ChatGPT 垫底,Claude 领先,7月底大模型测评榜单出人意料!
ChatGPT,曾经的王者,陷入替身危机。
Claude获得77分,Gemini获得76分,ChatGPT垫底,获得20分。
这项数据来自 AiPy 在 7 月 31 日发布的最新一期“大模型适配度测评报告”。测评围绕五大核心应用场景:信息获取、数据处理、可视化分析、系统分析、交互操作,共计130项任务。评估维度包括成功率(权重80%)、执行时间(权重10%)和Tokens消耗(权重10%)三个方面。
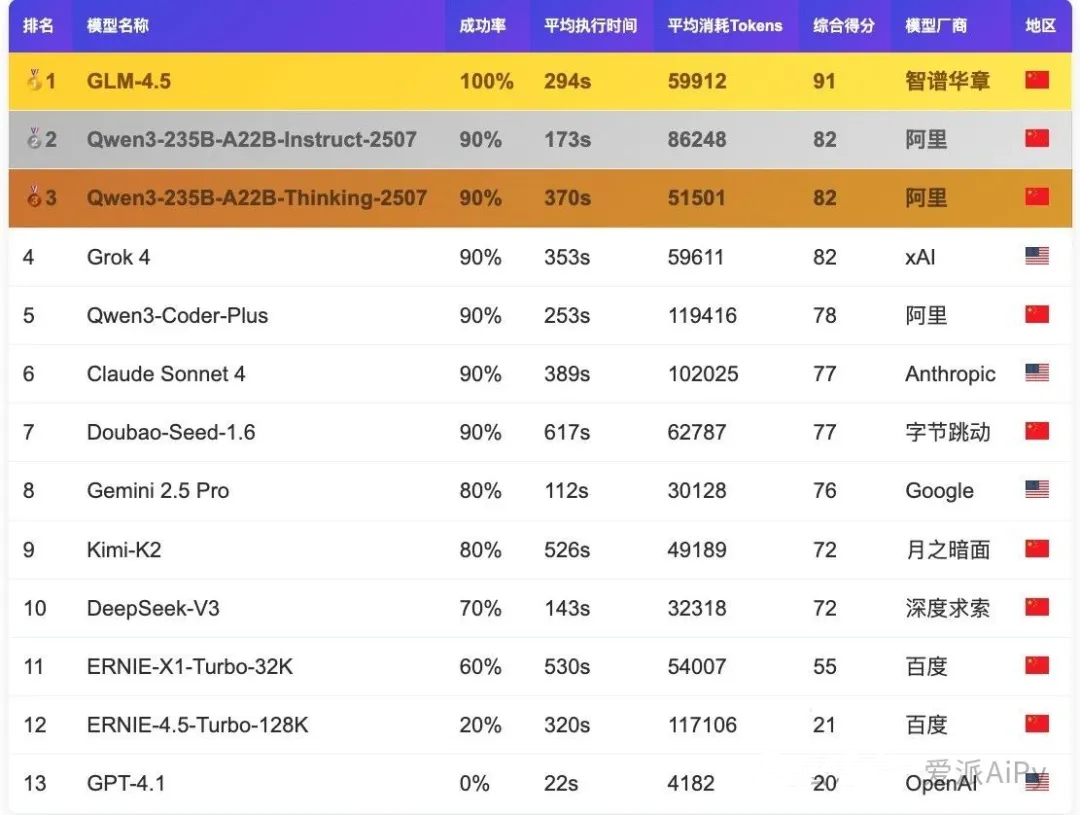
尽管这个数据的样本有限,但还是具有一定参照性的。
笔者认为,个性化模型时代,其实很难讨论哪个模型最强,这三个模型中,最强的不是某一个模型,而是:
大模型进入了“能力分化”的阶段,而不是“通吃”的阶段。
①Claude:不是最聪明的那一个,但最省心
在这次测评中,Claude Sonnet 4 被 xAI 的 Grok 超过,成功率和效率上均无突破亮点。结合我自己的使用感受,Claude 在复杂数据处理、系统任务规划、多语言交互这些偏“执行类”的任务中表现较为稳定但要说创新也算不上。
但是,不管是Sonnet还是Opus,Claude都延续了Anthropic团队那种“像人又不是人”的亲切感。它写的代码不一定是最前沿的,但稳、可复用、边角处理齐全,有时候你自己都没意识到有坑,它已经帮你垫上 try-catch 了。它理解需求不是靠语言模型的“意图捕捉”,而像是靠几十个老项目踩过的坑总结出的直觉。
它也不和你扯什么“架构哲学”,你想怎么写,它就照着你那套思路补上去,是一个比较默契的开发搭子。
②Gemini:跑得快、眼界广,但思维层级不稳定
Gemini的问题是,它知道得很多,但不一定能好好理解你要它干嘛。
在此次测评中,Gemini 2.5 Pro 是平均响应时间最快的模型,但它的成功率并不是最优。这印证了一个印象:Gemini 在语音、视频、搜索类任务中反应超快,但到了多步骤逻辑执行、任务拆解这些需要深层结构规划的任务上,就有点稚嫩。
我个人也有类似感受,Gemini 非常适合写资讯稿、做实时搜索类摘要,尤其多语言能力极强,但一旦你把任务链拉长,它容易在中途跑偏。
而且,目前 Gemini 在指令可控性上依然不如 Claude 或 GPT,表现出了一种先跑再想的特质。
Gemini适合对响应速度、信息广度要求极高的用户,例如外贸、新闻、翻译、内容审核团队,不太适合需要稳定长期逻辑推理、复杂任务链调度的开发或科研用户。
③ChatGPT(GPT-4.1):曾经的王者,陷入替身危机
必须要诚实地说一句:GPT 目前陷入了多重身份的泥潭。
它既要当写稿能手,又要兼顾多轮对话、又要接开发插件、又要应对成本控制,在企业端和消费者端之间左右为难,结果就是在每一项都不够极致。
从测评数据看,GPT-4.1 成功率为0,主要是因为它在代码任务中存在严重的代码块标记规范失败问题。这不代表它不能生成代码,而是说它无法稳定地完成严肃工作流中的代码处理任务,这对企业来说是致命的。
而在我最近的使用中也感受到一个很明显的问题:GPT越来越“滑”,它开始用策略型语言试图规避问题或模糊表述,以降低出错概率。听起来圆滑,实则效率下降。
OpenAI在最近的多模态集成、Agent实验上有一些探索,如GPT-4o,但能力丰富并没有换来能力强大。
GPT适合追求稳妥表达、综合问答、插件生态体验的用户,不适合谁需要低延迟、结构化、快速执行的生产场景用户。
当然,对于我们普通用户来说,我们只要择优选择适合任务场景的模型,每一个模型都能发挥最大效率。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 38
38 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)