超级智能:基于第一性原理的思考
近期,关于如何依托现有技术突破至AGI(通用人工智能)乃至ASI(人工超级智能)的讨论正持续升温。Meta最近高调宣布,将斥资数十亿美元打造一个高度机密的“超级智能”实验室;而OpenAI、Anthropic、Google DeepMind等其他科技巨头也纷纷通过不同形式表态,明确将构建超级智能机器作为核心目标。这其中,OpenAI CEO萨姆・奥特曼(Sam Altman)的观点尤为直白,其将超
近期,关于如何依托现有技术突破至AGI(通用人工智能)乃至ASI(人工超级智能)的讨论正持续升温。
Meta最近高调宣布,将斥资数十亿美元打造一个高度机密的“超级智能”实验室;而OpenAI、Anthropic、Google DeepMind等其他科技巨头也纷纷通过不同形式表态,明确将构建超级智能机器作为核心目标。
这其中,OpenAI CEO萨姆・奥特曼(Sam Altman)的观点尤为直白,其将超级智能的实现归为工程问题:
“超级智能需要大量的算力、数据、模型规模以及工程投入。”
本文将以此为切入点,基于第一性原理(first principles)深入拆解细节,推演构建超级智能的潜在路径。
我们先假定技术的基本构件已确定:超级智能将以神经网络为基础,通过反向传播(backpropagation)和某种机器学习范式进行训练。
关于具体架构细节内容,本文将不做详述,后续探讨将基于一个强假设:超级智能将基于Transformer架构构建。这一选择的依据在于,Transformer目前已是海量数据集上训练大模型的主流方案,其在并行计算效率与长序列建模上的优势已得到充分验证。
由此可初步得出:超级智能将是一个基于Transformer的神经网络,通过某种机器学习目标和基于梯度的反向传播进行训练。但这一框架下,仍有两大核心问题亟待厘清:
其一,需采用何种学习算法?
其二,应依托何种数据供给?
数据:文本是核心
ChatGPT的问世,离不开互联网这座蕴含海量人类知识的宝库。
目前最先进的模型均从互联网文本中学习知识。截至当下,尚未有明显证据表明整合非文本数据能为模型带来整体性能提升——这些数据包括图像、视频、音频以及机器人传感器数据等。这些模态数据让ChatGPT变得更聪明的原因并不被大众所完全知晓。
为何如此?一方面,这可能是科学或工程上的问题;但另一方面,文本本身很可能具有某种独特性。互联网上的每一段文本(至少在LLM出现之前)都是人类思维过程的映射。某种意义上,人类撰写的文本均经过“预处理”,蕴含极高的信息密度。
反观图像这类数据,它们是对周围世界的原始捕捉,未经人类干预。由真实人类书写的文本,很可能承载着来自纯感官输入所无法比拟的内在价值。
因此,在有人证明非文本数据的价值之前,我们暂且假设:唯有文本数据至关重要。
那么,目前文本数据体量有多大呢?
事实上,文本数据即将耗尽的隐忧已引发行业深度探讨。“数据墙”(data wall)与 “词元危机”(token crisis)等概念的诞生,正是为了破解数据枯竭背景下模型规模扩张的困局。
这场危机似乎已越来越近——大型AI实验室的工程师们正投入极大精力,从网络最边缘的角落搜罗最后一批可用文本,甚至将数百万小时的YouTube视频逐字转录,并斥巨资购入海量新闻素材,只为维系模型训练的数据供给。
不过值得庆幸的是,或许存在另一个可依赖的数据源(可验证环境)。这一点我们将在后续展开探讨。
学习算法:通向超级智能的关键
前文已揭示了一条重要原则:文本数据是通向超级智能的最佳路径。换言之,AGI很可能以大型语言模型(LLM)为核心形态。尽管视频学习、机器人学习等方向同样具备潜力,但至少在2030年前,二者似乎均难以独立支撑智能系统的构建。更为关键的是,它们所需要的数据规模远大于文本学习,而文本学习在信息密度与效率上又具备极大的天然优势。
接下来,我们须直面最核心的问题:驱动超级智能的学习算法究竟是什么?
在机器学习领域,从海量数据中提炼知识的经典方法主要有两类:一是监督学习(supervised learning),通过训练模型以提高对样本数据的似然度;二是强化学习(reinforcement learning),模型生成输出后,依据用户定义的 “优劣标准”,对其行为的 “正向价值” 给予奖励反馈。
明确这一分类后不难推断:任何潜在的超级智能系统,其训练逻辑都必然围绕监督学习、强化学习,或二者的融合展开。
我们不妨逐一进行剖析。
假设一:超级智能可通过监督学习实现
2023年,学界对 “扩展定律”(scaling laws)的热情高涨,而GPT-4的问世则引发了人们对于模型持续扩展将带来危险的担忧。
曾有一段时间,一种主流观点认为:大规模监督学习——尤其是“下一词元预测”(next-token prediction)任务,可催生出超级智能AI。OpenAI联合创始人伊利亚・萨茨凯弗(Ilya Sutskever)曾指出:下一词元预测的本质是“学习压缩宇宙”,因为要实现精准预测,模型就需要隐含对所有可能程序(或类似复杂系统)的模拟能力。
其论证逻辑大致如下:
要实现对下一词元的精确预测,模型需建模“任意人在任意场景下的书写逻辑”;
对单一个体的建模精度越高,模型便越逼近该个体的智能水平;
互联网沉淀的海量人类文本,要求预训练模型在大规模语料上精准捕捉无数个体的智能特征;
当模型能精准复现海量人类的智能集合时,其本身便等同于超级智能。
▌感性论证:通过模仿人类能否实现超级智能?
此逻辑值得推敲。首先,当前我们已构建出在下一词元预测任务上远超人类的系统,但其展现的通用智能仍远未达到人类的水平。这些模型精准掌握了我们设定的目标(预测下一词元),却始终难以实现真正期待的能力:比如如实回答问题而非虚构内容,或是毫无偏差地遵循复杂指令。
这可能仅是机器学习的失败。我们训练模型去预测每种情境下人类的平均结果。学习目标不鼓励模型对任何可能结果赋予过低概率。这种范式常导致“模式崩溃”(mode collapse),即模型擅长预测平均结果,却未能学习分布的尾部特征。
这或许源于机器学习范式的固有局限:训练模型去预测“每种情境下人类行为的平均结果”,而这种学习目标天然排斥对“极端可能性”赋予过低概率。这直接导致了“模式崩溃”(mode collapse),即模型擅长预测平均结果,却对分布尾部的罕见特征(如小众观点、突发场景)缺乏学习能力。
也许这些问题会随着参数规模扩大而消失。例如,像LLaMA这样的百亿参数模型常出现“幻觉” 现象,但当参数规模跃升至10^19时,一切或许会不同?理论上,这样的模型可能具备独立建模全球80亿人个体特征的能力,并为每个人生成基于数据的个性化预测——但这是否等同于超级智能,仍需打上问号。
▌基础设施论证:模型与数据规模恐难无限扩张
然而,“通过规模扩张实现超级智能”的设想可能只是空中楼阁——我们或许永远无法将模型参数推向10^19的量级。这种假设源于2022年前后的深度学习思潮:语言模型扩展定律的巨大成功让人们相信,让行业坚信“持续扩大模型与数据规模,终将催生完美智能”。
时间来到2025年,尽管扩展定律的理论逻辑未被彻底推翻,但模型规模突破临界点后,扩张的难度呈指数级攀升。早在2022年,就已逼近工程可行性的极限。
如今,几乎所有头部科技公司的模型训练都依赖数百台机器组成的巨型集群,单设备算力早已无法承载;向万亿参数发起冲击的过程中,硬件短缺(英伟达芯片的供不应求已反映在股价曲线中)与电力危机接踵而至:超大规模模型的功耗高到难以集中部署,企业不得不将训练任务拆分到全球分散的数据中心,甚至有人打起老旧核电站的主意,试图通过重启这类能源设施支撑下一代模型的训练——我们正身处一个为AI扩张而疯狂的时代。
数据维度的困境同样严峻。没人能精确统计每个模型消耗了多少互联网数据,但总量必然是一个天文数字。过去几年,大型AI实验室投入的工程资源几乎“榨干”了网络文本的最后一滴价值,例如OpenAI据称已转录了所有YouTube视频的语音内容,Reddit等高质量平台的数据更是被反复抓取到无新可挖。
种种迹象显示,将模型参数推向千亿以上量级,或将训练数据规模扩展至20万亿词元以上,看起来都困难重重。这些现实约束意味着,未来三年内监督学习的规模扩张空间可能不超过10倍——仅靠此路径实现超级智能,显然难以为继,必须另寻突破。
假设二:监督学习与强化学习相结合
除了纯粹的监督学习,还有一条值得探索的路径:监督学习(SL)与强化学习(RL)的协同。
为何需要监督学习?
强化学习的核心价值,在于提供了一套“从反馈中学习”而非“从演示中模仿”的方法论。但为何不能完全依赖强化学习?
答案隐藏在强化学习的固有难题中。从实践来看,RL的短板显著:相比SL的稳定高效,RL的训练过程充满不确定性。一个直观的困境是“冷启动问题”(cold start problem)——随机初始化的模型在初始阶段表现极差,所有动作几乎都无价值,必须 “碰巧”做出有效行为才能获得奖励,这使得早期训练效率极低。而利用人类数据进行监督学习,被证明是规避冷启动问题的绝佳途径。
不妨再明确强化学习的核心范式:模型通过尝试生成 “动作”,由外部反馈判定其优劣。这种反馈机制有两种主流形式:一是由人类评分员直接对模型表现打分(这正是典型RLHF——基于人类反馈的强化学习的核心逻辑);二是由自动化系统替代人工完成评估。
假设二(A):基于人类验证者的强化学习
这一范式的核心逻辑是:通过人类判断为模型提供奖励信号,若希望模型逼近超级智能,便奖励其生成更接近超级智能水准的文本(由人类评估界定)。
实践中,此类数据的收集成本极高。典型的RLHF(基于人类反馈的强化学习)流程中,须训练一个“奖励模型” 来模拟人类反馈。因为它们能提供远超实际人类所能给予的反馈量。
不妨构想一个理想场景:假设有无限量的人类为LLM标注数据并提供奖励,且奖励强度与模型逼近超级智能的程度正相关。暂且搁置所有后勤难题,假设这种模式终能大规模落地——它会奏效吗?一个纯粹从人类奖励信号中学习的机器,能否攀上智能阶梯并超越人类?
换个角度:即便人类自身无法创造超级智能,当它出现时,我们能否准确识别?从定义而言,人类并非超级智能。我们能否足够可靠地识别,从而为LLM提供有用的梯度信号?进而,LLM能否通过积累海量此类反馈,实现“自举式”进化,最终抵达超级智能?
有人常指出“生成难于验证”(generation is harder than verification),就像你能分辨一部电影的优劣,却未必能拍出佳作。这种二分法在机器学习中普遍存在,例如,区分猫与狗的照片,其计算复杂度远低于生成一张逼真的猫或狗的图像。
依此逻辑,若人类具备验证超级智能的能力,那么通过RLHF训练出超级智能模型便有了可能性。举例来说,让LLM持续创作小说,依据人类对“优秀程度”的评分给予奖励,循环往复,理论上或能得到一个超级智能的小说创作系统。
假设二(B):基于自动化验证器的强化学习路径
近年来,利用自动化验证器训练更优语言模型的思路逐渐成为行业关注的焦点。
当由计算机评估强化学习(RL)的中间结果时,可以使用模型或自动化验证器(verifier),这类系统能基于明确规则输出客观反馈,例如国际象棋中的“将死判定”(程序可直接检查棋局是否达成胜利条件并给予奖励),或编程任务中的“单元测试”(通过运行代码验证是否满足预设规范)。
自动化验证器的最大价值在于:它能将人类完全排除在训练循环之外(除了人类曾构建互联网这一前提)。由此衍生出一套构建超级智能的潜在方案:
通过监督学习在海量互联网文本上预训练一个LLM;
将其接入具备明确奖励机制的验证系统,对优质输出给予反馈;
长期迭代训练;
最终实现超级智能。
这一路径可行吗?
DeepMind的AlphaGo给出了部分答案。它通过监督学习与强化学习的结合,实现了“围棋霸权”——击败所有人类顶尖棋手,包括那些浸淫棋艺数十年的大师。其核心优势正源于围棋的“天然可验证性”:每一步棋的价值都可通过规则程序量化,最终胜负信号清晰无歧义,长期训练中甚至能精准评估某步棋对胜率的影响——这大致就是RL的工作原理。
更为关键的是,AlphaGo展现了AI实验室梦寐以求的特质:思考时间越长(计算量越大),表现越优。这与传统语言模型形成鲜明对比。
OpenAI去年秋季发布的O1模型,正是对这一范式的延续。它通过RLVR(可验证奖励强化学习)训练,像AlphaGo一样能通过延长思考时间提升输出质量: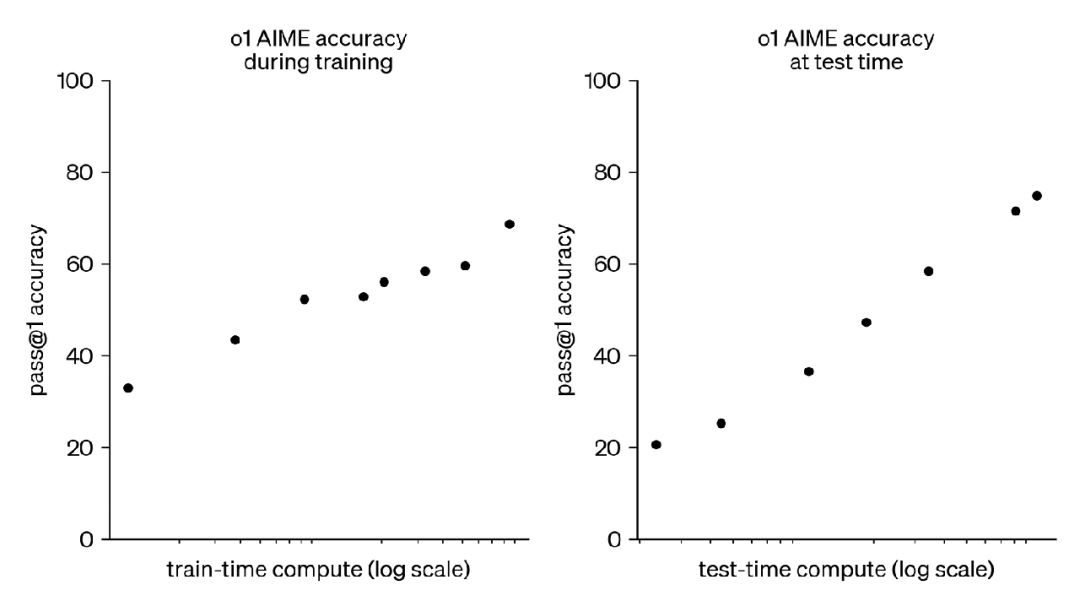
值得注意的是,这不是开放式任务,它是具有可验证训练数据的任务,因为可以检查LLM是否生成正确答案并相应奖励模型。
事实证明,对于当前预训练后能较好执行任务的LLM,它们能对AIME问题做出合理猜测。我们可利用RL训练它们,使其随时间推移做出越来越好的判断。
RLVR是通向超级智能之路吗?
显然,OpenAI、谷歌等头部AI实验室对这种“基于LLM的强化学习”范式满怀期待,认为它或许正是通向超级智能的钥匙。
萨姆・奥特曼(Sam Altman)此前那条语焉不详的推文,所指向的很可能也是这一技术路径——所谓超级智能的“工程问题”,本质上就是为海量不同类型任务构建强化学习环境,再训练一个能同时驾驭所有任务的LLM。
不妨先站在乐观角度推演:目前已知的可验证任务包括编程(通过运行代码验证正确性)与数学(并非证明题,而是有明确数值解的题目)。若我们能收集世界上所有可验证任务,通过联合训练(或分别训练后进行模型融合),真的能催生出通用超级智能吗?
这里存在几处逻辑跳跃,最关键的一点是:我们尚不清楚“可验证任务上的强化学习”能否实现跨领域迁移。例如,训练模型解数学题,是否能让它学会订机票?在可验证环境中提升编码能力,能否使其成为更优秀的软件工程师?
退一步假设,若强化学习的能力真能完美迁移到各类任务——这无疑会引发行业巨变:AI公司将陷入军备竞赛,争相构建最丰富、最实用、工程最完善的任务集用于LLM强化学习,届时很可能有多家企业通过这种方式打造出“超级智能 LLM”。
至于此方式最终是否真的能通向超级人工智能,唯有交给时间来检验了

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)