关于高炉炼铁行业垂直大模型构建路线的探讨与简易测试
高炉炼铁行业正加速推进智能化转型,垂直大模型(V-LLMs)成为关键技术方向。本文分析了国内外大模型发展现状,指出当前钢铁行业通用大模型(U-LLMs)存在专业性不足的问题,而闭源式高算力钢铁大模型又面临部署成本高、知识融合有限等挑战。文章重点探讨了高炉炼铁垂直大模型的构建路线,包括Transformer架构应用、数据采集预处理、模型训练等关键环节。领域专业知识的深度整合是提升高炉炼铁大模型性能的
🚀 高炉炼铁行业垂直大模型(Large language model, LLM),正站在智能化转型的风口浪潮之中!高算力、闭源式的宏观场景钢铁大模型已纷纷发布并初步应用

注:图片素材来源于网络
简介:在钢铁工业的数字化转型浪潮中,高炉炼铁作为钢铁生产的核心环节,其智能化升级的需求愈发迫切。🚀 本文探讨了构建高炉炼铁垂直大模型的路线图,从数据采集到模型训练,再到实际应用的测试。尽管国内高算力、闭源式的宏观场景钢铁大模型已纷纷发布并初步应用,但面向特定工序下可解决特定情景问题的高炉炼铁垂直大模型需进一步研究!
作者:刘然,段一凡,刘小杰,吕庆
完成单位:华北理工大学冶金与能源学院;燕赵钢铁实验室;
目录:
一、大模型应用现状
1.1 国内外大模型发展现状
1.2 现存问题与思考
二、大模型的构建路线
2.1 通用/垂直大模型的构建
2.2 通用/高炉炼铁垂直大模型的性能对比测试
三、结束语
读完本文,你将获得以下知识储备与简易技能:
- 🔍 行业洞察:了解高炉炼铁行业在数字化转型中的现状与挑战,掌握国内外大模型在钢铁行业的应用进展。
- 🛠️ 构建能力:学会从零开始如何构建高炉炼铁垂直大模型,包括数据采集、预处理、模型选择与训练的全流程的相关理论体系。
- 🚀 实际应用:通过简易测试案例,学会将训练好的模型应用于实际生产场景,评估模型在特定情景下的表现。
- 🌐 未来趋势:感知高炉炼铁垂直大模型的未来发展方向,包括多模态数据融合、实时决策支持等前沿技术的应用前景。
一、大模型应用现状
1.1、国内外大模型发展现状
从技术特性的角度出发,LLMs是一类具有海量超参数与复杂神经结构的深度学习模型,能够在大规模文本数据中学习到具有通用特征模式的知识推理与语言表达能力。目前,LLMs的底层逻辑基于Transformer架构,通过自注意力机制与多头注意力机制处理数据,具体采用无监督式学习与有监督式学习相结合的方式,去捕捉输入序列中的上下文信息。由于参数规模较大,LLMs通常需配备具有高性能算力的硬件集群进行训练,数据处理能力较强,能够对多模态数据实现高效处理与信息融合,如文本、图像、视频等数据类型。

注:图片素材来源于网络
从功能应用的角度出发,河北太行钢铁大模型研发专家、燕山大学刘文远教授提出,LLMs视应用场景不同可分为通用大模型(Universal LLMs, U-LLMs)与垂直大模型(Vertical LLMs, V-LLMs)两类。
- U-LLMs对各类知识具有普适性,即利用大规模无标注类数据进行训练,采用通用式回答模板,但对于特定领域内的精确问题求解属于“入门级”水平,缺乏专业性。
- V-LLMs专注于特定领域进行训练,如金融、法律、钢铁等,能够为用户提供更专业、更精准的解决方案,专业性强但普适性较差。
国内目前主流应用的U-LLMs与钢铁V-LLMs应用现状如下表所示。
| 产品名称 | 开发者 | 参数规模 | 产品名称 | 开发者 | 参数规模 |
|---|---|---|---|---|---|
| ChatGLM | 北京智谱清言科技有限公司 | 62 亿 | 河北太行 LLM | 39 家钢铁企业、阿里巴巴、华为等 | - |
| DeepSeek | 杭州深思人工智能基础技术研究有限公司 | 6710 亿 | 冶金工艺优化 LLM | 中国钢研集团有限公司 | - |
| KimiChat | 月之暗面科技有限公司 | 2000 亿 | 威赛博 LLM | 河北钢铁集团有限公司 | - |
| Qwen | 阿里巴巴云计算有限公司 | 18 亿、70 亿、140 亿、720 亿 | 宝联登 LLM | 中国宝武钢铁集团有限公司 | - |
| ERNIE Bot | 百度 | 2600 亿 | 盘古钢铁工业 LLM | 湘潭钢铁 | - |
| DouBao | 字节跳动 | 1300 亿 | 华院钢铁工业 LLM | 华院计算技术有限公司 | - |
| Spark Desk | 科大讯飞股份有限公司 | 1000 亿 | “一键炼钢”百度钢铁 LLM | 百度、唐山钢铁企业 | - |
| Tencent Yuanbao | 腾讯 | 10000 亿 | 转炉炼钢 LLM | 中国联通 | - |
注:内容素材来源于网络,此表为整理汇总版,或有纰漏,敬请指正
目前,国内开发的U-LLMs技术相对成熟,如智谱AI、DeepSeek等,且大多LLM处于开源状态,用户可根据硬件水平自行部署与使用。
但在钢铁领域,U-LLMs只能实现对基础性内容的建模,难以对专业性问题进行解答。以解释高炉炼铁概念的问题为例,初始U-LLMs只能回答其为一种金属冶炼工艺,并附带一些典型企业的发展现状内容(需联网搜索),但却无法从原理、经验等方面解释其具体的物理化学过程,以及关键生产技术等内容。
1.2、现存问题与思考
目前公开发布的V-LLMs处于高算力条件下的闭源状态,如河北太行钢铁大模型、冶金流程优化大模型等,尚无公开的项目或技术用于测试,但其对钢铁领域的专业性问题求解能力必然高于U-LLMs。
除百度与唐山钢铁企业联合发布的“一键炼钢百度LLM”、中国联通发布的“转炉炼钢LLM”外,其它LLMs均面向钢铁生产全流程,覆盖高炉炼铁、转炉炼钢、精炼、连铸、轧制等工序,旨在解决钢铁全流程中的生产调度与工艺优化问题。
尽管V-LLMs已在钢铁行业取得初步发展,但仍面临一些显著局限性,特别在高炉炼铁领域:
- 部署成本高,小型企业难以承受;
- 领域专业知识融合有限,高炉领域知识复杂,缺乏信息化的数据融合;
- 推理和规划能力欠佳,高炉生产问题往往由多因素协同导致,需要进行大量人工指令微调;
- 深度思考能力有限,易出现“幻觉”,如转炉工序发生的化学反应被错误理解为存在于高炉工序。
高炉炼铁作为钢铁生产的关键工序,面向全流程优化的V-LLMs虽然在宏观场景应用中具有一定优势,但落实在高炉工序去解决特定情景问题仍存在关键技术挑战,如文本化专家经验融合、炉况感知、多参数调控方案制定等。
二、大模型的构建路线
2.1 通用/垂直大模型的构建
LLMs已在各行业实现迅速渗透与大规模应用,在辅助分析、决策优化、个性化定制等任务场景中展现出显著的价值创造潜力,如医疗大模型 Med-PaLM(谷歌研发)、金融大模型 BloombergGPT(彭博社研发)、教育大模型 MathGPT(好未来研发)等。
然而,在钢铁行业、尤其是高炉领域,LLMs技术的发展与应用相对缓慢,主要包括以下原因:
- 医疗、金融、教育等领域的领域数据丰富,且标准化程度较高;
- 钢铁行业的生产过程复杂,涉及多工序和大量工艺参数的耦合作用,标准化数据难以获取;
- 医疗、金融、教育等领域的技术创新接受程度高,在钢铁领域,尤其高炉领域则更注重生产安全与稳定性,新技术的应用需要经过严格测试与验证。
尽管如此,以LLMs驱动高炉炼铁智能化的范式重构与升级,实现高炉领域的V-LLMs开发已成为其当前智能化转型升级的重点任务,而越来越多的U-LLMs开源项目也使得V-LLMs的构建门槛更低。通过对比现有其它行业的V-LLMs,首先分析了高炉炼铁领域下U-LLMs的构建路线如下图所示。
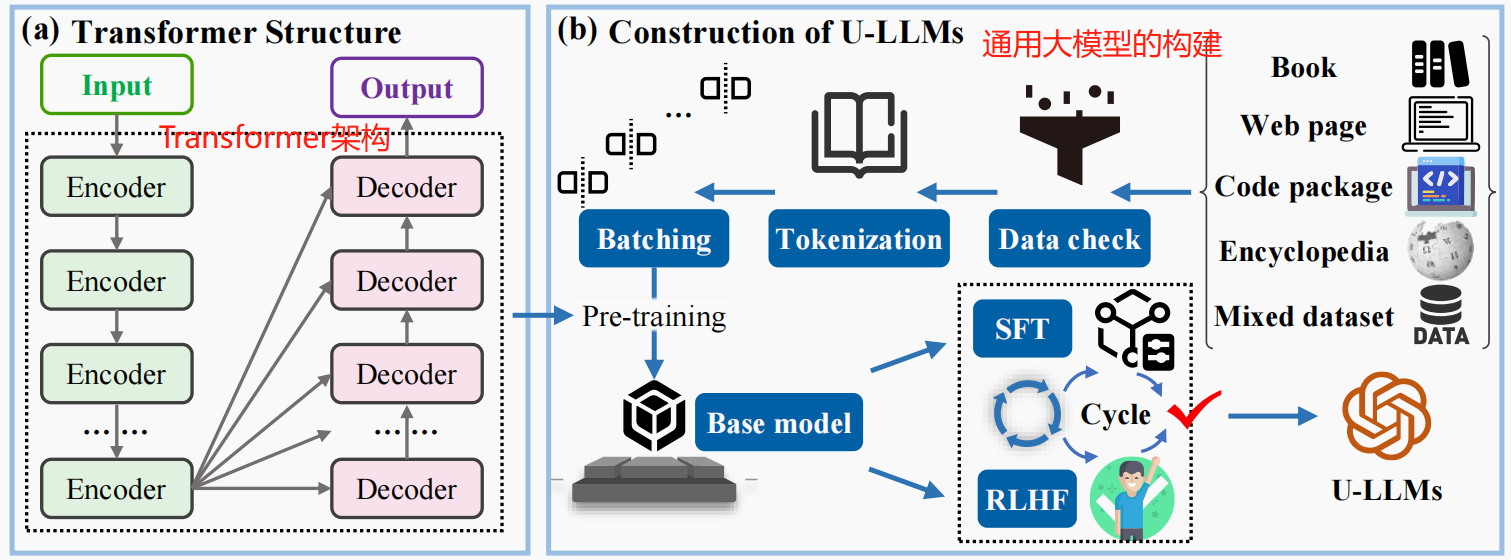
(a) Transformer架构;(b)通用大模型的构建路线
作为一种处理序列任务的深度学习模型架构,Transformer是构建LLMs的技术基础,由编码器(Encoder)-解码器(Decoder)结构组成,如上图(a)所示。
目前,Transformer架构已在高炉炼铁智能化领域取得广泛应用,如风口图像分类、出铁终点预报、铁水硅含量软测量等,但均面向单一任务场景。围绕Transformer架构探讨了U-LLMs的构建路线。
U-LLMs可以看作是基于Transformer架构的深度神经网络模型,面向通用任务,对海量、通用知识与大规模参数进行学习拟合,主要包括预训练(Pre-training)、指令微调(Supervised fine-tuning, SFT)和人类对齐(基于人类反馈的强化学习,Reinforcement learning from human feedback, RLHF)三个步骤,如上图(b)所示。
- 构建语料库(即大规模文本数据),可以从书籍、网页、开源代码、维基百科以及混合型数据集(如“Dolma ”、“ROOTS ”等)中获取,并进行严格的清洗与检测工作,以保证数据质量。
- 将语料库中的数据词元化(Tokenization)并按批次进行切割(Batching)用于基座模型的训练。此时,基座模型已具备较强的文字生成能力,但受限于预训练的任务形式,仍不能直接用于解决具体任务。
- SFT基于标准化“输入-输出”形式的数据对基座模型进行微调,以促进模型更好利用问答形式进行任务求解,但并不具备知识注入作用。RLHF的本质作用为促进模型输出更符合人类偏好,需要对模型输出进行偏好程度排序与标注后将其重新作为输入进行训练。SFT与RLHF两过程交替进行,直至模型性能或损失函数满足要求,U-LLMs训练完成。
2.2 通用/高炉炼铁垂直大模型的性能对比测试
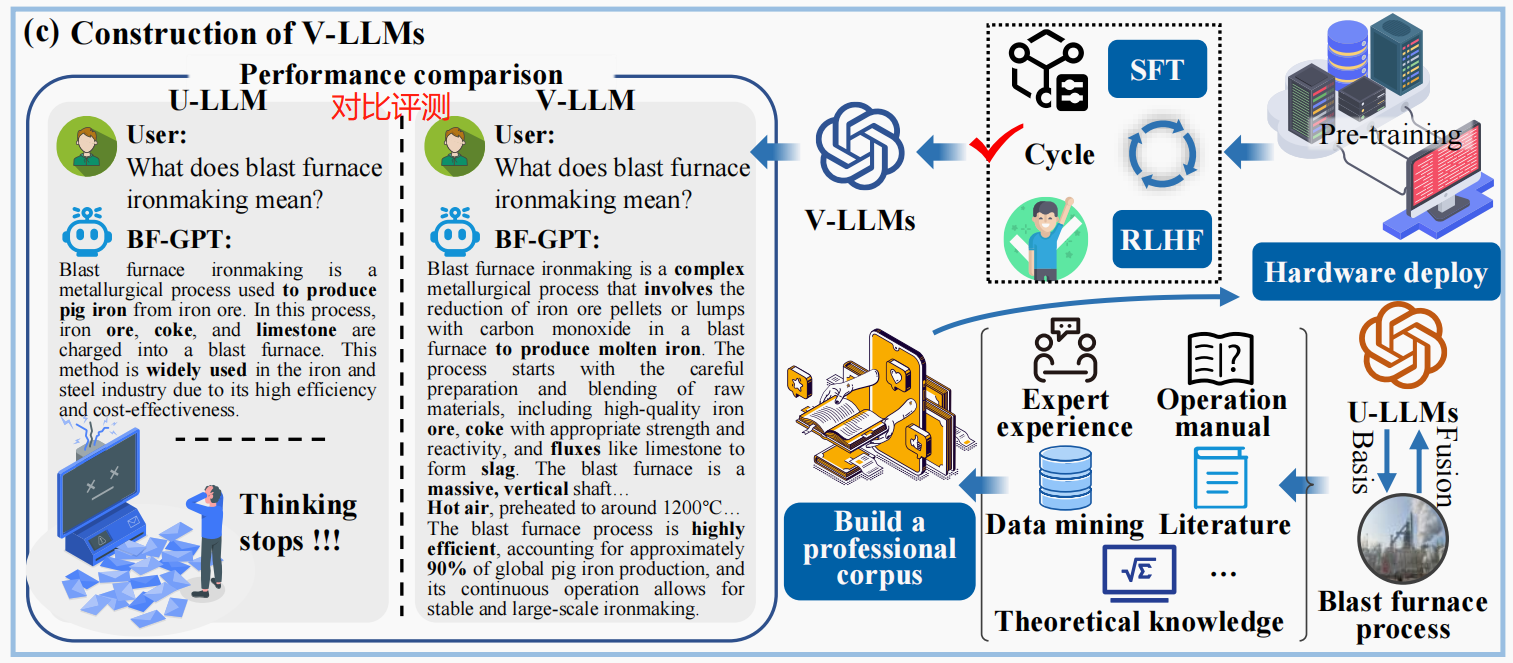
( c ) 高炉炼铁垂直大模型的构建路线与性能对比评测
V-LLMs的构建与U-LLMs类似,但V-LLMs属于对U-LLMs的二次开发。
- 面向高炉工艺构建领域语料库,来源包括理论知识、专家经验、数据挖掘结果等。
- 在厂区内部进行硬件部署对U-LLMs进行二次预训练(Continue Pre-training),最后在经过SFT和RLHF的交替循环处理后得到V-LLMs,SFT与RLHF主要培养U-LLMs的三个能力:领域问题判别、领域知识召回以及领域风格对齐。
- 性能对比评测:对于“高炉炼铁的定义?”问题,提供了实验室训练的V-LLM与开源U-LLM的文本生成能力对比结果。可以发现,U-LLM的回答提到“生铁”、“矿”、“焦炭”、“广泛应用”等关键词,但仅限于浅层的表面知识,思考过程简单。相比之下,V-LLM在U-LLM的基础上,继续回答到“复杂”、“熔剂”、“炉渣”等关键词,并且从高炉结构、鼓风等工艺角度做了量化性的补充说明,如“1200℃”、“90%”等。
三、结束语
LLMs的性能主要受训练数据影响,一般涉及语料库、指令实例以及偏好数据的整理,分别服务于预训练、SFT和RLHF阶段。
构建高炉领域V-LLMs所需的训练数据集要远比U-LLMs困难,除了需要将海量文本化知识转换为模型可识别的输入数据外,还需要大量人工整理的专业性指令实例与偏好数据。
未来,高炉炼铁垂直大模型(V-LLMs)的发展将聚焦于以下几个关键方向:
- 数据驱动的模型优化:随着对高炉炼铁过程理解的加深,数据将成为模型性能提升的核心。通过精心设计的预训练语料库和高质量的指令实例,结合偏好数据,V-LLMs 将能够更好地理解和预测高炉运行中的复杂现象。
- 强化学习与人类反馈的深度融合:强化学习人类反馈(RLHF)将继续在模型优化中发挥重要作用。通过持续收集和整合人类专家的反馈,模型将能够更好地对齐人类的偏好和价值观,从而在实际应用中表现出更高的准确性和可靠性。
- 多模态数据的整合:V-LLMs 将不仅仅依赖于文本数据,还将整合图像、视频和传感器数据等多模态信息。这种多模态数据的融合将使模型能够更全面地理解高炉炼铁过程,从而提供更精准的决策支持。
- 模型的可解释性和安全性:在工业应用中,模型的可解释性和安全性至关重要。未来的研究将致力于开发能够提供透明解释的模型,并确保模型在复杂环境中的稳定性和安全性。
- 持续学习与动态适应:高炉炼铁过程中的动态变化要求模型能够持续学习和适应新的数据和环境。通过引入持续学习机制,V-LLMs 将能够实时更新知识库,以应对生产过程中的不确定性和变化。
资料来源:刘然,段一凡,刘小杰,等.大模型驱动高炉炼铁智能化范式重构:演进、融合与展望[J/OL].钢铁,1-21.
原文链接:https://doi.org/10.13228/j.boyuan.issn0449-749x.20250139.
版权归作者所有,未经许可请勿抄袭,套用,商用(或其它具有利益性行为)。
💡 标签:高炉炼铁、垂直大模型、智能化、模型训练、测试案例
🌟 关注我,获取更多关于高炉炼铁智能化的深度内容和实用技巧!🌟

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 45
45 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)