WhisperX 性能测试:为什么默认参数不一定是最优选择?
摘要: WhisperX作为AI语音识别工具在使用默认参数时可能并非最优解。测试发现,在3060ti 6G显存的GPU上,small模型+float32配置(17.94秒)比默认的small+float16(24.69秒)更快,甚至优于large-v3模型的所有配置。这一反常现象源于硬件对float32的优化、显存管理策略及WhisperX内部处理机制的差异。建议开发者针对自身硬件进行性能测试,平
前言
在 AI 语音识别领域,WhisperX 作为 OpenAI Whisper 的优化版本,以其出色的性能和准确度备受开发者青睐。然而,在实际使用中,我们往往习惯性地使用默认参数,却很少思考这些参数是否真的适合我们的硬件环境。
今天,我通过一次详细的性能测试,发现了一个有趣的现象:WhisperX 的默认参数并不总是最优选择。
测试环境与方法
测试配置
- 测试视频: test.mp4(标准测试样本)
- 硬件环境: Windows 系统,CUDA 支持的 GPU(3060ti 6G 显存)
- 测试模型: small、large-v3
- 精度设置: float16、float32
测试代码核心逻辑
def test_performance():
configs = [
("small", "float16", "small_16"),
("small", "float32", "small_32"),
("large-v3", "float16", "large-v3_16"),
("large-v3", "float32", "large-v3_32")
]
for model, compute_type, output in configs:
time_taken = transcribe_simple(
video_file,
whisper_name=model,
compute_type=compute_type,
output=output
)
震撼的测试结果
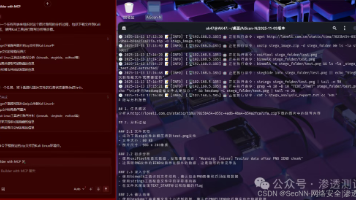
测试结果截图:
经过完整的性能测试,结果让人大跌眼镜:
| 配置 | 处理时间 | 相对性能 |
|---|---|---|
| small + float32 | 17.94 秒 | 1.0x (最快) |
| small + float16 | 24.69 秒 | 1.4x |
| large-v3 + float16 | 31.09 秒 | 1.7x |
| large-v3 + float32 | 153.68 秒 | 8.6x |
颠覆认知的发现
🤔 为什么 float32 比 float16 更快?
这个结果完全颠覆了我们的常规认知。按理说:
- float16 占用内存更少,应该更快
- WhisperX 默认使用 float16,说明官方认为它是最优选择
但现实却告诉我们:
- 硬件适配性:不是所有 GPU 都对 float16 有良好优化
- 转换开销:某些硬件上,float16 需要额外的类型转换
- 计算单元利用率:float32 可能更好地利用了 GPU 的原生计算能力
📊 small 模型的意外表现
更令人惊讶的是,small 模型 + float32 不仅比同模型的 float16 快,甚至比 large-v3 模型的所有配置都要快得多。
这说明:
- 模型大小对性能的影响是非线性的
- 精度选择比模型选择更关键(在某些硬件上)
- 实际应用中,small 模型可能是更明智的选择
深度分析:为什么会这样?
1. 硬件架构的影响
不同的 GPU 架构对浮点精度有不同的优化:
- 游戏卡:通常为 float32 优化
- 专业卡:可能对 float16 有更好支持
- 较老的 GPU:float16 支持可能不完善
2. 内存管理策略
large-v3 + float32 = 153.68秒(8.6x慢)
这个极端的性能下降暗示:
- 可能触发了显存不足
- 导致内存交换或CPU 回退
- 系统资源争抢加剧
3. WhisperX 的内部优化
WhisperX 在不同精度下的行为可能不同:
- 某些操作在 float16 下会回退到 float32
- 批处理策略可能因精度而异
- 内存分配模式影响整体性能
实战建议
🎯 最佳实践
基于测试结果,我的建议是:
-
不要盲信默认参数
# 不要这样 model = whisperx.load_model("small") # 使用默认float16 # 建议这样 model = whisperx.load_model("small", compute_type="float32") -
针对硬件进行测试
- 每个硬件环境都应该做性能测试
- 不同的 GPU 可能有完全不同的最优配置
-
平衡速度与准确度
- 对于实时应用:优先选择
small + float32 - 对于高精度需求:可以考虑
large-v3 + float16
- 对于实时应用:优先选择
🔧 测试你的环境
想知道你的硬件最优配置?运行这个简单的测试:
def benchmark_whisperx():
configs = [
("small", "float16"),
("small", "float32"),
("large-v3", "float16"),
("large-v3", "float32")
]
results = []
for model, compute_type in configs:
start_time = time.time()
# 你的转录代码
end_time = time.time()
results.append((model, compute_type, end_time - start_time))
return results
写在最后
这次测试让我深刻认识到:在 AI 应用中,经验主义往往不如实证主义。
- 默认参数是为了通用性,不是为了你的特定硬件
- 理论最优和实际最优可能完全不同
- 性能测试应该成为每个 AI 项目的标准流程
下次当你使用任何 AI 模型时,不妨花几分钟测试一下不同的参数配置。也许你会发现,最适合你的配置就藏在那些"非主流"的参数组合中。
你的硬件环境下,哪个配置最快?欢迎在评论区分享你的测试结果!
相关资源
本文基于真实性能测试,结果仅供参考。不同硬件环境可能有不同表现。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)