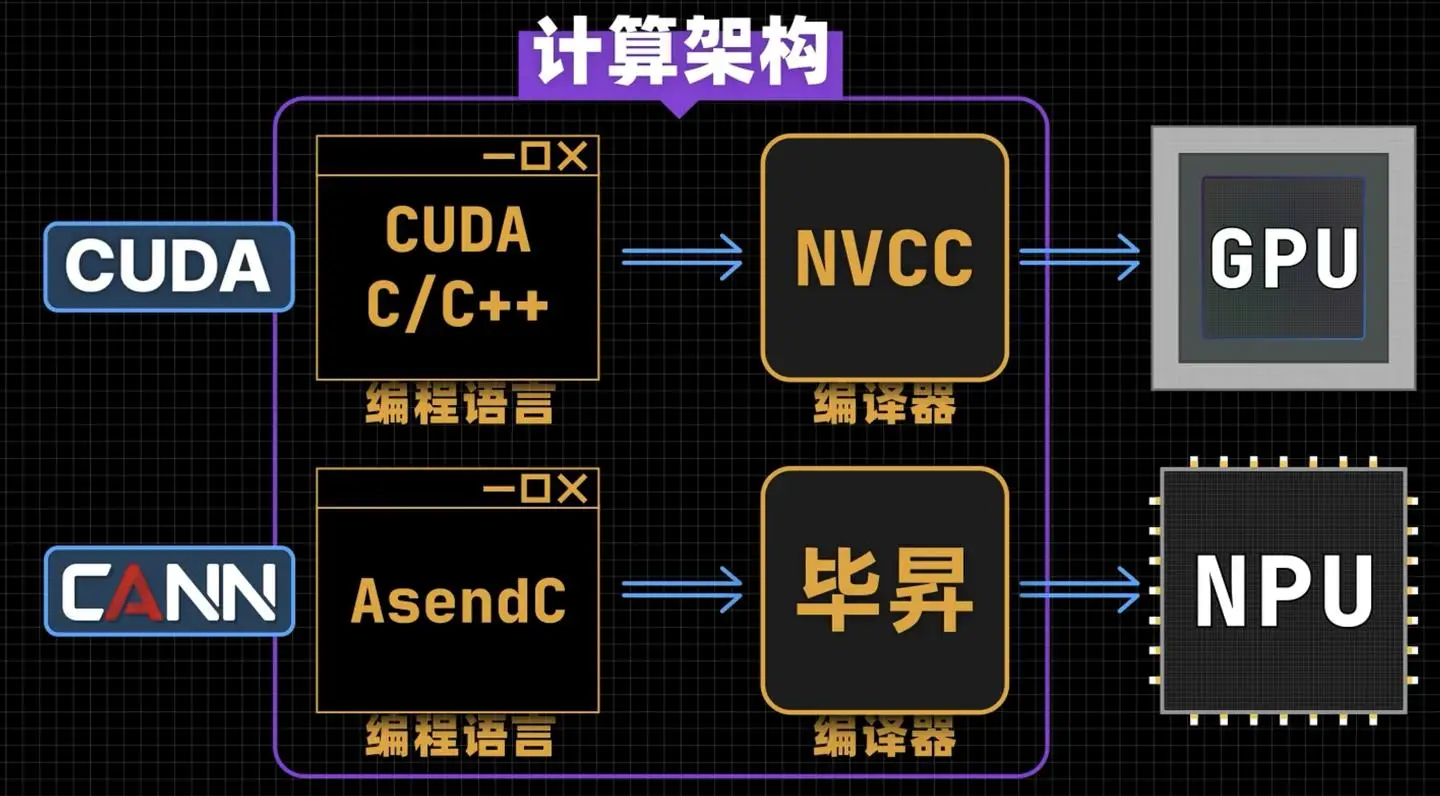
华为昇腾384超节点「全对等架构」是否意味着冯·诺依曼体系走到尽头?
华为昇腾384超节点的「全对等架构」是针对AI大模型需求的重要创新,突破了传统冯·诺依曼体系在超大规模并行计算中的通信瓶颈,实现384卡高速互联与高效分布式推理,使AI训练效率提升3倍。虽然该架构在AI领域表现突出,但冯·诺依曼体系在通用计算中仍不可替代。未来两者将呈现专用与通用场景分化、技术融合发展的趋势。这一创新标志着计算架构向专用化演进,但传统体系的基础思想仍将持续影响计算机科学发展。
·

一、核心结论
否,但标志传统架构在AI领域的突破。
华为昇腾384超节点的「全对等架构」并未完全取代冯·诺依曼体系,而是针对AI大模型的特定需求进行了架构创新。它解决了传统体系在超大规模并行计算中的通信瓶颈问题,但冯·诺依曼体系的通用性和灵活性在中小规模计算、通用软件生态中仍不可替代。未来,两者将呈现场景分化与融合发展的趋势。

二、详细分析
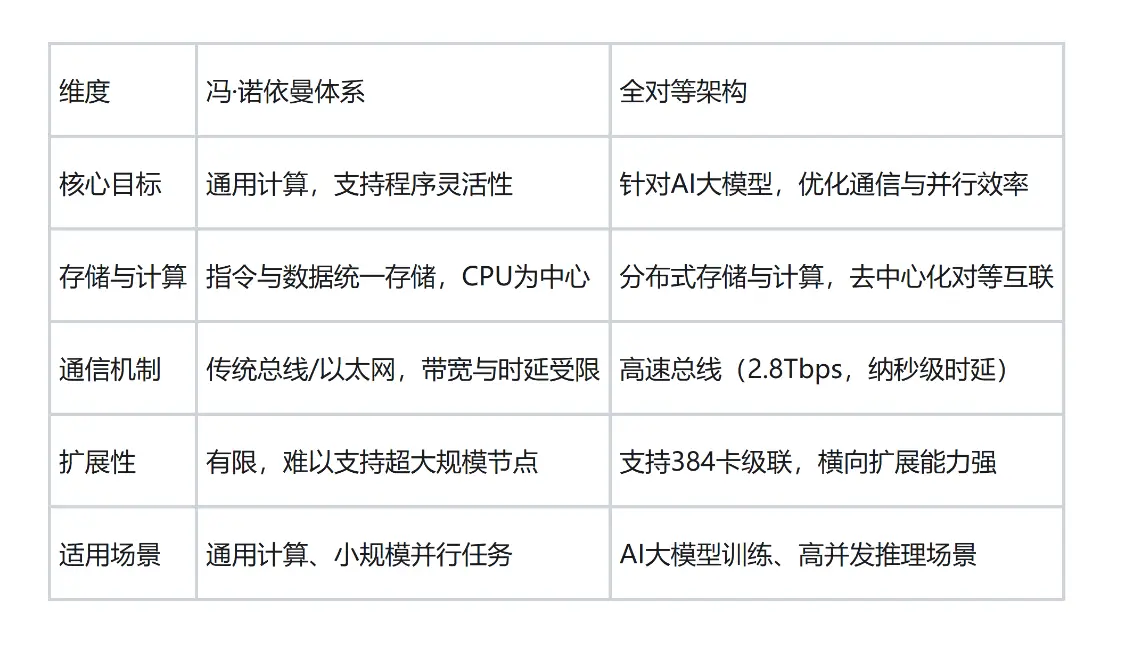
1. 冯·诺依曼体系的核心与局限
核心特征:
- 存储程序:指令与数据统一存储在内存中,通过CPU顺序执行。
- 模块化设计:运算器、控制器、存储器、输入输出设备分工明确,支持通用计算。
- 二进制基础:采用二进制进行数值计算,简化硬件设计。
历史局限:
- 通信瓶颈:集群间通信带宽增长(4倍)远低于单卡算力增长(40倍),导致AI大模型训练效率受限。
- 内存墙:CPU与内存间的数据传输速度成为性能瓶颈。
- 扩展性限制:传统总线架构难以支持超大规模节点(如384卡)的高效互联。
2. 全对等架构的创新点
架构设计:
- 对等互联:
- 通过高速总线(MatrixLink)实现384卡全对等互联,卡间带宽达2.8Tbps,时延降至纳秒级,突破传统以太网限制。
- 双层网络:
- ScaleUp总线网络:超节点内部高速无阻塞互联。
- ScaleOut网络:跨超节点间微秒级时延,支持弹性扩展。
- 分布式推理:
- 专为MoE模型设计,实现“一卡一专家”分布式推理,提升计算与通信效率。

性能提升:
- 通信效率:带宽提升15倍,时延降低10倍,解决集群通信瓶颈。
- 资源利用率:
- 细粒度资源分配(如“一卡一算子任务”)和训推共池,算力有效使用率(MFU)提升50%以上。
- “朝推夜训”模式使资源利用率提升30%,降低企业算力成本。
- 可靠性:
- 故障自愈机制(如“1-3-10”标准)确保90%硬件故障感知率,万卡集群快速恢复。
应用场景:
- AI大模型训练:尤其适合MoE、长序列、多模态模型,训练效率提升3倍。
- 训推一体化:支持“朝推夜训”模式,动态分配算力资源。
3. 与冯·诺依曼体系的对比
4. 行业评价与未来影响
正面评价:
- 华为云副总裁黄瑾: 全对等架构是“系统性、工程性创新”,突破通信效率瓶颈,定义下一代AI基础设施。
- 朗科科技: 通过存储技术适配(如PCIe 4.0 SSD)和服务器制造合作,验证了全对等架构的商业化潜力。
- 知乎用户分析: 全对等架构在性能上接近英伟达H100,且具备生态替代能力(兼容CUDA),对国产AI算力意义重大。
局限性:
- 成本与功耗: 单卡功耗700瓦,与英伟达H20相当,商用领域成本优势不明显。
- 生态成熟度: 软件工具链(如编译器、调试器)仍需完善。
- 通用性: 专为AI设计,传统通用计算场景仍需依赖冯·诺依曼体系。
5. 未来趋势
- 场景分化:
- 冯·诺依曼体系继续主导通用计算。
- 全对等架构(或类似创新)成为AI、高性能计算领域的专用架构。
- 融合发展:
- 通过缓存优化、近存计算等技术缓解冯·诺依曼体系的瓶颈。
- 吸收全对等架构的对等互联思想,推动架构融合。

三、总结
全对等架构是冯·诺依曼体系在AI时代的演进,而非终结。它标志着计算架构从“通用”向“专用”的深化,但传统体系的基础设计思想仍将持续影响计算机科学发展。未来,两者将共同推动计算技术的进步,适应不同场景的需求。
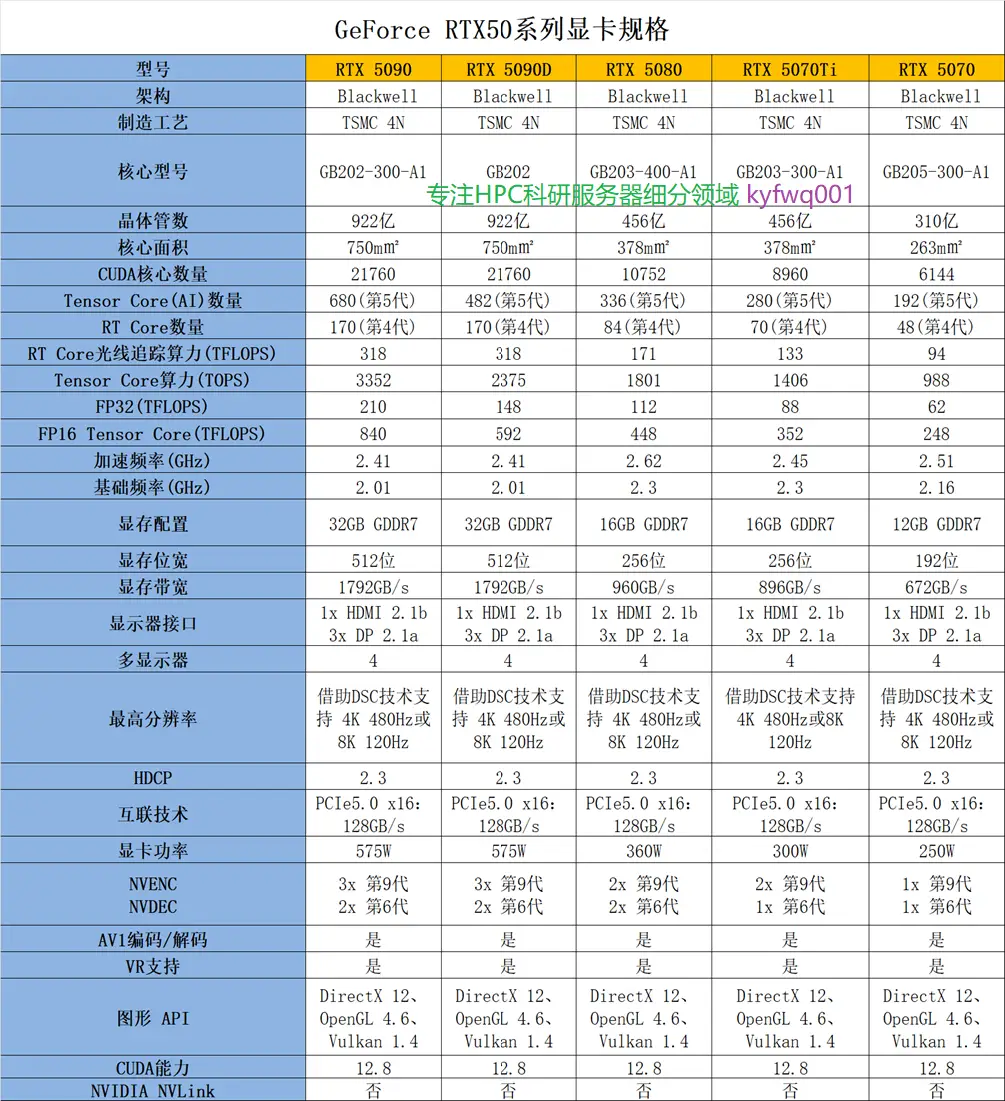
附1:NVIDIA GeForce RTX 5090系列参数图
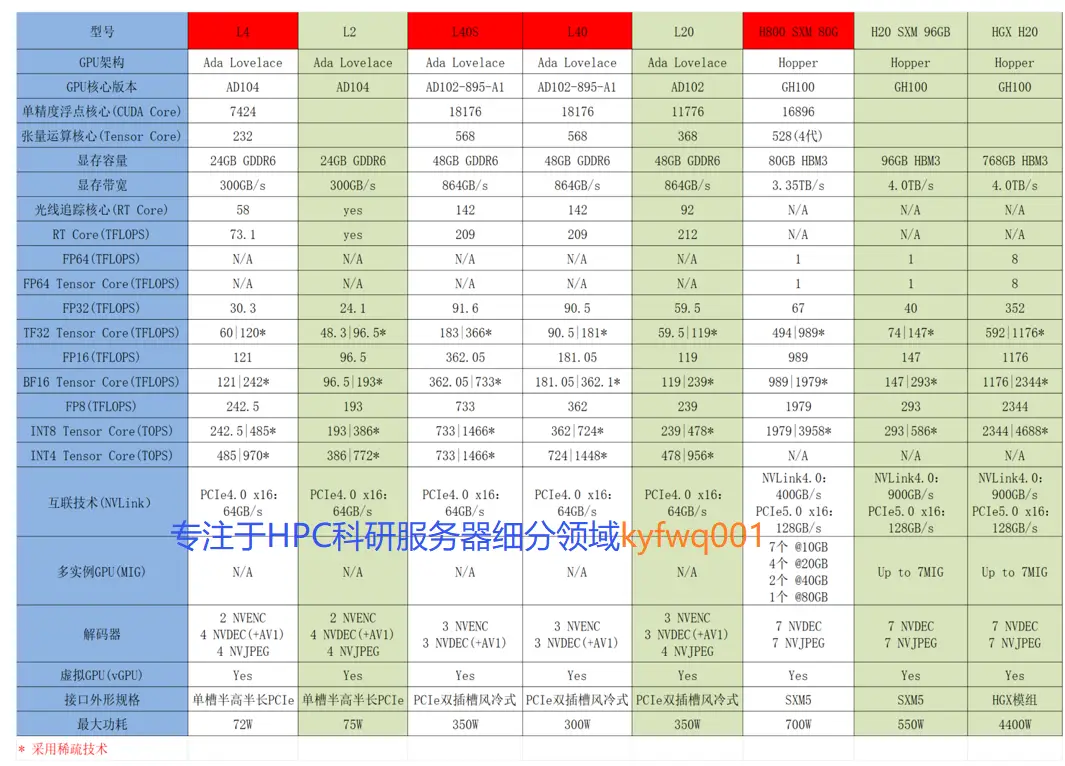
附2:NVIDIA L (L2、L4、L20、L40、L40S)系列参数图
附3:NVIDIA Tesla (A800、H800、H100、H200)系列参数图
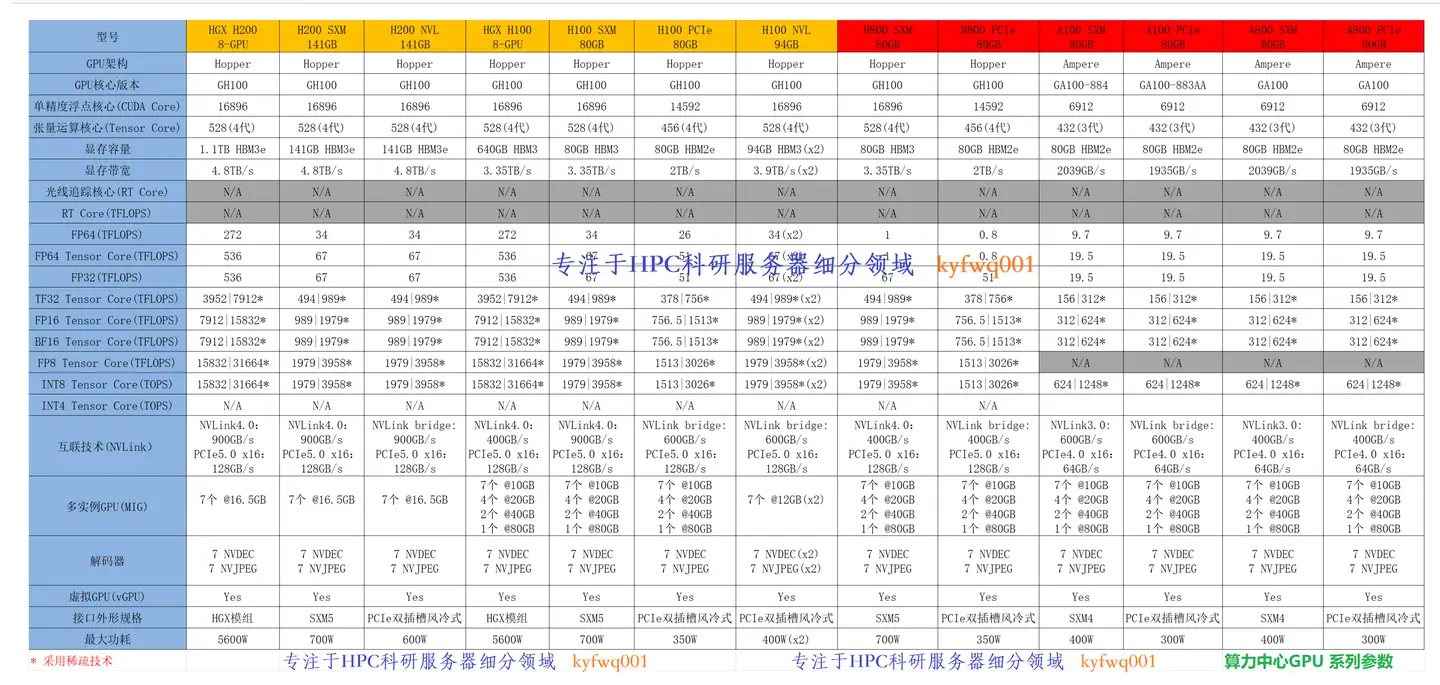
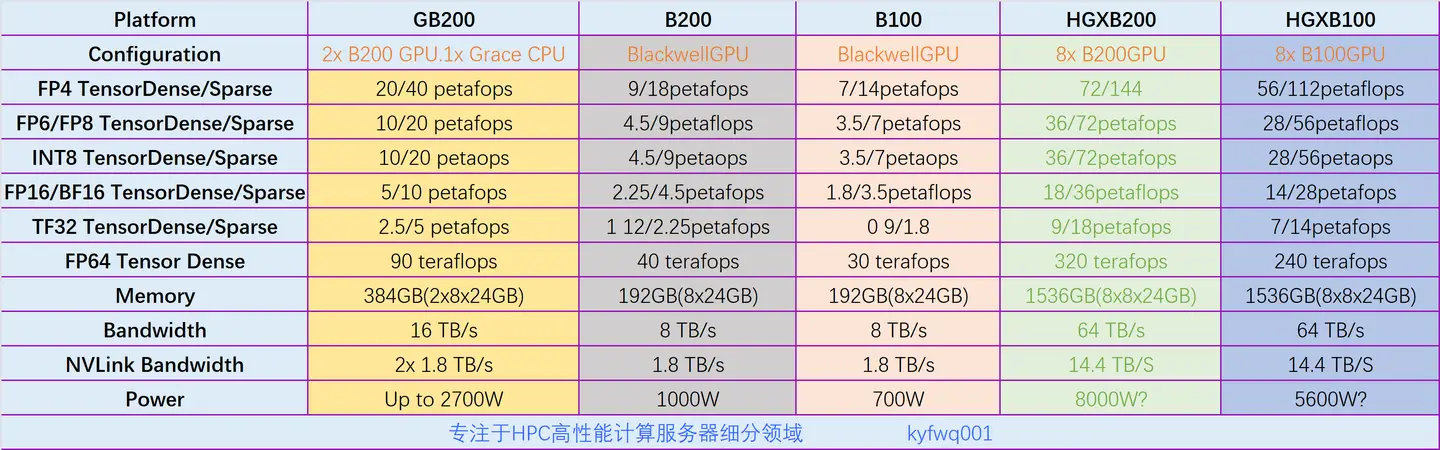
附4:NVIDIA B(B100、B200、GB200)系列参数图


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)