AI基础学习周报七
本周聚焦时间序列Transformer机制解析与数据分析工具实践。深入研究Transformer在时序预测中的效能本质,通过互信息分析与合成数据集验证,揭示模型性能主要由单变量趋势捕捉能力而非复杂注意力机制主导;系统学习Matplotlib可视化技术,掌握多子图绘制、样式定制及图表属性控制;全面实践Pandas数据处理流程,涵盖对象创建、索引操作、数据变形及透视分析,构建了从理论到应用的数据分析能
摘要
本周聚焦时间序列Transformer机制解析与数据分析工具实践。深入研究Transformer在时序预测中的效能本质,通过互信息分析与合成数据集验证,揭示模型性能主要由单变量趋势捕捉能力而非复杂注意力机制主导;系统学习Matplotlib可视化技术,掌握多子图绘制、样式定制及图表属性控制;全面实践Pandas数据处理流程,涵盖对象创建、索引操作、数据变形及透视分析,构建了从理论到应用的数据分析能力矩阵。
Abstract
This week’s focus centers on the mechanism analysis of time series Transformers and the practical application of data analysis tools. We conducted an in-depth study on the efficacy of Transformers in time series forecasting, validating through mutual information analysis and synthetic datasets that model performance is primarily driven by univariate trend capture capabilities rather than complex attention mechanisms. We systematically mastered Matplotlib visualization techniques, including multi-subplot creation, style customization, and chart attribute control. Comprehensive Pandas data processing workflows were practiced, covering object creation, indexing operations, data reshaping, and pivot analysis, thereby building a multidimensional competency framework bridging theory to application in data analysis.
一、Transformer:为何有效,瓶颈何在?
论文对该研究并未提出新模型,而是对现有时间序列 Transformer 模型进行了一次深刻的拷问——为何结构更简单的 Transformer( PatchTST, iTransformer)在各大基准测试中,反而能优于设计更复杂的模型?
研究发现,当前主流基准数据集的性能主要由单变量内部的依赖关系主导,而跨变量间的影响较小。因此,模型的成功更多地得归功于Z-score 归一化和Skip connections等组件,它们极大地增强了模型捕捉单变量趋势的能力。本文通过引入互信息分析和可控的合成数据集,系统性地揭示了现有 Transformer 模型的真实能力和局限性,为未来设计更适用于真实、复杂场景的模型提供了重要见解。
【论文标题】A Closer Look at Transformers for Time Series Forecasting: Understanding Why They Work and Where They Struggle
【论文链接】https://papers.cool/venue/kHEVCfES4Q@OpenReview
1.1 研究背景
Transformer 在时间序列预测领域取得了巨大成功。研究者们提出了多种 Token 化策略,Point-wise、Patch-wise和Variate-wise,以捕捉不同维度的数据依赖。虽然模型架构日益复杂,但是一些设计相对简单的模型,如仅关注单变量内部模式的 PatchTST 和专注于跨变量关系的 iTransformer,却在性能测试中稳定名列前茅。
这种现象引出了一系列关键问题:
为什么以时间点为单位进行建模的 Point-wise Transformer 效果普遍较差? 为什么关注单变量的 Intra-variate attention 和关注多变量的 Inter-variate attention 会取得相似的性能?
那些成功的简单 Transformer 模型,获得其卓越性能的真正原因是什么? 针对这些问题,此论文摒弃了提出新模型的思路,转而设计了一套系统的分析框架,目的是深入理解现有模型的工作机制和真正的优势所在。
1.2 核心贡献
本研究贡献可总结如下:
-
通过实验证明,在大多数标准基准上,模型的预测性能主要由捕捉单变量内部依赖的能力决定,而跨变量依赖的影响则小得多。这解释了为何不同注意力机制的模型能取得相似结果。
-
设计了一套基于Mutual Information的评估指标,用于量化模型对不同维度依赖的捕捉能力。同时,创建了可控的合成数据集,能够系统性地评估模型在不同依赖结构下的表现。
-
得出了时序模型的核心组件:研究发现,Z-score 实例归一化和编码器中的跳跃连接是推动模型成功的关键技术组件,而非复杂的注意力设计本身。
-
在真实的医疗健康数据集上验证了研究发现,指出基准数据集的自依赖和平稳特性是影响模型评估结果的重要因素,并为设计面向更复杂应用的 Transformer 提供了实践指导。
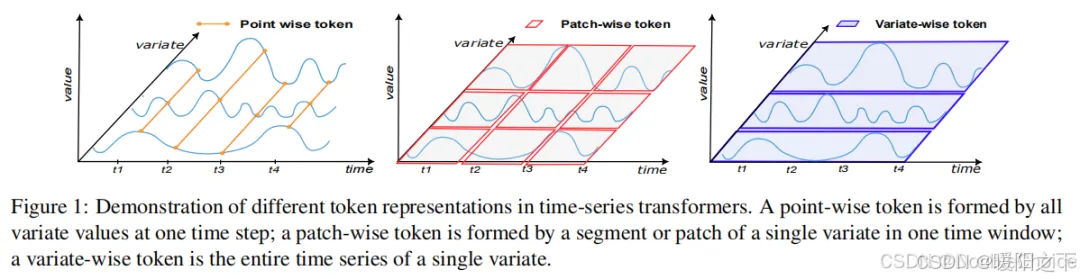
1.3 方法解析
本文的核心并非一个新模型,而是一套创新的分析框架。该框架旨在客观、定量地评估不同transformer模型捕捉时间序列依赖关系的能力。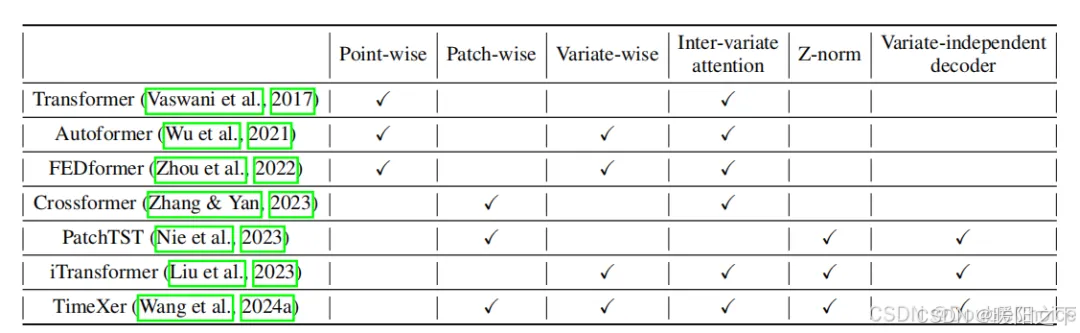

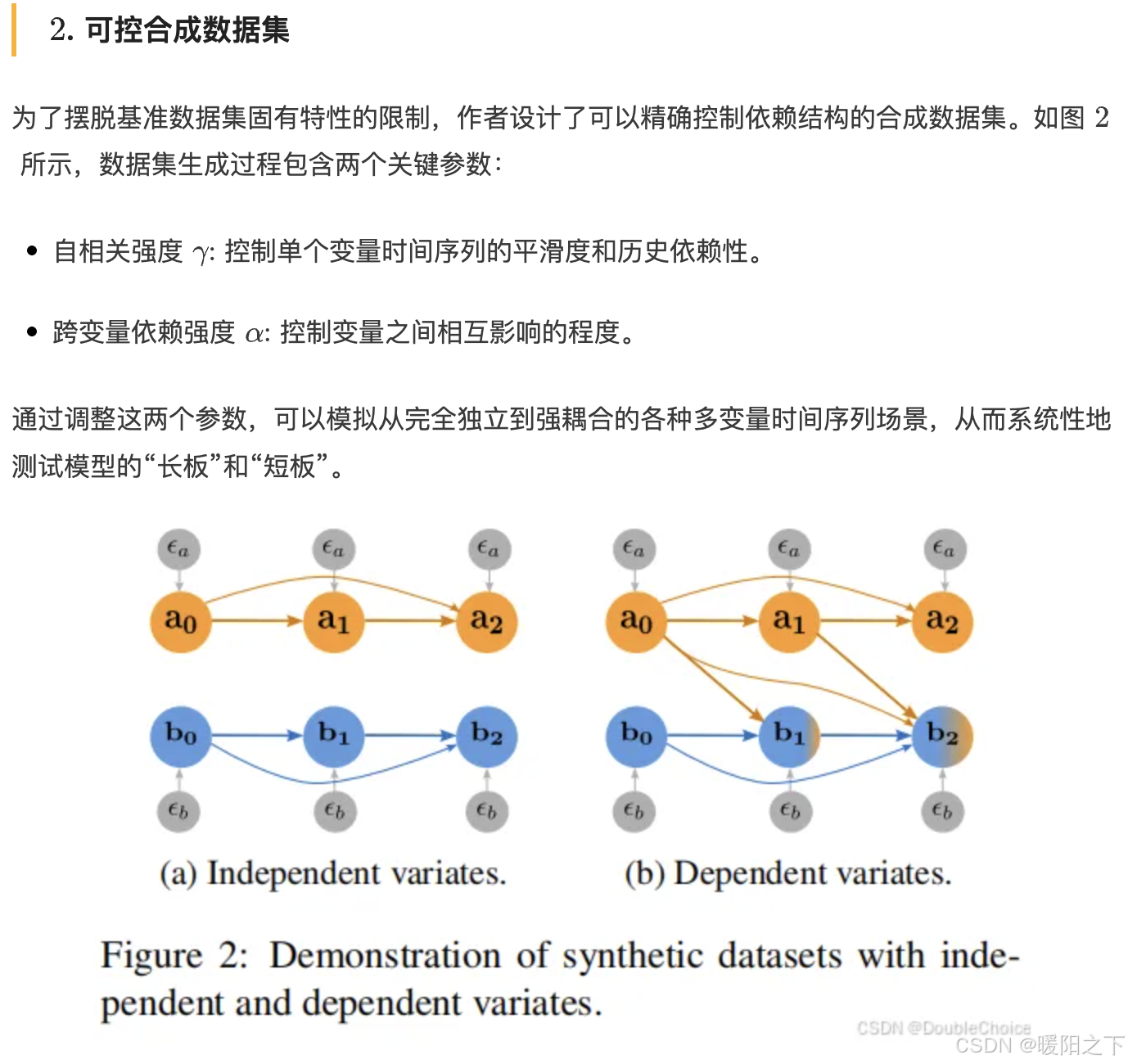

1.4 总结
本文通过一套严谨的分析框架,揭示了当前时间序列 Transformer研究中的一个重要“盲点”:模型的成功在很大程度上被基准数据集的内在特性以及简单而有效的技术组件,Z-score归一化、跳跃连接所驱动,而非表面上宣传的复杂注意力机制。这提醒研究者们需要重新审视模型的评估方式,并开发更多样化、更接近现实世界的基准,以推动领域向解决真正复杂问题迈进。
一言概括之,时序Transformer的成功秘诀,可能不在于花哨的注意力,而在于对单变量趋势的精准捕捉和数据归一化的巧妙运用。
二、Matplotlib学习
Matplotlib图像的主要组成部分包括:
画布(figure):画布是所有绘制元素的顶级容器,可将其视为一张白纸,供我们后期创作;
轴域(axes):轴域是图中绘制数据的矩形区域,每个画布可以包含一个或多个轴,轴提供坐标系;
标题(title):标题是一个文本元素,通常用于提供所绘图像的信息;
轴标签(x label,y label):标签是为 x 轴和 y 轴提供描述的文本元素,用于提供单位或其他相关信息;
图例(legend):图例用于指示图中不同元素的含义;
网格线(grid):网格线用于帮助读者对齐刻度线,从而更准确地读取数据点的位置和值。

2.1 绘图基础
Matplotlib 库太大,画图通常仅仅使用其中的核心模块 matplotlib.pyplot, 并给其一个别名 plt,即 import matplotlib.pyplot as plt。
设置图像大小
用plt.figure函数设置图片大小,其中figsize为元组,分别代表长宽,dpi(Dot Per Inch)为分辨率表示的单位之一。
plt.figure(figsize=(20,8),dpi=150) #图片大小为20*8,每英寸150个像素点
绘制图像
import matplotlib.pyplot as plt
# 绘制图像 Fig1 = plt.figure()
x = [ 1, 2, 3, 4, 5 ]
y = [ 1, 8, 27, 64, 125 ]
plt.plot(x,y)
# 创建新图窗 # 数据的 x 值 # 数据的 y 值 # plot 函数:先描点,再连线
保存图像
保存图形用.savefig( )方法,其需要一个 r 字符串:r’绝对路径\图形名.后缀’。
绝对路径:如果要保存到桌面,绝对路径即:C:\Users\用户名\Desktop;
后缀 :可保存图形的格式很多,包括:eps、jpg、pdf、png、ps、svg 等。 为了保存清晰的图,推荐保存至 svg 矢量格式,即
Fig2.savefig(r'C:\Users\zjj\Desktop\我的图.svg')
plt.savefig("./t1.png") #将图片保存到本地
保存为 svg 格式后,可直接拖至 Word 或 Visio 中,即可显示高清矢量图。
2.2 多图形的绘制
绘制多线条
# 准备数据
x = [ 1, 2, 3, 4, 5 ]
y1 = [ 1, 2, 3, 4, 5 ]
y2 = [ 0, 0, 0, 0, 0 ]
y3 = [ -1, -2, -3, -4, -5 ]
# Matlab 方式 Fig1 = plt.figure()
plt.plot(x,y1) plt.plot(x,y2) plt.plot(x,y3)
绘制多子图
# Matlab 方式
Fig1 = plt.figure()
plt.subplot(3,1,1), plt.plot(x,y1)
plt.subplot(3,1,2), plt.plot(x,y2)
plt.subplot(3,1,3), plt.plot(x,y3)
# 面向对象方式 Fig2, ax2 = plt.subplots(3)
ax2[0].plot(x,y1)
ax2[1].plot(x,y2)
ax2[2].plot(x,y3)
2.3 图表类型
图表类型
plt 提供 5 类基本图表,分别是二维图、网格图、统计图、轮廓图、三维图。 详见 https://matplotlib.org/stable/plot_types/index 。
除了上述链接中的这五类基本图表外,还有更多作者提前画好的花哨的靓图, 详见 https://matplotlib.org/stable/gallery/index.html 。
最后,作者还温馨地向小白的我们提供了从 0 开始到大神的完整教程,详见: https://matplotlib.org/stable/tutorials/index.html 。但是,UP 认为,这是额外的内容, 作为一个技术工程师,在画图上(而非技术上)花费太多时间,这叫做主次颠倒。
二维图
- 设置颜色
plot()函数含 color 参数,可以设置线条的颜色
- 设置风格
plot()函数含 linestyle 参数,可以设置线条的风格
- 设置粗细
plot()函数含 linewidth 参数,可以设置线条的粗细
- 设置标记
plot()函数含 marker 参数,可以设置线条的标记
# Matlab 方式 Fig1 = plt.figure()
plt.plot(x, y1, color='#7CB5EC', linestyle='-', linewidth=2, marker='o', markersize=6)
plt.plot(x, y2, color='#F7A35C', linestyle='--', linewidth=2, marker='^', markersize=6)
plt.plot(x, y3, color='#A2A2D0', linestyle='-.', linewidth=2, marker='s', markersize=6)
plt.plot(x, y4, color='#F6675D', linestyle=':', linewidth=2, marker='D', markersize=6)
plt.plot(x, y5, color='#47ADC7', linestyle=' ', linewidth=2, marker='o', markersize=6)
2.4 图窗属性
坐标轴上下限
- lim 法
# Matlab 方式(lim 法)
Fig1 = plt.figure()
plt.plot(x,y)
plt.xlim(1,5)
plt.ylim(1,125)
- axis 法
# Matlab 方式(axis 法)
Fig5 = plt.figure()
plt.plot(x,y)
plt.axis([1, 5, 1, 125])
标题与轴名称
# Matlab 方式
Fig1 = plt.figure()
plt.plot(x,y)
plt.title('This is the title.')
plt.xlabel('This is the xlabel')
plt.ylabel('This is the ylabel')
# 面向对象方式
Fig2, ax2 = plt.subplots() ax2.plot(x,y)
ax2.set_title('This is the title.')
ax2.set_xlabel('This is the xlabel')
ax2.set_ylabel('This is the ylabel')
网格
# Matlab 方式
Fig1 = plt.figure()
plt.plot(x, y1)
plt.plot(x, y2)
plt.plot(x, y3)
plt.grid(color='#000000',linestyle='--') #grid()函数还有 color 与 linestyle 两个参数
三、Pandas标签库学习
3.1 对象的创建
导入 Pandas 时,通常给其一个别名“pd”,即 import pandas as pd。
作为标签库,Pandas 对象在 NumPy 数组基础上给予其行列标签。可以说,列表之于字典,就如 NumPy 之于 Pandas。
Pandas 中,所有数组特性仍在,Pandas 的数据以 NumPy 数组的方式存储。
一维对象的创建
字典创建法
NumPy 中,可以通过 np.array()函数,将 Python 列表转化为 NumPy 数组;同样,Pandas 中,可以通过 pd.Series()函数,将 Python 字典转化为 Series 对象。
# 创建字典
dict_v = { 'a':0, 'b':0.25, 'c':0.5, 'd':0.75, 'e':1 }
# 用字典创建对象
sr = pd.Series( dict_v )
sr
a 0.00
b 0.25
c 0.50
d 0.75
e 1.00
dtype: float64
数组创建法
最直接的创建方法即直接给 pd.Series()函数参数,其需要两个参数。第一个参数是值 values(列表、数组、张量均可),第二个参数是键 index(索引)。
# 先定义键与值
v = [0, 0.25, 0.5, 0.75, 1]
k = ['a', 'b', 'c', 'd', 'e']
# 用列表创建对象
sr = pd.Series( v, index=k )
sr
a 0.00
b 0.25
c 0.50
d 0.75
e 1.00
dtype: float64
A = pd.Series(data = [1, 2, 3, 4, 5], index = ["A", "B", "C", "D", "E"], name = "A1")
print(A)
其中,参数 index 可以省略,省略后索引即从 0 开始的顺序数字。
一维对象的属性
Series 对象有两个属性:values 与 index。
import numpy as np
import pandas as pd
# 用数组创建 sr
v = np.array( [ 53, 64, 72, 82 ] )
k = ['1 号', '2 号', '3 号', '4 号']
sr = pd.Series( v, index=k )
sr
1 号 53
2 号 64
3 号 72
4 号 82
dtype: int32
# 查看 values 属性
sr.values
array([53, 64, 72, 82])
# 查看 index 属性
sr.index
Index(['1 号', '2 号', '3 号', '4 号'], dtype='object')
二维对象的创建
二维对象将面向矩阵,其不仅有行标签 index,还有列标签 columns。
字典创建法
用字典法创建二维对象时,必须基于多个 Series 对象,每一个 Series 就是一列数据,相当于对一列一列的数据作拼接。
创建 Series 对象时,字典的键是 index,其延展方向是竖直方向;
创建 DataFrame 对象时,字典的键是 columns,其延展方向是水平方向。
# 创建 sr1:各个病人的年龄
v1 = [ 53, 64, 72, 82 ]
i = [ '1 号', '2 号', '3 号', '4 号' ]
sr1 = pd.Series( v1, index=i )
sr1
1 号 53
2 号 64
3 号 72
4 号 82
dtype: int64
# 创建 sr2:各个病人的性别
v2 = [ '女', '男', '男', '女' ]
i = [ '1 号', '2 号', '3 号', '4 号' ]
sr2 = pd.Series( v2, index=i )
sr2
1 号 女
2 号 男
3 号 男
4 号 女
dtype: object
# 创建 df 对象
df = pd.DataFrame( { '年龄':sr1, '性别':sr2 } )
df
Out [4] : 年龄 性别
1 号 53 女
2 号 64 男
3 号 72 男
4 号 82 女
如果 sr1 和 sr2 的 index 不完全一致,那么二维对象的 index 会取 sr1 与 sr2 的所有 index,相应的,该对象就会产生一定数量的缺失值(NaN)。
数组创建法
最直接的创建方法即直接给 pd.DataFrame 函数参数,其需要三个参数。第一个参数是值 values(数组),第二个参数是行标签 index,第三个参数是列标签columns。其中,index 和 columns 参数可以省略,省略后即从 0 开始的顺序数字。
import numpy as np
import pandas as pd
# 设定键值
v = np.array( [ [53, '女'], [64, '男'], [72, '男'], [82, '女'] ] )
i = [ '1 号', '2 号', '3 号', '4 号' ]
c = [ '年龄', '性别' ]
# 数组创建法
df = pd.DataFrame( v, index=i, columns=c )
df
年龄 性别
1号 53 女
2号 64 男
3号 72 男
4号 82 女
细心的同学可能会发现端倪,In [2]第二行的 NumPy 数组居然又含数字又含字符串,上次课中明明讲过数组只能容纳一种变量类型。这里的原理是,数组默默把数字转为了字符串,于是 v 就是一个字符串型数组。
二维对象的属性
DataFrame 对象有三个属性:values、index 与 columns。
# 设定键值
v = [ [53, '女'], [64, '男'], [72, '男'], [82, '女'] ]
i = [ '1 号', '2 号', '3 号', '4 号' ]
c = [ '年龄', '性别' ]
# 数组创建法
df = pd.DataFrame( v, index=i, columns=c )
df
年龄 性别
1 号 53 女
2 号 64 男
3 号 72 男
4 号 82 女
# 查看 values 属性
df.values
array([[53, '女'],
[64, '男'],
[72, '男'],
[82, '女']], dtype=object)
# 查看 index 属性
df.index
Index(['1 号', '2 号', '3 号', '4 号'], dtype='object')
3.2 对象的索引
在学习 Pandas 的索引之前,需要知道
Pandas 的索引分为显式索引与隐式索引。显式索引是使用 Pandas 对象提供的索引,而隐式索引是使用数组本身自带的从 0 开始的索引。
现假设某演示代码中的索引是整数,这个时候显式索引和隐式索引可能会出乱子。于是,Pandas 作者发明了索引器 loc(显式)与iloc(隐式),
手动告诉程序自己这句话是显式索引还是隐式索引。
本章示例中,若代码块出现两栏,则左侧为显式索引,右侧为隐式索引,
左右两列属于平行关系,任选其一均可。
一维对象的索引
- 访问元素
# 创建 sr
v = [ 53, 64, 72, 82 ]
k = ['1 号', '2 号', '3 号', '4 号']
sr = pd.Series( v, index=k )
sr
1 号 53
2 号 64
3 号 72
4 号 82
dtype: int64
# 访问元素
sr.loc[ '3 号' ]
72
# 访问元素
sr.iloc[ 2 ]
72
- 访问切片
# 创建 sr
v = [ 53, 64, 72, 82 ]
k = ['1 号', '2 号', '3 号', '4 号']
sr = pd.Series( v, index=k )
sr
1 号 53
2 号 64
3 号 72
4 号 82
dtype: int64
# 访问切片
sr.loc[ '1 号':'3 号' ]
1 号 53
2 号 64
3 号 72
dtype: int64
# 访问切片
sr.iloc[ 0:3 ]
1 号 53
2 号 64
3 号 72
dtype: int64
二维对象的索引
- 访问元素
# 字典创建法
i = [ '1 号', '2 号', '3 号', '4 号' ]
v1 = [ 53, 64, 72, 82 ]
v2 = [ '女', '男', '男', '女' ]
sr1 = pd.Series( v1, index=i )
sr2 = pd.Series( v2, index=i )
df = pd.DataFrame( { '年龄':sr1, '性别':sr2 } )
df
年龄 性别
1 号 53 女
2 号 64 男
3 号 72 男
4 号 82 女
# 访问元素
df.loc[ '1 号', '年龄' ]
# 花式索引
df.loc[ ['1 号', '3 号'] , ['性别','年龄'] ]
- 访问切片
# 切片
df.loc[ '1 号':'3 号' , '年龄' ]
# 切片
df.iloc[ 0:3 , 0 ]
3.3 对象的变形
对象的重塑
考虑到对象是含有行列标签的,.reshape()已不再适用,因此对象的重塑没有那么灵活。但可以做到将 sr 并入 df,也可以将 df 割出 sr。
# 数组法创建 sr
i = [ '1 号', '2 号', '3 号', '4 号' ]
v1 = [ 10, 20, 30, 40 ]
v2 = [ '女', '男', '男', '女' ]
v3 = [ 1, 2, 3, 4 ]
sr1 = pd.Series( v1, index=i )
sr2 = pd.Series( v2, index=i )
sr3 = pd.Series( v3, index=i )
sr1, sr2, sr3
# 字典法创建 df
df = pd.DataFrame( { '年龄':sr1, '性别':sr2 } )
df
# 把 sr 并入 df 中
df['牌照'] = sr3
df
# 把 df['年龄']分离成 sr4
sr4 = df['年龄']
sr4
3.4 导入Excel文件
创建 Excel 文件
首先,创建 Excel 文件,录入信息,第一列为 index,第一行为 columns。
如果你的数据没有 index 和 columns,也即你只是想导入一个数组,那么也请先补上行列标签,后续用 .values 属性就能将二维对象转换为数组。
接着,将其另存为为 CSV 文件。无视之后弹出的“工作薄的部分功能丢失”,csv 确实没有 Excel 功能多。这
个过程,表格的信息不会丢失,大可放心。
导入Excel信息
import pandas as pd
# 导入 Pandas 对象
df = pd.read_csv('Data.csv', index_col=0)
df
年龄 性别 牌照 kun
1 号 10 女 1 是
2 号 20 男 2 是
3 号 30 男 3 是
4 号 40 女 4 否
5 号 50 男 5 是
6 号 60 女 6 是
# 提取纯数组
arr = df.values
arr
array([[10, '女', 1, '是'],
[20, '男', 2, '是'],
[30, '男', 3, '是'],
[40, '女', 4, '否'],
[50, '男', 5, '是'],
[60, '女', 6, '是']], dtype=object)
import numpy as np
import pandas as pd
iris = pd.read_csv("D:/iris.csv")
print(iris.head())
3.5 数据分析
聚合方法
可在输出 df 时,对其使用 .head() 方法,使其仅输出前五行。
import pandas as pd
# 导入 Pandas 对象
df = pd.read_csv('行星数据.csv', index_col=0)
df.head()
NumPy 中所有的聚合函数对 Pandas 对象均适用。此外,Pandas 将这些函数变为对象的方法,这样,不导入 NumPy 也可使用。
描述方法
在数据分析中,用以上方法挨个查看未免太过麻烦,可以使用 .describe() 方法直接查看所有聚合函数的信息。
import pandas as pd
# 导入 Pandas 对象
df = pd.read_csv('行星数据.csv', index_col=0)
df.head()
发现时间 发现数量 观测方法 行星质量 距地距离 轨道周期
0 1989 1 径向速度 11.68 40.57 83.8880
1 1992 3 脉冲星计时 NaN NaN 25.2620
2 1992 3 脉冲星计时 NaN NaN 66.5419
3 1994 3 脉冲星计时 NaN NaN 98.2114
4 1995 1 径向速度 0.472 15.36 4.2308
df.describe()
发现时间 发现数量 行星质量 距地距离 轨道周期
count 1035 1035 513 808 992
mean 2009.070531 1.785507 2.638161 264.069282 2002.917596
std 3.972567 1.240976 3.818617 733.116493 26014.7283
min 1989 1 0.0036 1.35 0.0907
25% 2007 1 0.229 32.56 5.442575
50% 2010 1 1.26 55.25 39.9795
75% 2012 2 3.04 178.5 526.005
max 2014 7 25 8500 730000
第 1 行 count 是计数项,统计每个特征的有效数量(即排除缺失值),从 count可以看出,行星质量的缺失值比较多,需要考虑一定的办法填充或舍弃。
第 2 行至第 3 行的 mean 与 std 统计每列特征的均值与标准差。
第 4 行至第 8 行的 min、25%、50%、75%、max 的意思是五个分位点,即
把数组从小到大排序后,0%、25%、50%、75%、100%五个位置上的数值的取值。
显然,50%分位点即中位数。
数据透视
- 两个特征以内的数据透视
import pandas as pd
# 导入 Pandas 对象
df = pd.read_csv('泰坦尼克.csv', index_col=0)
df.head()
性别 年龄 船舱等级 费用 是否生还
0 男 22.0 三等 7.2500 0
1 女 38.0 一等 71.2833 1
2 女 26.0 三等 7.9250 1
3 女 35.0 一等 53.1000 1
4 男 35.0 三等 8.0500 0
# 一个特征:性别
df.pivot_table('是否生还', index='性别')
性别 是否生还
女 0.742038
男 0.188908
# 两个特征:性别、船舱等级
df.pivot_table('是否生还', index='性别', columns='船舱等级')
船舱等级 一等 三等 二等
性别
女 0.968085 0.500000 0.921053
男 0.368852 0.135447 0.157407
- 多个特征的数据透视
import pandas as pd
# 导入 Pandas 对象
df = pd.read_csv('泰坦尼克.csv', index_col=0)
df.head()
性别 年龄 船舱等级 费用 是否生还
0 男 22.0 三等 7.2500 0
1 女 38.0 一等 71.2833 1
2 女 26.0 三等 7.9250 1
3 女 35.0 一等 53.1000 1
4 男 35.0 三等 8.0500 0
# 三个特征:性别、船舱等级、年龄
age = pd.cut( df['年龄'], [0,18,120] ) # 以 18 岁为分水岭
df.pivot_table('是否生还', index= ['性别', age], columns='船舱等级')
船舱等级 一等 三等 二等
性别 年龄
女 (0, 18] 0.909091 0.511628 1.000000
(18, 120] 0.972973 0.423729 0.900000
男 (0, 18] 0.800000 0.215686 0.600000
(18, 120] 0.375000 0.133663 0.071429
总结
本周通过三方面研究构建了完整的技术认知体系:在时序模型领域,深入解析了Transformer在主流基准表现优异的本质原因;在可视化工具层面,系统掌握Matplotlib的画布控制、多图形布局及高级样式设置,实现科研级图表输出;在数据处理维度,全面实践Pandas的二维对象创建、分层索引机制及透视分析,完成从数据导入到特征聚合的完整流程。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)