Token的数值化,从文本到向量
这三个技术本质上都是为了弥补模型对 “文本结构信息” 的天然缺失:位置编码→补充 “顺序信息”;分段嵌入→补充 “片段边界信息”;Chat 格式对齐→补充 “对话角色与轮次信息”。它们共同作用,让模型能更准确地理解复杂文本的语义和结构,是大模型实现高质量输出的基础。
我们日常与大模型进行交互,是用的都是文本词句,那么大模型是如何理解文本的呢?这就涉及到文本的数值化,使其由人类可以理解的自然语言变化为大模型可以理解的向量。总的来说,就是:文本 → token → ID → embedding(向量)
1、总览
文本数据在送入大模型(如 GPT、DeepSeek、Qwen)时,会依次经历以下步骤:
- 分词(Tokenization):将文本切分为 token;
- 数值编码(Numericalization):将每个 token 映射为一个整数 ID;
- 词嵌入(Embedding):通过查表将每个 token ID 映射为一个向量;
- 输入 transformer 层:开始前向传播。
2、 分词
token 是模型的最小处理单位,可能是一个字、一个词,甚至是一个词的一部分。不同模型使用不同分词器(tokenizer):
| 模型系列 | 分词方式 | 举例(输入 “苹果手机很好用”) |
|---|---|---|
| GPT-2/GPT-3 | BPE (Byte Pair Encoding) | [“苹果”, “手机”, “很好”, “用”] |
| GPT-4(OpenAI) | tiktoken | [“苹”, “果”, “手机”, “很”, “好”, “用”] |
| LLaMA/Qwen/DeepSeek | SentencePiece/BPE | [“苹果”, “手机”, “很”, “好”, “用”] |
| 可以看一段示例代码: |
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-llm-7b-chat")
text = "苹果手机很好用"
tokens = tokenizer.tokenize(text)
ids = tokenizer.convert_tokens_to_ids(tokens)
print("Tokens:", tokens)
print("Token IDs:", ids)
注意:分词器AutoTokenizer所加载的文件本质上并不是常规意义上大体积的模型权重文件,分词器(Tokenizer)的 “权重” 实际上是一系列配置文件(而非神经网络权重),用于定义分词规则、词汇表等核心信息。这些关键文件始终是模型仓库的一部分:
分词器的核心文件构成,分词器的 “权重” 本质是一套描述分词逻辑的配置,包含但不限于:
| 文件名 | 作用 | 格式类型 |
|---|---|---|
tokenizer.model |
主体词表(二进制格式) | SentencePiece(Qwen、T5) |
tokenizer.json |
序列化的 vocab & merge 数据 | BPE 格式(LLaMA) |
tokenizer_config.json |
分词器配置(如是否 lowercasing) | JSON |
vocab.json |
token → string 的映射表(BPE 用) | JSON |
merges.txt |
BPE 合并规则(字符对合并) | Text |
special_tokens_map.json |
特殊 token ID 定义,如 <bos> |
JSON |
added_tokens.json |
用户自定义 token(如 <image>) |
JSON |
这些文件是模型正常工作的必备组件,所有公开发布的模型仓库(包括 Hugging Face Hub)都会包含这些文件,否则分词器无法正常初始化。
例如hugging face中deepseek-prover-7B模型的全文件: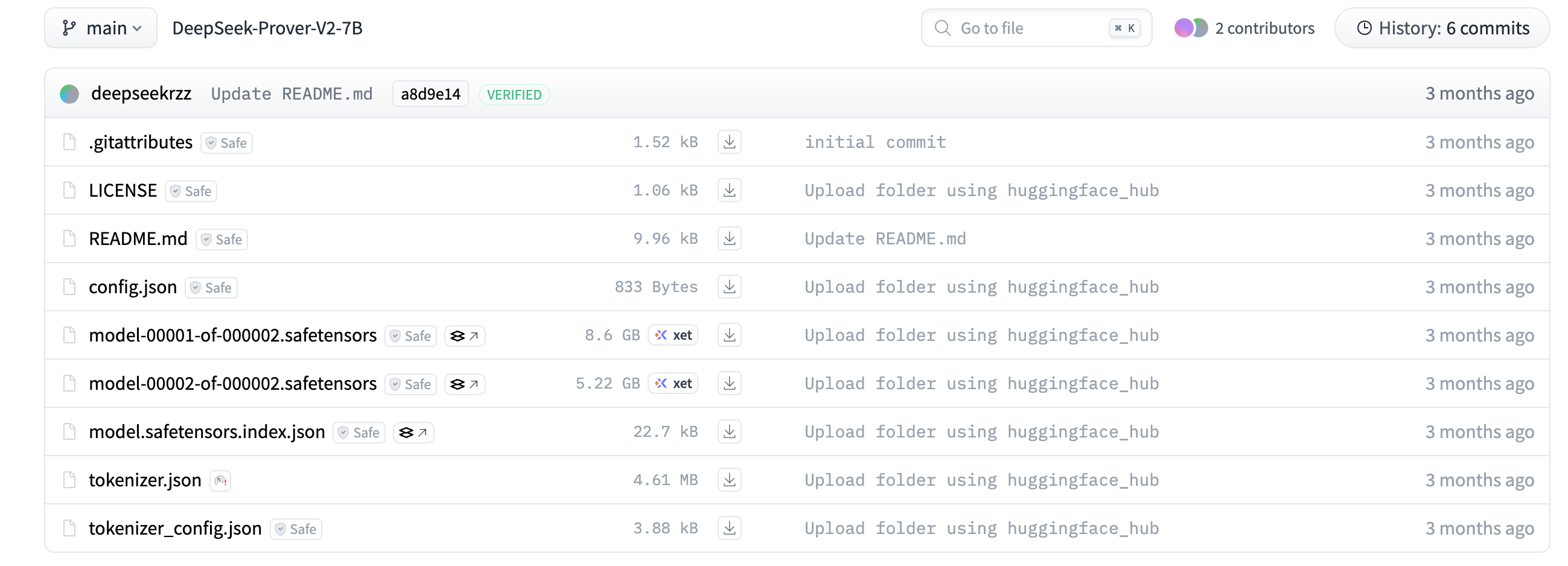
2.1 数值编码和编码
此部分即为Numericalization(转换为 token ID),也就是将文本按照上文的过程分离成离散的token。此时引入Embedding Lookup Table(词嵌入查找表),查找得到token唯一对应的向量:
该表是大语言模型中非常关键的部分,是将离散的 token ID 映射成连续向量空间表示的核心机制。
Embedding Lookup Table是需要跟随模型训练的,凝结在大模型的训练权重文件中,Embedding Lookup Table 是一个矩阵,形状通常是:[vocab_size, hidden_dim],其中vocab_size:词表大小(例如 Qwen3-7B 是 151936),hidden_dim:每个 token 的向量维度(如 Qwen3-7B 是 4096);注意这两个数值在不同的模型中均有不同。
| 模型名称 | 参数量 | hidden_dim(嵌入维度) |
注意头数(n_heads) | 层数(n_layers) |
|---|---|---|---|---|
| Qwen3-0.5B | 0.5B | 1024 | 16 | 24 |
| Qwen3-1.8B | 1.8B | 2048 | 32 | 24 |
| Qwen3-7B | 7B | 4096 | 32 | 32 |
| Qwen3-14B | 14B | 5120 | 40 | 40 |
| Qwen3-72B | 72B | 8192 | 64 | 80 |
| 模型 | vocab_size | hidden_dim | Embedding参数量 | 体积(float16) |
|---|---|---|---|---|
| Qwen3-0.5B | ~50k | 1024 | 50M | ~100MB |
| Qwen3-7B | ~150k | 4096 | 614M | ~1.2GB |
| Qwen3-72B | ~150k | 8192 | 1.2B | ~2.4GB |
2.1 Embedding Table的训练
预训练时初始化方式:通常使用 Xavier uniform, normal, 或 truncated normal 初始化;
初始化后通过梯度反向传播,随着训练一起优化;
对于微调任务(LoRA等),也可以冻结或部分更新 Embedding。
2.2 大模型中如何使用 Embedding
input_ids → Embedding Table → Token Embeddings([B, T, D])
→ 加上位置编码 → 输入Transformer
具体步骤:
用户输入文本,如 “苹果手机很好用”;
分词器转换为 [id1, id2, id3, id4, id5];
模型取出 embedding_table[id1] 到 embedding_table[id5];
加上位置编码,成为最终输入。
2.3 具体示例
Qwen3-7B 中的 Embedding查看方式如下,每个 token 通过查表,转化为可以输入模型的向量。
vocab_size: 151936
hidden_dim: 4096
embedding_path: model.embed_tokens.weight
存储位置: pytorch_model-00001-of-00002.bin(HuggingFace权重)
2.4 遇到没见到的新词怎么办
大模型都是机遇已有的数据训练的,发布时可能会出现新的词语;或者一些小模型因为使用的词汇表限制,不能将所有的词语都包含在模型中。
此时业界主流的使用方法为:子词分词法:采用 Byte - Pair Encoding(BPE)、WordPiece 等子词分词算法,将新词语拆分为更小的子词单元。例如 “unhappiness” 可拆分为 “un” 和 “happiness”,模型通过已知子词来处理新词语,这是目前主流大模型常用的方式,能在控制词表大小的同时,保持对未见词的良好覆盖率。
在使用开源分词器时,即使词汇表中已包含完整词语(如 “unhappiness”),子词分词法仍可能将其拆分为子词(如 “un” 和 “happiness”),这并非 “未达到效果”,而是子词分词算法的设计逻辑和优势所在,具体可从以下角度理解:
- 子词分词的核心目标:平衡 “词汇覆盖” 与 “语义粒度”
- 开源分词器的拆分规则:基于训练语料的统计优先级
- 对模型效果的影响:拆分反而可能提升泛化能力
开源分词器的子词拆分逻辑是 “以语义粒度和泛化能力为优先”,而非 “优先使用完整词”。即使词汇表中存在完整词,拆分行为仍是算法基于语言规律和统计优先级的合理选择,其核心是帮助模型更高效地理解语言结构,而非 “未达到效果”。这种设计恰恰是子词分词法能在不同模型中广泛应用的关键 —— 通过统一的拆分逻辑,让模型无论参数量大小,都能基于子词的语义关联处理复杂词汇。
3 第四步:Transformer 层前的准备
得到以上向量之后,模型还会做一些处理,提供先验信息帮助大模型更好的理解文本。
3.1 Position Embedding(位置编码):让模型理解 token 的顺序
在自然语言中,词的顺序直接影响语义(如 “我打你” 和 “你打我”),但 Transformer 等模型的注意力机制本身是 “无序” 的(输入 token 的顺序不影响注意力计算逻辑)。因此,需要通过位置编码为每个 token 注入位置信息。
核心作用:
告诉模型 “每个 token 在句子中的位置”,让模型区分不同位置的相同 token(如 “猫追狗” 和 “狗追猫” 中,“猫”“狗” 的位置不同,语义相反)。
常见实现方式:
- 正弦余弦位置编码(Sinusoidal Embeddings)
这是 Transformer 原论文的方案,通过公式生成固定的位置向量:
偶数维度:PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
奇数维度:PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
其中pos是 token 位置,i是维度索引,d_model是嵌入维度。
特点:位置向量与 token 嵌入向量直接相加,且能泛化到训练时未见过的更长序列。 - 可学习位置编码(Learned Positional Embeddings)
初始化一个与 “最大序列长度 × 嵌入维度” 对应的矩阵,作为可训练参数,通过模型训练学习位置信息。
特点:更灵活,能适应特定任务,但对超出训练长度的序列泛化能力较差(需截断或外推)。 - 相对位置编码(Relative Position Embeddings)
不编码绝对位置,而是编码 token 之间的相对距离(如 “距离前 3 个 token”“距离后 2 个 token”),常见于 BERT 等模型的注意力计算中。
特点:更符合语言中 “上下文关联与相对距离相关” 的特性(如邻近词关联性更强)。
3.2 Segment Embedding(分段嵌入):区分文本片段的边界
当输入包含多个文本片段(如句子对、对话历史、文档段落)时,需要用分段嵌入标记不同片段,帮助模型区分边界。
典型应用场景:
- 句子对任务:如自然语言推理(判断 “句子 A 是否蕴含句子 B”),输入为[CLS] 句子A [SEP] 句子B [SEP],通过分段嵌入区分 “A” 和 “B”(例如用 0 表示句子 A,1 表示句子 B)。
- 对话场景:在多轮对话中,区分 “用户输入” 和 “模型回复”,或不同轮次的对话(如用 0 表示用户,1 表示助手,2 表示系统提示)。
- 长文档分段:处理超长篇文本时,将文档拆分为多个段落,用分段嵌入标记段落边界,避免模型混淆段落间的逻辑。
实现方式:
为每个片段分配一个唯一的标识(如 0、1、2),并将其映射为固定维度的向量(与 token 嵌入维度相同),与 token 嵌入、位置嵌入相加后输入模型。
例如,BERT 中的token_type_ids就是分段嵌入的体现,用于区分两个句子。
3.3 模型类型特殊处理:Chat 格式 prompt 对齐
在对话类大模型(如 ChatGPT、DeepSeek Chat 等)中,需要对输入的 prompt 进行格式对齐,确保模型能正确理解对话历史、角色区分等特殊结构,这是模型训练时约定的输入格式。
核心目的:
让模型识别 “谁在说话”(用户 / 助手 / 系统)、“对话的轮次顺序”,从而生成符合上下文逻辑的回复。
常见处理方式:
- 角色标记符:用特殊 token 包裹不同角色的内容,例如:
<system>你是一个助手</system>
<user>你好</user>
<assistant>你好!有什么可以帮你?</assistant>
<user>请问...?</user>
模型通过 <system> <user> <assistant>等标记区分角色。
- 格式模板硬编码:在 tokenizer 或模型预处理阶段,强制将对话历史按固定模板拼接,例如:
* prompt = f"Human: {user_input}\nAssistant: {assistant_reply}\n
* Human: {new_input}\nAssistant:"
- 特殊 token 嵌入:部分模型会为对话角色分配特殊的嵌入向量(类似分段嵌入),让模型在语义层面区分不同角色的文本。
为什么需要对齐?
对话模型的训练数据通常是 “格式化的多轮对话”,模型已学习到 “特定格式对应特定语义” 的规律。如果输入格式与训练时不一致(如缺少角色标记),模型可能无法正确理解上下文,导致回复偏离预期(如重复上文、忽略历史)。
3.4总结
这三个技术本质上都是为了弥补模型对 “文本结构信息” 的天然缺失:
位置编码→补充 “顺序信息”;
分段嵌入→补充 “片段边界信息”;
Chat 格式对齐→补充 “对话角色与轮次信息”。
它们共同作用,让模型能更准确地理解复杂文本的语义和结构,是大模型实现高质量输出的基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)