【SpringAI 1.0.0】实现智能体工作流-路由模式(Routing)
引言
部分内容来自:Anthropic 最新长文:构建有效的智能体
智能体可以通过多种方式定义。Anthropic使用了新名词“智能体系统”(Agentic System),主要分为工作流(Workflow)和智能体(Agent,自主代理)两类,它们在架构上的主要区别如下。
(1)工作流是通过预定义的代码路径编排大模型和工具的系统。
(2)智能体是通过大模型动态规划流程和工具调用的系统。
首先构建智能体系统的基本构建模块是经过增强的LLM,例如添加检索、工具和记忆功能。我们目前的模型能够主动使用这些能力,包括生成自己的搜索查询、选择适当的工具以及决定保留哪些信息。
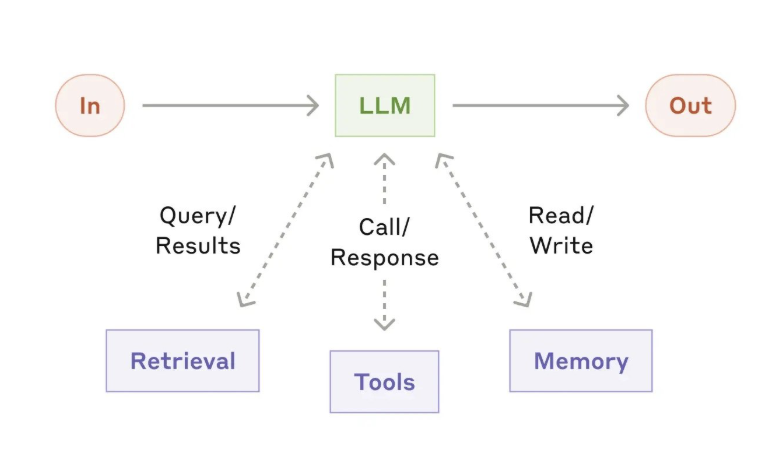
工作流常见的设计模式
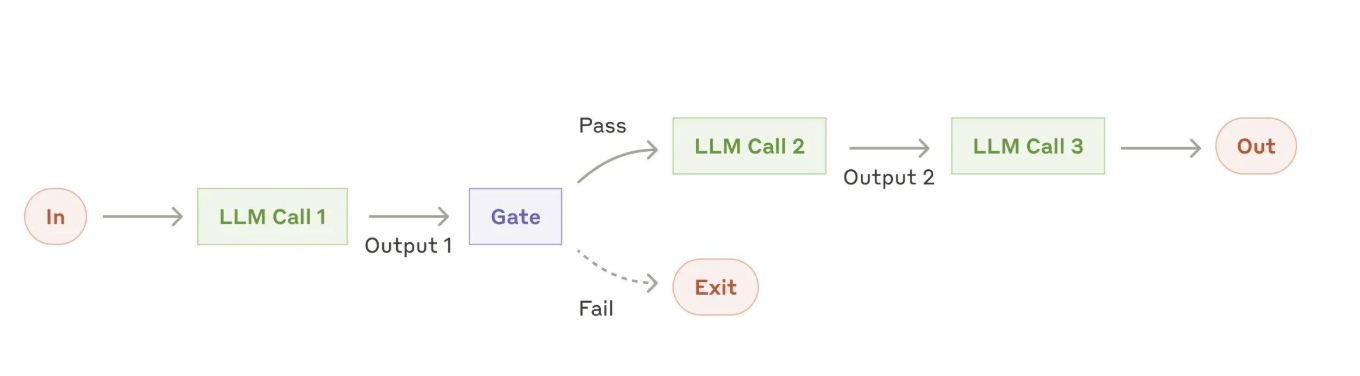
1、提示链(Prompt Chaining)
提示链将任务分解为一系列步骤,每次LLM调用都会处理前一步的输出。您可以在任何中间步骤添加程序化检查(如下图中的“gate”),以确保过程仍然正常进行。这种分解方式通常能提高准确性,代价是增加了延迟。
2、路由(Routing)
路由将输入分类并将其引导至特定的后续任务。此工作流允许分离关注点,并构建更专业化的提示。如果没有此工作流,为一种输入优化可能会影响其他输入的性能。
正如Anthropic所述:“路由机制对输入进行分类,并将其定向到专门的后续任务”,这种关注点分离的设计能避免单一提示试图处理所有问题。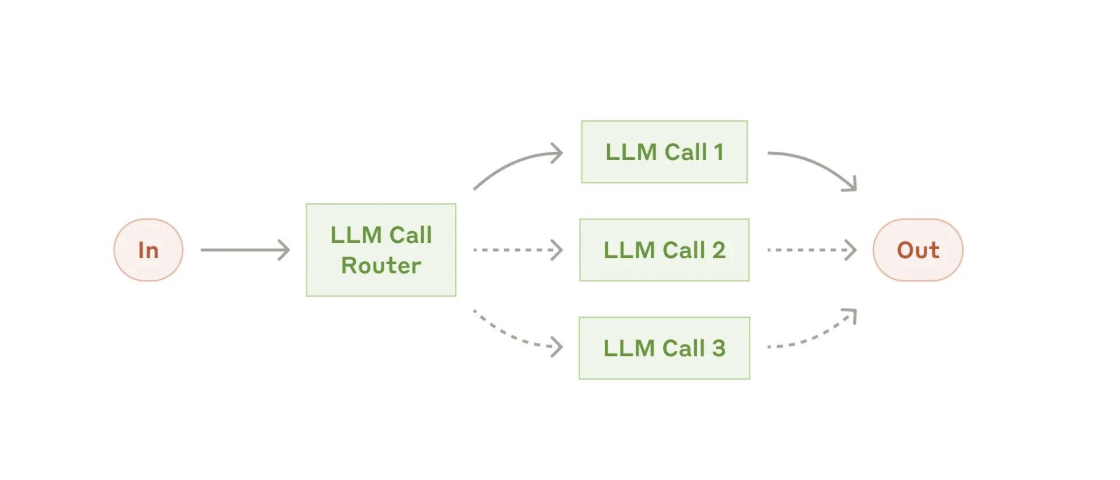
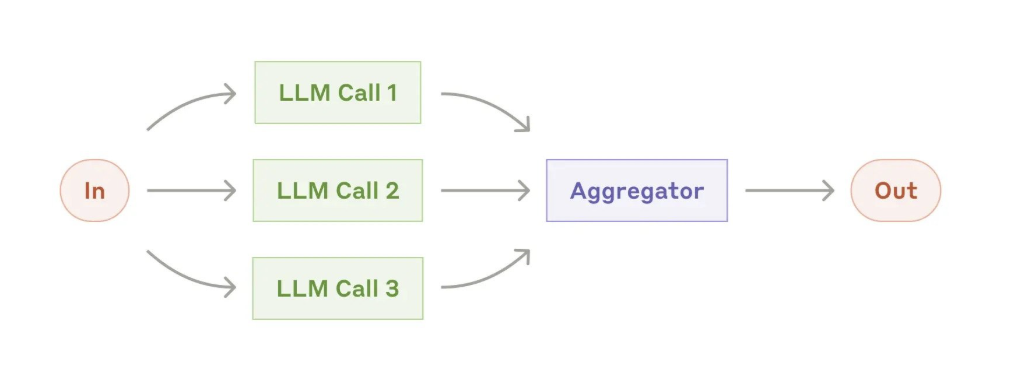
3、并行化(Parallelization)
LLM有时可以同时处理任务,其输出可以通过程序聚合。并行化工作流主要有两种关键形式:
- 分块:将任务分解为可并行运行的独立子任务。
- 投票:多次运行相同任务以获得多样化的输出。
正如LangChain开发者所述:“LLM有时能同步处理任务,并通过编程方式聚合输出结果”。
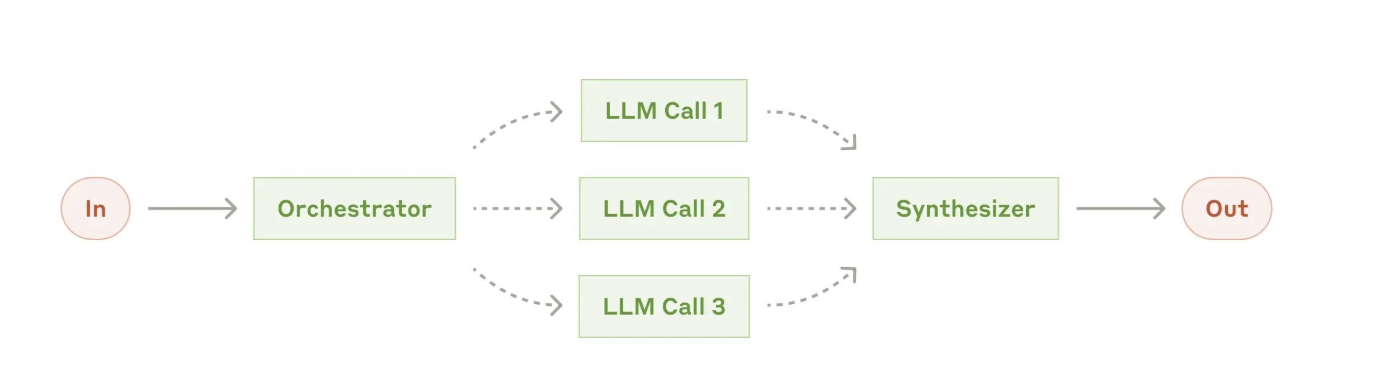
4、协调器-工作者模式(Orchestrator-Workers)
在协调器-工作者模式中,中心LLM动态分解任务,将任务分配给工作者LLM并综合它们的结果。
当任务复杂且无法预测所需的子任务时,此工作流非常适合(例如,在编程任务中,需要修改的文件数量及其每个文件的修改性质可能取决于任务的具体情况)。虽然其拓扑结构类似于并行化,但关键区别在于灵活性——子任务不是预定义的,而是由协调器根据具体输入确定的。
正如Anthropic所定义:“中央LLM动态分解任务、分配给工作者LLM执行,并合成最终结果”。这种模式特别适用于无法预判完整工作流的场景。
5、评估器-优化器模式(Evaluator-Optimizer)
在评估器-优化器模式中,一个LLM调用生成响应,而另一个提供评估和反馈,形成一个循环。
当我们有明确的评估标准,并且迭代优化能带来可测量的改进时,此工作流特别有效。适用的两个标志是:第一,当人类提出反馈时,LLM的响应能够显著改善;第二,LLM能够提供这样的反馈。这类似于人类作家在撰写精致文档时的迭代写作过程。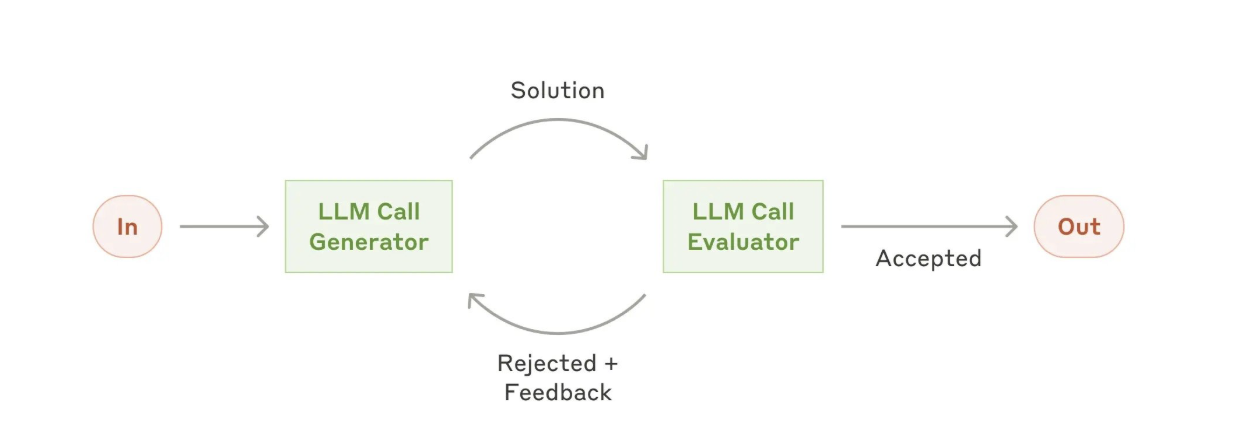
SpringAI实现简单路由模式
数据库设计
1、首先每个 client(LLM)需要自己的执行条件(图中的 condition ),然后每个 client 节点维护下一个节点。
这是 client 表,其中 rout 就是一个 LLM CallRouter,充当一个路由的作用。

代码实现
public class ClientNode {
private final Long clientId;
private final ChatClient clientInstance; // 实际的Client Bean
// key: condition (前一个client的输出), value: 下一个 ClientNode
private final Map<String, ClientNode> conditionalChildren = new HashMap<>();
private ClientNode defaultNextChild; // 如果condition为null/empty或无匹配时的默认下一个节点
public ClientNode(Long clientId, ChatClient clientInstance) {
this.clientId = clientId;
this.clientInstance = clientInstance;
}
public void addConditionalChild(String condition, ClientNode child) {
if (condition .equals("default") || condition.trim().isEmpty()) {
// 如果 condition 为空或空白字符串,视为默认的下一个节点
this.defaultNextChild = child;
} else {
this.conditionalChildren.put(condition, child);
}
}
public ClientNode getNextNode(String previousClientOutput) {
for(Object a:conditionalChildren.keySet().toArray()){
if(previousClientOutput.toLowerCase().contains((String)a)) {
return conditionalChildren.get(a);
}
}
if(defaultNextChild!=null){
return defaultNextChild;
}
return null;
}
}
public class ClientAssemblyService {
@Resource
private ApplicationContext applicationContext;
@Resource
private IAgentRepository agentRepository;
/**
* 根据Agent ID组装客户端流程节点网络。
* @param agentId 智能体ID
* @return 流程的起始节点列表 (没有被其他节点指向的节点)
*/
public ClientNode assembleClientFlow(Long agentId) {
Long aiClientId = agentRepository.queryHeadClientByAgentId(agentId);
List<AiAgentClientVO> relations = agentRepository.queryAgentClientConfigByAgentId(agentId);
if (relations == null || relations.isEmpty()) {
return new ClientNode(aiClientId,applicationContext.getBean("ChatClient_" + aiClientId, ChatClient.class));
}
Map<Long, ClientNode> clientNodeMap = new HashMap<>();
Set<Long> allClientIdsInFlow = new HashSet<>();
relations.forEach(r -> {
allClientIdsInFlow.add(r.getClientIdFrom());
if (r.getClientIdTo() != null) {
allClientIdsInFlow.add(r.getClientIdTo());
}
});
// 初始化所有节点
for (Long clientId : allClientIdsInFlow) {
try {
// 假设Bean的名称规则为 "clientBeanPrefix" + clientId
// 您需要根据实际的Bean命名规则调整
String beanName = "ChatClient_" + clientId;
ChatClient clientBean = applicationContext.getBean(beanName, ChatClient.class);
clientNodeMap.put(clientId, new ClientNode(clientId, clientBean));
} catch (Exception e) {
// 处理Bean未找到或类型不匹配的异常
// log.error("Failed to get or cast client bean for ID: {}", clientId, e);
// 可以选择抛出异常或跳过此节点
throw new RuntimeException("Failed to initialize client bean: " + clientId, e);
}
}
// 构建条件转换关系
for (AiAgentClientVO relation : relations) {
ClientNode parentNode = clientNodeMap.get(relation.getClientIdFrom());
ClientNode childNode = null;
if (relation.getClientIdTo() != null) {
childNode = clientNodeMap.get(relation.getClientIdTo());
}
parentNode.addConditionalChild(relation.getCondition(), childNode);
}
return clientNodeMap.get(aiClientId);
}
}
这边会根据前面的 client 去选择后面的 client。每次都会去访问节点的conditionalChildren,查找有没有可以执行的后续节点。如果没有就结束循环,返回结果。
public class FlowExecutorService {
@Resource
private ClientAssemblyService clientAssemblyService;
/**
* 执行指定Agent的客户端流程。
* @param agentId 智能体ID
* @param message 初始输入参数,可以是一个Map或自定义对象
* @return 最终的执行结果或状态
*/
public String executeAgentFlow(Long agentId, String message,String chatId) throws Exception {
ClientNode startNodes = clientAssemblyService.assembleClientFlow(agentId);
if (startNodes==null) {
// log.warn("No start nodes found for agentId: {}", agentId);
return "No flow configured or no start nodes found.";
}
// 简单起见,这里只执行第一个起始节点。实际可能需要更复杂的逻辑处理多个起始点。
ClientNode currentNode = startNodes;
List<Message> messages=new ArrayList<>();
String previousClientOutput;
int stepCount = 0; // 防止无限循环
int maxSteps = 100; // 最大执行步骤
UserMessage userMessage=new UserMessage(message);
messages.add(userMessage);
while (currentNode != null && stepCount < maxSteps) {
log.info("Executing client: {}, step: {}", currentNode.getClientId(), stepCount);
try {
ChatResponse response = currentNode.getClientInstance()
.prompt()
.messages(messages)
.system(s -> s.param("current_date", LocalDate.now().toString()))
.advisors(a -> a
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100))
.call().chatResponse();
previousClientOutput=response.getResult().getOutput().getText();
log.info("Client {} output: {}", currentNode.getClientId(), previousClientOutput);
UserMessage assistantMessage=new UserMessage(previousClientOutput);
if(currentNode.getConditionalChildren().isEmpty()){
messages.add(assistantMessage);
}
} catch (Exception e) {
// log.error("Error executing client: {}", currentNode.getClientId(), e);
// 可以选择中断流程,或者记录错误并尝试执行默认路径等
throw new RuntimeException("Error in client execution: " + currentNode.getClientId(), e);
}
ClientNode nextNode = currentNode.getNextNode(previousClientOutput);
if (nextNode == null) {
// log.info("Flow finished after client: {}. Final output: {}", currentNode.getClientId(), previousClientOutput);
return previousClientOutput; // 返回最后一个客户端的输出作为流程结果
}
currentNode = nextNode;
stepCount++;
}
if (stepCount >= maxSteps) {
// log.warn("Flow execution exceeded max steps for agentId: {}", agentId);
return "由于超过了最大步骤数,流程执行已中止。";
}
return "流程未按预期完成。"; // 如果currentNode为null但没有返回结果
}
}示例演示
这里做了一个简单的 json 标准化工具,如果是标准的,会直接输出是标准的,如果不是标准的会帮你修改再输出。
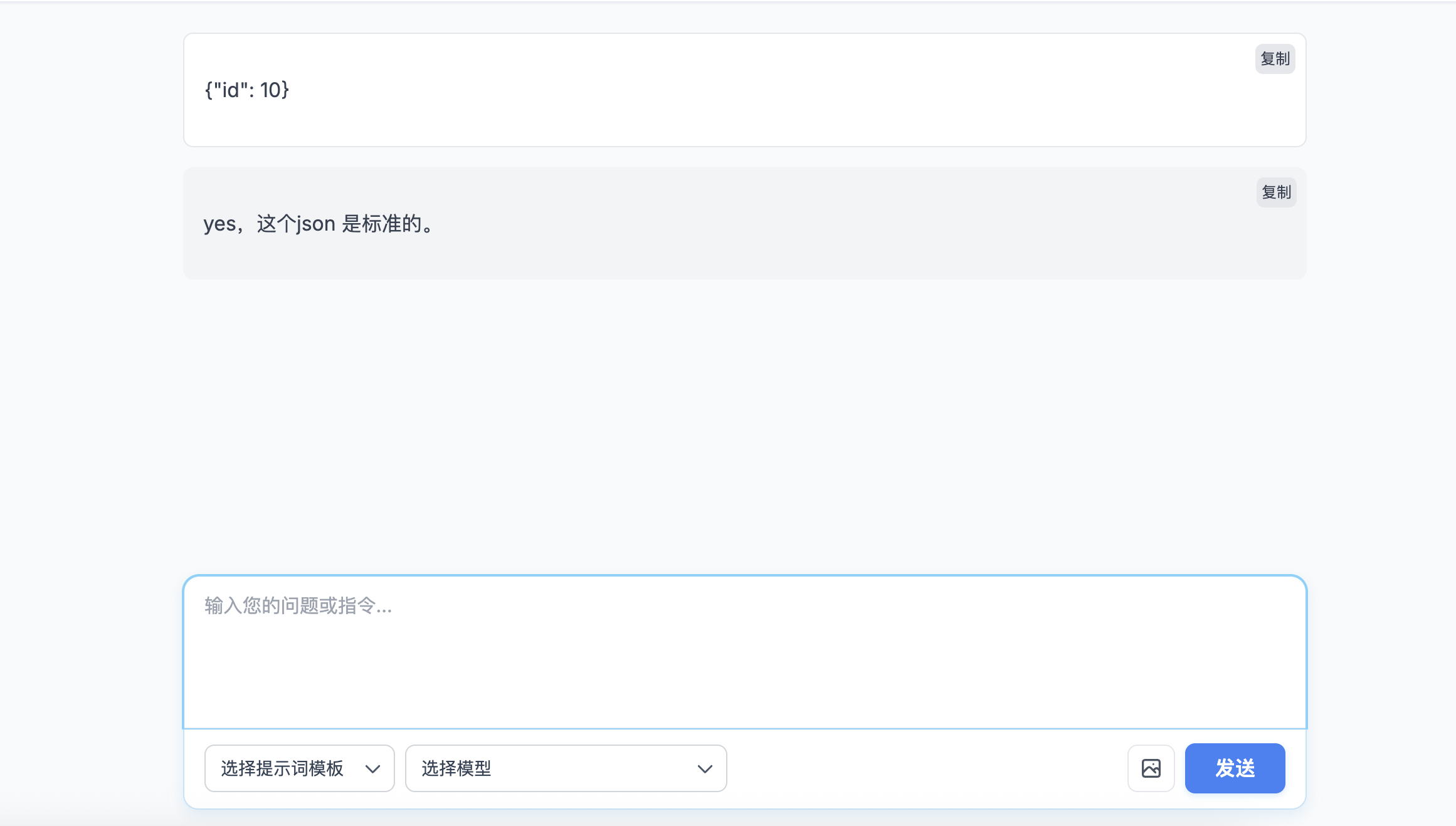
这边看一下控制台,现在只走了第一个步骤,判断正确后就直接返回。

现在输入一个错误的 json/你要转换为 json 的 prompt。
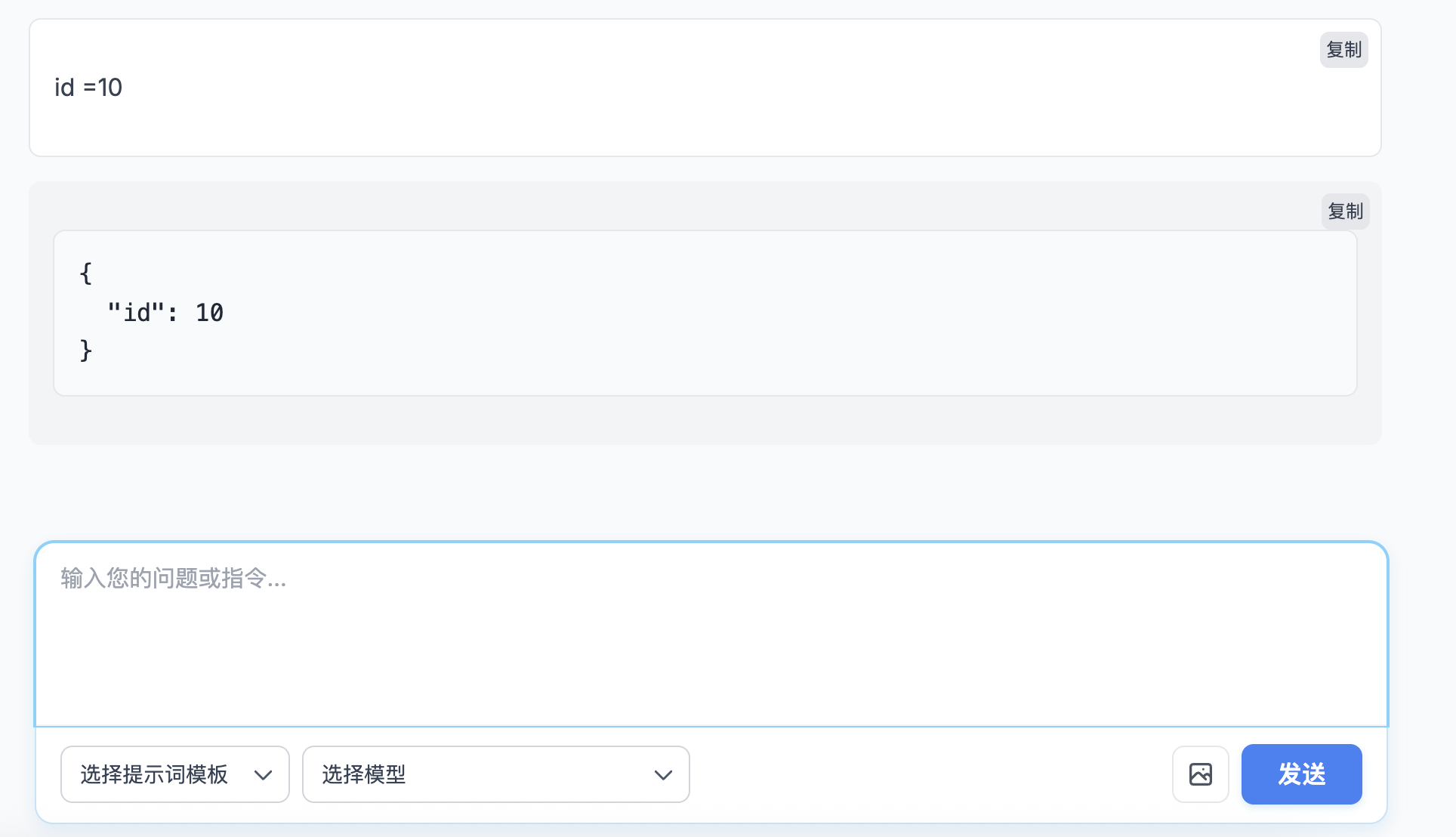
它直接给你返回了一个修改后的正确的 json,且控制台也能看出来走了两个 LLM。

这里只是一个简单的示例,实际可以配置的更复杂一点。
总结
正如Anthropic所述:“路由机制对输入进行分类,并将其定向到专门的后续任务”,这种关注点分离的设计能避免单一提示试图处理所有问题。
可将路由想象成一位友善的前台或客服总机:“您需要什么帮助?”——随后将您转接至对应部门。
若缺乏路由机制,开发者可能将所有规则塞进单一提示,试图一次性处理所有可能的输入,结果往往导致混乱或"样样通、样样松"的效果。而路由模式能让每个分支流程得到针对性优化。
适用场景:当你面对不同类别的请求,需要采取非常不同的处理方式(例如,文本摘要、翻译、分类等。
文章结尾
感谢大家的阅读,后续还会继续更新学习中的一些小知识。后续如有问题,欢迎在评论区留言!!!也欢迎联系我!(*^▽^*)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)