Redis基础概念
泛指非关系型数据库。1、NoSQL的特点方便扩展(数据之间没有关系)大数据量高性能(Redis写8w/s, 读11w/s,NoSQL的缓存记录级是一种细粒度的,性能会更高)数据类型是多样型的。不需要事先设计数据库,随取随用存储方式多样, 键值对,列存储,文档存储,图形数据库没有固定的查询语言2、NoSql的四大分类KV键值对新浪 Redis美团 Redis+Tair阿里 百度: Redis+Mem
前言
就数据的存储而言,服务器的数据存储设计大概经历了一下几个过程:
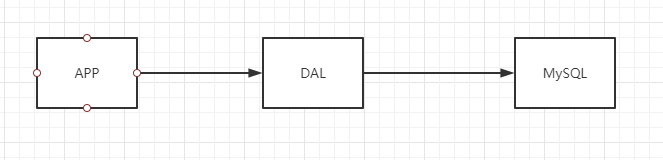
这种模式下的瓶颈: 数据量太大,一个机器存放不下 数据的索引太大,一个机器的内存放不下 访问量(读写混合)太大,一个服务器承受不住
1、缓存 Memcached+读写分离
网站上80%的情况都是在读,每次都去查询数据库,效率很低。这时候可以加入缓存机制,第一次查 询去MySQL中读取数据,将数据返回给用户的同时,在缓存中也存储下来。第二次访问,就可以直接从 缓存中读取。
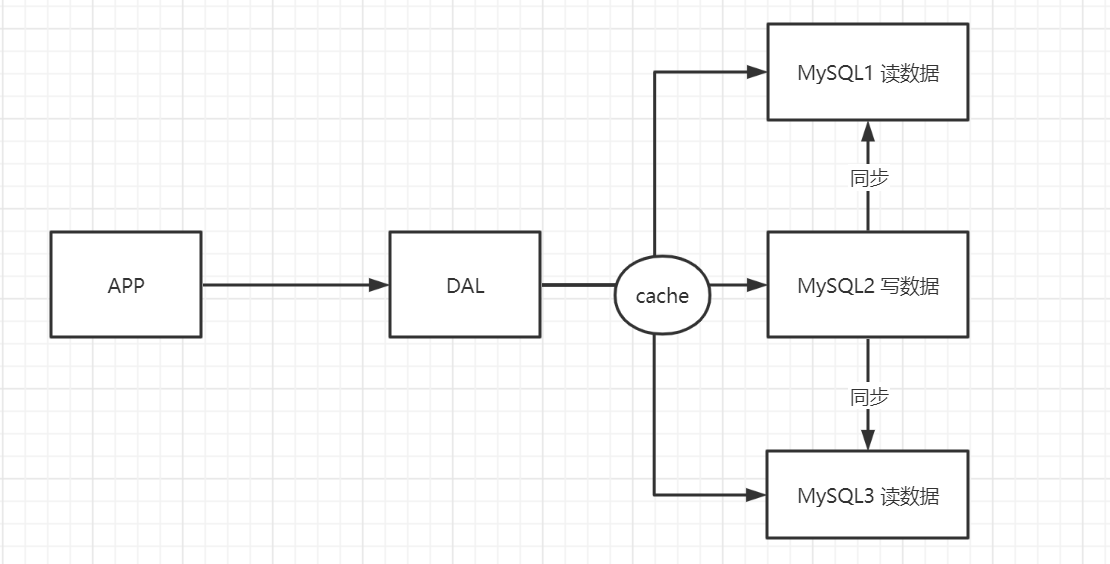
2、分库分表 + 水平拆分(MySQL集群)
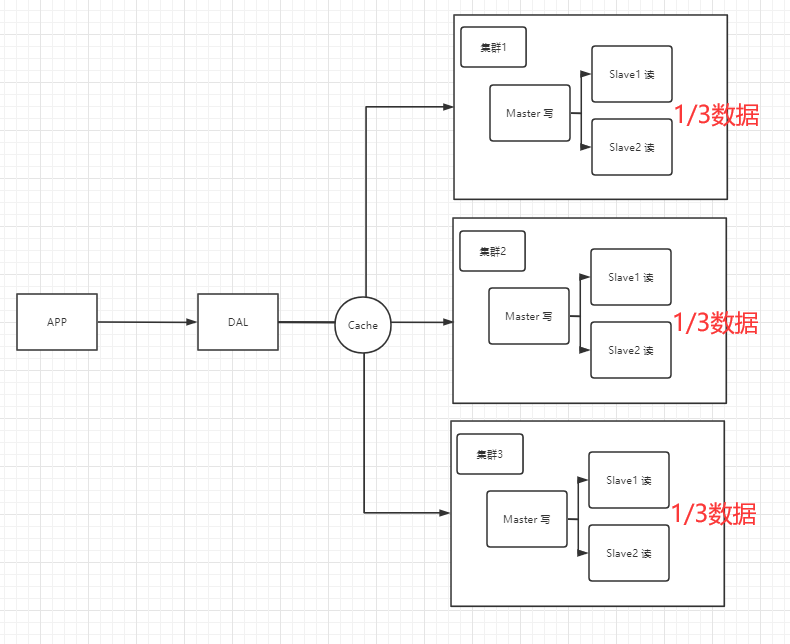
但是随着社会的发展,要存储数据的类型(音乐,视频,地理位置,人际交往圈、用户自己产生的数 据,用户日志等)也越来越繁多,数据量也爆发式增长。这样MySQL等关系型数据库就越来越不够用 了。NoSQL数据库就开始进入人们的视野!NoSQL数据库可以很好的解决这些问题。
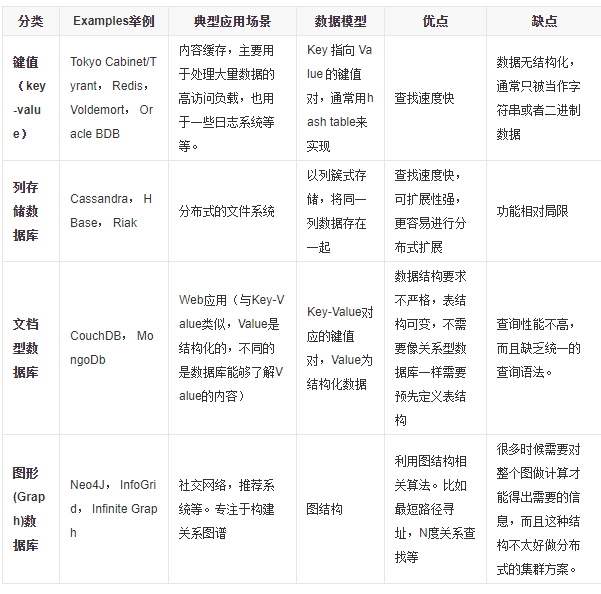
3、什么是NoSQL NoSQL(Not Only SQL)
泛指非关系型数据库。
1、NoSQL的特点
- 方便扩展(数据之间没有关系)
- 大数据量高性能(Redis写8w/s, 读11w/s,NoSQL的缓存记录级是一种细粒度的,性能会更高)
- 数据类型是多样型的。不需要事先设计数据库,随取随用
- 存储方式多样, 键值对,列存储,文档存储,图形数据库
- 没有固定的查询语言
2、NoSql的四大分类
KV键值对
- 新浪 Redis
- 美团 Redis+Tair
- 阿里 百度: Redis+Memcached
文档型数据库 bson格式
- MongoDB MongoDB是一个基于分布式文件存储的数据库,C++编写,主要用来处理大量的文档
- MongoDB是一个介于关系型数据库和非关系型数据库的中间产品。MongoDB是非关系型数据库 中功能最丰富,最像关系型数据库的
列存储数据库
- HBase 分布式文件系统
- GFS
图关系数据库
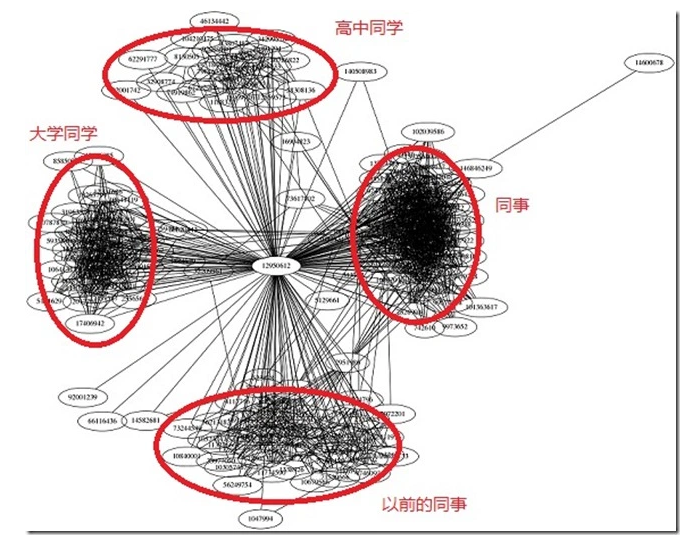
- 他不是存图片的,存储的是关系,比如:朋友圈社交网络、广告推荐
- Neo4j, infoGrid
四种分类的比较
一、Redis 的基本概念
Redis 是一个开源(BSD 许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件 。它支持多种类型的数据结构,如字符串(strings),散列(hashes),列表(lists),集合(sets),有序集合(sorted sets)与范围查询,bitmaps,hyperloglogs 和地理空间(geospatial)索引半径查询。Redis 内置了复制(replication),LUA 脚本(Lua scripting),LRU 驱动事件(LRU eviction),事务(transactions)和不同级别的磁盘持久化(persistence) -- RDB 和 AOF ,并通过 Redis 哨兵(Sentinel)和自动分区(Cluster)提供高可用性(high availability)。
| 名称 | 类型 | 数据存储选项 | 查询类型 | 附加功能 |
|---|---|---|---|---|
| Redis | 使用内存存储(in-memory)的非关系数据库 | 字符串、列表、集合、散列表、有序集合 | 每种数据类型都有自己的专属命令,另外还有批量操作(bulk operation)和不完全(partial)的事务支持 | 发布与订阅,主从复制(master/slave replication),持久化,脚本(存储过程,stored procedure) |
| memcached | 使用内存存储的键值缓存 | 键值之间的映射 | 创建命令、读取命令、更新命令、删除命令以及其他几个命令 | 为提升性能而设的多线程服务器 |
| MySQL | 关系数据库 | 每个数据库可以包含多个表,每个表可以包含多个行;可以处理多个表的视图(view);支持空间(spatial)和第三方扩展 | SELECT、INSERT、UPDATE、DELETE、函数、存储过程 | 支持 ACID 性质(需要使用 InnoDB),主从复制和主主复制(master/master replication) |
| PostgreSQL | 关系数据库 | 每个数据库可以包含多个表,每个表可以包含多个行;可以处理多个表的视图;支持空间和第三方扩展;支持可定制类型 | SELECT、INSERT、UPDATE、DELETE、内置函数、自定义的存储过程 | 支持 ACID 性质,主从复制,由第三方支持的多主复制(multi-master replication) |
| MongoDB | 使用硬盘存储(on-disk)的非关系文档存储 | 每个数据库可以包含多个表,每个表可以包含多个无 schema(schema-less)的 BSON 文档 | 创建命令、读取命令、更新命令、删除命令、条件查询命令等 | 支持 map-reduce 操作,主从复制,分片,空间索引(spatial index) |
二、Redis 的基本操作
Redis 默认有 16 个数据库,默认使用的是第 0 个数据库,可以通过select切换数据库。Redis 的命令对大小写不敏感。
1. select
切换数据库,格式:select index
127.0.0.1:6379> SELECT 3 # 切换数据库
OK
2. dbsize
查看数据的大小,格式:dbsize
127.0.0.1:6379[3]> DBSIZE # 查看数据库的大小
(integer) 0
127.0.0.1:6379[3]> set name wangold
OK
127.0.0.1:6379[3]> set age 28
OK
127.0.0.1:6379[3]> DBSIZE
(integer) 2
3. keys
查看所有的 key,格式:keys *
127.0.0.1:6379[3]> KEYS * # 查看所有的key
1) "name"
2) "age"
4. flushdb、flushall
清空当前数据库和清空所有的数据库
127.0.0.1:6379[3]> FLUSHDB # 清空当前数据库
OK
127.0.0.1:6379[3]> KEYS *
(empty array)
127.0.0.1:6379[3]> FLUSHALL # 清空所有的数据库
OK三、Redis 是单线程的
Redis 是很快的,官方表示,Redis 是基于内存操作的,CPU 不是 Redis 的性能瓶颈,Redis 的瓶颈就是根据机器的内存和网络带宽。既然可以使用单线程来实现,就使用单线程了!
Redis 是 C 语言实现的,官方数据:读:110000/s 写:80000/s,完全不比同样使用 key-value 的 Memcached 差
Redis 为什么单线程还这么快?
- 误区 1:高性能的服务器一定是多线程的
- 误区 2:多线程(CPU 上下文切换)一定比单线程效率高
核心:Redis 是将所有的数据全部放在内存中的,所以说使用单线程去操作效率就是最高的,相比多线程,减少了 CPU 上下文切换的耗时。对于内存系统来说,没有上下文切换效率就是最高的,多次读写都是在一个 CPU 上的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)