Easy Dataset + 神州问学: 让大模型高效学习领域知识
EasyDataset简化了大型语言模型(LLM)微调数据集的生成流程,支持本地和云端模型调用。本教程演示了从互联网公司财报构建SFT微调数据的过程:1)通过Docker部署EasyDataset,上传财报文本并智能分割;2)调用DeepSeek等API生成问题-答案对;3)导出Alpaca/ShareGPT格式数据集。随后在神州问学平台微调Qwen3-0.6B模型,调整学习率至1e-4、训练8轮
Easy Dataset 能够简化生成大型语言模型(LLM)微调数据集的流程。支持上传特定领域的文件,智能分割内容,生成问题,并为模型微调生成高质量的训练数据。支持使用 OpenAI、DeepSeek等大模型 API 和 本地模型调用。
神州问学 依托平台既有能力,用户可,一键完成模型训练和部署,快速构建AI应用,轻松切换模型。
本教程使用 Easy Dataset 从互联网公司的公开财报构建 SFT 微调数据,并在 神州问学 中微调 Qwen3-0.6B模型,使微调后的模型能学习到财报数据集中的知识。
目录
一、使用 Easy Dataset 生成微调数据
安装 Easy Dataset
1. 从 GitHub 拉取 Easy Dataset 仓库
| Bashgit clone https://github.com/ConardLi/easy-dataset.gitcd easy-dataset |
|---|
2. 构建 Docker 镜像
| Bashdocker build -t easy-dataset . |
|---|
3. 运行容器
| Bashdocker run -d \ -p 1717:1717 \ -v {YOUR_LOCAL_DB_PATH}:/app/local-db \ --name easy-dataset \ easy-dataset |
|---|
示例数据准备
本教程准备了一批互联网公司公开的财报作为示例数据,包含五篇国内互联网公司 2024 年二季度的财报,格式包括 txt 和 markdown。数据均为纯文本数据,如下为节选内容示例。
快手二季度净利润增超七成,CEO程一笑强调可灵AI商业化
8月20日,快手科技发布2024年第二季度业绩,总营收同比增长11.6%至约310亿元,经调整净利润同比增长73.7%达46.8亿元左右。该季度,快手的毛利率和经调整净利润率均达到单季新高,分别为55.3%和15.1%。值得一提的是,针对今年加码的AI相关业务,快手联合创始人、董事长兼CEO程一笑在财报后的电话会议上表示,可灵AI将寻求更多与B端合作变现的可能性,也会探索将大模型进一步运用到商业化推荐中,提升算法推荐效率。
线上营销服务贡献近六成收入,短剧日活用户破3亿
财报显示,线上营销服务、直播和其他服务(含电商)收入依然是拉动快手营收的“三驾马车”,分别占总营收的56.5%、30.0%和13.5%。线上营销服务收入由2023年同期的143亿元增加22.1%至2024年第二季度的175亿元,财报解释主要是由于优化智能营销解决方案及先进的算法,推动营销客户投放消耗增加。
二、生成微调数据
创建项目并配置参数
1.在浏览器进入 Easy Dataset 主页后,点击创建项目

2.首先填写项目名称(必填),其他两项可留空,点击确认创建项目

3.项目创建后会跳转到项目设置页面,打开模型配置,选择数据生成时需要调用的大模型 API 接口

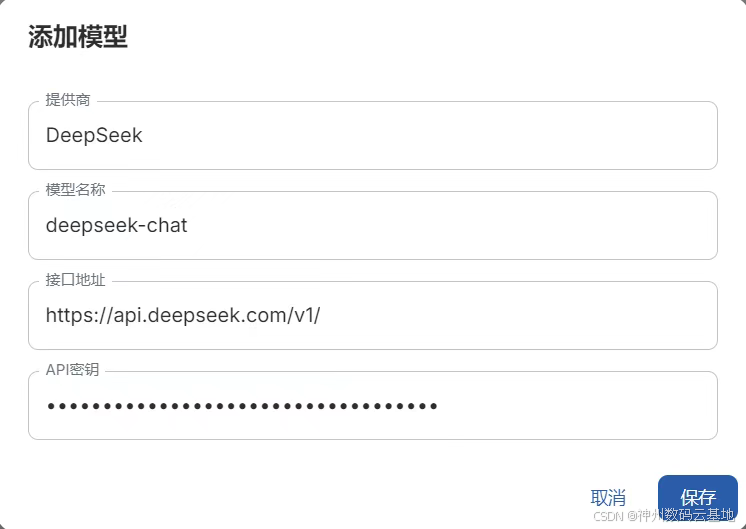
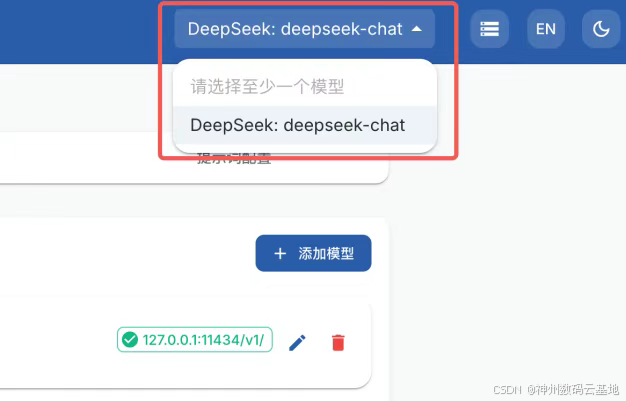
4.这里以 DeepSeek 模型为例,修改模型提供商和模型名称,填写 API 密钥,点击保存后将数据保存到本地,在右上角选择配置好的模型
5. 打开任务配置页面,设置文本分割长度为最小 500 字符,最大 1000 字符。在问题生成设置中,修改为每 10 个字符生成一个问题,修改后在页面最下方保存任务配置

处理数据文件
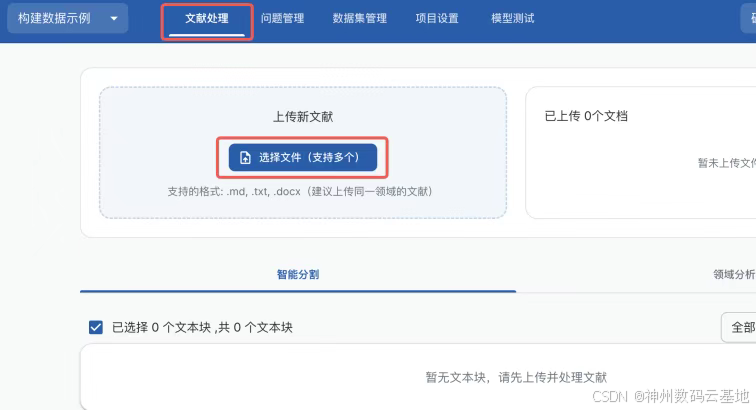
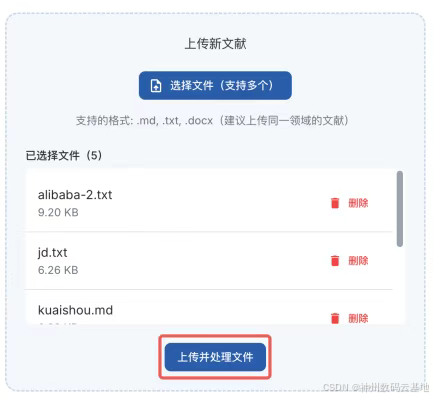
1.打开文献处理页面,选择并上传示例数据文件,选择文件后点击上传并处理文件
2.上传后会调用大模型解析文件内容并分块,耐心等待文件处理完成,示例数据通常需要 2 分钟左右

生成微调数据
1.待文件处理结束后,可以看到文本分割后的文本段,选择全部文本段,点击批量生成问题

2.点击后会调用大模型根据文本块来构建问题,耐心等待处理完成。视 API 速度,处理时间可能在 20-40 分钟不等

3.处理完成后,打开问题管理页面,选择全部问题,点击批量构造数据集,耐心等待数据生成。视 API 速度,处理时间可能在 20-40 分钟不等


如果部分问题的答案生成失败,可以重复以上操作再次生成。
导出数据集到 神州问学 平台微调模型
1.答案全部生成结束后,打开数据集管理页面,点击导出数据集

2.在导出配置中选择 导出到本地,选择需要导出的数据集格式(默认alpaca和shareGPT)即可在本地对应路径文件夹下生成配置文件。

3.在导出文件路径对应的文件夹中可以看到生成的数据文件,其中主要生成以下二个文件
- 在导出文件路径对应的文件夹中可以看到生成的数据文件,其中主要生成以下二个文件
- dataset_info.json:自定义格式的数据集配置文件
- alpaca.json:以 Alpaca 格式组织的数据集文件
- sharegpt.json:以 Sharegpt 格式组织的数据集文件
其中 alpaca 和 sharegpt 格式均可以用来微调,两个文件内容相同。

三、使用 神州问学 微调 Qwen3-0.6B 模型
1.在神州问学平台选择 数据集 板块,点击 上传文件数据集

2.上传从 Easy Dataset导出的数据集。

启动微调任务
1.在神州问学平台选择 大模型训练 ,上传选择创建的文件数据集

2.填写合适的训练参数和资源大小,选择模型为 Qwen3-0.6B,配置完成点击开始训练

为了让模型更好地学习数据知识,建议将学习率改为 1e-4,训练轮数提高到 8 轮。批处理大小和梯度累计则根据设备显存大小调整,在显存允许的情况下提高批处理大小有助于加速训练,一般保持批处理大小×梯度累积×显卡数量等于 32 即可,将保存间隔设置为 50,保存更多的检查点,有助于观察模型效果随训练轮数的变化
点击开始按钮,等待容器运行,拉取数据集,拉取模型,模型微调训练,合并模型,推送模型几个步骤完成,等待模型训练完毕,视显卡性能,训练时间可能在 20-60 分钟不等

验证微调效果
1.训练完成后,在大模型列表找到训练完的模型,点击部署,填写合适的资源大小等待模型部署完成



可同步查看模型部署阶段的日志

2.在下方的对话框中输入问题后,点击提交与模型进行对话,经与原始数据比对发现微调后的模型回答正确,证明微调有效。

微调后的回答如下:

| 0.6B 模型的微调效果相对有限,此处仅用作教程演示。如果希望得到更好的结果,建议在资源充足的条件下尝试 7B/14B 模型。 |
|---|

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)