GenAI Processors:构建未来的实时AI应用程序
GenAI Processors是由 DeepMind 开发的全新开源Python库,旨在为开发挑战提供条理性和简单性。它们充当抽象机制,定义了一个通用的Processors接口,涵盖输入处理、预处理、实际模型调用,甚至输出处理。想象一下,GenAI Processors成为AI工作流程之间的通用语言。你无需为AI流水线中的每个组件从头编写自定义代码,只需使用易于组合、测试和维护的标准化的“Pro
GenAI Processors是由 DeepMind 开发的全新开源Python库,旨在为开发挑战提供条理性和简单性。它们充当抽象机制,定义了一个通用的Processors接口,涵盖输入处理、预处理、实际模型调用,甚至输出处理。

译者 | 布加迪
审校 | 重楼
想象一下,一个AI应用程序可以处理你的语音、分析摄像头视频,并进行如同人类的实时对话。就在不久前,为了创建这样一个技术密集型的多模态应用程序,工程师们还在努力应对复杂的异步操作、处理多个API调用以及拼凑代码,后来证明这些代码难以维护或调试。GenAI Processors应运而生。
谷歌DeepMind推出的这个革命性开源Python库为有志于AI应用程序的开发者开辟了新的道路。该库将混乱的AI开发环境转变为开发者的宁静环境。我们在本篇博文中将介绍GenAI Processors如何使复杂的AI工作流程更易于享用,从而帮助我们构建实时AI智能体。
GenAI Processors简介
GenAI Processors是由 DeepMind 开发的全新开源Python库,旨在为开发挑战提供条理性和简单性。它们充当抽象机制,定义了一个通用的Processors接口,涵盖输入处理、预处理、实际模型调用,甚至输出处理。
想象一下,GenAI Processors成为AI工作流程之间的通用语言。你无需为AI流水线中的每个组件从头编写自定义代码,只需使用易于组合、测试和维护的标准化的“Processors”单元。究其核心,GenAI Processors将所有输入和输出视为ProcessorParts(双向流)的异步流。标准化数据部分(比如音频块、文本转录、图像帧)与附带的元数据一起流经流水线。
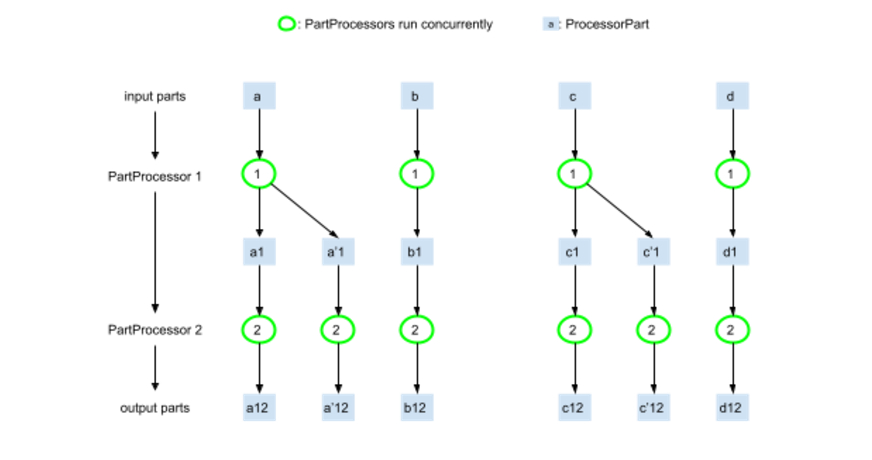
GenAI Processors的关键概念如下:
- Processors:接收输入流并生成输出流的独立工作单元。
- Processors部件:包含元数据的标准化数据块。
- 流传输:流经你管道的实时双向数据。
- 组合:使用简单的操作(比如 +)组合Processors。
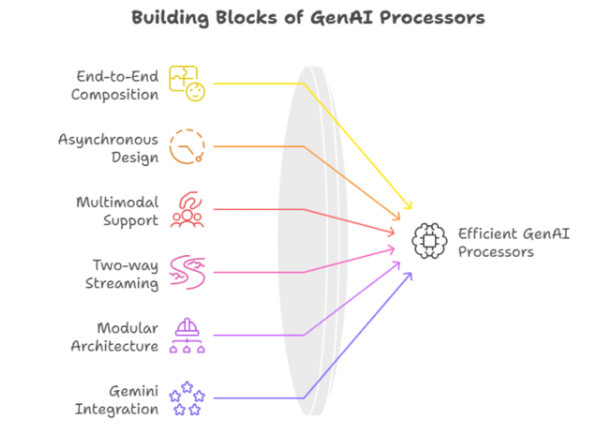
GenAI Processors的主要特性
1.端到端组合:通过使用直观的语法连接操作来实现。
Live_agent = input_processor + live_processor + play_output- 1.
2.异步设计:采用Python的asynchio进行设计,可通过手动线程高效处理I/O密集型和纯计算密集型任务。
3.多模态支持:通过 ProcessorPart包装器在统一的接口下处理文本、音频、视频和图像。
- 双向流传输:允许组件实时双向通信,从而提高交互性。
- 模块化架构:可重用且可测试的组件,极大地简化了复杂流水线的维护。
- Gemini 集成:直接支持Gemini Live API 和常见的基于文本的LLM操作。
如何安装 GenAI Processors?
上手GenAI Processors很简单:
先决条件
- Python 3.8 及以上版本
- Pip 包管理器
- Google Cloud 帐户(用于访问 Gemini API)
安装步骤
1. 安装库
pip install genai-processors- 1.
2. 设置身份验证
# For Google AI Studio
export GOOGLE_API_KEY="your-api-key"
# Or for Google Cloud
gcloud auth application-default login3. 检查安装
import genai_processors
print(genai_processors.__version__)- .
4. 开发设置(可选)
# Clone for examples or contributions
git clone https://github.com/google-gemini/genai-processors.git
cd genai-processors
pip install -eGenAI Processors如何工作?
GenAI Processors以基于流的处理模式而存在,数据沿着连接的Processors流水线流动。每个Processor:
- 接收ProcessorParts 流
- 处理数据(转换、API 调用等)
- 输出结果流
- 将结果传递给链中的下一个Processor
数据流示例
音频输入 → 语音转文本 → LLM 处理 → 文本转语音 → 音频输出
↓ ↓ ↓ ↓ ↓
ProcessorPart → ProcessorPart → ProcessorPart → ProcessorPart → ProcessorPart核心组件
GenAI Processors的核心组件包括:
1. 输入Processors
- VideoIn():摄像头数据流处理
- PyAudioIn():麦克风输入
- FileInput():文件输入
2. 处理Processors
- LiveProcessor():集成 Gemini Live API
- GenaiModel():标准 LLM 处理
- SpeechToText():音频转录
- TextToSpeech():语音合成
3. 输出Processors
- PyAudioOut():音频播放
- FileOutput():文件写入
- StreamOutput():实时流传输
并发性和性能
首先,GenAI Processors旨在最大限度地提高Processors的并发执行能力。此示例执行流程的任何部分都可以在计算图中的所有祖先节点后并发运行。换句话说,你的应用程序实际上将同时处理多路数据流,从而加快响应速度并提升用户体验。
实战:使用GenAI Processors构建实时智能体
不妨构建一个完整的实时AI智能体,它将连接摄像头内容流和音频流,将它们发送到 Gemini Live API 进行处理,最终返回音频响应。
注意:如果你想了解有关AI智能体的所有信息,请点击此处加入我们完整的AI Agentic Pioneer计划:Agentic AI Pioneer Program。
项目结构
我们的项目结构如下:
live_agent/
── main.py
── config.py
└── requirements.txt第1步:配置步骤
config.py
import os
from genai_processors.core import audio_io
# API configuration
GOOGLE_API_KEY = os.getenv("GOOGLE_API_KEY")
if not GOOGLE_API_KEY:
raise ValueError("Please set GOOGLE_API_KEY environment variable")
# Audio configuration
AUDIO_CONFIG = audio_io.AudioConfig(
sample_rate=16000,
channels=1,
chunk_size=1024,
format="int16"
)
# Video configuration
VIDEO_CONFIG = {
"width": 640,
"height": 480,
"fps": 30
}第2步:核心智能体实现
main.py
import asyncio
from genai_processors.core import (
audio_io,
live_model,
video,
streams
)
from config import AUDIO_CONFIG, VIDEO_CONFIG, GOOGLE_API_KEY
class LiveAgent:
def __init__(self):
self.setup_processors()
def setup_processors(self):
"""Initialize all processors for the live agent"""
# Input processor: combines camera and microphone
self.input_processor = (
video.VideoIn(
device_id=0,
width=VIDEO_CONFIG["width"],
height=VIDEO_CONFIG["height"],
fps=VIDEO_CONFIG["fps"]
) +
audio_io.PyAudioIn(
cnotallow=AUDIO_CONFIG,
device_index=None # Use default microphone
)
)
# Gemini Live API processor
self.live_processor = live_model.LiveProcessor(
api_key=GOOGLE_API_KEY,
model_name="gemini-2.0-flash-exp",
system_instructinotallow="You are a helpful AI assistant. Respond naturally to user interactions."
)
# Output processor: handles audio playback with interruption support
self.output_processor = audio_io.PyAudioOut(
cnotallow=AUDIO_CONFIG,
device_index=None, # Use default speaker
enable_interruptinotallow=True
)
# Complete agent pipeline
self.agent = (
self.input_processor +
self.live_processor +
self.output_processor
)
async def run(self):
"""Start the live agent"""
print("🤖 Live Agent starting...")
print("🎥 Camera and microphone active")
print("🔊 Audio output ready")
print("💬 Start speaking to interact!")
print("Press Ctrl+C to stop")
try:
async for part in self.agent(streams.endless_stream()):
# Process different types of output
if part.part_type == "text":
print(f"🤖 AI: {part.text}")
elif part.part_type == "audio":
print(f"🔊 Audio chunk: {len(part.audio_data)} bytes")
elif part.part_type == "video":
print(f"🎥 Video frame: {part.width}x{part.height}")
elif part.part_type == "metadata":
print(f"📊 Metadata: {part.metadata}")
except KeyboardInterrupt:
print("\n👋 Live Agent stopping...")
except Exception as e:
print(f"❌ Error: {e}")
# Advanced agent with custom processing
class CustomLiveAgent(LiveAgent):
def __init__(self):
super().__init__()
self.conversation_history = []
self.user_emotions = []
def setup_processors(self):
"""Enhanced setup with custom processors"""
from genai_processors.core import (
speech_to_text,
text_to_speech,
genai_model,
realtime
)
# Custom input processing with STT
self.input_processor = (
audio_io.PyAudioIn(cnotallow=AUDIO_CONFIG) +
speech_to_text.SpeechToText(
language="en-US",
interim_results=True
)
)
# Custom model with conversation memory
self.genai_processor = genai_model.GenaiModel(
api_key=GOOGLE_API_KEY,
model_name="gemini-pro",
system_instructinotallow="""You are an empathetic AI assistant.
Remember our conversation history and respond with emotional intelligence.
If the user seems upset, be supportive. If they're excited, share their enthusiasm."""
)
# Custom TTS with emotion
self.tts_processor = text_to_speech.TextToSpeech(
voice_name="en-US-Neural2-J",
speaking_rate=1.0,
pitch=0.0
)
# Audio rate limiting for smooth playback
self.rate_limiter = audio_io.RateLimitAudio(
sample_rate=AUDIO_CONFIG.sample_rate
)
# Complete custom pipeline
self.agent = (
self.input_processor +
realtime.LiveModelProcessor(
turn_processor=self.genai_processor + self.tts_processor + self.rate_limiter
) +
audio_io.PyAudioOut(cnotallow=AUDIO_CONFIG)
)
if __name__ == "__main__":
# Choose your agent type
agent_type = input("Choose agent type (1: Simple, 2: Custom): ")
if agent_type == "2":
agent = CustomLiveAgent()
else:
agent = LiveAgent()
# Run the agent
asyncio.run(agent.run())第3步:增强功能
不妨添加情绪检测和响应定制:
class EmotionAwareLiveAgent(LiveAgent):
def __init__(self):
super().__init__()
self.emotion_history = []
async def process_with_emotion(self, text_input):
"""Process input with emotion awareness"""
# Simple emotion detection (in practice, use more sophisticated methods)
emotions = {
"happy": ["great", "awesome", "fantastic", "wonderful"],
"sad": ["sad", "disappointed", "down", "upset"],
"excited": ["amazing", "incredible", "wow", "fantastic"],
"confused": ["confused", "don't understand", "what", "how"]
}
detected_emotion = "neutral"
for emotion, keywords in emotions.items():
if any(keyword in text_input.lower() for keyword in keywords):
detected_emotion = emotion
break
self.emotion_history.append(detected_emotion)
return detected_emotion
def get_emotional_response_style(self, emotion):
"""Customize response based on detected emotion"""
styles = {
"happy": "Respond with enthusiasm and positivity!",
"sad": "Respond with empathy and support. Offer help.",
"excited": "Match their excitement! Use energetic language.",
"confused": "Be patient and explanatory. Break down complex ideas.",
"neutral": "Respond naturally and helpfully."
}
return styles.get(emotion, styles["neutral"])第4步:运行智能体
requirements.txt
genai-processors>=0.1.0
google-generativeai>=0.3.0
pyaudio>=0.2.11
opencv-python>=4.5.0
asyncio>=3.4.3运行智能体的命令:
pip install -r requirements.txt
python main.pyGenAI Processors的优点
- 简化的开发体验:GenAI Processors消除了管理多个API调用和异步操作所带来的所有复杂性。开发人员可以直接将注意力集中在功能构建上,而不是基础设施代码上;因此,这不仅缩短了开发时间,还减少了潜在的错误。
- 统一的多模态接口:该库通过ProcessorPart包装器提供统一、一致的接口,用于与文本、音频、视频和图像数据进行交互。这意味着你无需针对不同类型的数据学习不同 API,这将大大简化你的开发工作。
- 实时性能:GenAI Processors直接基于Python的asyncio构建,在处理并发操作和流数据方面表现出色。该架构可确保最低延迟和流畅的实时交互——这正是语音助手或交互式视频处理等实时应用所需的执行能力。
- 模块化的可重用架构:模块化设计使组件更易于测试、调试和维护。你可以随意更换Processors、添加新功能和更改工作流程,无需重写整个系统。
GenAI Processors的局限性
- 依赖谷歌生态系统:支持不同的AI模型,但针对谷歌的的AI服务进行了高度优化。依赖其他AI提供商的开发者可能无法享受这种无缝集成,需要进行一番额外的设置。
- 复杂工作流程学习起来难度大:基本概念简单易懂;然而,复杂的多模态应用需要了解异步编程模式和流处理概念,这对初学者来说可能比较困难。
- 社区和文档有限:作为一个比较新的开源DeepMind项目,社区资源、教程和第三方扩展仍在不断完善,这使得高级故障排除和示例查找更加复杂。
- 资源密集型:实时多模态处理需要耗费大量的计算资源,尤其是在包含音频和文本的视频流中。此类应用会消耗大量的系统资源,必须进行适当的优化才能部署到生产环境。
GenAI Processors的用例
- 交互式客服机器人:构建真正先进的客服智能体,能够处理语音呼叫、通过视频分析客户情绪并提供情境化回复,同时还能实现几乎零延迟的实时自然对话。
- 教育工作者:AI 导师——可以设计个性化学习助手,能够识别学生面部表情、处理语音问题,并通过文本、音频和视觉辅助工具实时提供讲解,并根据每个人的学习风格进行调整。
- 医疗保健或医疗监测:通过视频监测患者的生命体征及其语音模式,以便及早发现疾病;然后将其与医疗数据库集成,进行全面的健康评估。
- 内容创作和媒体制作:构建即时视频编辑、自动播客生成或即时直播,AI 能够响应观众反应、生成字幕并动态改进内容。
结论
GenAI Processors标志着AI应用开发模式的转变,将复杂且互不关联的工作流程转变成合理且易于维护的解决方案。通过一个通用接口进行多模态 AI 处理,开发者可以开发创新功能,无需处理复杂的基础设施问题。
因此,如果流传输、多模态和迅即响应是AI应用的未来趋势,那么 GenAI Processors现在就可以满足这些需求。如果你想构建下一批大型客户服务机器人、教育助手或创意工具,GenAI Processors是你成功的基础。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献205条内容
已为社区贡献205条内容

所有评论(0)