如何在conda虚拟环境下安装llama-cpp-python,推理gguf格式大模型【踩坑总结超简单上手】
本文详细介绍了如何安装llama-cpp-python的CPU和CUDA版本。CPU版本需先安装Anaconda、创建虚拟环境并安装依赖,然后从源码编译安装。CUDA版本建议直接下载预编译的whl文件安装,并提供了解决GLIBCXX_3.4.30库缺失问题的方法:通过配置conda环境变量加载系统库。最后展示了如何使用安装好的库加载GGUF格式大模型进行代码分析推理,包括初始化模型、显存监控和推理
如果是安装cuda版本的直接从第六点开始看,cpu版本的可以看前五点。
1、先安装anaconda,在创建conda虚拟环境。
2、安装相关依赖
conda install -c conda-forge cmake make gcc gxx_linux-64 -y
3、依赖安装完成后,从源码上安装llama-cpp-python
git clone --recursive https://github.com/abetlen/llama-cpp-python.git
4、进去看看vendor/llama.cpp 目录是否存在
cd llama-cpp-python
ls vendor/llama.cpp/CMakeLists.txt
如果为空,手动下载:
rm -rf vendor/llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git vendor/llama.cpp
5、安装:CPU版本
pip install -e . #这个命令默认是安装CPU版本
到这里安装CPU版本很简单,但是基本没啥用,我们都是用CUDA版本的。
6、CUDA版本:
这个是人家github的官方库:
GitHub - abetlen/llama-cpp-python:llama.cpp的 Python 绑定
可以看到这个库里面的这个命令: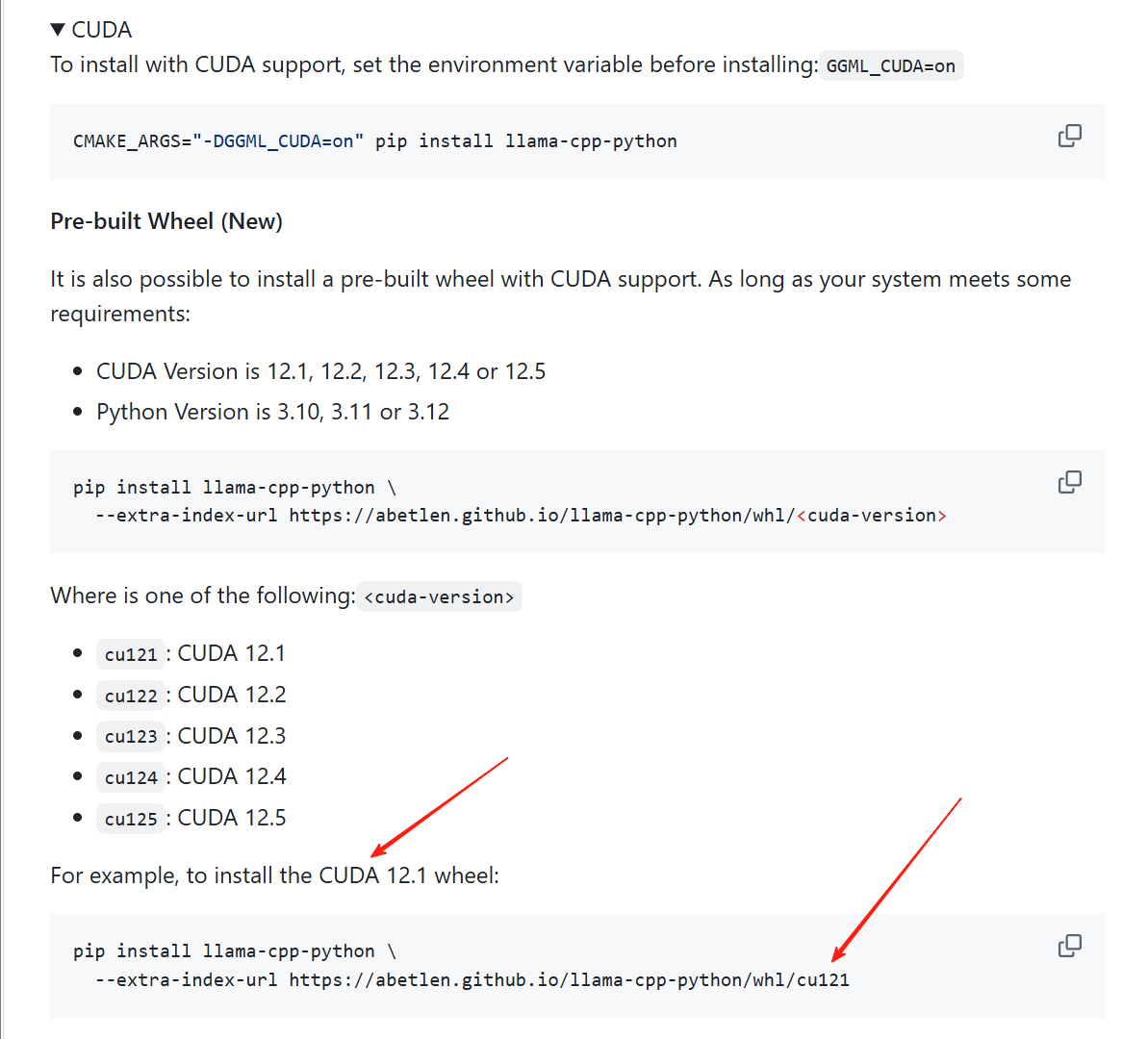
我们根据自己的CUDA版本,然后直接用这个命令安装:
pip install llama-cpp-python \ --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cu121
按理讲这样是可以安装成功的,但是大概率会出错,我就是一直安装失败,后来发现我们可以直接点击到这个链接:https://abetlen.github.io/llama-cpp-python/whl/cu121里去看,去找文件手动下载在安装。进去如下: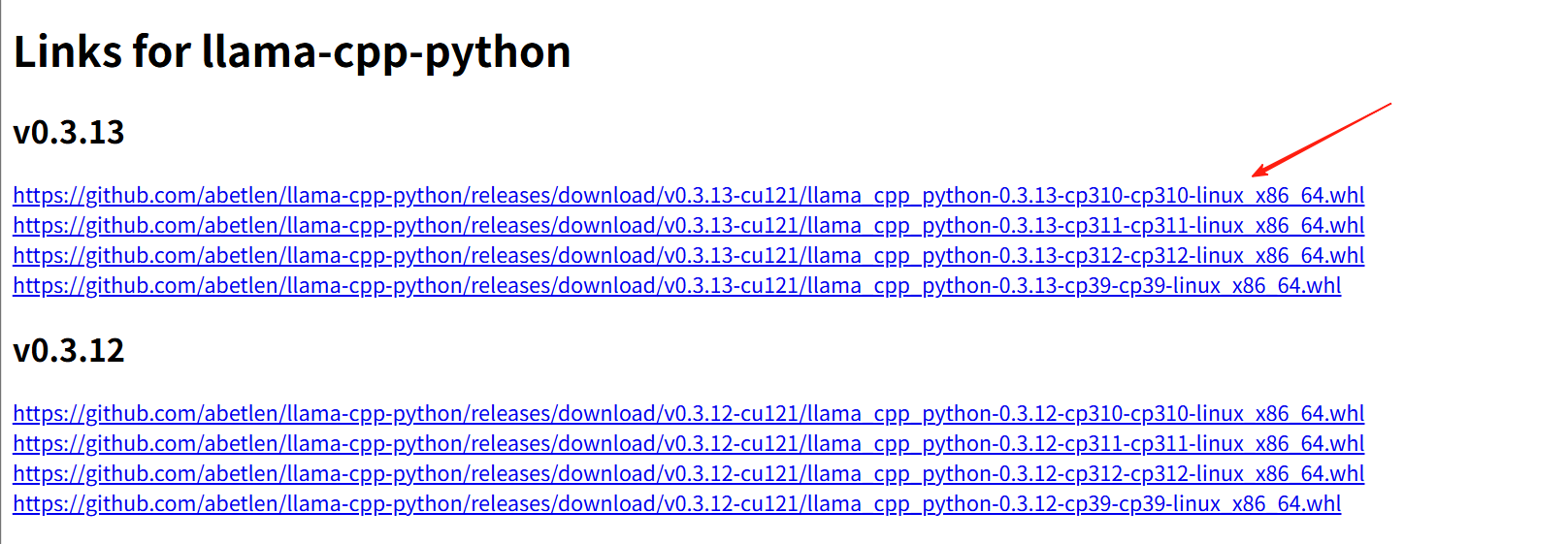
直接点击这个最新版本下载到本地,传到服务器上,然后在使用命令行去安装。
!!!注意:由于我的conda虚拟环境中的python版本是3.10,所以这里我安装的是cp310,如果你的版本是3.12,那就安装cp312.其他同理。
命令如下:(记得改路径)
pip install /home/liqianxi/llama_cpp_python-0.3.13-cp310-cp310-linux_x86_64.whl
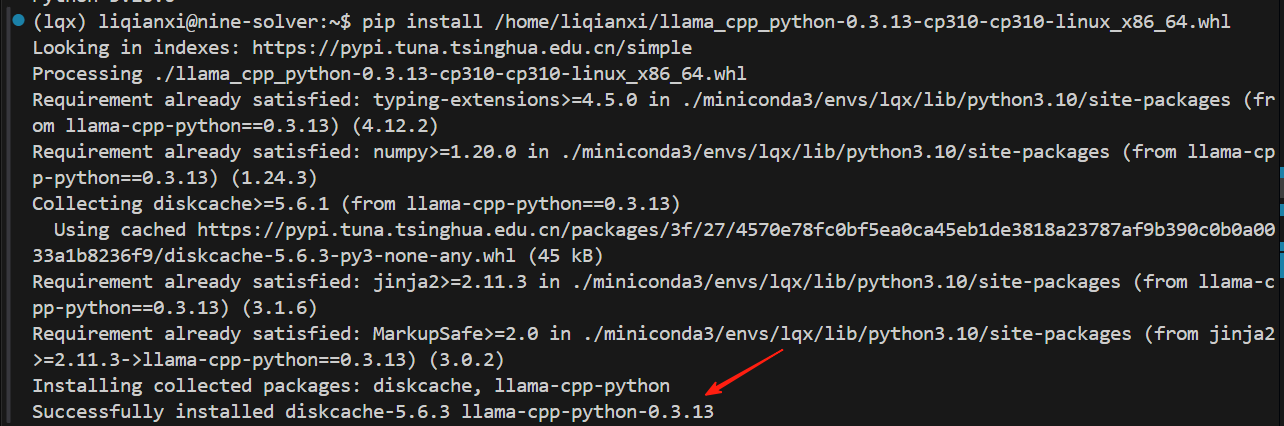
7、验证安装是否成功
python -c "import llama_cpp; print(llama_cpp.__version__)"
如果发现报错:
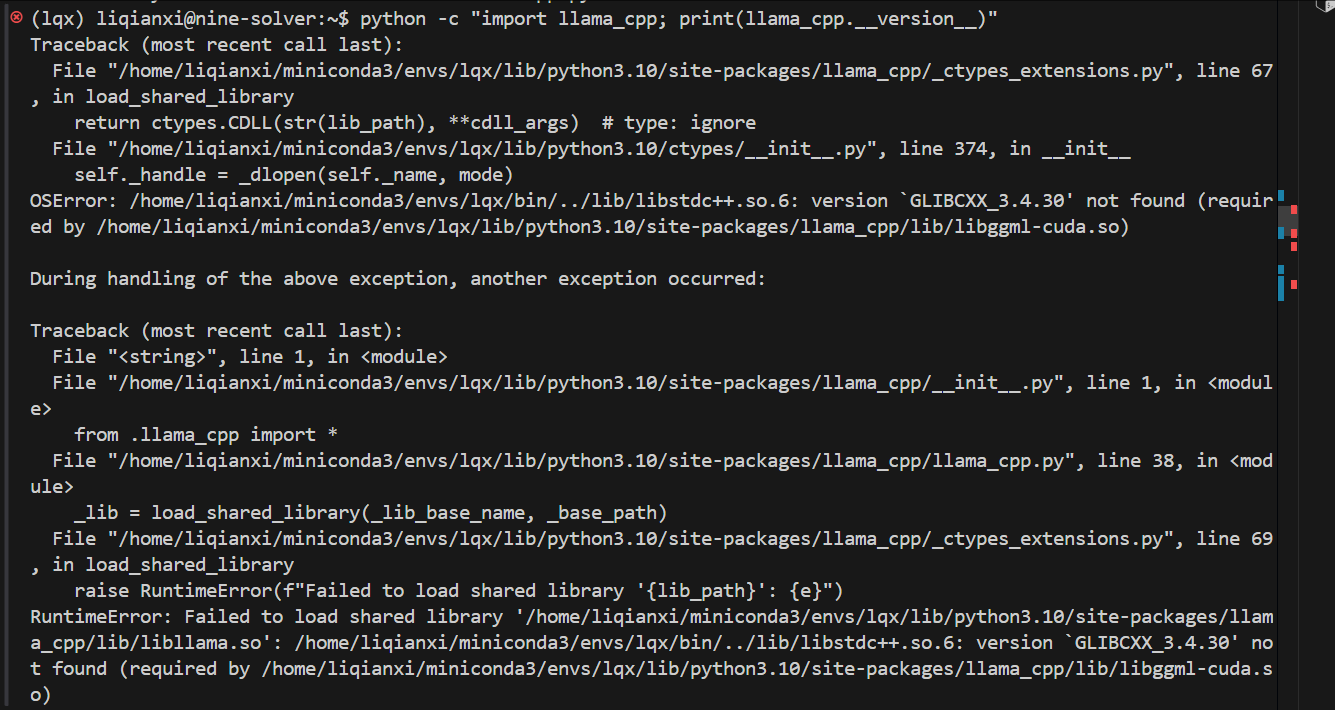
发现是 conda 环境中缺少GLIBCXX_3.4.30版本的库文件导致的,这是 llama-cpp-python 依赖的 CUDA 库所需要的。然后去检查一下:
strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep GLIBCXX_3.4.30
发现有这个库,那就是conda环境没用上,那就开始配置环境,进入 conda 环境的配置目录:
cd ~/miniconda3/envs/lqx/etc/conda/activate.d/创建一个激活环境时自动执行的脚本:
echo 'export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libstdc++.so.6' > set_ld_preload.sh
chmod +x set_ld_preload.sh同样在 deactivate.d 目录创建恢复脚本:
cd ~/miniconda3/envs/lqx/etc/conda/deactivate.d/
echo 'unset LD_PRELOAD' > unset_ld_preload.sh
chmod +x unset_ld_preload.sh重新激活环境即可永久生效:
conda deactivate
conda activate lqx
python -c "import llama_cpp; print(llama_cpp.__version__)"但如果没有这个目录就自己创建:
# 创建激活环境时的配置目录
mkdir -p ~/miniconda3/envs/lqx/etc/conda/activate.d/
# 创建激活时的脚本
echo 'export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libstdc++.so.6' > ~/miniconda3/envs/lqx/etc/conda/activate.d/set_ld_preload.sh
# 赋予执行权限
chmod +x ~/miniconda3/envs/lqx/etc/conda/activate.d/set_ld_preload.sh
# 可选:创建退出环境时的恢复脚本
mkdir -p ~/miniconda3/envs/lqx/etc/conda/deactivate.d/
echo 'unset LD_PRELOAD' > ~/miniconda3/envs/lqx/etc/conda/deactivate.d/unset_ld_preload.sh
chmod +x ~/miniconda3/envs/lqx/etc/conda/deactivate.d/unset_ld_preload.sh执行完上述命令后,重新激活环境即可生效:
conda deactivate
conda activate lqx
python -c "import llama_cpp; print(llama_cpp.__version__)"最后成功安装:

8、最后将下载好的gguf格式的大模型进行推理测试:
代码如下:
# !pip install llama-cpp-python pynvml # 确保安装必要的库
from llama_cpp import Llama
import pynvml
import time
def get_gpu_memory_usage():
"""获取当前GPU显存占用(单位:MB)"""
pynvml.nvmlInit()
handle = pynvml.nvmlDeviceGetHandleByIndex(0) # 默认监控第一块GPU
info = pynvml.nvmlDeviceGetMemoryInfo(handle)
pynvml.nvmlShutdown()
return info.used // 1024 // 1024 # 转换为MB
# 初始化模型(全GPU推理)
llm = Llama(
model_path="./models/Qwen3-14B-UD-Q6_K_XL/Qwen3-14B-128K-UD-Q8_K_XL.gguf",
n_ctx=2048,
n_threads=8,
n_gpu_layers=-1, # 设为极大值强制全卸载到GPU [6,7](@ref)
verbose=True # 显示详细日志
)
def test_code_understanding(code_snippet):
# 记录推理前显存占用
start_mem = get_gpu_memory_usage()
start_time = time.time()
prompt = f"""请分析以下代码的功能,并解释其作用:
{code_snippet}
请逐步解释代码的逻辑:"""
response = llm.create_chat_completion(
messages=[
{"role": "system", "content": "你是一个专业的程序员助手,擅长分析和解释代码。"},
{"role": "user", "content": prompt}
],
temperature=0.6,
max_tokens=4096
)
# 记录推理后显存占用和耗时
end_mem = get_gpu_memory_usage()
end_time = time.time()
print(f"\n=== 资源使用报告 ===")
print(f"- 显存占用: {start_mem} MB → {end_mem} MB (增量: {end_mem - start_mem} MB)")
print(f"- 推理耗时: {end_time - start_time:.2f} 秒")
return response["choices"][0]["message"]["content"]
if __name__ == "__main__":
sample_code = """
void BRepExtrema_ExtPF::Initialize(const TopoDS_Face& TheFace,
const Extrema_ExtFlag TheFlag,
const Extrema_ExtAlgo TheAlgo)
{
// cette surface doit etre en champ. Extrema ne fait
// pas de copie et prend seulement un pointeur dessus.
mySurf.Initialize(TheFace, Standard_False);
if (mySurf.GetType() == GeomAbs_OtherSurface)
return; // protect against non-geometric type (e.g. triangulation)
Standard_Real Tol = Min(BRep_Tool::Tolerance(TheFace), Precision::Confusion());
Standard_Real aTolU, aTolV;
aTolU = Max(mySurf.UResolution(Tol), Precision::PConfusion());
aTolV = Max(mySurf.VResolution(Tol), Precision::PConfusion());
Standard_Real U1, U2, V1, V2;
BRepTools::UVBounds(TheFace, U1, U2, V1, V2);
myExtPS.SetFlag(TheFlag);
myExtPS.SetAlgo(TheAlgo);
myExtPS.Initialize(mySurf, U1, U2, V1, V2, aTolU, aTolV);
}
"""
print("=== 代码分析结果 ===")
analysis = test_code_understanding(sample_code)
print(analysis)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)