dify常用插件以及好用的解析
最近闲下来日更分享,今天必须给大家安利一波 Dify 的宝藏插件!用过就知道有多香 —— 虽然 Dify 的插件市场不像某些社区那样看似全面,但胜在隐私安全拉满,不用担心数据泄露或丢失~后面还会分享数据库实操场景,干货满满!不管你是想入门 AI 工作流,还是想优化现有流程,这篇都能给你灵感~ 戳进来学习,有任何问题评论区留言,手把手帮你解决!
耶,这几天刚好比较闲,可以做到日更一下,这次就给大家讲一讲我在做工作流的时候用到的相关插件,我觉得还是相当好用的,dify的市场插件虽然没有扣子社区的那么全面又丰富但是扣子有一定的信息泄露以及数据丢失的风险,上传在github上的也不可能是全部的源代码,大家可以去看一看就能感觉到在github上的扣子是阉割版的,这一块大概率都会留给收费的应用以及操作,所以我觉得目前来说还是dify更加适合学习搭建并且更有隐私安全这块(其实n8n也不错大家感性却的也可以去github上面拉代码下来学习一下)个人拙见如果有不对的地方接受大家的指正
n8n地址 我把地址放在这里了大家感兴趣的可以拉下来学习一下,如果需要帮助的话可以在评论区提出你们的疑问。
下面这个就是dify的插件市场大家简单看一下就可以发现真的是相当丰富啥都有。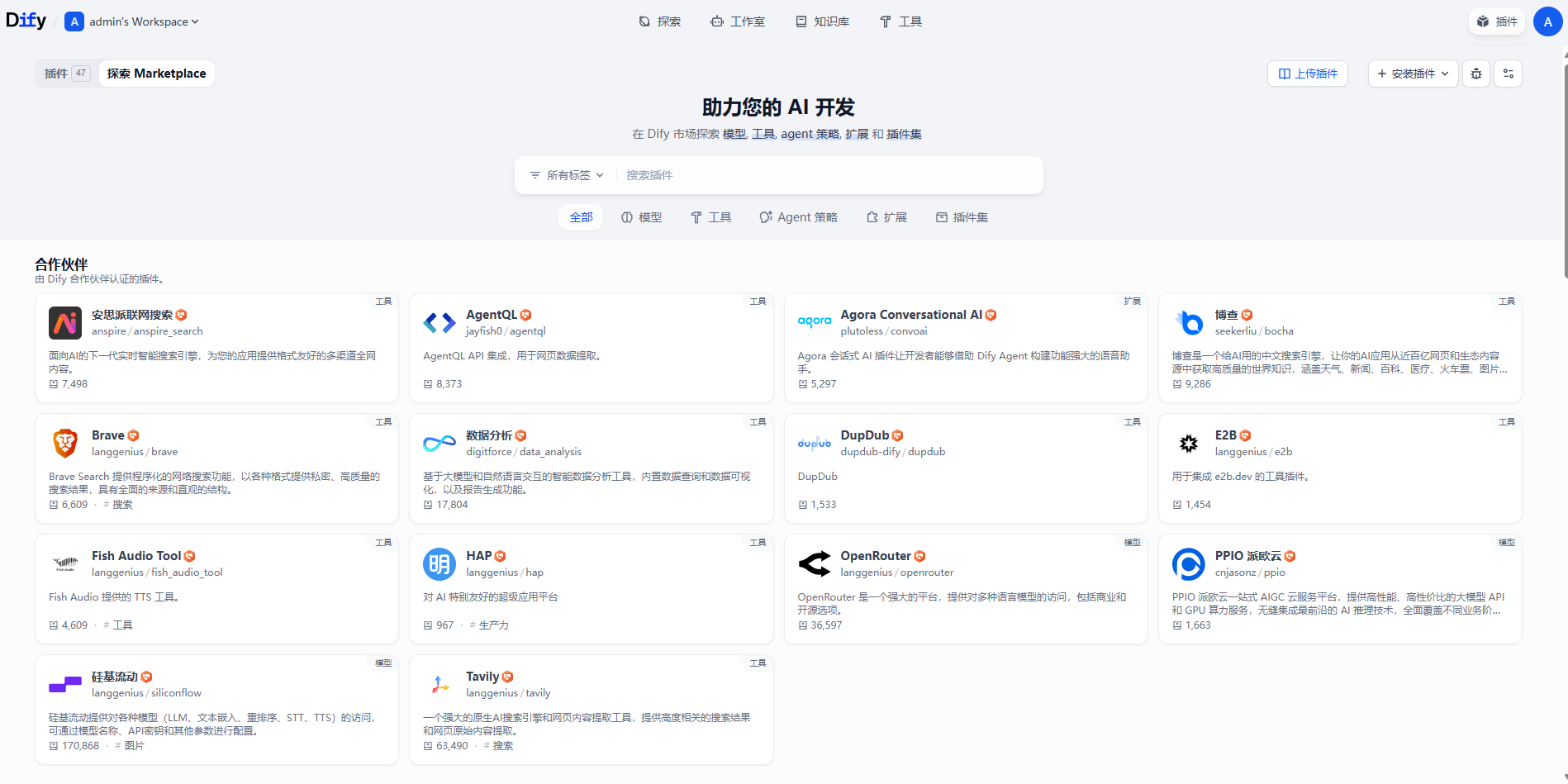
1.模型相关
市面上的主流模型在dify里面基本都适用,里面我之前文章提到的硅基流动的验证方式大家到时候可以去翻一下之前的文章学习一下,如何验证和获取硅基流动的api-key,我这里再贴一下网址硅基流动 SiliconFlow - 致力于成为全球领先的 AI 能力提供商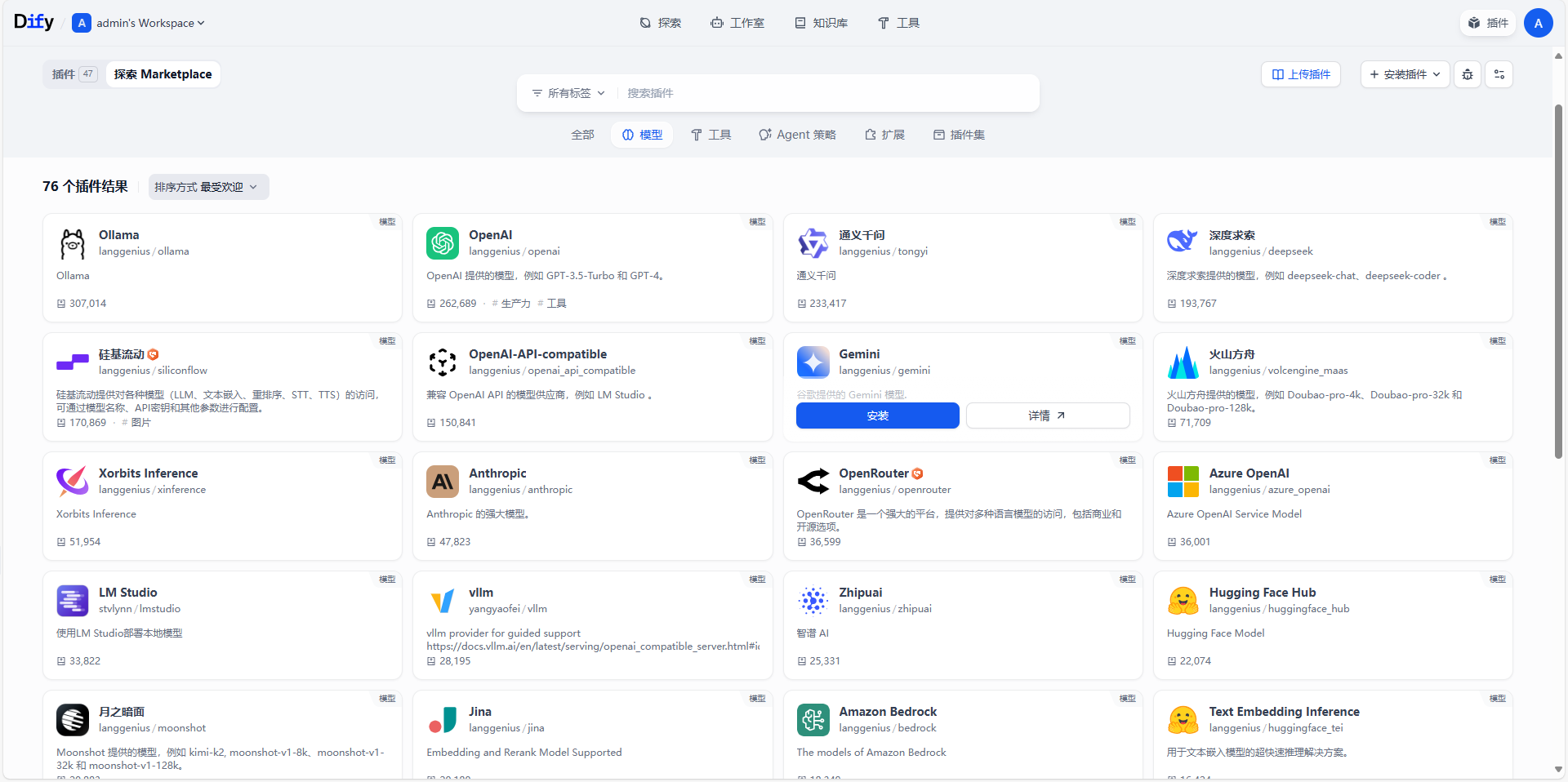
然后如果大家要用本地部署的大模型的话就需要下载ollama,下面是ollama需要提供的参数如果大家不会配置的话可以私信或者评论区问我我会给大家解答遇到的问题。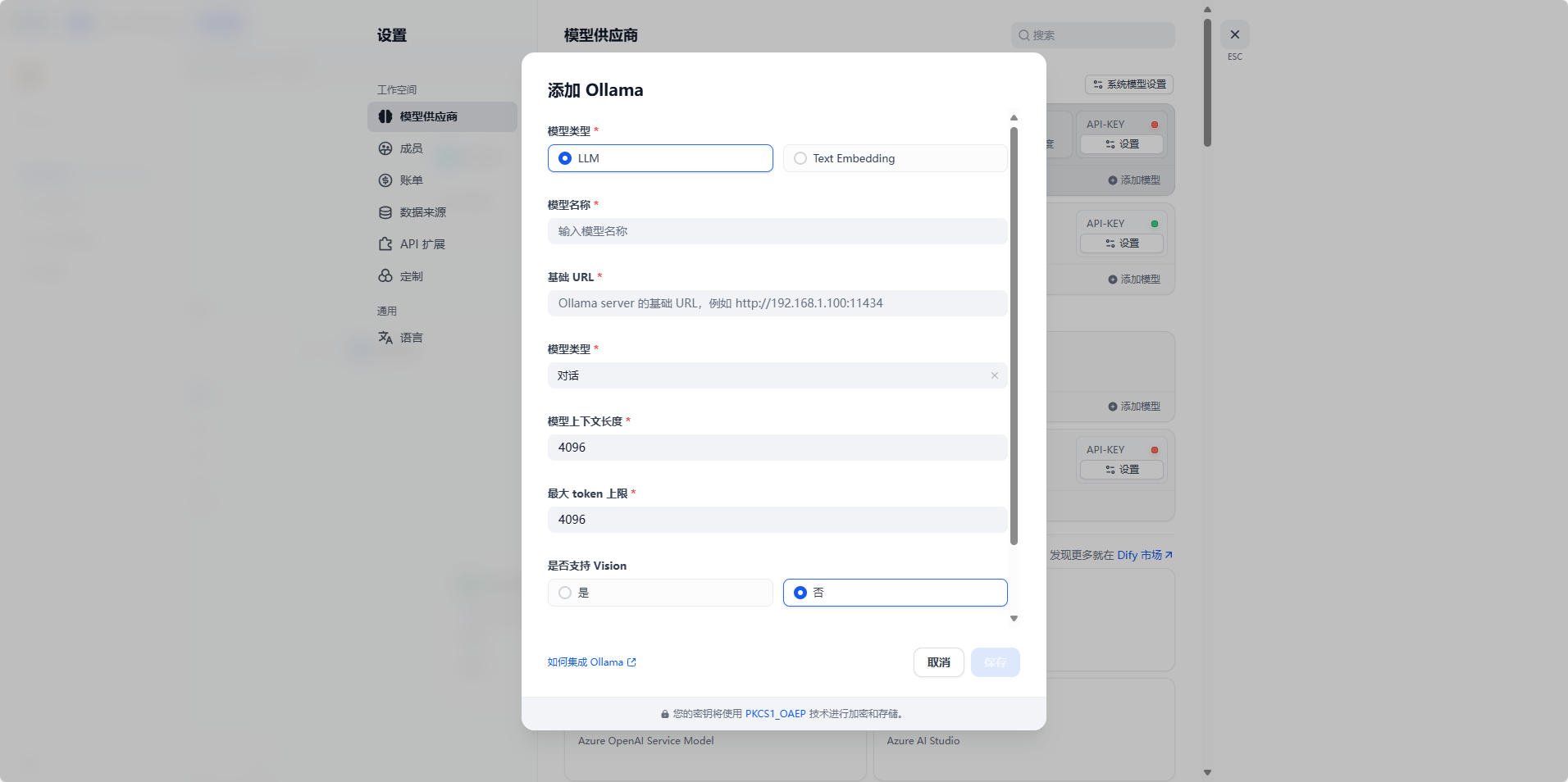
剩下的模型安装和使用基本上就只需要api-key大家可以根据名字去网上搜索一下网址注册获取api-key。我在下面贴几个我常用的模型网址。
如何获取API Key_大模型服务平台百炼(Model Studio)-阿里云帮助中心
大家如果有用到其他的可以去谷歌上搜索一下进行测试。
2.工具相关
爬取数据相关,这个工具爬取数据的能力相当可以不过它需要使用科学上网,然后每个月送一定的免费额度使用,只要你要爬的数据不是非常大也不是非常多的话这个工具还是很好用的
Firecrawl
Firecrawl注册和登录的网址放在这里了这个也是要配api,
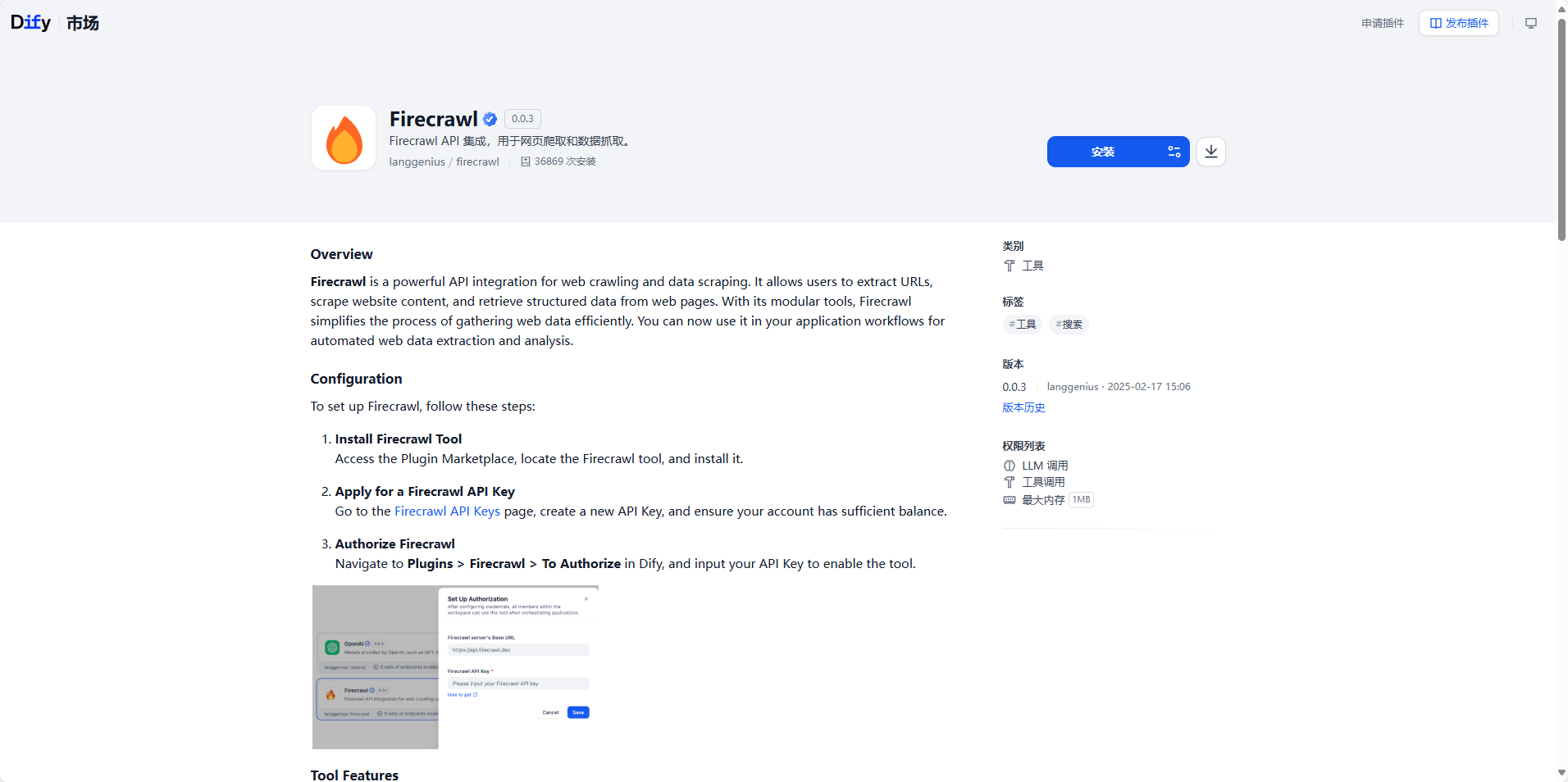
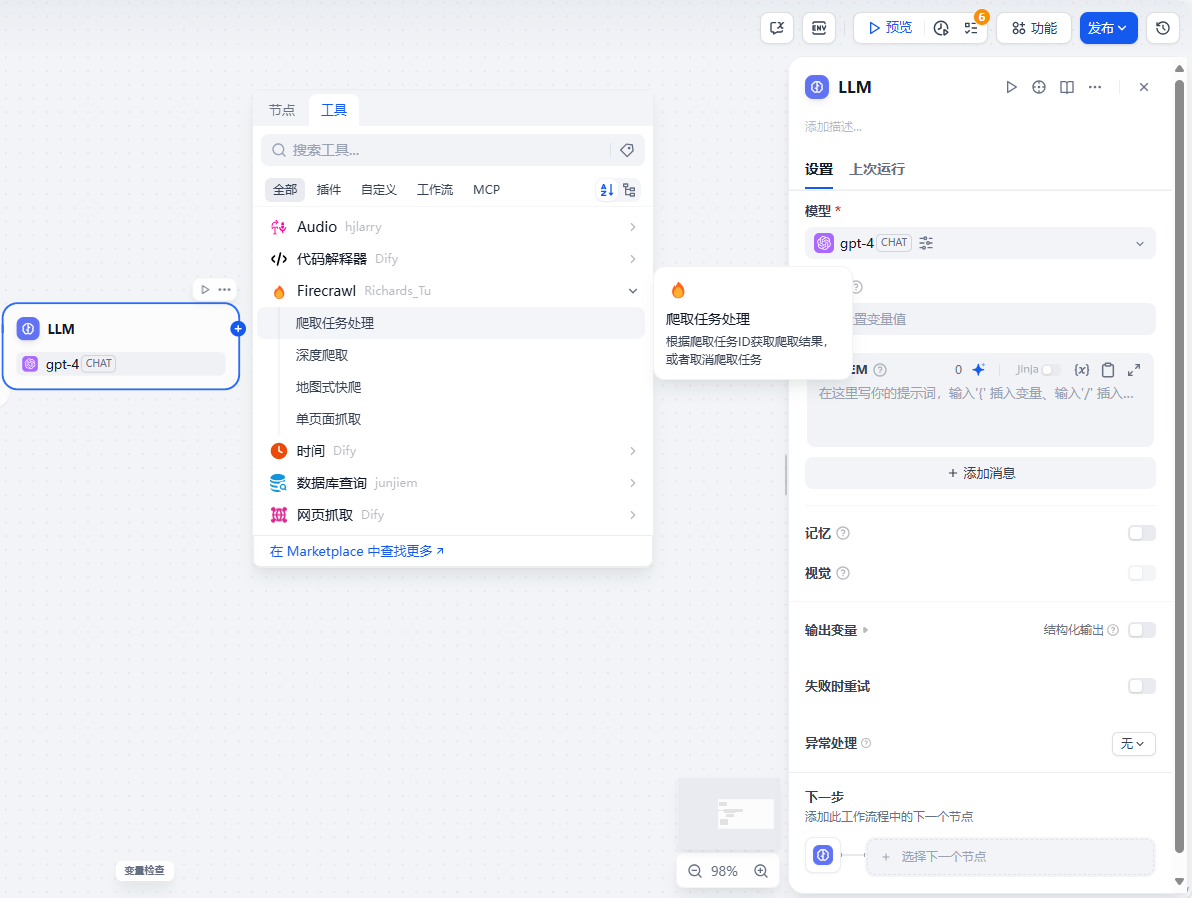
下载之后你在工作流里面点击节点旁边的工具就能看到Firecrawl工具,这里面比较有用的三个爬取操作是深度爬取和地图式快爬,还有单页面抓取。接下来我就来给大家大致讲一下这几个不一样的地方以及使用。
深度爬取是指在一个网址下不断爬取获取更深的网页内容,就是有点类似于俄罗斯套娃一样如果它点开你的这个网页下面还有新的网页它就会继续爬取,直到没有更新的网站。
地图式快爬这个就倾向于广度假设你给了一个谷歌浏览器的搜索结果它会把你当前页面所拥有的所有页面的网址都爬取下来,但是无法爬网址里面的内容。
单页面抓取就是平常的把一个网页的数据爬取下来比较适合做知识库的内容,他们两可以联动。
通讯
这里面可以联动钉钉,企业微信,飞书等,如果需要帮助也可以在评论区提问,这里我就不展示了。

Agent策略
这个是与Mcp节点进行联动的策略,里面可以使用Function Calling就是相当于调用ai里面外部工具类似的操作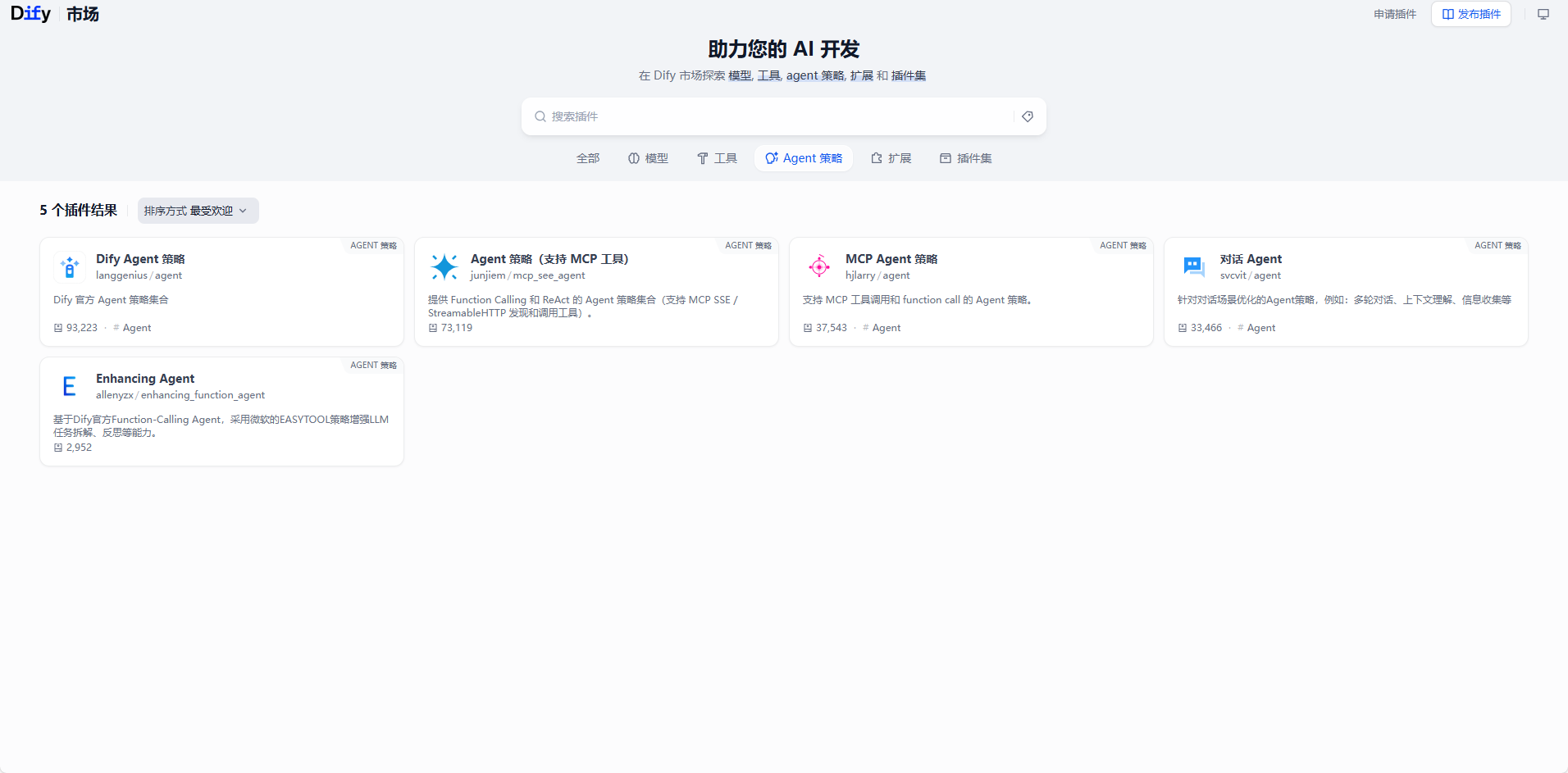
后面还有一些其他好用的工具和节点,等后面讲到具体的场景我会给大家先进行科普,大家放心,马上我就来给大家分享一个数据库相关的场景,大家敬请期待。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)