Langchain入门:构建一个聊天机器人
我们将通过一个示例来设计和实现一个基于大型语言模型的聊天机器人。这个聊天机器人将能够进行对话并记住之前的互动。
我们将通过一个示例来设计和实现一个基于大型语言模型的聊天机器人。 这个聊天机器人将能够进行对话并记住之前的互动。
消息历史
我们可以使用消息历史类来包装我们的模型,使其具有状态。 这将跟踪模型的输入和输出,并将其存储在某个数据存储中。 未来的交互将加载这些消息,并将其作为输入的一部分传递给链
安装 langchain-community,因为我们将使用其中的集成来存储消息历史:
pip install langchain_community
构建model:
model = ChatOpenAI(
openai_api_base = "https://api.siliconflow.cn/v1/",
openai_api_key = os.environ['siliconflow'],
model_name = "Qwen/Qwen3-8B", # 模型名称
)
之后,我们可以导入相关类并设置我们的链,该链包装模型并添加此消息历史。这里的一个关键部分是我们作为 get_session_history 传入的函数。这个函数预计接受一个 session_id 并返回一个消息历史对象。这个 session_id 用于区分不同的对话,并应作为配置的一部分在调用新链时传入
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
with_message_history = RunnableWithMessageHistory(model, get_session_history)
我们现在需要创建一个 config,每次都传递给可运行的部分。这个配置包含的信息并不是直接作为输入的一部分,但仍然是有用的。在这种情况下,我们想要包含一个 session_id。
config = {"configurable": {"session_id": "abc2"}}
config 参数是用于配置 RunnableWithMessageHistory 行为的配置字典,主要用于指定会话管理的相关设置
from langchain_core.messages import HumanMessage
response = with_message_history.invoke([HumanMessage(content="你好!我是Bob")], config=config)
response.content

response = with_message_history.invoke([HumanMessage(content="你知道我的名字吗?")], config=config)
response.content

我们的聊天机器人现在记住了关于我们的事情。如果我们更改配置以引用不同的 session_id,我们可以看到它开始新的对话。
config = {"configurable": {"session_id": "abc3"}}
response = with_message_history.invoke(
[HumanMessage(content="你知道我的名字吗?")],
config=config,
)
response.content

然而,我们始终可以回到原始对话(因为我们将其保存在数据库中)
config = {"configurable": {"session_id": "abc2"}}
response = with_message_history.invoke(
[HumanMessage(content="你知道我的名字吗?")],
config=config,
)
response.content

提示词模板
提示词模板帮助将原始用户信息转换为大型语言模型可以处理的格式。在这种情况下,原始用户输入只是一个消息,我们将其传递给大型语言模型。现在让我们使其变得更复杂一些。首先,让我们添加一个带有一些自定义指令的系统消息(但仍然将消息作为输入)。接下来,我们将添加除了消息之外的更多输入。
首先,让我们添加一个系统消息。为此,我们将创建一个 ChatPromptTemplate。我们将利用 MessagesPlaceholder 来传递所有消息。
MessagesPlaceholder 是 LangChain 中用于在提示模板中预留消息列表位置的占位符组件
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[(
"system",
"You are a helpful assistant. Answer all questions to the best of your ability."
),
MessagesPlaceholder(variable_name="messages")]
)
chain = prompt | model
我们现在传递的是一个包含 messages 键的字典,其中包含一系列消息,而不是传递消息列表。
response = chain.invoke({"messages": [HumanMessage(content="Hi! I'm bob")]})
response.content
我们现在可以将其包装在与之前相同的消息历史对象中
with_message_history = RunnableWithMessageHistory(chain, get_session_history)
config = {"configurable": {"session_id": "abc5"}}
response = with_message_history.invoke(
[HumanMessage(content="Hi! I'm Jim")],
config=config
)
response.content

现在让我们使我们的提示变得更复杂一点。假设提示模板现在看起来像这样:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. Answer all questions to the best of your ability in {language}.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
chain = prompt | model
我们在提示中添加了一个新的 language 输入。我们现在可以调用链并传入我们选择的语言。
response = chain.invoke(
{
"messages": [HumanMessage(content="Hi! I'm Bob")],
"language": "Chinese",
}
)
response.content

现在让我们将这个更复杂的链封装在一个消息历史类中。这次,由于输入中有多个键,我们需要指定正确的键来保存聊天历史。
input_messages_key 参数用于指定输入数据中哪个键包含当前的消息列表
with_message_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="messages",
)
config = {"configurable": {"session_id": "abc11"}}
response = with_message_history.invoke(
{
"messages":[HumanMessage(content="Hi! I'm Todd")],
"language": "Chinese",
},
config=config
)
response.content

response = with_message_history.invoke(
{"messages": [HumanMessage(content="whats my name?")], "language": "Chinese"},
config=config,
)
response.content

管理对话历史
构建聊天机器人时,一个重要的概念是如何管理对话历史。如果不加以管理,消息列表将无限增长,并可能溢出大型语言模型的上下文窗口。因此,添加一个限制您传入消息大小的步骤是很重要的。
您需要在提示模板之前但在从消息历史加载之前的消息之后执行此操作。
我们可以通过在提示前添加一个简单的步骤,适当地修改 messages 键,然后将该新链封装在消息历史类中来实现。
from langchain_core.messages import SystemMessage, trim_messages, AIMessage
trimmer = trim_messages(
max_tokens=10,
strategy="last", # 保留最新对话
token_counter=len, # 指定如何计算 token 数量
include_system=True, # 是否保留系统提示
allow_partial=False, # 保持消息完整性
start_on="human" # 指定从哪个消息类型开始保留
)
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
]
trimmer.invoke(messages)
要在我们的链中使用它,我们只需在将 messages 输入传递给提示之前运行修剪器。现在如果我们尝试询问模型我们的名字,它将不知道,因为我们修剪了聊天历史的那部分:
RunnablePassthrough: 将输入数据原样传递到下一步,同时可以添加或修改字段
.assign(): 为输入数据分配新的字段或修改现有字段
itemgetter(“messages”): 从输入字典中提取 “messages” 字段的值
from operator import itemgetter
from langchain_core.runnables import RunnablePassthrough
chain = (
RunnablePassthrough.assign(messages=itemgetter("messages") | trimmer)
| prompt | model
)
response = chain.invoke(
{
"messages": messages + [HumanMessage(content="whats my name?")],
"language": "Chinese",
}
)
response.content
但是如果我们询问最近几条消息中的信息,它会记住
response = chain.invoke(
{
"messages": messages + [HumanMessage(content="what math problem did i ask")],
"language": "Chinese",
}
)
response.content

现在让我们将其包装在消息历史中
with_message_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="messages",
)
config = {"configurable": {"session_id": "abc20"}}
response = with_message_history.invoke(
{
"messages": messages + [HumanMessage(content="What's my name?")],
"language": "Chinese",
},
config=config
)
response.content

正如预期的那样,我们声明姓名的第一条消息已被删除。此外,聊天历史中现在有两条新消息(我们最新的问题和最新的回答)。这意味着以前可以在我们的对话历史中访问的更多信息现在不再可用!在这种情况下,我们最初的冰淇淋讨论也已从历史中删除,因此模型不再知道它:
response = with_message_history.invoke(
{
"messages": [HumanMessage(content="what did i said about ice cream?")],
"language": "Chinese",
},
config=config,
)
response.content

这部分内容比较绕,笔者整理出代码运行的逻辑链条: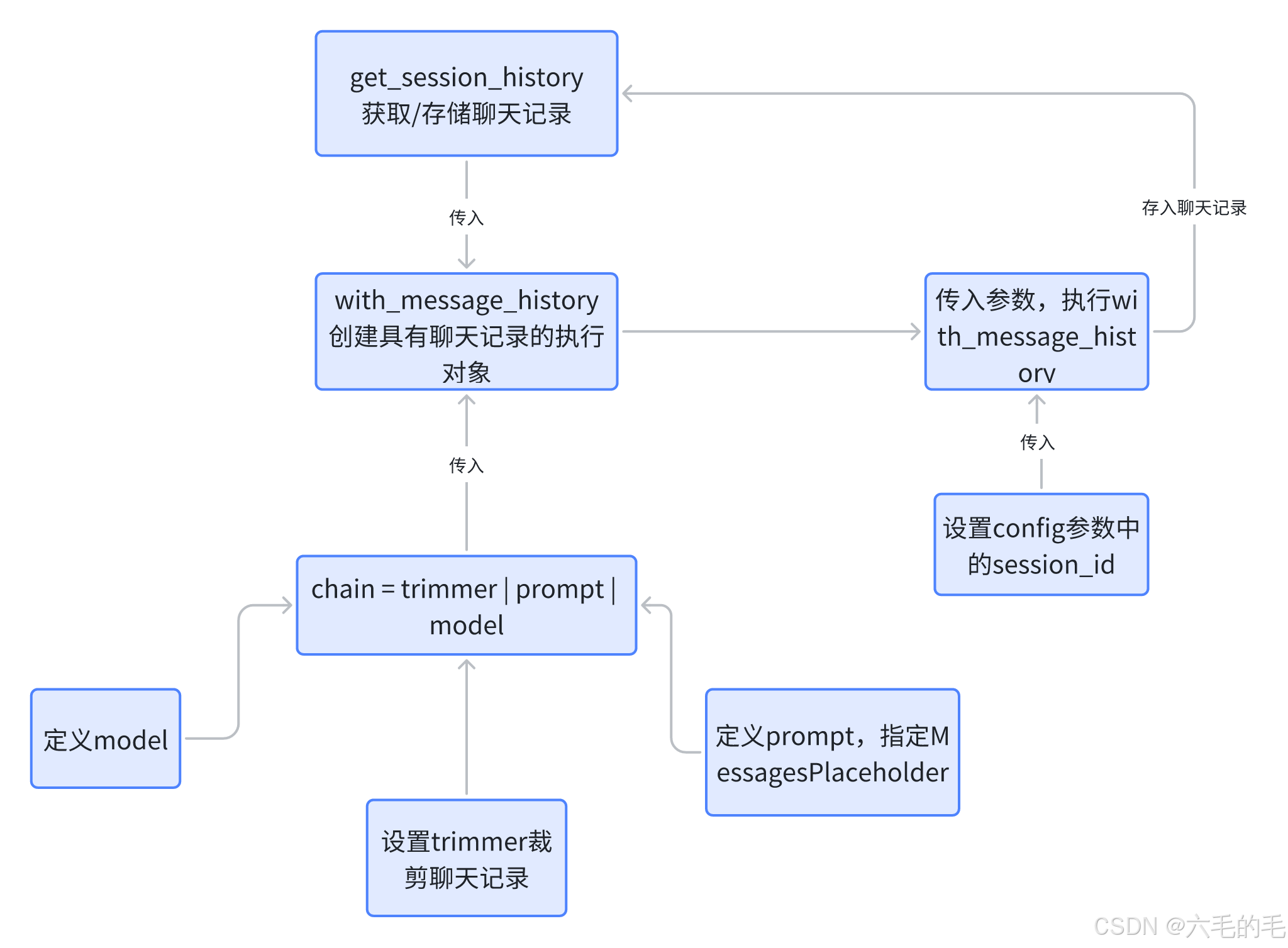
流式处理
现在我们有了一个功能齐全的聊天机器人。然而,对于聊天机器人应用程序来说,一个非常重要的用户体验考虑是流式处理。大型语言模型有时可能需要一段时间才能响应,因此为了改善用户体验,大多数应用程序所做的一件事是随着每个令牌的生成流回。这样用户就可以看到进度。
所有链都暴露一个.stream方法,使用消息历史的链也不例外。我们可以简单地使用该方法获取流式响应。
stream() 是 LangChain 中 Runnable 对象的流式输出方法,用于实时接收模型的响应内容,而不是等待完整响应后再返回
config = {"configurable": {"session_id": "abc15"}}
for r in with_message_history.stream(
{
"messages": [HumanMessage(content="hi! I'm Maria. Tell me a joke.")],
"language": "Chinese",
},
config=config,
):
print(r.content, end="|")

没听懂

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)