
✅ 目标:提取教师模型中间层的特征表示(如卷积层的激活值),使学生模型学习更丰富的语义信息。
✅ 关键:跨越网络深度匹配特征空间,弥补师生模型架构差异导致的表征差距。
✅ 优势:提升小模型对复杂模式的捕获能力,尤其适用于跨架构迁移。
实施步骤
| 步骤 | 操作描述 | 关键技术 |
|---|---|---|
| 1. 教师特征提取 | 输入数据 → 教师模型 → 选取中间层特征(如 ResNet 的第4阶段) | Hinton et al.提出的注意力转移法 |
| 2. 学生特征对齐 | 学生模型设计相似结构的中间层 → 提取对应层特征 | 可添加投影适配器(Projection Block)解决维度不匹配 |
| 3. 特征仿射损失 | 计算师生特征的距离(MSE/Cosine相似度)→ 加入总损失函数 | L2损失 + 余弦相似度约束 |
| 4. 联合训练 | 同时优化分类损失和特征对齐损失 | 多任务学习框架 |
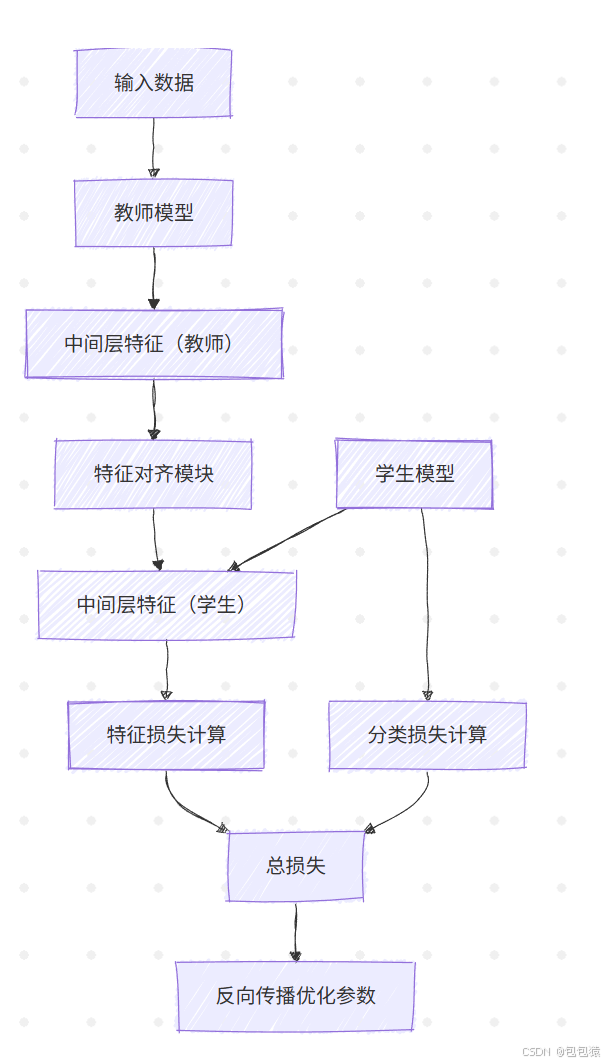
3. 关系蒸馏(Relation Distillation)
定义与核心思想
✅ 目标:建模样本间或特征通道间的关联关系(如注意力图、协方差矩阵)。
✅ 关键:捕捉教师模型隐含的结构先验(如空间相关性、通道重要性)。
✅ 优势:增强学生模型对上下文关系的建模能力,适用于细粒度识别任务。
典型实现方式
| 类型 | 示例方法 | 技术细节 |
|---|---|---|
| 样本关系 | Attention Map Distillation | 教师模型的注意力权重作为监督信号,引导学生关注关键区域 |
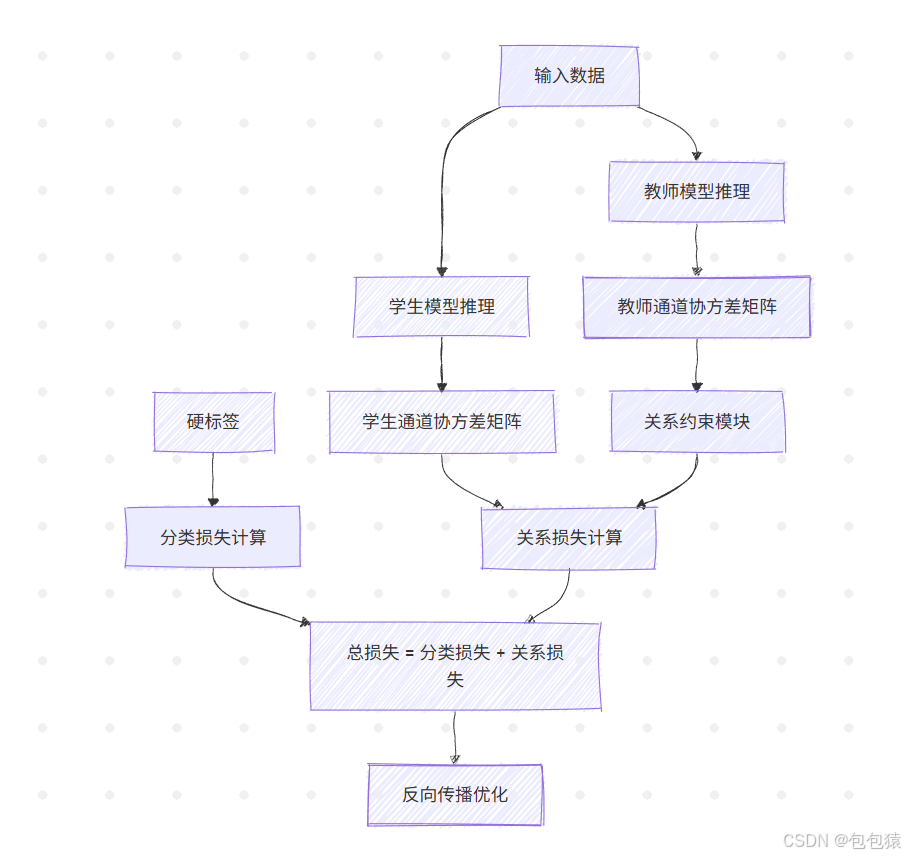
| 通道关系 | Channel Correlation Distillation | 统计教师特征图各通道的协方差矩阵,约束学生通道响应模式 |
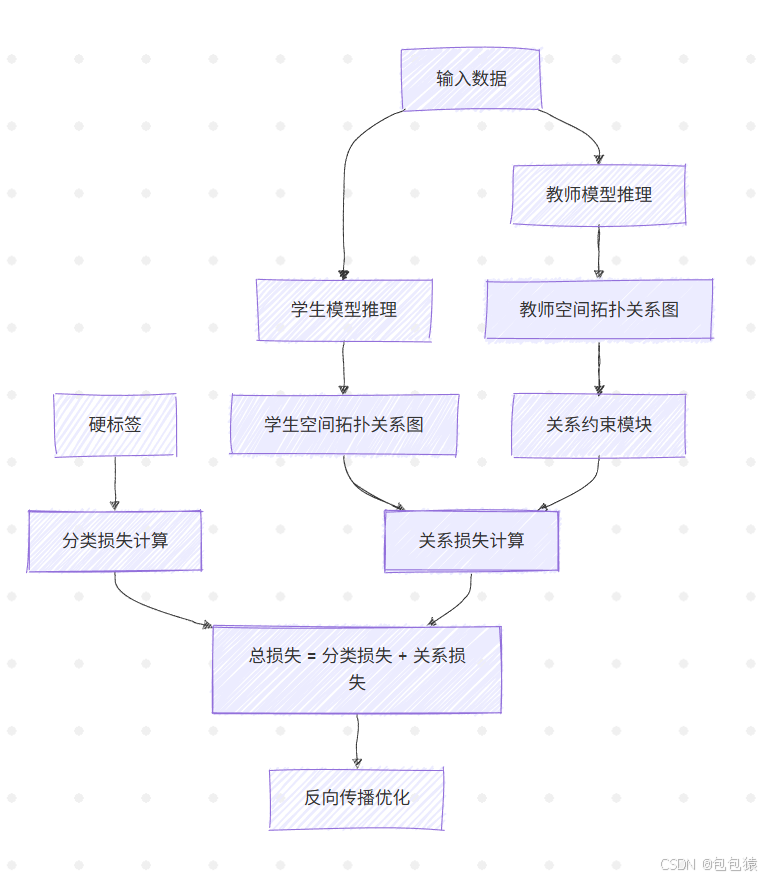
| 空间关系 | Spatial Relation Learning | 通过图神经网络建模特征点之间的拓扑关系 |
流程图描述
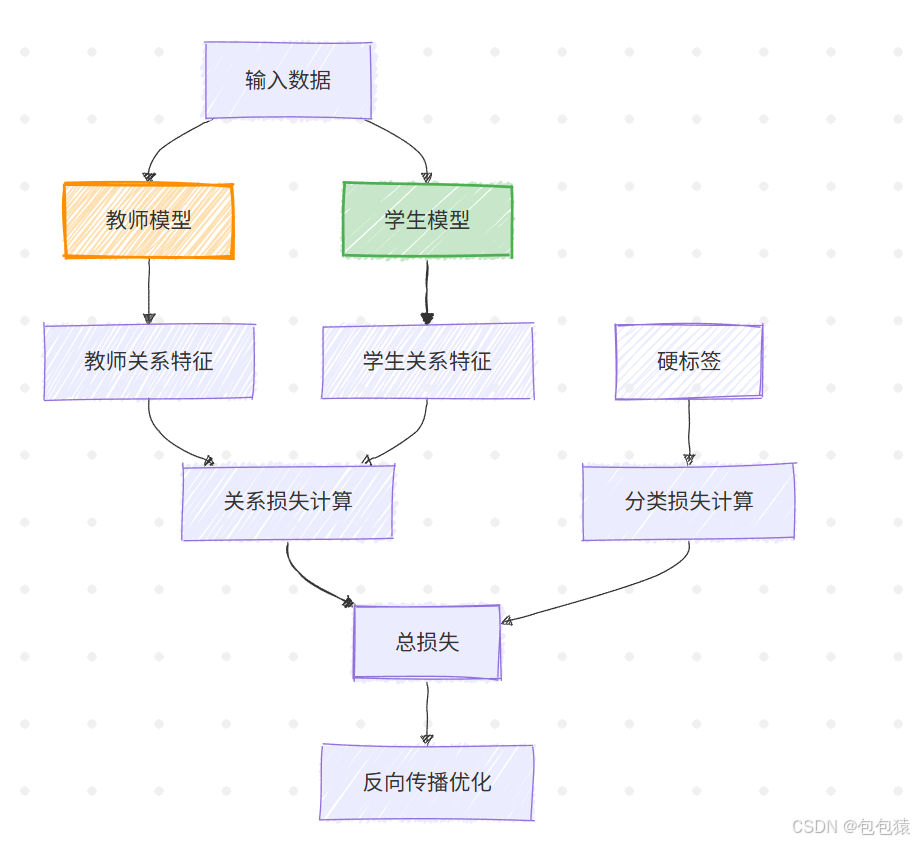
通道关系(Channel Correlation)流程图调整
空间关系(Spatial Relation)流程图调整
二、温度 T 的本质与作用
在模型蒸馏的 Softmax 温度调整机制里,温度 T 是控制 Softmax 输出概率分布 “平滑度” 的核心超参数,直接影响学生模型(Net - S)对正负标签信息的关注倾向:
- T→∞:输出概率趋近平均分布(所有类别概率接近),Softmax 几乎 “抹除类别差异”,学生被迫关注各类别(包括负标签)的相对关系。
- T→0:输出概率趋近 “One - Hot”(仅最大概率类别接近 1,其余接近 0),Softmax 强化 “硬分类”,学生主要关注正标签(或最显著类别)。
①温度 T 对信息学习的影响
温度 T 的高低,本质是 **“负标签有效信息利用” 与 “负标签噪声干扰” 的权衡 **:
| 温度 T 趋势 | 对负标签的关注程度 | 核心影响 |
|---|---|---|
| 升高(T 大) | 更多关注 | 让学生学习负标签中 “值显著高于平均” 的有效信息(如细粒度分类里 “相似类别” 的区分特征),但也可能引入负标签的噪声。 |
| 降低(T 小) | 更少关注 | 减少负标签噪声干扰(负标签值越低,信息越不可靠),但会损失负标签中潜在的有效信息。 |
②温度 T 的选取策略(经验性规则)
温度 T 的选择没有绝对公式,但与学生模型(Net - S)的复杂度(参数量)强相关:
-
学生模型 “小而简单”(参数量少):
选较低温度(如 T = 1 ~ 5 )。因小模型表达能力有限,无法 “消化” 负标签全部信息,低温度可让模型聚焦正标签和最关键负标签,避免被噪声拖垮。 -
学生模型 “大而复杂”(参数量多):
可尝试较高温度(如 T = 5 ~ 20 )。大模型有更强的特征拟合能力,能从负标签中筛选有效信息(如区分 “相似但非目标” 的类别特征),提升泛化性。
③总结:温度 T 的设计逻辑
温度 T 的本质是 **“信息取舍的杠杆”—— 在 “挖掘负标签有效信息” 和 “规避负标签噪声” 间找平衡。实践中,需结合学生模型复杂度、任务场景(负标签噪声程度、有效信息密度)** 做 “经验性调试”:
- 若任务负标签噪声少(如标注精准的细粒度分类),可适当调高 T 挖掘更多信息;
- 若学生模型极轻量化(如移动端部署模型),优先调低 T 保证训练稳定。
简单说,温度 T 的选取没有 “最优解”,但核心逻辑是匹配学生模型的 “信息消化能力” ,在负标签的 “收益 - 风险” 间找平衡点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)