即插即用涨点系列 (九):TBSN 详解!AAAI 2025 SOTA,重构 Transformer 注意力,G-CSA 与 M-WSA 适配 BSN 的涨点新范式
提出了一种名为 TBSN(Transformer-Based Blind-Spot Network)的新型自监督图像去噪网络。其核心思想是系统性地分析并重新设计 Transformer 中的自注意力机制,使其在满足“盲点(Blind-Spot)”约束的前提下运行
🔥 AI 即插即用 | 你的CV涨点模块“军火库”已开源!🔥
大家好!为了方便大家在CV科研和项目中高效涨点,我创建并维护了一个即插即用模块的GitHub代码仓库。
仓库里不仅有:
- 核心模块即插即用代码
- 论文精读总结
- 架构图深度解析
- 全文逐句翻译与应用实例
更有海量SOTA模型的创新模块汇总,致力于打造一个“AI即插即用”的百宝箱,方便大家快速实验、组合创新!
🚀 GitHub 仓库链接:https://github.com/AITricks/AITricks
觉得有帮助的话,欢迎大家 Star, Fork, PR 一键三连,共同维护!
即插即用涨点系列 (九):TBSN 详解!AAAI 2025 SOTA,重构 Transformer 注意力,G-CSA 与 M-WSA 适配 BSN 的涨点新范式。
论文原文 (Paper):https://arxiv.org/abs/2404.07846
官方代码 (Code):https://github.com/nagejacob/TBSN
论文精读:TBSNNet
1. 核心思想
本文提出了一种名为 TBSN(Transformer-Based Blind-Spot Network)的新型自监督图像去噪网络。其核心思想是系统性地分析并重新设计 Transformer 中的自注意力机制,使其在满足“盲点(Blind-Spot)”约束的前提下运行,从而解决传统卷积盲点网络(BSN)感受野受限的问题。为此,本文设计了两种创新的注意力模块:1)“带掩码的窗口自注意力”(M-WSA),通过精巧的固定掩码来模拟空洞卷积的感受野,以实现动态的局部拟合;2) “分组通道自注意力”(G-CSA),用于防止在多尺度架构中因特征下采样而导致的空间信息泄露。最后,本文还提出了一种知识蒸馏策略(TBSN2UNet),将复杂的 TBSN 压缩为一个高效的 U-Net,在保持高性能的同时大幅提升了推理效率。
2. 背景与动机
-
背景与动机总结:
- 现有方法的局限性:自监督图像去噪(SSID)领域的主流方法是盲点网络(BSN),它通过网络结构设计(如空洞卷积)来确保输出像素的感受野中“跳过”对应的输入像素,从而避免模型学到“恒等映射”而直接过拟合到噪声上。然而,现有的 BSN 大多基于卷积(CNN)实现,但卷积(CNN)在捕获长程依赖和根据内容动态调整(内容自适应性)方面存在天然局限。
- 引入 Transformer 的挑战:Transformer 在其他图像恢复任务中已展现出超越 CNN 的强大能力(得益于其动态注意力和全局依赖建模)。但其核心的“自注意力机制”会访问感受野中的所有像素,这天然地违反了 BSN 的盲点约束。
- 现有尝试的不足:虽然有少数工作(如 LG-BPN, SwinIA)尝试将 Transformer 引入 BSN,但它们要么存在信息泄露的风险(如 LG-BPN 的通道注意),要么为了满足盲点约束而限制了 Transformer 只能在浅层特征上使用(如 SwinIA),未能充分发挥其能力。
- 本文动机:因此,本文的动机是系统性地分析和重新设计 Transformer 的空间和通道注意力机制,使之能安全、高效地嵌入多尺度 BSN 架构,以解决传统 BSN 感受野受限、缺乏全局上下文和动态性的核心问题。
-
动机图解分析 (Figure 1):
- 图表解读:Figure 1 可视化了四种不同 BSN 的“有效感受野”(ERF),即输入中的哪些像素对输出的中心点贡献最大。
- 看图说话:
- (a) AP-BSN, (b) LG-BPN, © PUCA:这三个代表了现有的 BSN 方法。我们可以清晰地看到,它们的有效感受野都非常局部化,激活区域(亮斑)紧密地集中在中心点周围一个很小的范围内,缺乏对图像全局信息的感知能力。
- (d) TBSN (Ours):相比之下,本文提出的 TBSN 展现出了显著扩大的有效感受野。其激活模式呈现出两种特性:1)中心区域更强、更集中的“局部拟合”能力;2)遍布整个特征图的、更广泛的“全局透视”能力。
- 引出的核心问题:这组对比图直观地暴露了现有 BSN 架构的核心局限性:感受野受限。这种局限性使得模型难以利用全局上下文信息来辅助去噪(例如判断大面积平坦区域的颜色)或恢复复杂纹理。本文需要解决的核心问题就是:如何在严格遵守 BSN 盲点约束的前提下,将 Transformer 强大的全局信息聚合能力和动态局部拟合能力引入网络,以实现如图 (d) 所示的“局部拟合与全局透视”兼备的去噪能力?
3. 主要贡献点
-
[贡献点 1]:提出了一种专为 BSN 重新设计的 Transformer 架构 (TBSN)
- 本文提出了 TBSN,一个基于 Transformer 的盲点网络。与以往的尝试不同,它不是简单地插入 Transformer 块,而是从根本上分析了注意力机制与盲点约束的冲突,并重新设计了注意力模块,使其在 BSN 框架内安全运行,实现了 SOTA 性能。
-
[贡献点 2]:提出了分组通道自注意力 (G-CSA) 以解决信息泄露
- 本文首次发现:在多尺度 BSN 架构中(使用 Pixel-Shuffle 进行下采样时),标准的通道注意力(Channel Attention)会泄露盲点信息。这是因为下采样将空间信息“折叠”到了通道维度,当通道数 C C C 超过空间分辨率 H × W H \times W H×W 时,通道间的交互就等同于“违规”的空间交互。
- 解决方案:G-CSA 通过将通道分成 G G G 组,在每组内部(维度 C / G C/G C/G)分别计算通道注意力。通过控制每组的通道数 C / G C/G C/G 始终小于 H × W H \times W H×W,G-CSA 阻止了这种信息泄露,从而安全地引入了全局通道上下文。
-
[贡献点 3]:提出了带掩码的窗口自注意力 (M-WSA) 以模拟空洞卷积
- 为了在 BSN 中实现空间注意力,本文设计了 M-WSA。其核心是在计算注意力矩阵时,叠加一个固定的、精心设计的掩码。
- 差异:这个掩码的作用是强制使每个 Query 像素只能关注到 Key/Value 中相对坐标为“偶数”的像素,这在功能上完美地“模拟”了空洞卷积(Dilated Convolution)的采样行为,从而自然地满足了盲点约束。与 SwinIA 只能使用浅层特征不同,M-WSA 可以灵活地在网络的任意深层特征上使用,同时(与静态的卷积核不同)它保留了 Transformer 的动态内容自适应能力。
-
[贡献点 4]:提出了知识蒸馏策略 (TBSN2UNet) 以实现高效推理
- 认识到 TBSN 作为 SOTA 模型计算量偏大,本文利用其强大的去噪能力作为“教师”(Teacher),将其输出的“伪真值”结果(pseudo ground-truths)作为监督信号。
- 用这些信号去训练一个标准、轻量级的 U-Net(Student)。最终得到的 TBSN2UNet 在计算量(参数量、FLOPs、推理时间)与 SASL 等轻量级网络相当的情况下,取得了远超后者的性能,证明了该策略在模型压缩和加速上的有效性。
4. 方法细节
-
整体网络架构 (Figure 2(a))
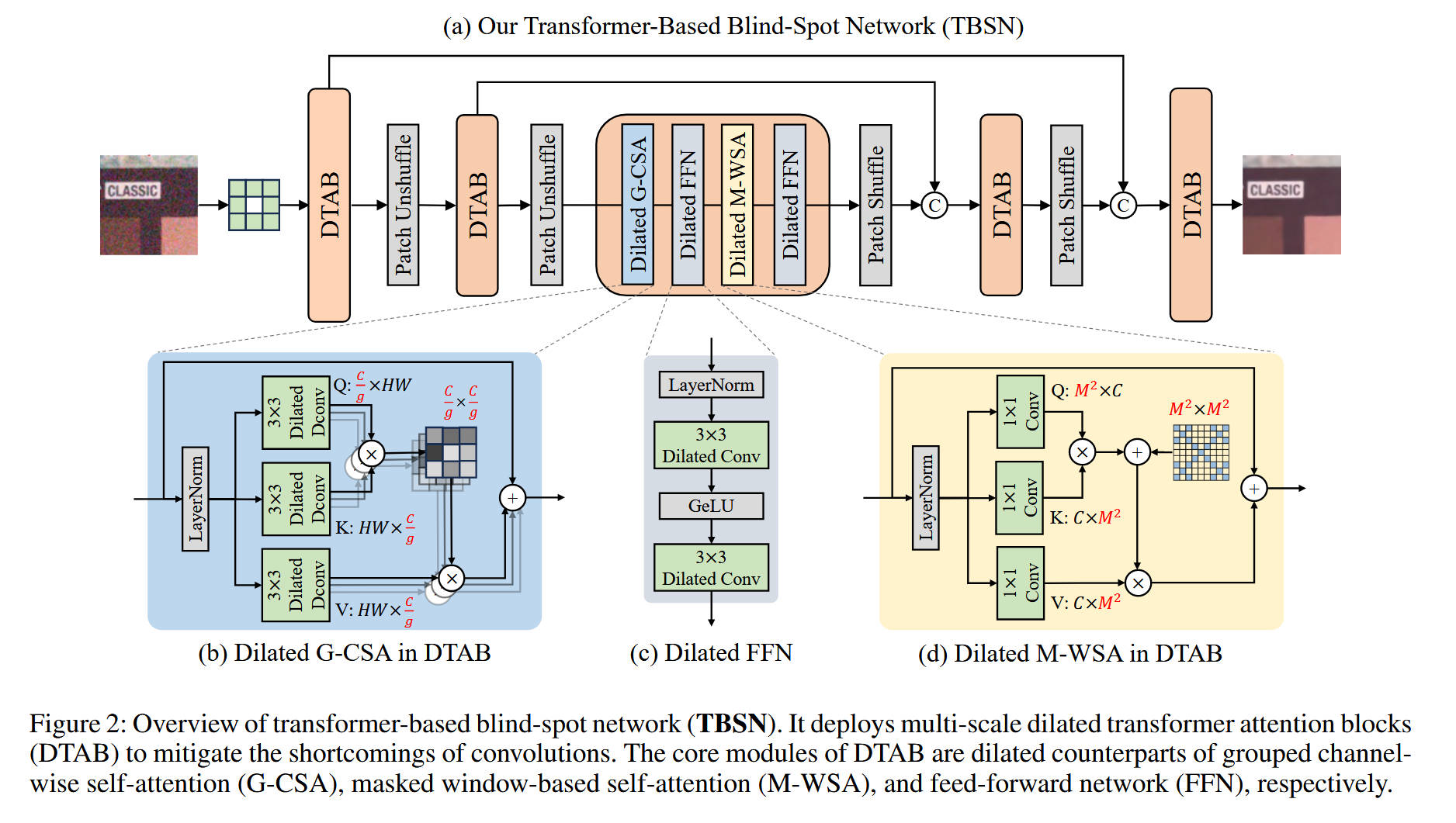
- TBSN 整体上是一个采用编码器-解码器结构的 U-Net 架构,并严格遵循 BSN 的设计规范。
- 数据流:
- 输入 (Input):带噪图像 “CLASSIC” 输入。
- 第一层:首先通过一个 3 × 3 3 \times 3 3×3 的“中心遮蔽卷积”(centrally masked convolution),这是 BSN 的标准操作,用于在网络入口处建立盲点。
- 编码器 (Encoder):数据流经第一个
DTAB(空洞 Transformer 注意力块)进行特征提取。随后,使用Patch Unshuffle操作进行下采样。Patch Unshuffle是一种无损下采样,它将 H × W × C H \times W \times C H×W×C 的特征图重塑为 H 2 × W 2 × 4 C \frac{H}{2} \times \frac{W}{2} \times 4C 2H×2W×4C,即将空间信息“折叠”到通道维度,此操作可完美保持盲点特性。此过程(DTAB -> Patch Unshuffle)在编码器中重复多次。 - 瓶颈层 (Bottleneck):在 U-Net 的最深处,数据流经一系列
DTAB模块。根据 Figure 2(a) 的放大图,这个核心序列由Dilated G-CSA、Dilated FFN、Dilated M-WSA和Dilated FFN串联组成。 - 解码器 (Decoder):数据开始上采样,使用
Patch Shuffle操作(Patch Unshuffle的逆操作,将通道信息“展开”回空间维度)。来自编码器对应层级的特征通过跳跃连接(Skip Connection,图中的C箭头)进行拼接(Concat)。拼接后的特征再送入DTAB模块进行特征融合与上采样。 - 输出 (Output):经过最后一级
DTAB和一个最终的卷积层,网络输出去噪后的图像 “CLASSIC”。
-
核心创新模块详解
-
对于 模块 (b) Dilated G-CSA (分组通道自注意力):
- 设计目的:在多尺度 BSN 中安全地引入“全局通道上下文”,同时防止空间信息泄露。
- 内部结构:如图 (b) 所示,输入特征首先通过
LayerNorm。然后,它并分三路,分别通过 3 × 3 3 \times 3 3×3 的空洞反卷积(Dilated Deconv)生成Q(Query)、K(Key) 和V(Value)。 - 工作机制:它计算的是通道间的注意力(类似于 Restormer 的 MDTA)。其核心在于,它将通道分成 G G G 组(如 Fig 4(b) 所示),在每组内部(维度 C / G C/G C/G)分别计算通道注意力。通过控制每组的通道数 C / G C/G C/G 始终小于空间分辨率,G-CSA 避免了空间信息通过通道交互而泄露。计算出的注意力图与
V相乘,最后通过残差连接(Add)加回到原始输入上。
-
对于 模块 (d) Dilated M-WSA (带掩码的窗口自注意力):
- 设计目的:在 BSN 中实现“动态的局部空间注意力”,以替代静态的空洞卷积,同时严格满足盲点约束。
- 内部结构:如图 (d) 所示,输入特征通过
LayerNorm,然后并分三路,通过 1 × 1 1 \times 1 1×1 卷积生成Q、K、V。 - 工作机制:这是在 M × M M \times M M×M 的局部窗口内计算的。核心创新在于 Q Q Q 和 K K K 相乘(矩阵乘法)后,会加上一个固定的掩码矩阵( M 2 × M 2 M^2 \times M^2 M2×M2,即图 (d) 中带格子的矩阵)。
- 掩码原理 (Fig 3):这个掩码的设计是关键。如 Figure 3(b) 所示,它会强制将注意力矩阵中不符合“空洞卷积”采样规则的位置(即相对坐标非偶数的位置)设为 − ∞ -\infty −∞。这使得一个 Query 像素(如图 3(b) Q 中的蓝点)只能关注到 Key/Value 中坐标为“偶数”的像素(如图 3(b) K/V 中的蓝点)。这种设计巧妙地“模拟”了空洞卷积的感受野,自然满足了 BSN 的要求,但又具备了 Transformer 的动态注意力和内容自适应能力。
-
对于 模块 © Dilated FFN (空洞前馈网络):
- 设计目的:作为 Transformer 块中的标准 FFN,但必须满足 BSN 约束。
- 内部结构:这是一个标准的 FFN 结构(Conv -> GeLU -> Conv),但关键在于它使用了两个 3 × 3 3 \times 3 3×3 的空洞卷积(Dilated Conv)来代替普通卷积,从而在非线性变换时也能保持盲点特性。
-
-
理念与机制总结:
- G-CSA 的核心理念是“分组避免泄露”。它揭示了多尺度 BSN 中 C > H × W C > H \times W C>H×W 时的信息泄露风险,并提出了通过分组 G − CSA ( X ) = Concat ( CA ( X 1 ) , … , CA ( X G ) ) G-\text{CSA}(X) = \text{Concat}( \text{CA}(X_1), \dots, \text{CA}(X_G) ) G−CSA(X)=Concat(CA(X1),…,CA(XG)) 的方式,确保组内 C / G < H × W C/G < H \times W C/G<H×W,从而阻断泄露。
- M-WSA 的核心理念是“掩码模拟空洞”。它通过一个固定的掩码 M M M 来修改注意力矩阵: Attention ( Q , K , V ) = SoftMax ( Q K T / d + M ) V \text{Attention}(Q, K, V) = \text{SoftMax}(QK^T / \sqrt{d} + M)V Attention(Q,K,V)=SoftMax(QKT/d+M)V。其中 M ( i , j ) = 0 M(i, j) = 0 M(i,j)=0(允许关注)当且仅当 i i i 和 j j j 的相对坐标 ( x i − x j ) (x_i - x_j) (xi−xj) 和 ( y i − y j ) (y_i - y_j) (yi−yj) 均为偶数;否则 M ( i , j ) = − ∞ M(i, j) = -\infty M(i,j)=−∞(禁止关注)。这使得动态的窗口注意力完美地复现了空洞卷积的盲点特性。
-
图解总结:
- 在“动机图解”(Figure 1)中,我们看到了现有 BSN 的核心问题是有效感受野(ERF)受限。
- 本文的新颖设计(Figure 2, 3, 4)通过以下方式解决了这个问题:
- G-CSA (Fig 2b, 4b):它安全地引入了通道注意力的“全局交互”能力。这使得网络可以(在通道维度上)聚合来自整个特征图的上下文信息,这极大地扩展了模型的有效感受野,实现了 Figure 1(d) 中所示的“全局透视”能力。
- M-WSA (Fig 2d, 3b):它取代了“静态”的空洞卷积,提供了“动态”的、具有更强局部拟合能力的空间注意力。这使得模型能更自适应地处理局部纹理和噪声(即 Figure 1(d) 中更强的“局部拟合”)。
- 综上所述,G-CSA 提供了“全局”上下文,M-WSA 提供了“局部”自适应拟合,两者结合,使得 TBSN 能够在满足盲点约束的前提下,同时获得 Transformer 的全局依赖和局部动态拟合优势,从根本上解决了传统 BSN 感受野受限的问题。
5. 即插即用模块的作用
本文的创新点(G-CSA, M-WSA)具有很强的模块化特性,可以作为“即插即用”组件应用于其他 BSN 架构中:
-
M-WSA (带掩码的窗口自注意力)
- 适用场景:任何使用“空洞卷积”来满足盲点约束的 BSN 网络。
- 具体应用:它可以作为“即插即用”模块,直接替换 BSN 网络(如 AP-BSN 或其他基于 U-Net 的 BSN)中的 3 × 3 3 \times 3 3×3 空洞卷积层。这种替换可以将原有的“静态”卷积核升级为“动态”的、内容自适应的注意力窗口,从而在不违反盲点的前提下,显著增强模型的局部特征拟合能力。
-
G-CSA (分组通道自注意力)
- 适用场景:任何在多尺度 BSN 架构(特别是使用 Patch Unshuffle/Shuffle)中希望使用“通道注意力”的场景。
- 具体应用:可用于替换 LG-BPN 等方法中“朴素”的通道注意力模块。在网络的深层(即高通道数、低空间分辨率的特征图上),使用 G-CSA 可以有效防止空间信息的泄露,从而安全地为模型提供全局上下文。
-
TBSN2UNet (知识蒸馏策略)
- 适用场景:当一个自监督模型(Teacher)虽然效果好但计算量过大,不适用于实际部署(如移动端或边缘设备)时。
- 具体应用:作为一个模型压缩和加速流程。通过在自监督任务上训练一个强大的(但复杂的)TBSN 教师网络,然后用它的输出作为“伪标签”,去监督训练一个轻量级的 U-Net 学生网络。这使得学生网络能在极低的计算成本下(如 Table 2 所示,参数量和推理时间大幅降低),达到或接近教师网络的性能,非常适用于对推理速度有要求的实际应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)