生成式人工智能展望报告-欧盟-05-监管框架
本章概述了GenAI的监管格局,从AI法案及其对GenAI应用的影响开始。它探讨了与GenAI相关的风险以及《数字服务法》在减轻这些风险方面的作用。本章还探讨了GenAI与《通用数据保护条例》(GDPR)之间的相互作用,以及知识产权(IP),特别是版权挑战。核心问题包括如何平衡创新与人工智能治理中强大的道德和法律的标准的需求。最后,总结了规范数据交换和再利用的立法。

摘要
本章概述了GenAI的监管格局,从AI法案及其对GenAI应用的影响开始。它探讨了与GenAI相关的风险以及《数字服务法》在减轻这些风险方面的作用。本章还探讨了GenAI与《通用数据保护条例》(GDPR)之间的相互作用,以及知识产权(IP),特别是版权挑战。核心问题包括如何平衡创新与人工智能治理中强大的道德和法律的标准的需求。最后,总结了规范数据交换和再利用的立法。
文章目录
5.1人工智能法案及其对生成型人工智能的影响
关键信息:
- 《人工智能法案》促进了GenAI系统的发展。一方面,它提出了一系列法律的要求,使欧盟的GenAI系统更加透明和可信。
- 另一方面,它促进了与值得信赖的人工智能相关领域的技术创新,例如水印和指纹技术。
《人工智能法》是世界上第一部关于人工智能的法规,目前正在欧盟实施。它要求某些人工智能系统和模型在进入欧盟市场之前满足一系列要求。根据基于风险的方法(即考虑健康,安全和基本权利的风险),这套法律的要求取决于具体的应用程序,人工智能系统有四个不同的风险级别(最小,有限,高和不可接受的风险),模型有三个级别(无义务,通用人工智能(GPAI)模型和具有系统性风险的GPAI模型)。委员会目前的指导文件对这些水平和要求作了澄清。这些级别也适用于生成性的AI系统和模型。特别是,GenAI应用与一些高风险和透明度风险相关联,GenAI模型是GPAI模型的核心。《人工智能法案》对GenAI模型的采用和可信度具有相关影响,以下章节对此进行了概述。
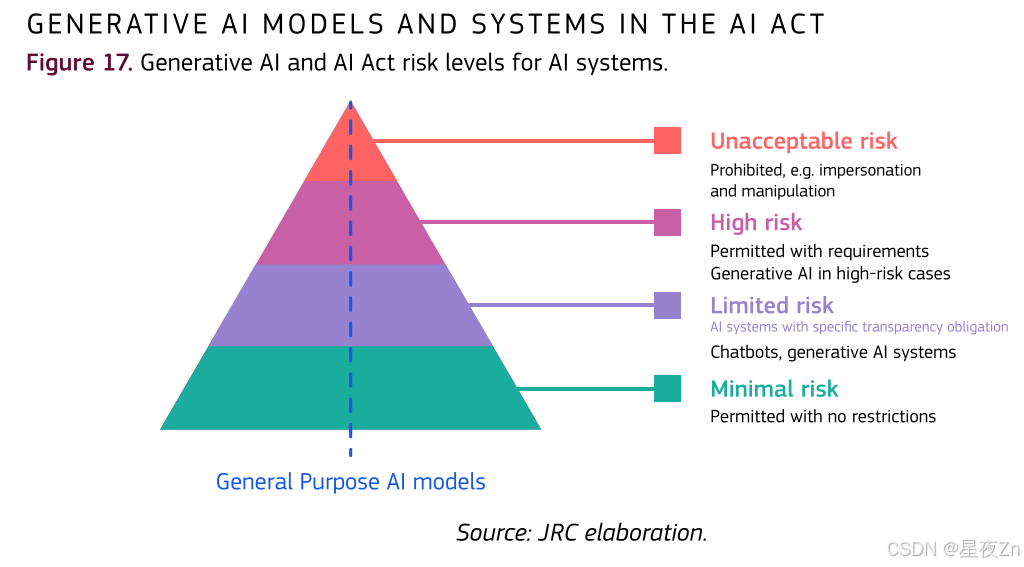
许多GenAI系统与第50条中描述的“有限风险”级别和相关透明度义务特别相关。276这些义务规定,某些GenAI系统(如聊天机器人)的提供商需要确保与这些系统相关的人类意识到他们正在与机器进行交互。此外,提供商需要确保AI生成的内容是可识别的。最重要的是,某些人工智能生成的内容应该有清晰可见的标签,例如深度伪造和发布的文本,目的是向公众通报与公共利益相关的问题。
除了有限的风险,GenAI系统可能是高风险AI系统或不可接受的风险实践的一部分。高风险人工智能系统受到严格的义务277,人工智能法案禁止与不可接受的风险相关的八种做法。278虽然在高风险用例列表中没有明确提到GenAI系统(人工智能法案附件三),但GenAI系统有可能被整合到这些用例中。在被禁止的做法方面,GenAI系统可以与其中一些相关联,特别是有害的基于人工智能的操纵和欺骗(AI法案第5(a)和(B)条)。
委员会关于禁止人工智能实践的指南草案279提供了一些不可接受的使用GenAI系统的例子:人工智能聊天机器人冒充一个人的朋友或亲戚造成重大伤害,或者一个旨在检测何时正在评估以阻止不受欢迎的行为的系统。该准则还提到了这些被禁止的做法与前面提到并由第50条第4款规定的有限风险的透明度措施之间的相互作用。透明度措施可被视为减少欺骗和操纵风险的缓解战略。
人工智能法案中的生成人工智能模型
除了人工智能系统,人工智能法案还对通用人工智能模型(包括但不限于GenAI模型)的提供商规定了某些特定义务,这些模型可以执行广泛的任务,并正在成为上一节提到的许多人工智能系统的基础。该法案对这些模型提出了若干透明度要求和版权相关规则,并对可能与这些系统性风险有关的模型提出了系统性风险识别和缓解的额外要求。目前,许多最先进的GenAI模型都提供了与通用AI概念相关的功能,因此它们将受到相关义务的约束。欧洲联盟委员会的人工智能办公室目前正在协助起草一项业务守则,以根据最新的做法详细说明这些规则。
相关技术
如上所述,《人工智能法案》依赖于GenAI透明度的技术解决方案,即允许识别人工智能生成内容的技术解决方案。这些技术应具备以下四个属性:效率、数据完整性、内容更改的鲁棒性和防止操纵。281 GenAI的透明度技术基于用于标记数字内容(音频、图像或文本)的技术,以确保遵守版权法。这些技术涵盖四种主要的透明方法:(1)嵌入内容中的元数据;(2)旨在将几乎不可感知的标记嵌入音频,图像或文本中的水印技术;(3)依赖于内容标识符的生成和存储的指纹技术;以及(4)基于AI的检测机制。
尽管这些技术已经取得了重大进展,但GenAI的透明度仍然是一个具有挑战性的领域,需要进一步的基础研究来开发更可靠的解决方案。这还涉及探索内容识别及其治理的新工程方法,考虑专有与开放解决方案的作用,如1.3节所述。
5.2人工智能风险和数字服务法案
关键信息:
- 《欧盟数字服务法》(DSA)规定了在线中介和平台应对系统性风险的义务,要求它们调整其服务、系统和算法以减轻这些风险。大多数大型在线平台和大型在线搜索引擎在其最近的风险评估报告中确定了与GenAI相关的风险。
- GenAI技术引入了新的风险形式,指定的数字服务必须分析和减轻这些风险,例如对用户身心健康的风险或对公民话语和选举过程的风险。
- 如果正确实施和测试,它也有可能为更安全的在线空间带来机会,包括通过在内容审核中使用LLM以及对有害或恶意内容实施护栏和缓解措施。
《欧盟数字服务法》(DSA)是世界上第一个针对使用在线平台和搜索引擎等中介服务所产生的社会风险的法规。DSA根据其角色、规模和社会影响对在线中介和平台规定了义务,涵盖了这些服务及其相关系统(包括算法系统)的设计或运作和使用所产生的系统性风险。
自DSA义务于2023年8月开始适用于大多数指定的超大型在线平台(VLOP)和超大型在线搜索引擎(VLOSE)以来,欧盟委员会已采取多项监管和执法行动,其中一些专门针对GenAI(特别是与幻觉,深度伪造和选举相关风险有关)。其中包括在2024年3月至5月期间向六个VLOP和三个VLOSE发送的信息请求(RFI)。
在线平台在其风险评估报告中识别的一般风险
一些具有GenAI功能的平台和搜索引擎在其2024年报告中涵盖了相关风险。例如,Bing的风险评估明确承认了利用GenAI功能所带来的风险,与获取信息和表达自由有关的风险,与虚假和误导性信息以及回音室有关的风险,以及与生成不安全,误导性,欺诈性,隐私或其他有害内容有关的风险。
幻觉,如GenAI的反应是不接地的输入源,明确提到,并讨论了具体的缓解措施和护栏技术,特别是在容易受到攻击或涉及所谓的“数据空洞”的情况下,搜索领域缺乏权威信息,特别是在语言流量较少。其他平台,例如LinkedIn,也提到了GenAI功能的风险,例如模型反映有害刻板印象的可能性,或与平台用户滥用相关的风险,包括越狱事件或恶意提示注入,例如在职位描述中。
与平台上滥用生成人工智能相关的风险也在风险评估报告中得到了突出反映。例如,大多数社交媒体平台都提到了GenAI降低技术壁垒的潜力,以高速和规模生产有害内容。特别是,GenAI被用来操纵内容的风险经常被强调,它被用来传播和放大虚假信息,或使欺诈和诈骗成为可能。在X,285 TikTok286和Meta,287 288等平台的风险评估报告中提到的一个值得注意的风险是,GenAI“可能会促进人工智能生成的非法内容的生产”或“被用作基于图像的滥用的一部分”。一个特别严重的例子是儿童性虐待材料(CSAM)的生成,最近的报告警告说,在2022年ChatGPT和Stable Diffusion公开发布的同时,使用GenAI的CSAM内容会增加。
一个相关的风险是色情深层假货的出现(见第4节)。这些风险并不局限于社交媒体,事实上可以说在色情平台上同样突出。虽然没有指定色情平台的风险评估报告,(Pornhub,Xvideos,Stripchat和XNXX)已经提供了迄今为止,谷歌风险评估报告“在未经他们同意的情况下,在网络上发布的描绘色情内容的图像和视频的增加令人担忧”,以及他们如何改进缓解措施以更好地解决这个问题,例如更新排名算法,以更好地解决这一问题,以及它们如何改进缓解措施,例如更新排名算法。
DSA要求指定的在线平台密切监测和解决因在数字服务中使用GenAI而加剧的现有和新出现的风险,特别是当这些服务的用户中有未成年人时。
事实上,虽然深度伪造和类似形式的非法或有害合成内容通常与其他违规内容一样受到相同的内容政策的约束,但专门针对人工智能生成内容的其他缓解措施正在开始出现。透明度,以标签工具的形式提供给用户和广告商,可以选择将其内容标记为使用人工智能制作,是第一道防线。检测合成内容的模型也正在开发和改进过程中,以补充用户标签。这项任务的技术难度往往突出,能够大规模检测合成介质的有效技术在很大程度上仍然不可用。一些平台提到与行业合作伙伴和组织的合作,以交换有关违规内容(包括合成内容)的信息,并继续开发检测技术。一个值得注意的例子是水印技术,它将数字签名嵌入到人眼无法感知但可以通过技术手段检测到的内容中,例如SynthID。291更广泛的内容出处解决方案也正在出现,例如C2PA,这是一种将元数据嵌入数字内容的开放技术标准,例如图像,视频,音频记录,292这些技术的目标是最终确定人工智能生成的有害内容的来源,293从而限制对该技术的滥用,提高透明度并允许问责制。然而,这些技术正在由各种组织积极开发和部署,进一步的工作是为了广泛的健壮和可互操作的采用。
更安全的在线空间的生成式AI的机会
尽管存在风险,但GenAI技术是一项变革性技术,有望在广泛的应用领域带来许多潜在的好处和机会。在促进安全的在线空间方面也是如此。突出这种潜力的一个例子是在内容审核用例中使用LLM,更一般地说,用于执行在线平台制定的社区指导方针和政策。专门的GenAI模型越来越多地被用于实施针对有害或恶意内容的防护和缓解措施,无论是用户生成的还是人工智能生成的。
使用自动化来支持在线平台和搜索引擎中的内容审核活动正在成为一种既定做法。对2024年4月1日至2025年4月1日期间所有VLOP的DSA透明度数据库294中的数据进行分析,发现大多数注册的内容审核操作至少涉及部分自动化,主要用于初始检测,并且越来越多地用于完全自动化的删除,即没有人为干预。
今天,与经典算法和AI模型相比,GenAI在内容审核方面可能仍然发挥有限的作用。但是,我们可以预期,它的作用在今后会增加。Google295等平台已经指出了使用人工智能来大规模预防、检测和响应非法和有害内容的机会,包括使用LLM。虽然潜在的好处是显而易见的,但重要的是要强调需要严格评估跨用户和语言的自动内容审核系统,以防止系统性偏见以及过度或不足的审核。Google295等平台已经指出了使用人工智能来大规模预防、检测和响应非法和有害内容的机会,包括使用LLM。虽然潜在的好处是显而易见的,但必须强调需要严格评估跨用户和语言的自动内容审核系统,以防止系统性偏见以及过度或不足的审核。
5.3通用数据保护条例(GDPR)和生成式AI
关键信息:
- 需要更好地理解数据保护法(尤其是GDPR)与GenAI之间的关系,特别是在实施和合规性保证方面。
- 尽管AI法案的适用范围不同,但它将提供一个补充的法律的框架,但GDPR将继续适用于AI和GenAI技术背景下的任何个人数据处理。
- 然而,需要继续详细评估现有数据保护法的应用,因为一些问题,例如个人数据的概念及其在人工智能模型中的处理,合法性,问责制以及提供数据主体权利等,仍然需要更多的研究和实际评估。
在第4.9节中,我们从数据保护和隐私的角度确定并分析了GenAI开发的社会影响和挑战。在这里,目的是介绍GenAI和GDPR之间的关系,并确定GenAI最近发展提出的一些关键问题。
自2018年适用以来,GDPR已受益于所谓的“布鲁塞尔效应”,成为数据保护方面的国际法律的标准,并成为世界各地其他法规的参考。297作为一个技术中立、基于原则和风险的法律的文本,它建立在其法律的前身的优势之上,并增加了一些自己的优势,以确保遵守数据保护规则。人工智能的快速发展–特别是其生成子集–引发了对数据保护法准备情况的质疑(包括GDPR)来解决这些技术所带来的复杂问题,298尽管欧盟监管机构和其他专家认为数据保护立法可以成为监管AI的相关工具。GDPR已经在不同情况下采取行动,例如意大利数据保护局对OpenAI进行初步调查和相应的制裁,包括1500万欧元的罚款; 300和NoYB 301投诉同一家公司,包括一个关于创造一个“假儿童杀手”。
“作为数据保护法基础的框架存在弱点,无法为个人提供随着人工智能的进步而保护其数据隐私所需的工具;它也未能解决社会层面的隐私风险,”King,J.和Meinhardt,C.,《重新思考人工智能时代的隐私–以数据为中心的世界的政策挑衅》,白色文件,斯坦福大学以人为本的人工智能研究所,第6页;“当前的隐私法远远不能解决人工智能的隐私挑战。人工智能给隐私法中许多最薄弱的部分带来了压力。隐私法的错误方法和其他未修复的缺陷特别不适合人工智能”,Solove,D.,人工智能与隐私,2024年2月,77佛罗里达法律评论1,2025,“不幸的是,许多新兴的数字技术似乎注定要破坏GDPR的目标。[…]GDPR主要关注数据收集时的输入阶段的保护,但在分析期间或之后几乎没有。因此,该法律忽视了这样一个事实:由于推理分析,数据收集后可能会出现不可预见的隐私威胁。”,Sandra Wachter,《大数据时代的数据保护》,Nature Electronics,第2卷,2019年1月,pp.6和7
为什么数据保护–以及规范它的法律的框架–在任何人工智能讨论中如此重要,可以用King和Meinhardt的话来解释:“隐私和人工智能之间的联系是数据:几乎所有形式的人工智能都需要大量的训练数据来开发分类或决策能力。数据是所有人工智能系统的关键组成部分-迄今为止,人工智能系统最重要的改进与访问大量训练数据有关。
在我们看来,毫无疑问,目前关于GenAI与数据保护之间的关系有许多问题需要更明确的答案。我们将在本节中讨论一些问题。随着人工智能技术的发展变得更加复杂(就像目前引入人工智能代理的情况一样),在处理个人数据以及遵守数据保护立法和GDPR时,它们提出的问题可能也会变得更加复杂。
GDPR和AI法案之间的冲突
尽管GDPR和欧盟AI法案的适用范围不同,(第2024/1689号条例)被视为“互补和相互加强的文书”。304《人工智能法》明确提及《欧盟运作条约》第16条、《通用数据保护条例》及其在人工智能生命周期背景下对个人数据处理的全面应用。305尽管其以市场为导向、支持创新的方法,它非常强调促进以人为本和值得信赖的人工智能的采用,并确保健康,安全和对欧盟基本权利宪章中所载基本权利的高度保护(包括隐私和数据保护的基本权利)。
AI法案和GDPR之间的这种互补性可以找到两个很好的例子:(i)在强制性基本权利影响评估(弗里亚)中,数据保护影响评估(DPIA)可以依赖于满足弗里亚的某些方面;(二)在《欧盟人工智能法》中,要求高-风险人工智能系统起草一份符合性声明,其中包含相关人工智能系统符合欧盟数据保护法的声明。
这种互补性也是为什么欧洲数据保护委员会(EDPB)在其关于数据保护机构(DPA)和欧盟人工智能法案的作用的声明中认为,“当通用人工智能模型或系统需要处理个人数据时,它可能会像任何其他人工智能系统一样,在适用的情况下,“当通用AI模型或系统需要处理个人数据时,它可能会像任何其他AI系统一样,在适用的情况下,属于相关国家DPA的监管范围。因此,它呼吁欧洲委员会和欧盟大赦办公室(在委员会内设立)注意“与国家指定代理人和欧洲发展和预防局合作的必要性,以及在与它们达成协议的情况下以最有效的方式建立适当的相互合作的必要性”。
四个关键问题
在GenAI环境中,根据GDPR处理个人数据可能会引发几个问题,其中许多问题已经在现有文献中得到解决。在此,我们只着重讨论我们认为非常相关的四个问题:
1.AI模型中的个人数据及其处理
围绕LLM是否处理个人数据的争论对AI系统的开发和使用具有重要意义。汉堡DPA跟随丹麦DPA的脚步,在EDPB关于在人工智能模型背景下处理个人数据的某些数据保护方面的意见28/2024通过之前,认为LLM不是数据库,不存储个人数据,因此,在模型中没有处理个人数据。不能授予与模型本身有关的任何数据主体权利,并且在LLM的开发阶段的任何潜在违规行为都不会影响以后使用这种模型的合法性,包括作为AI系统的一部分。
对这些论点的批评是基于:(i)对个人数据概念的评估,正如第29条工作组所提出的那样,结论是LLM中的信息(也称为“令牌”)福尔斯属于个人数据的定义;(ii)GDPR也适用于仅具有概率性的个人信息,包括不准确的个人信息,EDPB也有规定;及(iii)考虑到法律硕士课程内的保安措施能否成功保护个人安全,(因此,除了通过非法手段之外,不可能提取)并不妨碍GDPR的应用。309由于其对人工智能系统中使用LLM的影响,以及与LLM本身相关的数据主体权利的实施,采取一种或另一种立场的影响对于在这种情况下处理数据的个人来说是深远的,但对于公司来说也是如此-无论是开发这些模型的公司还是后来将其用作人工智能系统的一部分的公司,这可能需要也可能不需要,以确保在技术上复杂的GDPR合规性。
2.合法性(第5(1)(a)条,重点是合法利益(第6(1)(f)条)
通用人工智能(GPAI)模型通常在大量数据集(可能包含同样大量的个人数据,包括敏感的个人数据)上进行训练,这些数据集以不同的方式获得,例如通过对公开数据的网络抓取。
要合法处理个人数据,需要有法律的依据,一个可能的依据,特别是在有限责任公司的情况下,是数据控制者的合法利益(第6条第1款f)GDPR)311(对于敏感的个人数据,还有第9条第2款GDPR的附加要求)。然而,除其他标准外,这一法律的依据还需要进行“平衡测试”,即权衡控制者的利益与数据主体的权利和自由。挑战在于将这种平衡测试应用于大型、多样化的数据集,这些数据集可能包含非常重要和多样化的个人数据,用于训练人工智能模型。在实践中,数据控制者可能会非常复杂地准确识别个人利益与所涉处理,评估处理对个人权利和自由的影响,并在处理来自各种来源的大量数据时引入缓解措施。
欧洲数据保护委员会(EDPB)根据其关于在人工智能模型背景下处理个人数据的某些方面的第28/2024号意见,提供了关于合法利益的指导,承认人工智能模型开发和部署对基本权利的潜在风险。然而,EDPB强调,必须根据数据的性质和来源、数据处理的背景以及对相关个人的进一步影响等因素对每个案例进行单独评估。
合法性讨论至关重要,因为如果合法利益不适用,则必须考虑其他法律的依据,例如同意。313然而,从实践的角度来看,出于培训GPAI模型的目的,实施法律的依据(例如同意),就其本质而言,可能会对GPAI背景下的数据控制者构成挑战,其中用于训练模型的数据集可以包含非常大量的个人数据类别,这些个人数据类别潜在地涉及大量的个人。
3.问责原则:谁负责?
GenAI系统的性质和复杂性使得在整个AI生命周期中分配责任可能非常困难。GDPR规定,数据控制者(决定在特定背景下“为什么”和“如何”处理个人数据的数据控制者)应负责并能够证明对数据保护原则的遵守。如何定义数据控制者在GenAI环境中?在人工智能模型的开发阶段(包括数据收集和训练阶段),这可能更容易确定(例如,OpenAI是GPT开发中的数据控制器)。然而,一旦人工智能模型经过训练并作为人工智能系统的一部分部署,该确定就会变得更加复杂。
一个很好的例子是最近涉及一个德国消费者组织(北莱茵-威斯特伐利亚消费者组织)和Meta的案件。VNRW未能赢得法院禁令,以阻止Meta使用Facebook和Instagram的个人数据训练其AI模型(见:https://www.reuters.com/sustainability/boardspolicy-regulation/german-rights-group-fails-bid-stopmetas-data-use-ai-2025-05-23/。与此同时,汉堡数据保护局考虑根据GDPR第66条针对爱尔兰同行和Meta发布紧急程序,以阻止使用个人数据进行Meta人工智能培训,但后来决定不再向前推进(参见:https://www.euractiv.com/section/tech/news/germanprivacy-watchdog-scraps-plans-to-stop-meta-ai-trainingon-personal-data/)。NRW要求Meta于2025年5月6日停止在欧盟的人工智能培训。
在确定责任所提出的其他问题中,还有EDPB在其第64条第2款GDPR意见中提到的“毒树之果”316:如果使用非法处理的个人数据训练模型,它是否会影响处理的合法性,并因此影响依赖该模型的GenAI系统的控制者的责任?EDPB提供了三种不同的场景。鉴于个人数据处理的基于背景的性质,可能需要进行个案评估。话虽如此,这仍然是GDPR和GenAI之间关系中正在讨论的非常重要的方面之一。
4.数据主体权利:可以行使吗?
在任何活动中处理个人数据的个人有权享有GDPR第15条至第22条规定的一系列权利。即使不是绝对的,这些权利也为个人提供了对个人数据以及数据控制者对其进行处理的更多控制,允许个人:知道他们的个人数据是否、为什么以及如何被处理;318要求纠正或删除;319反对在某些条件下处理他们的个人数据; 320,特别是在人工智能的背景下,不受自动化的个人决策过程的影响,以及一系列后续保障措施,如人为干预。这对它们的执行并非没有挑战。
数据主体权利的适当行使还与围绕GenAI讨论的其他关键问题有关:(i)模型中包含的个人数据的准确性;以及(ii)人工智能模型是否实际存储了个人数据-如上所述,这可能会对数据主体权利的行使产生影响。从本质上讲,所确定的确保有效实施数据主体权利的方法似乎在技术上很复杂,包括其有效性,323可能需要进一步完善,并且本身并非没有挑战。
5.4版权挑战
关键信息:
- 人工智能革命已经影响了版权格局,在不久的将来需要澄清几个关键问题。这些问题包括如何将文本和数据挖掘(TDM)例外正确应用于GenAI模型的训练过程,以及在AI生成的输出可能侵犯与训练过程中使用的内容相关的第三方版权的情况下的责任问题,如果是这样,谁将对此类侵权行为负责。
- 有必要找到统一的方法来保留权利,并避免欧盟成员国法院的不同意见加剧目前缺乏一致性的情况。加强标准化工作对于创建一个统一和可预测的版权框架至关重要,使所有利益相关者受益。现有技术(如广泛用于Web服务器的robots.txt)可能不太适合GenAI应用程序,这一事实进一步强调了这一需求。
- 必须寻求解决方案,公平地补偿其作品用于人工智能培训过程的创作者。
人工智能给知识产权领域带来了相当大的挑战。这些挑战是紧迫的,因为在两个重要目标之间找到平衡至关重要:一方面,保护创作者的知识产权,关注未经授权使用他们的作品或缺乏补偿,另一方面,通过确保人工智能开发人员能够及时获得训练模型所需的内容来促进快速创新,但投诉方式。然而,挑战超出了这种冲突,在人工智能模型的整个生命周期的各个阶段都会出现,如以下段落所述。
1.从输入的角度来看,最重要的问题是对人工智能进行受版权保护的材料的培训。为了访问内容,人工智能解决方案提供商需要采取数据抓取、Web抓取、Web抓取等活动,并进一步进行数据挖掘。如果有疑问,《人工智能法案》澄清了“文本和数据挖掘技术可在此背景下广泛用于此类内容的检索和分析”325 -即人工智能模型的开发和训练。
根据关于数字单一市场版权和相关权利的指令(欧盟)2019/790(“DSM指令”),文本和数据挖掘(“TDM”)被定义为“旨在分析数字形式的文本和数据以生成包括但不限于模式,趋势和相关性的信息的任何自动分析技术”。所有这些活动本质上都涉及文本和数据的复制,这是权利人的专有权利。DSM指令规定了两种例外情况,允许对受保护作品进行TDM活动。第3条规定了一个例外,允许TDM用于合法获取的作品的科学研究目的,包括研究结果的验证,不受限制。第4条中详述的其他例外允许为TDM目的提取和复制合法访问的作品,如果权利人没有以适当的方式明确保留此类活动。然而,第4条中概述的例外情况带来了复杂性,因为它取决于权利人是否能够选择不使用其受版权保护的内容,只要他们以适当的方式这样做,例如通过机器可读的方式在线公开提供内容。“机器可读手段”的定义似乎具有挑战性,特别是DSM指令的第18段似乎留下了解释的空间,即是否可以仅通过条款和条件保留权利,或者元数据和条款是否都需要是机器可读的。
目前,最受认可的机器可读方法是机器人排除协议(Robot Exclusion Protocol)。txt)中指定的。然而,robots.txt存在几个缺点,因为它不允许“权利持有者指示他们的退出适用于特定类别的使用,例如no-tdm或no-generative-ai”。目前正在努力解决这一限制,包括IETF的AI首选项(AIPREF)工作组的工作,326该工作组正在开发一个通用词汇表,以支持在robots.txt等协议中对选择退出首选项进行更细粒度的表达。鉴于这些挑战,有人建议,合规政策应区分至少两种不同的退出机制:全面的TDM退出机制(“no-tdm”)和特定的生成性人工智能培训退出机制(“no-generative-ai”),这将专门适用于使用作品来培训《人工智能法》第105条所述的人工智能模型子集。
目前,大量数据提供商通过其网站上的服务条款禁止使用其内容,无论是专门用于人工智能培训还是更一般的“任何目的”。根据DSM指令,这种手段在多大程度上可被接受为有效的选择退出,尚未得到统一判例的支持。德国的一项决定328指出,“完全以’自然语言’拟订的使用保留(不像法律的文献中假定占主导地位的观点”)可被视为’机器可读的;但是,必须根据“使用作品的相关时间存在的技术发展”来评估这种保留,但该决定没有采取具有约束力的立场。
在2024年10月的一项裁决中,阿姆斯特丹地方法院329还必须考虑权利人(出版商)是否以机器可读的形式选择退出TDM。被告(一家商业新闻聚合商)辩称,在本案中,对自动搜索的禁止仅限于专门指定的人工智能机器人,如GPTBot、ChatGPT-User、CCBOT和anthropic-ai,索赔人未能反驳这一指控。判决的措辞有些模糊不清,不清楚裁决是否仅仅涉及所提出的证据,或者法院是否在决定什么构成适当的权利保留。
在最近的一项美国法院裁决中,330确定合理使用辩护,这可能被认为是欧盟版权法中的例外和限制的普通法等同物,不能用于训练人工智能模型。尽管这一案例与当前讨论的相关性是有争议的,因为它被认为“不是生成性人工智能(自己编写新内容的人工智能)”,但监测这一裁决如何影响美国的人工智能提供商,特别是那些从事培训生成性人工智能模型的人,仍然是有趣的。在纽约时报(“纽约时报”)针对OpenAI在模型训练期间未经授权使用纽约时报内容发起的一个正在进行的案件331中,OpenAI也依赖于合理使用辩护。
2.从人工智能生成的输出的角度来看,主要问题是这些输出是否符合版权保护的条件,如果符合,谁拥有所生成作品的版权。另一个问题是,人工智能生成的输出是否可能侵犯与培训过程中使用的内容相关的第三方版权,如果是,谁对这种侵权行为负责。
关于版权保护,有理由认为,如果人工智能生成的输出受到用户与人工智能工具交互的影响,通过精确的指令和反映个人风格的创造性选择,它可以被视为原创,因此有资格获得版权保护。但是,创建者必须演示提示过程。在布拉格市法院的第332号裁决中,法官否决了对一幅图像的版权保护,因为创作者没有用具体证据证明作者身份,而仅仅依靠个人陈述。
在美国,Théâtre D’opéra Spatial333和A Single Piece of American Cheese 334等案件的判决突显了版权局对人工智能生成内容处理的最初质疑。然而,美国版权局最近于2025年1月发布的《版权与人工智能》报告335得出的结论是,“使用人工智能工具来协助而不是取代人类的创造力,不会影响产出的版权保护的可用性”。
在中国,一项关于人工智能输出的版权性的早期判决336裁定,由于创作者的“智力投入”,原告的作品符合版权保护的条件。“调整和修改过程反映了原告的审美选择和个性化判断”,使作品具有原创性。
关于作者身份,传统的知识产权法律是基于人类作者身份的,这在人工智能系统生成内容时会产生歧义。根据欧洲法院的判例法,当使用人工智能工具创作的作品被视为“原创”并因此受到版权保护时,版权将属于使用人工智能工具的作者;337否则,不可能有任何版权保护。
当人工智能输出侵犯版权内容时,这通常是由模型训练过程中被称为“记忆”的过程造成的,在这个过程中,模型过于精确地学习数据,逐字复制它们。如果人工智能提供者使用材料的权利受到限制,这种复制就会成为一个问题。例如,如果人工智能提供商依赖于TDM等版权例外,允许数据仅用于文本和数据挖掘,则TDM例外不包括随后的复制或通过输出生成向公众传播。
接下来的问题是,在侵犯版权的情况下,谁应该承担责任。用户和人工智能提供商都可以根据被侵犯的具体权利和使用侵权内容的背景而承担责任。
到目前为止,大多数案件都针对AI提供商。在美国,纽约时报等出版商或Getty Images或Concord Music等创作者代表于2023年底至2024年初针对OpenAI、Stability AI或Anthropic等AI提供商发起了一系列案件。在德国,一个集体权利管理组织GEMA宣布,它正在起诉OpenAI和SunoAI侵犯版权。340在法国,Syndicat national de l’édition(SNE)、Société des Gens de Lettres(SGDL)和Syndicat national des auxiliary et des compositional(SNAC)宣布,它们开始起诉Meta非法培训其人工智能模型。
在英国,Getty Images和其他公司已经向高等法院起诉Stability AI侵犯版权。该案件凸显了一个代表问题,索赔人为超过50,000名拥有盖蒂图片集团独家许可的版权持有者提起诉讼,促使法官要求双方在2025年6月审判前解决“严重的案件管理问题”。
为了应对越来越多的判例法,特别是在美国,OpenAI等提供商与众多出版商达成了多项协议。这些协议不仅是为了解决将这些内容用于培训目的的问题,而且也是为了解决通过产出复制摘录的问题,“有明确的引用和与原始来源的直接链接”。343在格拉斯哥大学创意经济监管中心提供的答复中,在2025年2月提交给英国政府的版权和人工智能咨询报告中,345 CREATe确定了内容提供商和人工智能开发商之间的83项商业协议,其中68%是关于新闻和新闻媒体内容的。许可,特别是集体许可和谈判346已被确定为解决权利人公平报酬问题的潜在解决办法,尽管具有挑战性。
看来,GenAI已经改变了版权格局,在不久的将来需要澄清几个关键问题,其中包括TDM的适用性和适当的权利保留,权利人的赔偿和版权责任。为此,有效的解决办法很可能来自各利益攸关方之间的合作。
5.5横向数据立法
关键信息:
- 欧洲数据战略旨在增强数据可用性和云基础设施,以支持人工智能和GenAI应用,建立共同的欧洲数据空间,以实现安全和可信的数据共享。
- 包括《数据治理法案》和《数据法案》在内的关键立法措施专注于提高数据的可访问性和重用性,特别是对于人工智能和GenAI,即将推出的数据联盟战略和数据实验室计划旨在提高数据质量和组织,以最大限度地发挥人工智能的潜力。
如第1.3节所述,如果没有质量和数量合适的数据,GenAI就不可能应用。本节概述了欧盟规范数据共享的广泛政策背景,重点是欧盟的主要政策举措和相关立法及其对GenAI的影响和影响。欧洲数据战略348于2020年与人工智能白色白皮书一起发布,制定了雄心勃勃的政策议程,旨在充分发挥欧盟数据驱动创新的潜力,认识到(其中包括)需要提高数据可用性和采用云计算基础设施来推动人工智能应用。该战略还设想建立欧洲共同数据空间,作为分散、联合和主权的环境,以安全、可靠和值得信赖的方式,在完全符合欧洲规则和价值观的情况下,跨行为体和部门共享数据。在数字欧洲计划的资助下,Horizon Europe提供了额外的捐款,14个主题领域的数据空间已经概念化,目前(2025年夏季)正在进行实际部署。数据空间支持中心最近发布的一份白色文件350探讨了这种相互作用,该项目的任务是协调欧洲通用数据空间的开发。
实现愿景
为了帮助实现欧洲数据战略的宏伟目标,提出了一套关于数据共享事项的横向法律的规定。首先,这包括从2023年9月起适用的《数据治理法》,并实施跨领域措施,以提高数据可用性,克服数据重用的技术障碍,包括GenAI应用。为此,DGA建立了一个适用于一类新的参与者-数据中介的特定法律的制度,为数据提供者和数据寻求者之间提供了一个治理和信任框架。《数据法》第352条自2025年9月起适用,旨在通过制定措施,使更多数据可供重用,其中包括重用物联网(IoT)设备生成的数据。此外,自2024年6月起适用的《高价值数据集实施法案》353通过定义公共部门组织的数据集列表(另见第6.5节)来实施开放数据指令354,这些数据集的重复使用(特别是中小企业的重复使用)有可能为欧盟经济和社会带来高经济效益,包括通过人工智能和GenAI应用。这些数据集应根据开放获取许可证免费提供,并可通过应用程序接口访问。
前进方向
鉴于上述与数据有关的新立法的数量,根据欧洲联盟委员会2024-2029年计划,重点是实施这些法律的文书及其可能的简化。将于2025年下半年发布的数据联盟战略将为改善可靠、高质量和组织良好的数据的访问指明道路,以释放人工智能应用的全部力量,并充分利用欧洲的数据生态系统。数据实验室将加强这一点–这是一种新工具,可以提供、汇集和安全共享高质量数据,充当中央枢纽,汇集和组织与同一行业内运营的人工智能工厂相关的数据。此外,数据实验室将与欧洲通用数据空间保持一致并连接,从而将碎片化的数据源转换为联合的高质量数据集,以支持GenAI模型的开发。
以上内容全部使用机器翻译,如果存在错误,请在评论区留言。欢迎一起学习交流!
郑重声明:
- 本文内容为个人对相关文献的分析和解读,难免存在疏漏或偏差,欢迎批评指正;
- 本人尊重并致敬论文作者、编辑和审稿人的所有劳动成果,若感兴趣,请阅读原文并以原文信息为准;
- 本文仅供学术探讨和学习交流使用,不适也不宜作为任何权威结论的依据。
- 如有侵权,请联系我删除。xingyezn@163.com

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)