cmu15445(2024fall) project3
Project 3主要是实现BusTub中的查询执行部分的一些算子,同时补充一些查询优化的规则。BusTub采用iterator model,即迭代器模型 / 火山模型。project介绍中的background部分值得仔细阅读。其中涉及到bustub中的执行器架构、已经实现的部分与算子的介绍。下图中是关于Query Plan句法的一点介绍。Project 3 中,当使用 EXPLAIN 查看查询
文章目录
前言
Project 3主要是实现BusTub中的查询执行部分的一些算子,同时补充一些查询优化的规则。BusTub采用iterator model,即迭代器模型 / 火山模型。
project介绍中的background部分值得仔细阅读。其中涉及到bustub中的执行器架构、已经实现的部分与算子的介绍。下图中是关于Query Plan句法的一点介绍。

Project 3 中,当使用 EXPLAIN 查看查询计划时,#0.0 和 #0.1 这样的标记是 Bustub 查询计划表示法中的列引用。#0.0 表示:
- #0 引用的是计划中第 0 个子节点(输入关系)
- .0 表示该关系中的第 0 列(第一列)
#0.1 表示:
- #0 同样引用第 0 个子节点
- .1 表示该关系中的第 1 列(第二列)
如果有连接操作,会有类似 #1.2 的引用,这表示:
- #1 - 第1个子节点(第二个输入关系)
- .2 - 该关系中的第2列(第三列)
一、Task #1 - Access Method Executors
task 1主要实现用于读取和写入存储系统中的表的执行器。包括SeqScan、Insert、Update、Delete、IndexScan和Optimizing SeqScan to IndexScan。
两种scan算子与几种写表的算子实现相对简单,且有共同性。需要注意的点在于Next函数都是在返回false时停止上层循环,可以参考execution_engine.h中Execute函数的流程。seqscan和indexscan每次返回一个tuple且函数返回true,全部返回完毕后返回false。但insert、delete、update都是一次完成所有修改操作,返回一个tuple,tuple中value为插入/删除/更新的tuple数量,之后再Next会返回false,结束上层算子调用。
project 3的重点在于熟悉execution部分的代码,比前两个project的代码阅读量大。下面是execution部分重要代码结构的总结:
- ExecutorContext:存放算子上下文信息的重要类型,涉及事务、system catalog等
- Catalog:最常用的部分,是一个非持久性目录,旨在供 DBMS 执行引擎内的执行器使用。它处理表创建、表查找、索引创建和索引查找。
- TableInfo:TableInfo类维护有关表的元数据。其中的std::unique_ptr table_是常用的成员
- TableHeap:TableHeap 表示磁盘上的物理表,用于进行tuple的实际插入、删除、修改,实际操作table等。
- IndexInfo:IndexInfo类维护有关索引的元数据。其中的std::unique_ptr index_成员常使用。
- Index:不同类型的派生索引的基类。索引结构主要维护底层表的模式信息以及索引键和元组键之间的映射关系,并为外部世界提供了一种抽象的方式,以便与底层索引实现进行交互,而无需暴露实际实现的接口。除了简单插入、删除、谓词插入、点查询和全索引扫描之外,索引对象还处理谓词扫描。谓词扫描仅支持连接,并且可能会或可能不会根据谓词内部表达式的类型进行优化。
- expressions:各类表达式,如logic expression、column value expression、const value expression等,在filter谓词中会涉及到。
- 对于sql解析处理的全过程,可以参考文件src/common/busub_instance.cpp
阅读代码过程中,笔者对GetOutputSchema函数最初有很多疑问。GetOutputSchema
是执行器(executor)中的一个重要函数,它定义了每个算子输出数据的结构。GetOutputSchema 返回一个 Schema
对象,该对象描述了:
- 当前算子输出的列信息
- 每列的名称
- 每列的数据类型
- 列的排列顺序
这个信息对于查询执行至关重要,因为它让上层算子知道如何处理当前算子的输出,确保类型系统在整个执行计划中保持一致,为结果集提供元数据。不同算子的schema是可能不同的。
以Update 算子 (UpdateExecutor)为例:
- 输入 Schema:子执行器(通常是 Filter/SeqScan 等)的输出 Schema,包含要更新的行及其原始值
- 输出 Schema:通常是一个固定格式的单列 Schema。例如:(integer) 表示更新的行数,在 Bustub 中通常输出更新的记录数量。
GetOutputSchema函数则负责返回输出Schema。
SeqScan to IndexScan的优化规则实现是相对难一些的部分,简单来说就是在filter中涉及的列上有索引时,从seqscan转为indexscan。project中考虑较为简单的情况,index只在单列上,只考虑单点查询不考虑范围查询,在filter中涉及多列时不用转换。代码如下:
auto Optimizer::OptimizeSeqScanAsIndexScan(const bustub::AbstractPlanNodeRef &plan) -> AbstractPlanNodeRef {
// TODO(student): implement seq scan with predicate -> index scan optimizer rule
// The Filter Predicate Pushdown has been enabled for you in optimizer.cpp when forcing starter rule
std::vector<AbstractPlanNodeRef> children;
for (const auto &child : plan->GetChildren()) {
// 树结构,递归进行优化
children.emplace_back(OptimizeSeqScanAsIndexScan(child));
}
auto optimized_plan = plan->CloneWithChildren(std::move(children));
if (optimized_plan->GetType() == PlanType::SeqScan) {
const auto &seq_scan = dynamic_cast<const SeqScanPlanNode &>(*optimized_plan);
if (!seq_scan.filter_predicate_) {
return optimized_plan;
}
std::vector<AbstractExpressionRef> pred_keys;
std::vector<uint32_t> filter_column_ids;
// 这里利用dynamic_cast在对象不是目标类型的转换中失败时返回nullptr的机制,进行expression类型的检查
// 常见的多态机制
if (!Helper(pred_keys, filter_column_ids, seq_scan.filter_predicate_)) {
// 函数返回false表示不应该进行index_scan转换,不符合条件
return optimized_plan;
}
const auto table_info = catalog_.GetTable(seq_scan.GetTableOid());
const auto indices = catalog_.GetTableIndexes(table_info->name_);
for (const auto &index : indices) {
const auto &columns = index->index_->GetKeyAttrs();
if (filter_column_ids == columns) {
return std::make_shared<IndexScanPlanNode>(optimized_plan->output_schema_, seq_scan.GetTableOid(),
index->index_oid_, seq_scan.filter_predicate_, pred_keys);
}
}
}
return optimized_plan;
}
基本结构可以参考project中已经实现的几种优化器规则,基本流程都是一致的:对plan进行递归优化、优化前识别plan类型只对某种类型进行优化。
其中Helper函数最为关键,pre_keys为从filter中提取的要匹配的常数组成的数组,需要从seq_scan.filter_predicate_中提取,Helper函数主要进行这一工作,同时要提取filter_predicate_中涉及的列,与各个索引列比较是否为有索引的列。由于expression也有类似于树的结构,函数需要递归进行处理。函数中使用了dynamic_cast进行多态转换时类型不匹配时返回nullptr的特点,进行expression类型的判断,这一特点是这个函数的核心。
auto Helper(std::vector<AbstractExpressionRef> &pred_keys, std::vector<uint32_t> &filter_column_ids,
const AbstractExpressionRef &expr) -> bool {
const auto logic_expr = dynamic_cast<const LogicExpression *>(expr.get());
// 若logic_expr已经不可继续解析,即已经为比较表达式,则进行比较表达式的处理
if (logic_expr == nullptr) {
// 当expression不为逻辑表达式,则判断是否为单个的比较表达式,且需要为等式比较表达式
const auto comparison_expr = dynamic_cast<const ComparisonExpression *>(expr.get());
if (comparison_expr == nullptr || comparison_expr->comp_type_ != ComparisonType::Equal) {
// false表示不应该进行index_scan转换,不符合条件
return false;
}
auto column_value_expr = dynamic_cast<ColumnValueExpression *>(comparison_expr->GetChildAt(0).get());
// ConstantValueExpression *const_value_expr;
if (column_value_expr == nullptr) {
// const_value_expr = dynamic_cast<ConstantValueExpression *>(comparison_expr->GetChildAt(0).get());
column_value_expr = dynamic_cast<ColumnValueExpression *>(comparison_expr->GetChildAt(1).get());
pred_keys.emplace_back(comparison_expr->GetChildAt(0));
} else {
// const_value_expr = dynamic_cast<ConstantValueExpression *>(comparison_expr->GetChildAt(1).get());
pred_keys.emplace_back(comparison_expr->GetChildAt(1));
}
// 确认filter中列是否均为同一列,若不为同一列则直接返回false。均为同一列则将其存入column_value_expr中,column_value_expr中保持只有一个元素
if (filter_column_ids.empty()) {
filter_column_ids.emplace_back(column_value_expr->GetColIdx());
} else {
if (column_value_expr->GetColIdx() != filter_column_ids[0]) {
return false;
}
}
return true;
}
// 若logic_expr依旧可以解析,则继续解析
// 若不为or语句,没有必要转换为index scan,直接返回false
if (logic_expr->logic_type_ != LogicType::Or) {
return false;
}
return Helper(pred_keys, filter_column_ids, logic_expr->GetChildAt(0)) &&
Helper(pred_keys, filter_column_ids, logic_expr->GetChildAt(1));
}
下图可以对Expression表达式树的结构有比较清晰的认识,该图出自[2]。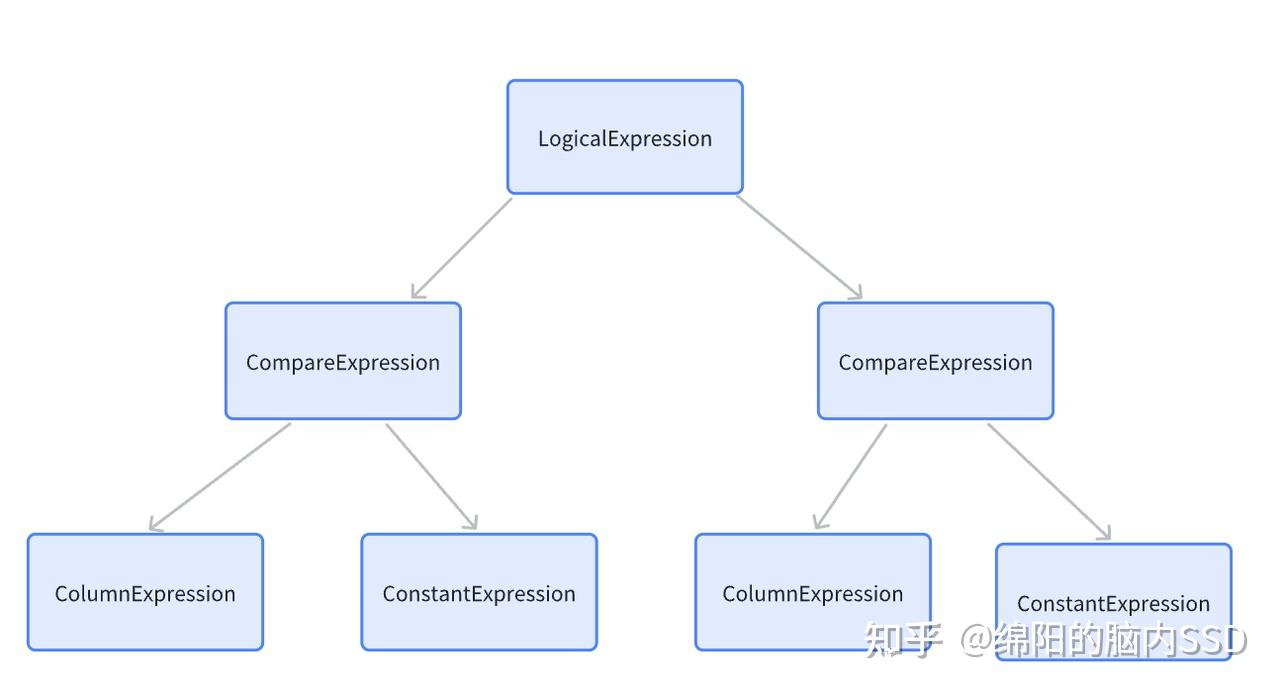
p.s. 在IndexScanExecutor实现过程中出现了project 2的bug:b+树迭代器中不应该存加锁的页面,不然会出现意外的死锁情况。
二、Task #2 - Aggregation & Join Executors
2.1 Aggregation
实现聚合的常用策略是使用哈希表,并以分组列作为键。在本项目中假设聚合哈希表可以装入内存。这意味着无需实现多阶段、基于分区的策略,并且哈希表也不需要由缓冲池页面支持,实现简化了很多。
最开始做的时候疑惑为什么枚举类AggregationType中没有DISTINCT类型。通过对Planer代码的分析,文件src/planner/plan_select.cpp中可见对DISTINCT的plan处理,其将DISTINCT转换为group by语句的处理方式,AggregationType为空类型。
// Plan DISTINCT as group agg
if (statement.is_distinct_) {
auto child = std::move(plan);
std::vector<AbstractExpressionRef> distinct_exprs;
size_t col_idx = 0;
for (const auto &col : child->OutputSchema().GetColumns()) {
distinct_exprs.emplace_back(std::make_shared<ColumnValueExpression>(0, col_idx++, col));
}
plan = std::make_shared<AggregationPlanNode>(std::make_shared<Schema>(child->OutputSchema()), child,
std::move(distinct_exprs), std::vector<AbstractExpressionRef>{},
std::vector<AggregationType>{});
}
几种聚合函数中count(*)较为特殊,计算包含了NULL值的行,下面是一些总结:
| 形式 | 行为描述 |
|---|---|
COUNT(*) |
计算所有行数,包括包含NULL值的行 |
COUNT(column_name) |
只计算指定列中非NULL值的行数 |
COUNT(1) / COUNT(0) |
与COUNT(*)效果相同,但在某些数据库引擎中可能有不同的优化处理 |
COUNT(DISTINCT column) |
计算指定列中不同非NULL值的数量(去重计数) |
p3中聚合函数返回类型统一为Integer,简化了实现。
当对一个空表使用 GROUP BY 时,查询总是返回空结果集(0行数据),原因如下:
(1)没有数据可分组的本质:
- GROUP BY 的工作原理是先获取数据,然后按照指定列分组
- 空表没有任何数据行,自然无法形成任何分组
- 没有分组就意味着没有结果行需要返回
(2)与聚合函数的区别:
- 单纯使用聚合函数(如 COUNT/SUM)会返回单行结果(COUNT=0,其他为NULL)
- 但 GROUP BY 要求按组返回结果,没有组就无法生成任何行
由此在对空表进行聚合函数操作时,其他聚合函数会返回null,而count(*)会返回0。这在GenerateInitialAggregateValue()函数可以看出。
Aggregation中要使用的哈希策略为:
1、child_executor_->Next(&tuple, &rid),解析出元组中的分组group by列和聚合列。
2、对于所有分组列构建一个组作为哈希表的Key。 对于所有聚合列保存起来等待聚合。这里project中提供了函数。
3、将键值对加入哈希表中。
p3中aggregation的outschema设计为group by中的列加上聚合的列。
auto AggregationPlanNode::InferAggSchema(const std::vector<AbstractExpressionRef> &group_bys,
const std::vector<AbstractExpressionRef> &aggregates,
const std::vector<AggregationType> &agg_types) -> Schema {
std::vector<Column> output;
output.reserve(group_bys.size() + aggregates.size());
for (const auto &column : group_bys) {
output.emplace_back(column->GetReturnType().WithColumnName("<unnamed>"));
}
for (size_t idx = 0; idx < aggregates.size(); idx++) {
// TODO(chi): correctly infer agg call return type
output.emplace_back("<unnamed>", TypeId::INTEGER);
}
return Schema(output);
}
2.2 NestedLoopJoin
可以根据课程内容设计,这部分的设计基本遵循naive nlj,实现的性能很差。如果要实现block nlj应该需要更多参数,涉及到正在处理的page id等。需要注意p3中只实现了inner join与left outer join,left outer join在处理中需要单独判断处理。
2.3 NestedIndexJoin
可以看一看Optimizer::OptimizeNLJAsIndexJoin加深理解,NestIndexJoinExecutor中只有一个child_executor,其与outer table相关,inner table直接用索引访问,plan中已经记录inner table、index的元数据,基本过程与nlj类似,但是内循环中对inner table使用index进行遍历。同样需要注意left outer join的处理。
三、Task #3 - HashJoin Executor and Optimization
3.1 HashJoin
HashJoin有一定的使用条件,主要为仅适用于 = 条件的连接,不适用于范围查询或其他比较操作,且on子句中条件谓词可以为用AND连接的多个 = 条件。更具体的使用条件在3.2中的查询优化部分。
HashJoin同样使用hash table进行处理,可以参考Aggregation中的实现哈希策略。这里笔者使用右表构建hash table,然后遍历左表所有tuple在hash table中查找,若识别成功则将两tuple连接成新tuple。
同时要注意不同的右表中tuple生成的HashJoinKey可能是一致的,所以HashJoinValue设计为Tuple数组,存储所有HashJoinKey相同的右表tuple。同时在左表tuple连接时,tuple数组中所有tuple都需要连接一次。每一次pull只会返回一个连接后的tuple, 所以我们要保存下来这些多余的连接元组,等待下一次pull返回,同时还需要记录当前已经连接到的tuple数组为止cursor。
struct HashJoinValue {
std::vector<Tuple> tuples_;
};
3.2 Optimizing NestedLoopJoin to HashJoin
哈希连接比嵌套循环连接性能好不少。当可以使用哈希连接时将 NestedLoopJoinPlanNode 转换为 HashJoinPlanNode进行优化。具体来说,当连接谓词是两列之间多个等值条件的结合时,可以使用哈希连接算法。根据文档,在本项目,只处理由 AND 连接的不同数量的等值条件。
这部分主要难点也在于表达式树的处理,同样通过递归处理。
- 判断当前过滤谓词的类型。若不为LogicExpression,则:
- 判断谓词是否为比较表达式类型,若不是或者比较类型不为相等比较,则返回false
- 若比较表达式左子表达式列属于Join左侧表,则写入left_key_expressions,反之写入right_key_expressions
- 比较表达式右子表达式类似处理
- 返回true
- 若为LogicExpression,则:
- 若logic_type不为AND,则返回false
- 递归处理谓词的左右子表达式
// 递归处理表达式树的函数
auto Helper(std::vector<AbstractExpressionRef> &left_key_expressions,
std::vector<AbstractExpressionRef> &right_key_expressions, const AbstractExpressionRef &predicate) -> bool {
const auto logic_expr = dynamic_cast<const LogicExpression *>(predicate.get());
if (logic_expr == nullptr) {
const auto comparison_expr = dynamic_cast<const ComparisonExpression *>(predicate.get());
if (comparison_expr == nullptr || comparison_expr->comp_type_ != ComparisonType::Equal) {
return false;
}
const auto col_value_expr_1 = dynamic_cast<const ColumnValueExpression *>(comparison_expr->GetChildAt(0).get());
if (col_value_expr_1->GetTupleIdx() == 0) {
left_key_expressions.emplace_back(comparison_expr->GetChildAt(0));
right_key_expressions.emplace_back(comparison_expr->GetChildAt(1));
} else {
right_key_expressions.emplace_back(comparison_expr->GetChildAt(0));
left_key_expressions.emplace_back(comparison_expr->GetChildAt(1));
}
return true;
}
if (logic_expr->logic_type_ != LogicType::And) {
return false;
}
return Helper(left_key_expressions, right_key_expressions, predicate->GetChildAt(0)) &&
Helper(left_key_expressions, right_key_expressions, predicate->GetChildAt(1));
}
四、Task #4: External Merge Sort + Limit Executors
4.1 External Merge Sort
24 fall和之前课程相比,加入了external merge sort的实现,之前均是对内部归并排序的实现。外部排序是中重点介绍的部分,project 3中对于external hash没有涉及,其实是极大简化了难度。这部分是收获最多的部分。
external merge sort与完全在内存实现的merge sort的区别在于需要排序的所有tuple可能没法全部放入内存进行操作,所以需要在排序过程中,将中间结果持久化到磁盘中,之后在需要时再读入内存进行操作。而根据课程介绍可以知道,merge sort的排序方式和契合于这样的特点。merge sort可以被分为一轮轮的run,每一轮的run可以作为中间结果持久化到磁盘中,在下一轮run时再取出继续排序。
SortPage
中间排序结果需要特定的页面格式。SortPage 是一个专用于存储中间排序结果的,SortPage的设计是这部分的难点。
/**
* Page to hold the intermediate data for external merge sort.
*
* Only fixed-length data will be supported in Fall 2024.
*
* Sort Page Format:
* 12
* ----------
* | HEADER |
* ----------
* ----------------------------------------------
* | Tuple(1) | Tuple(2) | ... | Tuple(n) |
* ----------------------------------------------
*
* HEADER Format:
* ----------------------------------
* | size_ | maxsize_ | tuple_size_ |
* ----------------------------------
*
* Tuple Format (after serialization):
* 4 schema.GetInlinedStorageSize()
* --------------------------------------
* | size | data |
* --------------------------------------
*
*/
基本结构就是Header + 元组区。为了保持紧凑,两者紧凑连接。对于Tuple的存储,可以看到Tuple类中实现了序列化与反序列化的函数:
void Tuple::SerializeTo(char *storage) const {
int32_t sz = data_.size();
memcpy(storage, &sz, sizeof(int32_t));
memcpy(storage + sizeof(int32_t), data_.data(), sz);
}
void Tuple::DeserializeFrom(const char *storage) {
uint32_t size = *reinterpret_cast<const uint32_t *>(storage);
this->data_.resize(size);
memcpy(this->data_.data(), storage + sizeof(int32_t), size);
}
Tuple类中有vector类的成员,vector中的元素存在内存的堆中,所以需要单独设计序列化的函数。可以看到SerializeTo()中将Tuple中data_的大小先存入storage的头部,相当于header的作用,提供必须的元数据,在DeserializeFrom()反序列化中可以看到利用size进行数据读取。所以序列化的Tuple大小为sizeof(uint32_t) + schema.GetInlinedStorageSize(),schema为Tuple对应的schema。
SortPage中设计的成员为:
/**
* TODO: Define the private members. You may want to have some necessary metadata for
* the sort page before the start of the actual data.
*/
// 元数据
int size_;
int max_size_;
int tuple_size_;
// tuples 元组数据区
char data_[];
之前笔者设计的为三个元数据加char data_,如果这样设计,内存中的数据布局与磁盘中会有不同。charl类型作为指针类型,在内存中需要占据4B或者8B,而指针数据存入磁盘是无意义的做法,再次的读入数据位置指针都会发生变化,所以指针的持久化是无意义的。这样内存中的布局与磁盘中将会不同,使用如下的类似B+tree中的、使用pageGuard的AsMut()函数进行磁盘page数据类型转换就会出现问题:
WritePageGuard page_guard = exec_ctx_->GetBufferPoolManager()->WritePage(page_id);
auto sort_page = page_guard.AsMut<SortPage>();
sort_page->Init(0, max_size, tuple_size);
当然也可以不使用这种方式进行转换,在SortPage的Init函数中自己设计反序列化的处理,不使用AsMut函数进行类型转换的方式,也是可以的。
补充信息:
data_ 指针的本质 指针的作用: data_ 是一个逻辑指针,用于在内存中访问元组数据区,其值是程序运行时的内存地址(如 0x7f8a3c00)。磁盘存储的无意义性: 写入指针的数值到磁盘毫无意义(下次程序运行时内存布局完全不同,地址无效)。
实际写入磁盘的内容 需要写入的是 data_ 指向的元组数据,而非指针本身
这部分加深了我对于持久化、序列化的认识,持久化处理在数据库中是常见的。
MergeSortRun
merge sort是一个递归/迭代的合并+排序过程,具有多轮次的特点,每个轮次中每组排序的元素数量相同(处理最后一组可能不同)。external merge sort类似。其中每组为一个MergeSortRun,排序过程中便可以根据MergeSortRun来组织排序。可以看到,run在一次次迭代中,其中包含的page数量会有1-2-4-…的变化,最终只留下一个run,run中所有page中所有tuple全局有序,则排序完成。
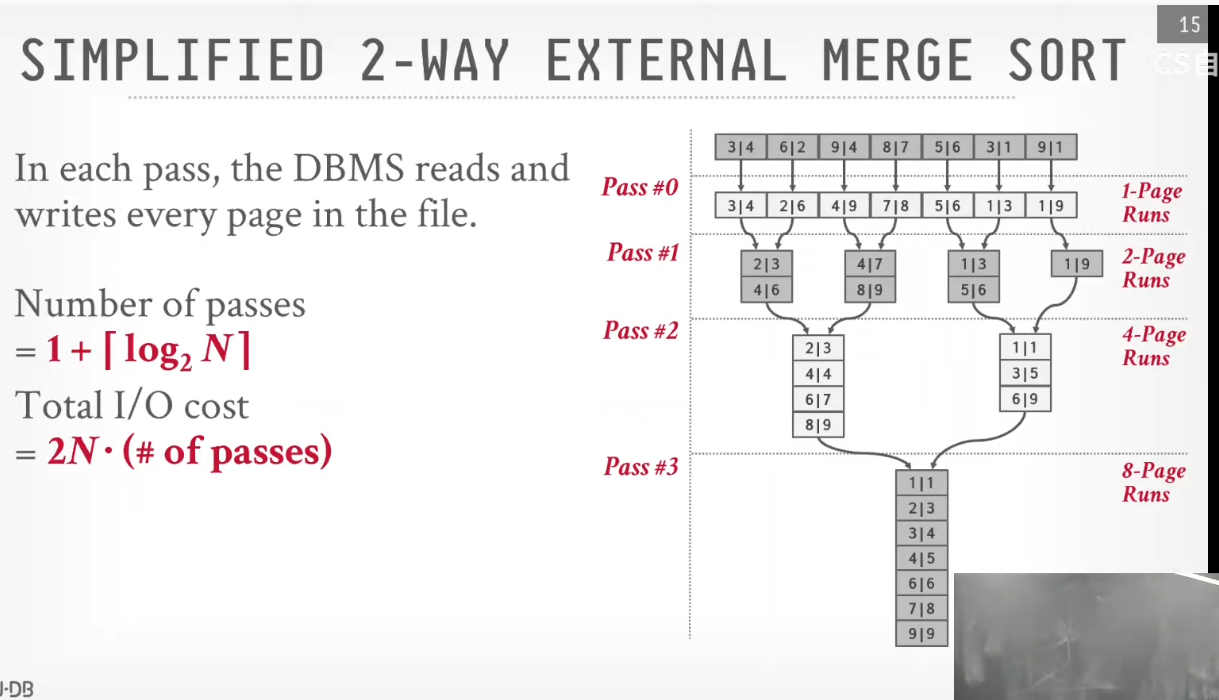
这里给出MergeSortRun的成员设计,根据这些成员可以设计出Iterator,利用Iterator可以按顺序读取一个run中的所有tuple。ReadPageGuard成员的加入是必要的,可以极大的提升读取速度,减少不必要的IO,在没加入时test中出现了超时的情况。(p.s. 之前B+tree的迭代器因为类似设计在p3的一个算子中出现了死锁,去掉了pageGuard成员。之后可以思考一下是否可以将其加回来又避免死锁情况)
private:
explicit Iterator(const MergeSortRun *run, size_t pages_idx, size_t tuple_idx)
: run_(run), pages_idx_(pages_idx), tuple_idx_(tuple_idx) {
if (pages_idx_ < static_cast<int>(run_->pages_.size())) {
page_guard_ = run_->bpm_->ReadPage(run_->pages_[pages_idx_]);
}
}
/** The sorted run that the iterator is iterating on. */
[[maybe_unused]] const MergeSortRun *run_;
/**
* TODO: Add your own private members here. You may want something to record your current
* position in the sorted run. Also feel free to add additional constructors to initialize
* your private members.
*/
// 目前所在的SortPage在pages_中的index
int pages_idx_;
// 目前所在SortPage内的tuple index
int tuple_idx_;
// 保存当前页面的ReadPageGuard,提高性能
// 之前没有设置这个,性能很差
ReadPageGuard page_guard_{};
Merge Sort
至此external merge sort的基本实现过程也已经清晰,可以根据上一张的情况设计,分为Pass #0和Pass #1,2,3…两类过程,Pass #0中获取每一个child_executor中的返回tuple,将其置于一个个SortPage中,对于每一个SortPage内部进行排序,每个run对应一个SortPage。之后的Pass #1,2,3…中,进行相邻run的排序,使用merge sort的方法,借助Iterator进行,生成新的MergeSortRun,以此类推。以上过程均在Init中进行。Next中每次读取一个全局排序完后的tuple。
笔者实现过程中,首先是出现了test超时的问题,通过减少中间存储结构(之前设计中用一个tuple数组存储所有tuple后再写入SortPage,在tuple量很大时,多出一次遍历处理性能会差很多,最终改为在排序中直接写page)和Iterator中加入ReadPageGuard减少冗余IO的方式减少了大量运行时间。之后在test中依旧有disk write次数过多的问题,总体来说解决方法可以有:
(1)将二路归并改为多路归并;
(2)在Pass #0中,初始MergeSortRun中的page数量不为1,设置为更多,如2、4等。这样可以减少迭代轮次,由此减少中间过程中创建的新page数量,从而减少磁盘写入次数。
在采用了第二种方法后,将初始page数量设置到4,满足了test中的disk write数量要求。
4.2 Limit
实现简单,计数返回对应数量的tuple即可。注意Init函数中对cnt赋0。
五、 重点难点 & 遇到的坑
1. dynamic_cast使用时常见多态技巧
dynamic_cast 返回 nullptr 的机制可以用于运行时子类类型的判断,这是一种常见的 C++ 多态技巧,称为 类型检查 + 安全向下转型(Type Checking + Safe Downcasting)。
由于 dynamic_cast 会在运行时检查对象的实际类型,如果转换失败(即对象不是目标类型或其派生类),它会返回 nullptr(指针)或抛出 std::bad_cast(引用)。因此,我们可以利用这个特性来判断一个基类指针/引用实际指向的是哪个子类。在Task 1中的查询优化中使用了这一特点。
需要注意的是:使用dynamic_cast时,基类必须有虚函数(virtual),否则 dynamic_cast 无法工作(编译错误或未定义行为)。因为 dynamic_cast 依赖 RTTI(Run-Time Type Information),而 RTTI 需要虚函数表支持。
2. shared_ptr和unique_ptr在函数返回类型中的隐式转换
函数返回类型为 std::shared_ptr 时,可以直接返回 std::unique_ptr,编译器会自动执行所有权转移(隐式调用 std::move),并正确构造 shared_ptr。这是 C++11 起支持的标准行为。
但是反过来,std::shared_ptr 不能 直接赋值或隐式转换为 std::unique_ptr,因为 shared_ptr 允许多个所有者,而 unique_ptr 要求独占所有权,编译器会阻止这种不安全的转换。
3. C++ 要求所有 没有默认构造函数的成员变量 必须在 构造函数的初始化列表 中初始化
4. 对函数返回值取地址&

在C或C++中,函数返回的值通常是一个临时对象(右值)。直接对函数返回值取地址(即使用&操作符)会导致编译错误,因为临时对象的地址无法被合法获取。
5. 自定义类型哈希的必要步骤
在实现Hash Join时设置哈希表成员时出现的报错:
无法引用 “std::unordered_map<bustub::HashJoinKey, bool, std::hashbustub::HashJoinKey, std::equal_tobustub::HashJoinKey, std::allocator<std::pair<const bustub::HashJoinKey, bool>>>” 的默认构造函数
因为笔者最开始没有为 HashJoinKey 提供 std::hash 的特化实现,所以编译器报错说无法使用std::unordered_map 的默认构造函数。根本原因为std::unordered_map 的底层是哈希表,它需要两个关键组件才能工作:
- 键的相等比较 - 通过 operator== 实现
- 键的哈希函数 - 原代码中缺少的部分
这里涉及到哈希表的基本原理,简单来说分为两步:计算哈希值(定位桶) 和 比较键值(解决冲突)。
| 步骤 | 操作 | 依赖条件 |
|---|---|---|
| 1. 哈希计算 | std::hash<Key> |
需为 Key 特化 std::hash |
| 2. 键比较 | operator== |
需为 Key 实现 operator== |
namespace std {
/** Implements std::hash on AggregateKey */
template <>
struct hash<bustub::HashJoinKey> {
auto operator()(const bustub::HashJoinKey &hash_join_key) const -> std::size_t {
size_t curr_hash = 0;
for (const auto &key : hash_join_key.columns_) {
if (!key.IsNull()) {
curr_hash = bustub::HashUtil::CombineHashes(curr_hash, bustub::HashUtil::HashValue(&key));
}
}
return curr_hash;
}
};
} // namespace std
上方这段代码是为 bustub::HashJoinKey 类型特化标准库中的 std::hash 模板,实现了一个哈希函数,使得 HashJoinKey 可以作为 std::unordered_map 或 std::unordered_set 的键使用。这是实现自定义类型哈希的必要步骤。这段代码可以参照AggregateKey的对应实现。其中主要涉及到对Value类型的哈希。
std::hash 是 C++ 标准库提供的一个函数对象模板,用于计算各种数据类型的哈希值。它是实现哈希表(如 std::unordered_map、std::unordered_set)的核心组件。其核心作用为:
- 为键类型生成哈希值:将任意类型的键(如 int、string 或自定义类)转换为 size_t 类型的哈希值,供哈希表快速定位存储位置。
- 支撑无序容器:std::unordered_map 和 std::unordered_set 依赖 std::hash 实现高效的插入、查找和删除操作(平均时间复杂度 O(1))。
6. 数据库中的数据存储方式,序列化与反序列化
当需要持久化时,应该:
- 将对象"序列化"为字节流写入原生数组
- 读取时再从字节流"反序列化"重建对象
这种设计是数据库系统实现的基础范式,确保了数据的安全存储和高效访问。
关于vector的持久化,需要清楚的是,vector 的元素在堆上,如果直接将一个包含 std::vector 成员的类对象转换为 char* 并写入磁盘,会导致 严重的数据错误,原因如下:
- 代码举例
class MyClass {
public:
std::vector<int> data;
int id;
};
MyClass a;
a.data = {1, 2, 3};
a.id = 42;
// 危险操作:直接转换为 char* 写入文件
char* raw_data = reinterpret_cast<char*>(&a);
std::ofstream out("bad.bin", std::ios::binary);
out.write(raw_data, sizeof(a)); // 严重错误!
std::vector 的底层数据不在对象内,vector 内部只存储元信息(指向堆内存的指针、大小、容量等),实际数据在堆上。写入 sizeof(MyClass) 只会保存 vector 的 控制结构,而不会保存其管理的实际数据。写入的是无效指针,vector.data() 返回的堆内存指针会被当作普通字节写入文件,但重新加载时,指针值无效(指向原内存地址,加载后失效)。堆数据完全丢失。
- 正确做法:手动序列化
class MyClass {
public:
std::vector<int> data;
int id;
void writeToFile(const std::string& filename) {
std::ofstream out(filename, std::ios::binary);
// 1. 写入 id
out.write(reinterpret_cast<char*>(&id), sizeof(id));
// 2. 写入 vector 大小
size_t size = data.size();
out.write(reinterpret_cast<char*>(&size), sizeof(size));
// 3. 写入 vector 数据
out.write(reinterpret_cast<char*>(data.data()), size * sizeof(int));
}
void readFromFile(const std::string& filename) {
std::ifstream in(filename, std::ios::binary);
// 1. 读取 id
in.read(reinterpret_cast<char*>(&id), sizeof(id));
// 2. 读取 vector 大小
size_t size;
in.read(reinterpret_cast<char*>(&size), sizeof(size));
// 3. 读取 vector 数据
data.resize(size);
in.read(reinterpret_cast<char*>(data.data()), size * sizeof(int));
}
};
- 总结
绝对不要 直接将含 vector 的类转换为 char* 写入文件。正确做法为手动序列化,依次写入 vector 的大小和数据内容。这里可以参考project 3中tuple的序列化与反序列化。
总结
project 3是个人认为前三个project中最难的,主要难点在于阅读代码量最大,涉及的模块较多,需要对execution engine部分的代码较深入的阅读。同时在leaderboard部分的三个Query优化还未进行,之后都是可以优化的方向。
Reference
[1] CMU Fall 2024 15-445 P3[待优化]&PaperNotes - Refrain的文章 - 知乎
https://zhuanlan.zhihu.com/p/5843407385
[2] CMU15445-2024fall-project3踩坑经历 - 绵阳的脑内SSD的文章 - 知乎
https://zhuanlan.zhihu.com/p/1932548792231634392

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)