机器学习学习笔记——02
假设一个模型,如果这个数据在训练集里存在过,那就输出它的真实值,如果没出现过,那就输出任意值。我们可以做三次(比如第一份做val,二三份做train),这样我们将模型带入就会得到三次结果,再将三个结果取平均,就得到了我们最终的结果。模拟得出Model就是我们通过训练集要做的事情,但是因为训练集太小从而导致模型想多了拟合出一个非常复杂的曲线,从而导致在测试集上的预测结果完全放飞。,也就是数据不够多时
训练Model
在之前已经熟悉了训练Model的方法。
1、定义一个包含未知数的Function:
2、定义一个Loss: 是一个Function,输入是一组参数,根据输出结果来判断这组参数效果好不好。
3、解决Optimization,通过微分得到一组参数 使Loss达到最小。
优化Model
当你觉得训练结果效果不好,我们可以通过这样一个流程来进行优化。
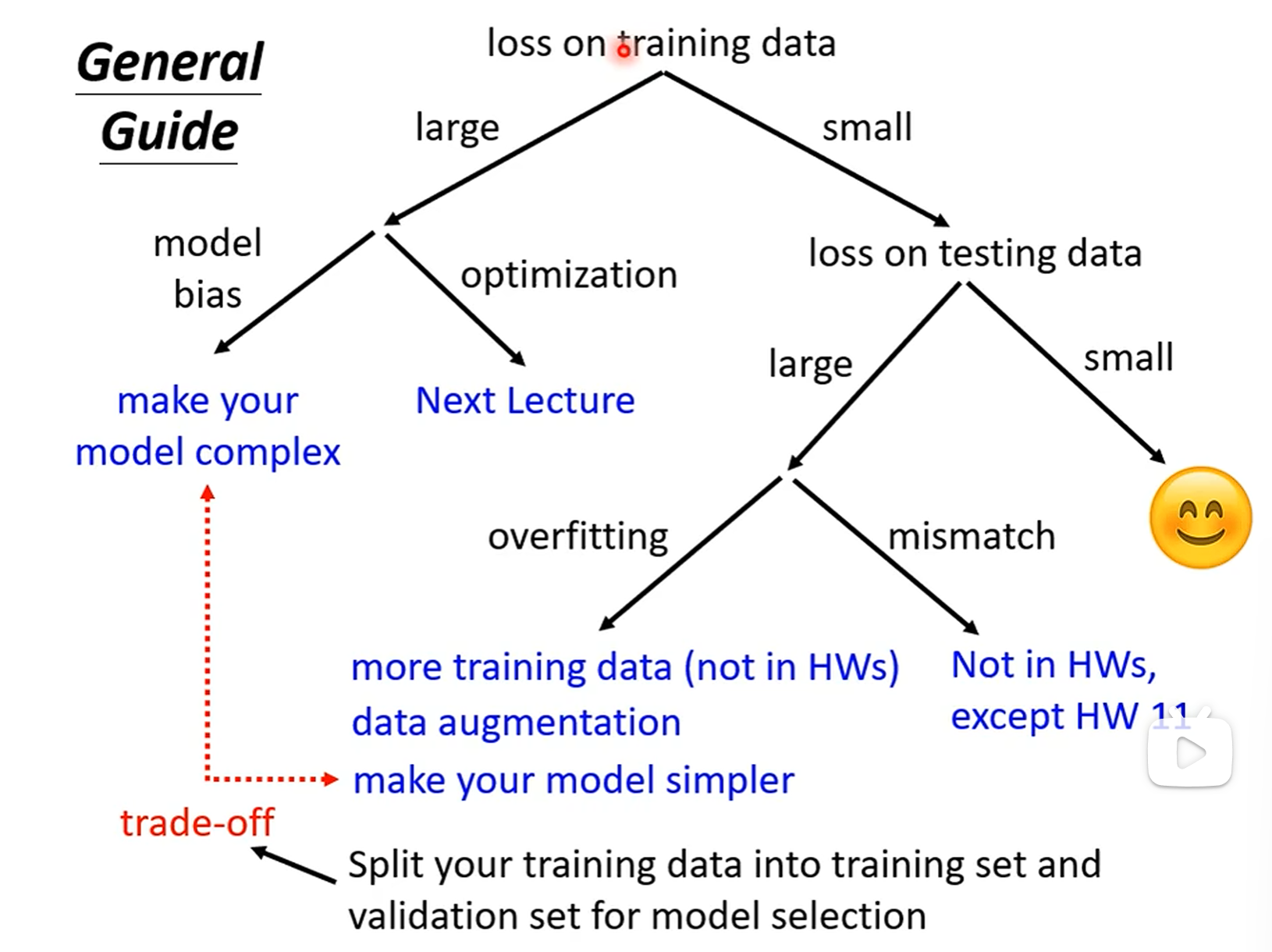
判断training data(训练集)的Loss
过大
1、Model Bias:Model is too simple.
通过增加Feature,或者Deep Learning的方式在重新设计模型,让模型更加灵活
2、Optimazation Issue:can't find the global minima
因为所选取的方法的问题无法找到更小的Loss
PS:那应该怎么确定Loss过大到底是那个因素导致的呢?
对于同一个模型在训练集上,Network层数越高,Loss越低。因为层数越高,模型灵活性越高,Loss一定不会比层数低的时候高。所以当高层的Network所得出的Loss比低层的高时,就可以判断是Optimization issue。
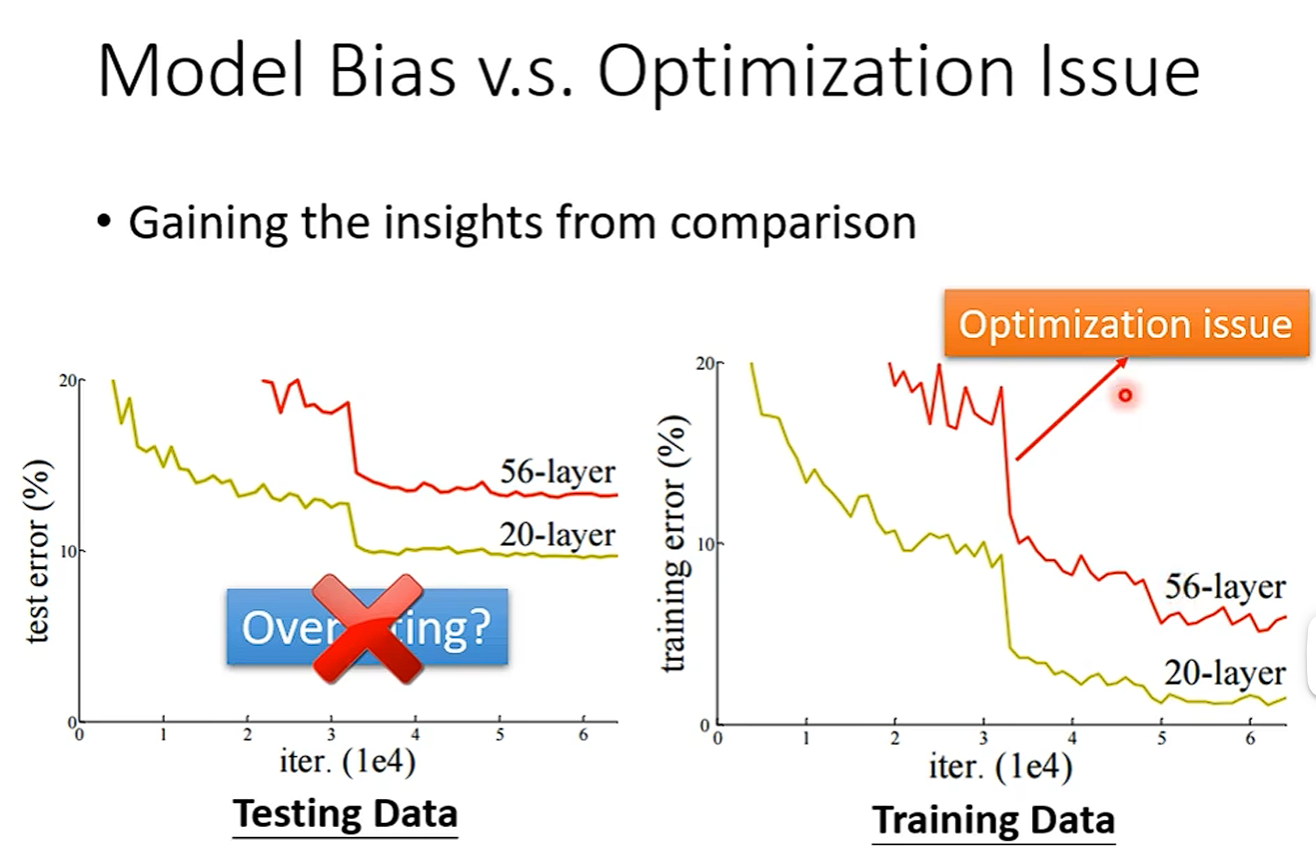
综上,当我们遇到一个没有见过的问题时,可以用一个比较浅的Network或者不是Deep Learning的方法来运行。这些方法不会出现Optimization issue。这样你就能得到一个目前最小的Loss,然后你再用更深的Network,如果发现在Training data上得到的Loss更高,那就是Optimization issue。
已经变小,进一步判断testing data的Loss
1、小
优化成功。
2、大
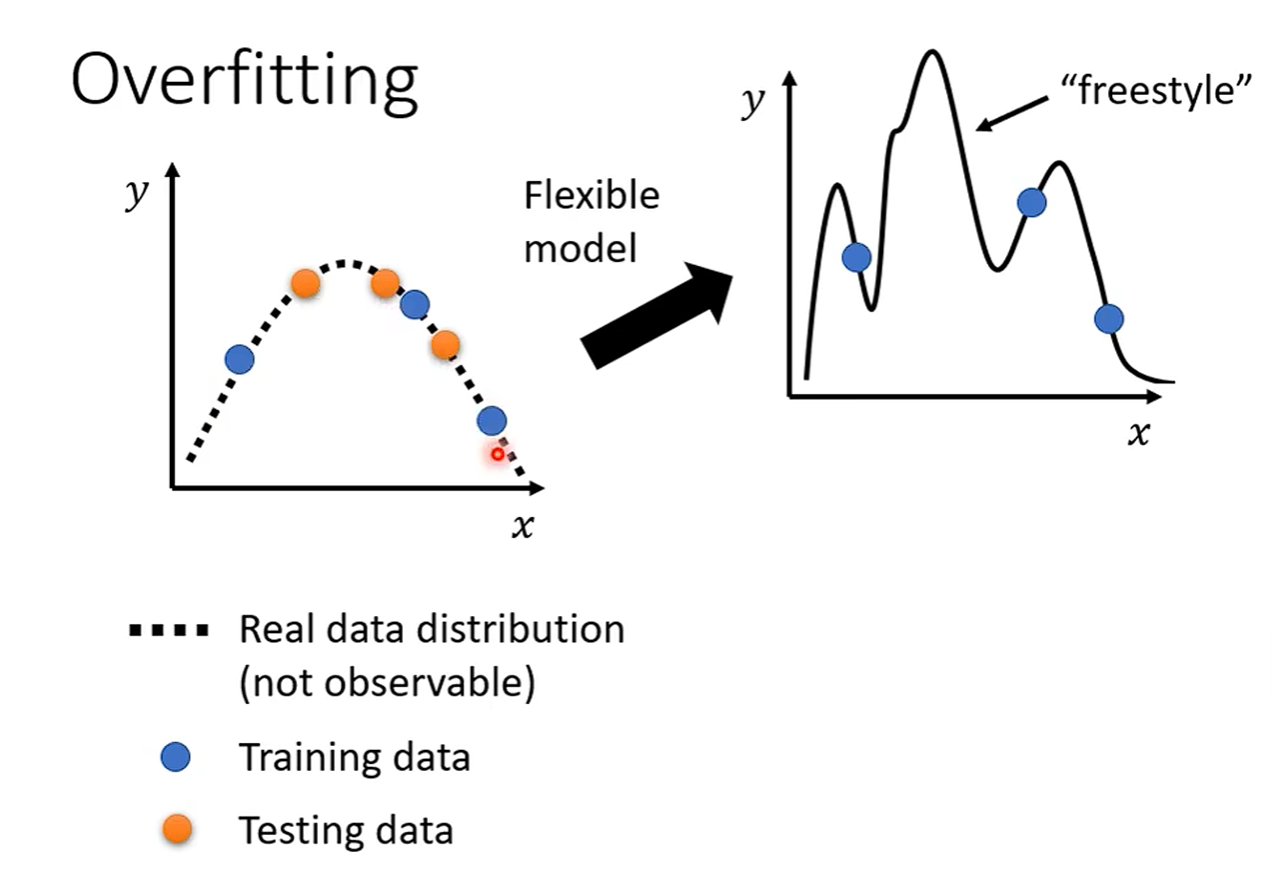
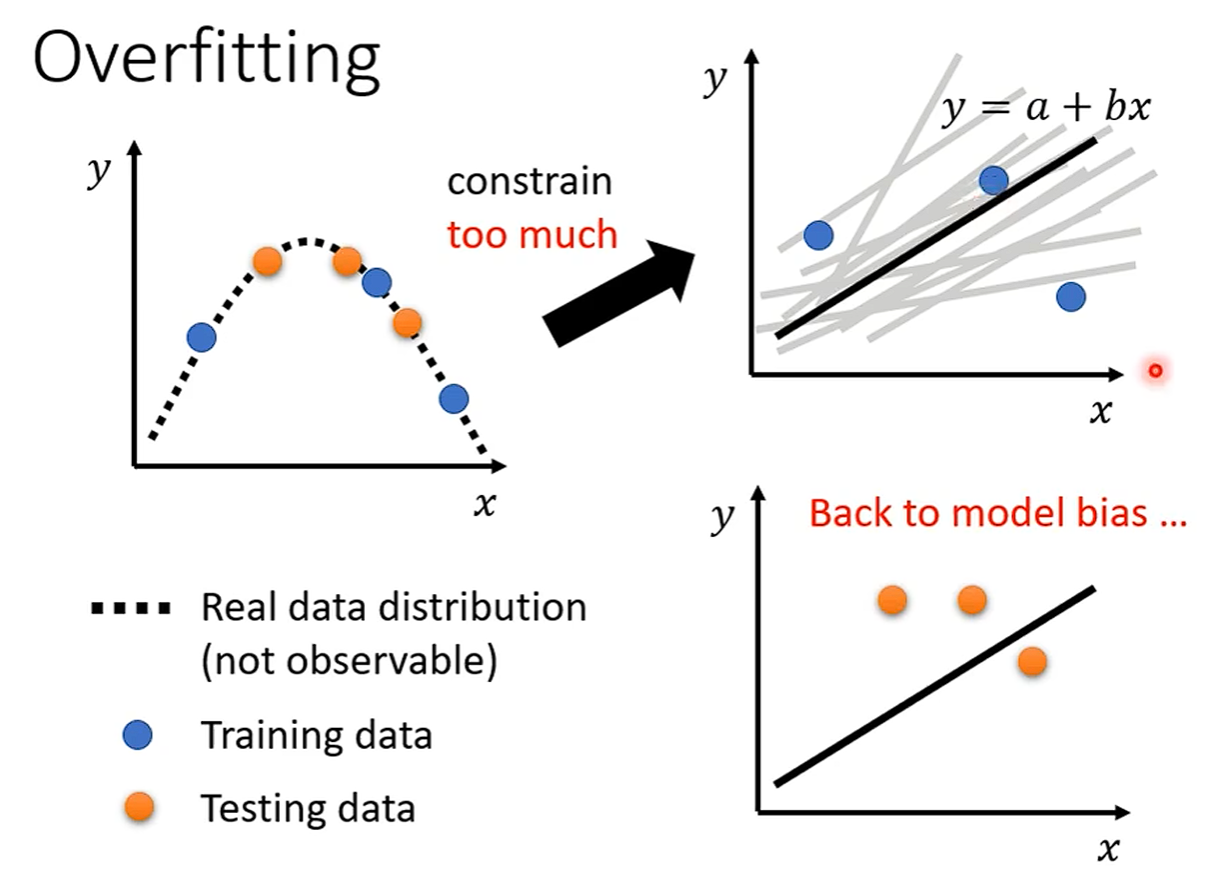
Overfitting
李老师举了一个通常情况的例子,我们知道虽然数据有一段曲线,但是我们作为训练集通常是从中去一些点来使用,那么如果我们的训练集不够大,也就是数据不够多时,带入一个非常灵活的模型,他只能知道这些训练集的值,但可能两个训练数据之间还有间隔,那么模型就会自由发挥假设出一个与真实数据完全不同的曲线,也就是模拟得出一个Model
注:模拟得出Model就是我们通过训练集要做的事情,但是因为训练集太小从而导致模型想多了拟合出一个非常复杂的曲线,从而导致在测试集上的预测结果完全放飞。
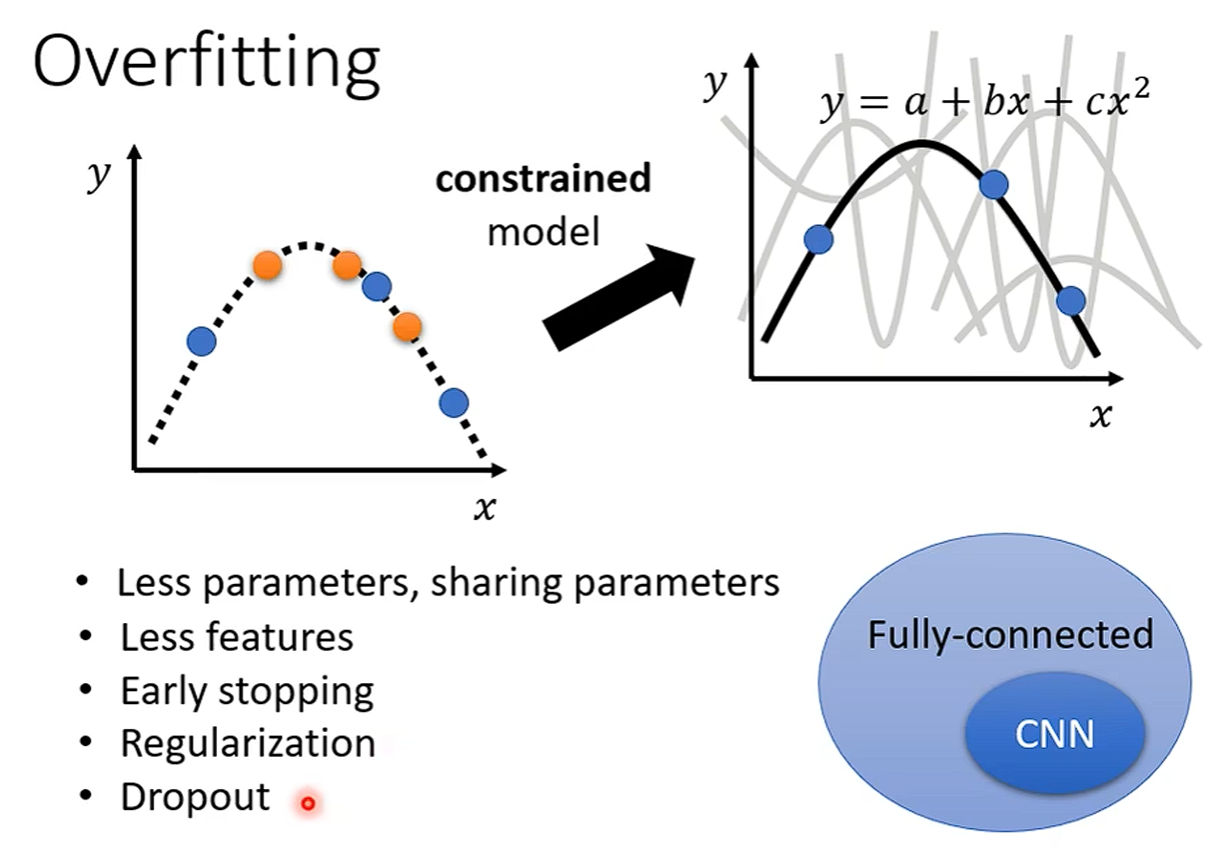
解决Overfitting:
1、最直接也是最好的当然就是增大训练集,
2、Data augmentation:合理增加训练集——白话就是造数据,比如图片数据左右翻转或者放大两倍
3、限制模型(Constrained Model)
训练集有限的情况下,对模型进行限制,可能能拟合出更好的结果。比如通过减少参数,减少特征等等。当然,如果对模型进行过多的限制就会导致没有结果能过通过所有训练集,从而导致Model Bias。
PS:既然复杂模型容易出现Over fitting,而简单模型又容易导致Model Bias,那怎么办?我们要怎么选择模型,有怎么用模型从而避免Over fitting?
很多朋友最直接的方法可能是,那直接把所有模型所得出的所有Function怼上去,找出那个结果最好的不就行了。这里就要举一个极端例子,假设一个模型,如果这个数据在训练集里存在过,那就输出它的真实值,如果没出现过,那就输出任意值。很明显这是一个没用的模型,因为他无法进行任何预测。但尽管如此在测试集的预测中,肯定也有一个效果相对好的Function。那这个Function是好的吗?我们当然知道即使它预测全对这个Function也是一个没用的垃圾= =。
与此同时还引申出另一个问题,这样一个没用的Model都能搞出一个预测全对的Function,要怎么防范这个问题呢?最直接的就是将测试集分为两份(Pubilc、Private)
既然不能全上那应该怎么选择出我们要的Model呢?
我们可以将训练集的数据也分成两份,一份作为原本的训练集,一份作为有效验证集(Validation Set)用训练集来确定参数,用Validation Set来计算Loss挑选Model。
这里又引申出一个问题我们要怎么划分Training Set 和Validation Set呢?
我们可以将原本的Training Set分为三等分,一份作为Validation Set 另外两份作为Training Set。那哪份做Val呢?我们可以做三次(比如第一份做val,二三份做train),这样我们将模型带入就会得到三次结果,再将三个结果取平均,就得到了我们最终的结果。
Mismatch
mismatch出现的原因与overfitting并不相同,mismatch意思是训练集与测试集分布并不相同。也就是出现了反常情况(没有规律)
注:文章所有内容均来自李宏毅老师的机器学习系列课程以及本人的一些理解看法,如理解错误是本人问题。还在学习,敬请谅解。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)