头歌机器学习
机器学习常用库以及回归算法聚类算法代码
·
本文仅供机器学习参考
1、pandas初体验
1、了解数据处理对象--Series
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def create_series():
'''
返回值:
series_a: 一个Series类型数据
series_b: 一个Series类型数据
dict_a: 一个字典类型数据
'''
# 请在此添加代码 完成本关任务
# ********** Begin *********#
series_a=Series([1,2,5,7],index=['nu','li','xue','xi'])
dict_a={'ting':1,'shuo':2,'du':32,'xie':44}
series_b=Series(dict_a)
# ********** End **********#
# 返回series_a,dict_a,series_b
return series_a,dict_a,series_b
2、了解数据处理对象-DataFrame
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def create_dataframe():
'''
返回值:
df1: 一个DataFrame类型数据
'''
# 请在此添加代码 完成本关任务
# ********** Begin *********#
dictionary = {'states':['0hio','0hio','0hio','Nevada','Nevada'],
'years':[2000,2001,2002,2001,2002],
'pops':[1.5,1.7,3.6,2.4,2.9]}
df1 = DataFrame(dictionary)
df1=DataFrame(dictionary,index=['one','two','three','four','five'])
df1['new_add']=[7,4,5,8,2]
# ********** End **********#
#返回df1
return df1
3、读取 CSV 格式数据
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def read_csv_data():
'''
返回值:
df1: 一个DataFrame类型数据
length1: 一个int类型数据
'''
# 请在此添加代码 完成本关任务
# ********** Begin *********#
df1 = pd.read_csv('test3/uk_rain_2014.csv', header=0)
df1.columns = ['water_year','rain_octsep','outflow_octsep','rain_decfeb', 'outflow_decfeb', 'rain_junaug', 'outflow_junaug']
length1=len(df1)
# ********** End **********#
#返回df1,length1
return df1,length1
4、数据的基本操作——排序
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def sort_gate():
'''
返回值:
s2: 一个Series类型数据
d2: 一个DataFrame类型数据
'''
# s1是Series类型数据,d1是DataFrame类型数据
s1 = Series([4, 3, 7, 2, 8], index=['z', 'y', 'j', 'i', 'e'])
d1 = DataFrame({'e': [4, 2, 6, 1], 'f': [0, 5, 4, 2]})
# 请在此添加代码 完成本关任务
# ********** Begin *********#
s2=s1.sort_index()
d2=d1.sort_values(by='f')
# ********** End **********#
#返回s2,d2
return s2,d2
5、数据的基本操作——删除
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import numpy as np
import pandas as pd
def delete_data():
'''
返回值:
s2: 一个Series类型数据
d2: 一个DataFrame类型数据
'''
# s1是Series类型数据,d1是DataFrame类型数据
s1 = Series([5, 2, 4, 1], index=['v', 'x', 'y', 'z'])
d1=DataFrame(np.arange(9).reshape(3,3), columns=['xx','yy','zz'])
# 请在此添加代码 完成本关任务
# ********** Begin *********#
s2=s1.drop('z')
d2=d1.drop(['yy'],axis=1)
# ********** End **********#
# 返回s2,d2
return s2, d2
6、 数据的基本操作——算术运算
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import numpy as np
import pandas as pd
def add_way():
'''
返回值:
df3: 一个DataFrame类型数据
'''
# df1,df2是DataFrame类型数据
df1 = DataFrame(np.arange(12.).reshape((3, 4)), columns=list('abcd'))
df2 = DataFrame(np.arange(20.).reshape((4, 5)), columns=list('abcde'))
df3=df1.add(df2,fill_value=4)
# 请在此添加代码 完成本关任务
# ********** Begin *********#
# ********** End **********#
# 返回df3
return df3
7、 数据的基本操作——去重
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def delete_duplicated():
'''
返回值:
df2: 一个DataFrame类型数据
'''
# df1是DataFrame类型数据
df1 = DataFrame({'k1': ['one'] * 3 + ['two'] * 4, 'k2': [1, 1, 2, 3, 3, 4, 4]})
# 请在此添加代码 完成本关任务
# ********** Begin *********#
df2=df1.drop_duplicates()
# ********** End **********#
# 返回df2
return df2
8、数据重塑
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
def suoying():
'''
返回值:
d1: 一个DataFrame类型数据
'''
#s1是Series类型数据
s1=Series(np.random.randn(10),
index=[['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'd', 'd'], [1, 2, 3, 1, 2, 3, 1, 2, 2, 3]])
# 请在此添加代码 完成本关任务
# ********** Begin *********#
d1=s1.unstack()
# ********** End **********#
# 返回d1
return d1
suoying()
2、pandas进阶
1、 Pandas 分组聚合
import pandas as pd
import numpy as np
'''
返回最大值与最小值的和
'''
def sub(df):
######## Begin #######
return df.max() - df.min()
######## End #######
def main():
######## Begin #######
data = pd.read_csv("step1/drinks.csv")
df = pd.DataFrame(data)
mapping = {"wine_servings":sub,"beer_servings":np.sum}
print(df.groupby("continent").agg(mapping))
######## End #######
if __name__ == '__main__':
main()
2、 Pandas 创建透视表和交叉表
#-*- coding: utf-8 -*-
import pandas as pd
#创建透视表
def create_pivottalbe(data):
###### Begin ######
return data.pivot_table(index=["day"],values=["tip"],columns=["time"],margins=True,aggfunc=sum)
###### End ######
#创建交叉表
def create_crosstab(data):
###### Begin ######
return pd.crosstab(index=[data.day],columns=[data.time],values=data.tip,aggfunc=sum ,margins=True)
###### End ######
def main():
#读取csv文件数据并赋值给data
###### Begin ######
data = pd.read_csv("step2/tip.csv")
###### End ######
piv_result = create_pivottalbe(data)
cro_result = create_crosstab(data)
print("透视表:\n{}".format(piv_result))
print("交叉表:\n{}".format(cro_result))
if __name__ == '__main__':
main()
3、NumPy基础及取值操作
1、ndarray对象
import numpy as np
def print_ndarray(input_data):
'''
实例化ndarray对象并打印
:param input_data: 测试用例,类型为字典类型
:return: None
'''
#********* Begin *********#
a = np.array(input_data['data'])
print(a)
#********* End *********#2、形状操作
import numpy as np
def reshape_ndarray(input_data):
'''
将ipnut_data转换成ndarray后将其变形成一位数组并打印
:param input_data: 测试用例,类型为list
:return: None
'''
#********* Begin *********#
a = np.array(input_data)
a = a.reshape((1,-1))
print(a[0,])
#********* End *********#3、基础操作
import numpy as np
def get_answer(input_data):
'''
将input_data转换成ndarray后统计每一行中最大值的位置并打印
:param input_data: 测试用例,类型为list
:return: None
'''
#********* Begin *********#
a = np.array(input_data)
print(a.argmax(axis=1))
#********* End *********#4、随机数生成
import numpy as np
def shuffle(input_data):
'''
打乱input_data并返回打乱结果
:param input_data: 测试用例输入,类型为list
:return: result,类型为list
'''
# 保存打乱的结果
result = []
#********* Begin *********#
result = list(np.random.choice(a=input_data,size=len(input_data),replace=False))
#********* End *********#
return result5、索引与切片
import numpy as np
def get_roi(data, x, y, w, h):
'''
提取data中左上角顶点坐标为(x, y)宽为w高为h的ROI
:param data: 二维数组,类型为ndarray
:param x: ROI左上角顶点的行索引,类型为int
:param y: ROI左上角顶点的列索引,类型为int
:param w: ROI的宽,类型为int
:param h: ROI的高,类型为int
:return: ROI,类型为ndarray
'''
#********* Begin *********#
a = data[x:x+h+1,y:y+w+1]
return a
#********* End *********#4、NumPy 数组的高级操作
1、堆叠操作
import numpy as np
def get_mean(feature1, feature2):
'''
将feature1和feature2横向拼接,然后统计拼接后的ndarray中每列的均值
:param feature1:待`hstack`的`ndarray`
:param feature2:待`hstack`的`ndarray`
:return:类型为`ndarray`,其中的值`hstack`后每列的均值
'''
#********* Begin *********#
return np.mean(np.hstack((feature1,feature2)), 0)
#********* End *********#2、比较、掩码和布尔逻辑
import numpy as np
def student(num,input_data):
result=[]
# ********* Begin *********#
a = np.array(input_data)
result = a[a > num]
# ********* End *********#
return result3、花式索引与布尔索引
import numpy as np
def student(input_data):
result=[]
#********* Begin *********#
a = np.array(input_data)
result = a[(a>='A')&(a<='Z')]
# ********* End *********#
return result4、广播机制
import numpy as np
def student(a,b,c):
result=[]
# ********* Begin *********#
a = np.array(a)
b = np.array(b)
c = np.array(c)
result = a + b + c
# ********* End *********#
return result5、线性代数
from numpy import linalg
import numpy as np
def student(input_data):
'''
将输入数据筛选性别为男,再进行线性方程求解
:param input_data:类型为`list`的输入数据
:return:类型为`ndarray`
'''
result=[]
# ********* Begin *********#
a = np.array(input_data)
x=[]
y=[]
for i in a:
if i[0]=="男":
x.append([int(i[1]),int(i[2])])
y.append([int(i[-1])])
if x==[] and y==[]:
return result
x=np.array(x)
y=np.array(y)
result=linalg.solve(x,y)
# ********* End *********#
return result5、数据挖掘算法原理与实践:数据预处理
1、标准化
# -*- coding: utf-8 -*-
from sklearn.preprocessing import scale,MaxAbsScaler,MinMaxScaler
#实现数据预处理方法
def Preprocessing(x,y):
'''
x(ndarray):处理 数据
y(str):y等于'z_score'使用z_score方法
y等于'minmax'使用MinMaxScaler方法
y等于'maxabs'使用MaxAbsScaler方法
'''
#********* Begin *********#
if y=='z_score':
x = scale(x)
return x
elif y=='minmax':
x = MinMaxScaler().fit_transform(x)
return x
elif y=='maxabs':
x = MaxAbsScaler().fit_transform(x)
return x
#********* End *********#
2、非线性转换
# -*- coding: utf-8 -*-
from sklearn.preprocessing import QuantileTransformer
#实现非线性转换方法
def non_linear_transformation(x,y):
'''
x(ndarray):待处理数据
y(int):y等于0映射到均匀分布
y等于1映射到高斯分布
'''
#********* Begin *********#
if y==0:
x = QuantileTransformer(random_state=666).fit_transform(x)
return x
elif y==1:
x = QuantileTransformer(output_distribution='normal', random_state=666).fit_transform(x)
return x
#********* End *********#
3、归一化
# -*- coding: utf-8 -*-
from sklearn.preprocessing import normalize
#实现数据归一化方法
def normalization(x,y):
'''
x(ndarray):待处理数据
y(int):y等于1则使用"l1"归一化
y等于2则使用"l2"归一化
'''
#********* Begin *********#
if y==1:
x = normalize(x,'l1')
return x
elif y==2:
x = normalize(x,'l2')
return x
#********* End *********#4、离散值编码
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
def onehot_label(label):
'''
input:label(list):待处理标签
output:lable(ndarray):onehot处理后的标签
'''
#********* Begin *********#
label = LabelEncoder().fit_transform(label)
label = np.array(label).reshape(len(label),1)
label = OneHotEncoder().fit_transform(label).toarray()
return label
#********* End *********#5、生成多项式特征
# -*- coding: utf-8 -*-
from sklearn.preprocessing import PolynomialFeatures
def polyfeaturs(x,y):
'''
x(ndarray):待处理特征
y(int):y等于0生成二项式特征
y等于1生成二项式特征,只需要特征之间交互
'''
#********* Begin *********#
if y==0:
x = PolynomialFeatures(2).fit_transform(x)
return x
elif y==1:
x = PolynomialFeatures(degree=2, interaction_only=True).fit_transform(x)
return x
#********* End *********#6、估算缺失值
# -*- coding: utf-8 -*-
from sklearn.preprocessing import Imputer
def imp(x,y):
'''
x(ndarray):待处理数据
y(str):y为'mean'则用取平均方式补充缺失值
y为'meian'则用取中位数方式补充缺失值
y为'most_frequent'则用出现频率最多的值代替缺失值
'''
#********* Begin *********#
if y=='mean':
x = Imputer(missing_values='NaN', strategy='mean', axis=0).fit_transform(x)
return x
elif y=='meian':
x = Imputer(missing_values='NaN', strategy='meian', axis=0).fit_transform(x)
return x
elif y=='most_frequent':
x = Imputer(missing_values='NaN', strategy='most_frequent', axis=0).fit_transform(x)
return x
#********* End *********#6、线性回归
1、简单线性回归与多元线性回归

2、线性回归的正规方程解
#encoding=utf8
import numpy as np
def mse_score(y_predict,y_test):
'''
input:y_predict(ndarray):预测值
y_test(ndarray):真实值
ouput:mse(float):mse损失函数值
'''
#********* Begin *********#
mse = np.mean((y_predict-y_test)/2)
#********* End *********#
return mse
class LinearRegression :
def __init__(self):
'''初始化线性回归模型'''
self.theta = None
def fit_normal(self,train_data,train_label):
'''
input:train_data(ndarray):训练样本
train_label(ndarray):训练标签
'''
#********* Begin *********#
x = np.hstack([np.ones((len(train_data),1)),train_data])
self.theta =np.linalg.inv(x.T.dot(x)).dot(x.T).dot(train_label)
#********* End *********#
return self.theta
def predict(self,test_data):
'''
input:test_data(ndarray):测试样本
'''
#********* Begin *********#
x = np.hstack([np.ones((len(test_data),1)),test_data])
return x.dot(self.theta)
#********* End *********#3、衡量线性回归的性能指标
#encoding=utf8
import numpy as np
#mse
def mse_score(y_predict,y_test):
mse = np.mean((y_predict-y_test)**2)
return mse
#r2
def r2_score(y_predict,y_test):
'''
input:y_predict(ndarray):预测值
y_test(ndarray):真实值
output:r2(float):r2值
'''
#********* Begin *********#
r2 = 1 - mse_score(y_predict,y_test)/np.var(y_test)
#********* End *********#
return r2
class LinearRegression :
def __init__(self):
'''初始化线性回归模型'''
self.theta = None
def fit_normal(self,train_data,train_label):
'''
input:train_data(ndarray):训练样本
train_label(ndarray):训练标签
'''
#********* Begin *********#
x = np.hstack([np.ones((len(train_data),1)),train_data])
self.theta =np.linalg.inv(x.T.dot(x)).dot(x.T).dot(train_label)
#********* End *********#
return self
def predict(self,test_data):
'''
input:test_data(ndarray):测试样本
'''
#********* Begin *********#
x = np.hstack([np.ones((len(test_data),1)),test_data])
return x.dot(self.theta)
#********* End *********#4、scikit-learn线性回归实践 - 波斯顿房价预测
#encoding=utf8
#********* Begin *********#
import pandas as pd
from sklearn.linear_model import LinearRegression
#读取训练数据
train_data = pd.read_csv('./step3/train_data.csv')
#读取训练标签
train_label = pd.read_csv("./step3/train_label.csv")
train_label = train_label["target"]
#读取测试数据
test_data = pd.read_csv("./step3/test_data.csv")
lr = LinearRegression()
#训练模型
lr.fit(train_data,train_label)
#预测标签
predict = lr.predict(test_data)
#写入csv
df = pd.DataFrame({"result":predict})
df.to_csv("./step3/result.csv", index=False)
#********* End *********#7、AGNES
1、距离的计算
import numpy as np
def calc_min_dist(cluster1, cluster2):
'''
计算簇间最小距离
:param cluster1:簇1中的样本数据,类型为ndarray
:param cluster2:簇2中的样本数据,类型为ndarray
:return:簇1与簇2之间的最小距离
'''
#********* Begin *********#
min_dist = np.inf
for i in range(len(cluster1)):
for j in range(len(cluster2)):
dist = np.sqrt(np.sum(np.square(cluster1[i] - cluster2[j])))
if dist < min_dist:
min_dist = dist
return min_dist
#********* End *********#
def calc_max_dist(cluster1, cluster2):
'''
计算簇间最大距离
:param cluster1:簇1中的样本数据,类型为ndarray
:param cluster2:簇2中的样本数据,类型为ndarray
:return:簇1与簇2之间的最大距离
'''
#********* Begin *********#
max_dist = 0
for i in range(len(cluster1)):
for j in range(len(cluster2)):
dist = np.sqrt(np.sum(np.square(cluster1[i] - cluster2[j])))
if dist > max_dist:
max_dist=dist
return max_dist
#********* End *********#
def calc_avg_dist(cluster1, cluster2):
'''
计算簇间平均距离
:param cluster1:簇1中的样本数据,类型为ndarray
:param cluster2:簇2中的样本数据,类型为ndarray
:return:簇1与簇2之间的平均距离
'''
#********* Begin *********#
num = len(cluster1)*len(cluster2)
avg_dist = 0
for i in range(len(cluster1)):
for j in range(len(cluster2)):
dist = np.sqrt(np.sum(np.square(cluster1[i] - cluster2[j])))
avg_dist +=dist
avg_dist = avg_dist/num
return avg_dist
#********* End *********#
2、AGNES算法流程
import numpy as np
def AGNES(feature, k):
'''
AGNES聚类并返回聚类结果
假设数据集为`[1, 2], [10, 11], [1, 3]],那么聚类结果可能为`[[1, 2], [1, 3]], [[10, 11]]]
:param feature:训练数据集所有特征组成的ndarray
:param k:表示想要将数据聚成`k`类,类型为`int`
:return:聚类结果
'''
#********* Begin *********#
# 找到距离最小的下标
def find_Min(M):
min = np.inf
x = 0;
y = 0
for i in range(len(M)):
for j in range(len(M[i])):
if i != j and M[i][j] < min:
min = M[i][j];
x = i;
y = j
return (x, y, min)
#计算簇间最大距离
def calc_max_dist(cluster1, cluster2):
max_dist = 0
for i in range(len(cluster1)):
for j in range(len(cluster2)):
dist = np.sqrt(np.sum(np.square(cluster1[i] - cluster2[j])))
if dist > max_dist:
max_dist = dist
return max_dist
#初始化C和M
C = []
M = []
for i in feature:
Ci = []
Ci.append(i)
C.append(Ci)
for i in C:
Mi = []
for j in C:
Mi.append(calc_max_dist(i, j))
M.append(Mi)
q = len(feature)
#合并更新
while q > k:
x, y, min = find_Min(M)
C[x].extend(C[y])
C.pop(y)
M = []
for i in C:
Mi = []
for j in C:
Mi.append(calc_max_dist(i, j))
M.append(Mi)
q -= 1
return C
#********* End *********#
3、红酒聚类
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
def Agglomerative_cluster(data):
'''
对红酒数据进行聚类
:param data: 数据集,类型为ndarray
:return: 聚类结果,类型为ndarray
'''
# 数据预处理:标准化处理,使得每个特征的均值为0,标准差为1
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# 创建AgglomerativeClustering实例,设置聚类数为3,使用ward方法来计算簇间距离
agnes = AgglomerativeClustering(n_clusters=3, linkage='ward')
# 训练模型并获取聚类结果
result = agnes.fit_predict(data_scaled)
return result
# 示例调用
# 假设有一个名为wine_data的ndarray,包含了红酒数据集
# result = Agglomerative_cluster(wine_data)
# print(result)
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
def Agglomerative_cluster(data):
'''
对红酒数据进行聚类
:param data: 数据集,类型为ndarray
:return: 聚类结果,类型为ndarray
'''
# 数据预处理:标准化处理,使得每个特征的均值为0,标准差为1
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# 创建AgglomerativeClustering实例,设置聚类数为3,使用ward方法来计算簇间距离
agnes = AgglomerativeClustering(n_clusters=3, linkage='ward')
# 训练模型并获取聚类结果
result = agnes.fit_predict(data_scaled)
return result
# 示例调用
# 假设有一个名为wine_data的ndarray,包含了红酒数据集
# result = Agglomerative_cluster(wine_data)
# print(result)
8、DBSCAN
1、DBSCAN算法的基本概念
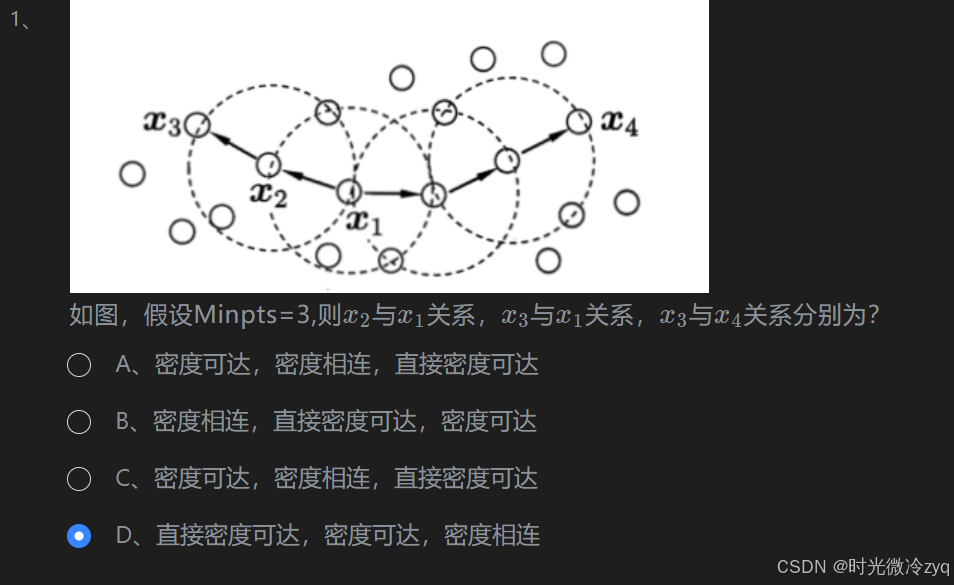
2、DBSCAN算法流程
# encoding=utf8
import numpy as np
import random
from copy import copy
from collections import deque
# 寻找eps邻域内的点
def findNeighbor(j, X, eps):
return {p for p in range(X.shape[0]) if np.linalg.norm(X[j] - X[p]) <= eps}
# dbscan算法
def dbscan(X, eps, min_Pts):
"""
input:X(ndarray):样本数据
eps(float):eps邻域半径
min_Pts(int):eps邻域内最少点个数
output:cluster(list):聚类结果
"""
# ********* Begin *********#
# 初始化核心对象集合
core_objects = {i for i in range(len(X)) if len(findNeighbor(i, X, eps)) >= min_Pts}
# 初始化聚类簇数
k = 0
# 初始化未访问的样本集合
not_visited = set(range(len(X)))
# 初始化聚类结果
cluster = np.zeros(len(X))
while len(core_objects) != 0:
old_not_visited = copy(not_visited)
# 初始化聚类簇队列
o = random.choice(list(core_objects))
queue = deque()
queue.append(o)
not_visited.remove(o)
while len(queue) != 0:
q = queue.popleft()
neighbor_list = findNeighbor(q, X, eps)
if len(neighbor_list) >= min_Pts:
# 寻找在邻域中并没被访问过的点
delta = neighbor_list & not_visited
for element in delta:
queue.append(element)
not_visited.remove(element)
k += 1
this_class = old_not_visited - not_visited
cluster[list(this_class)] = k
core_objects = core_objects - this_class
# ********* End *********#
return cluster3、sklearn中的DBSCAN
#encoding=utf8
from sklearn.cluster import DBSCAN
def data_cluster(data):
'''
input: data(ndarray) :数据
output: result(ndarray):聚类结果
'''
#********* Begin *********#
dbscan = DBSCAN(eps=0.5, min_samples=10)
result = dbscan.fit_predict(data)
return result
#********* End *********#
9、 k-means
1、距离度量
#encoding=utf8
import numpy as np
def distance(x,y,p=2):
'''
input:x(ndarray):第一个样本的坐标
y(ndarray):第二个样本的坐标
p(int):等于1时为曼哈顿距离,等于2时为欧氏距离
output:distance(float):x到y的距离
'''
#********* Begin *********#
#distance = np.linalg.norm(x-y, p)
if p == 1:
distance = np.abs(x-y).sum()#绝对值
if p == 2:
distance = np.sqrt(np.square(x-y).sum())
return distance
#********* End *********#
2、什么是质心
#encoding=utf8
import numpy as np
#计算样本间距离
def distance(x, y, p=2):
'''
input:x(ndarray):第一个样本的坐标
y(ndarray):第二个样本的坐标
p(int):等于1时为曼哈顿距离,等于2时为欧氏距离
output:distance(float):x到y的距离
'''
#********* Begin *********#
if p == 1:
distance = np.abs(x-y).sum()
if p == 2:
distance = np.sqrt(np.square(x-y).sum())
return distance
#********* End *********#
#计算质心(均值向量)
def cal_Cmass(data):
'''
input:data(ndarray):数据样本
output:mass(ndarray):数据样本质心
'''
#********* Begin *********#
Cmass = np.mean(data,axis=0)#np.mean()中的axis=0是指对列进行求均值,axis=1是指对行求均值
#********* End *********#
return Cmass
#计算每个样本到质心的距离,并按照从小到大的顺序排列
def sorted_list(data,Cmass):
'''
input:data(ndarray):数据样本
Cmass(ndarray):数据样本质心
output:dis_list(list):排好序的样本到质心距离
'''
#********* Begin *********#
distance_list = []#把每个样本到质心的距离放到列表里
#Cmass = cal_Cmass(data)(质心已知,无须计算)
for d in data:#计算每个样本到质心的距离
distance_list.append(distance(d, Cmass, p=2))
dis_list = sorted(distance_list)#排序
#********* End *********#
return dis_list
3、k-means算法流程
#encoding=utf8
import numpy as np
# 计算一个样本与数据集中所有样本的欧氏距离的平方
def euclidean_distance(one_sample, X):#one_sample:测试样本,X:所有样本
#将测试样本变成只有1行
one_sample = one_sample.reshape(1, -1)#reshape(1,-1)将one_sample转化成1行
#计算测试样本与每一个训练样本的欧氏距离
#(np.tile(one_sample, (X.shape[0], 1))将测试样本沿y轴复制,使其行数等于训练样本行数)
'''
np.tile(a,(2,1))第一个参数为Y轴扩大倍数,第二个为X轴扩大倍数。
本例中X轴扩大一倍便为不复制。
'''
distances = np.power(np.tile(one_sample, (X.shape[0], 1)) - X, 2).sum(axis=1)#axis=1表示按行相加(把每一行的数据相加得到一个数)
return distances
class Kmeans():
"""Kmeans聚类算法.
算法过程如下:
(1)随机选取K个数据作为质心(聚类中心)。
(2)计算每个数据到每个质心的距离,并把它归到最近的质心的簇。
(3)重新计算已经得到的各个簇的质心。
(4)迭代(2)~(3步直至新的质心与原质心相等或小于指定阈值,算法结束。
Parameters:
-----------
k: int
聚类的数目.
max_iterations: int
最大迭代次数.
varepsilon: float
判断是否收敛, 如果上一次的所有k个聚类中心与本次的所有k个聚类中心的差都小于varepsilon,
则说明算法已经收敛
"""
def __init__(self, k=2, max_iterations=500, varepsilon=0.0001):
self.k = k
self.max_iterations = max_iterations
self.varepsilon = varepsilon
#:从每堆种子里选出来的数都是不会变的,从不同的堆里选随机种子每次都不一样
np.random.seed(1)#第一堆
# 从所有样本中随机选取self.k样本作为初始的聚类中心
def init_random_centroids(self, X):
n_samples, n_features = np.shape(X)
centroids = np.zeros((self.k, n_features))#初始化:k行,n_features列
for i in range(self.k):
centroid = X[np.random.choice(range(n_samples))]#随机选择
centroids[i] = centroid
return centroids
# 返回距离该样本最近的一个中心索引[0, self.k)
def _closest_centroid(self, sample, centroids):
distances = euclidean_distance(sample, centroids)
closest_i = np.argmin(distances)#给出水平方向最小值的下标
return closest_i
# 将所有样本进行归类,归类规则就是将该样本归类到与其最近的中心
def create_clusters(self, centroids, X):
clusters = [[] for _ in range(self.k)]
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)
#组合为一个索引序列,
#同时列出数据和数据下标,一般用在 for 循环当中
for sample_i, sample in enumerate(X):
#返回距离该样本最近的一个中心索引
centroid_i = self._closest_centroid(sample, centroids)
clusters[centroid_i].append(sample_i)
return clusters
# 对中心进行更新
def update_centroids(self, clusters, X):
n_features = np.shape(X)[1]
centroids = np.zeros((self.k, n_features))
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)
#组合为一个索引序列,
#同时列出数据和数据下标,一般用在 for 循环当中
for i, cluster in enumerate(clusters):
centroid = np.mean(X[cluster], axis=0)
centroids[i] = centroid
return centroids
# 将所有样本进行归类,其所在的类别的索引就是其类别标签
def get_cluster_labels(self, clusters, X):
y_pred = np.zeros(np.shape(X)[0])
for cluster_i, cluster in enumerate(clusters):
for sample_i in cluster:
y_pred[sample_i] = cluster_i
return y_pred
#********* Begin *********#
# 对整个数据集X进行Kmeans聚类,返回其聚类的标签
def predict(self, X):
# 从所有样本中随机选取self.k样本作为初始的聚类中心
centroids = self.init_random_centroids(X)
# 迭代,直到算法收敛(上一次的聚类中心和这一次的聚类中心几乎重合)或者达到最大迭代次数
for i in range(self.max_iterations):
# 将所有进行归类,归类规则就是将该样本归类到与其最近的中心
clusters = self.create_clusters(centroids, X)
temp_centroids = centroids
# 计算新的聚类中心
centroids = self.update_centroids(clusters, X)
# 如果聚类中心几乎没有变化,说明算法已经收敛,退出迭代
difference = centroids - temp_centroids
if difference.any() < self.varepsilon:
break
y_pred = self.get_cluster_labels(clusters, X)
return y_pred
#********* End *********#
4、sklearn中的k-means
#encoding=utf8
from sklearn.cluster import KMeans
def kmeans_cluster(data):
'''
input:data(ndarray):样本数据
output:result(ndarray):聚类结果
'''
#********* Begin *********#
kmeans = KMeans(n_clusters=3,random_state=888)
result = kmeans.fit_predict(data)
#********* End *********#
return result
10、KNN算法
1、KNN算法原理

2、使用sklearn中的kNN算法进行分类
本关任务:编写一个能对数据进行分类的程序。
from sklearn.neighbors import KNeighborsClassifier
def classification(train_feature, train_label, test_feature):
'''
使用KNeighborsClassifier对test_feature进行分类
:param train_feature: 训练集数据
:param train_label: 训练集标签
:param test_feature: 测试集数据
:return: 测试集预测结果
'''
#********* Begin *********#
clf = KNeighborsClassifier()
clf.fit(train_feature, train_label)
return clf.predict(test_feature)
#********* End *********#3、使用sklearn中的kNN算法进行回归
本关任务:编写一个能对数据进行回归的程序。
from sklearn.neighbors import KNeighborsRegressor
def regression(train_feature, train_label, test_feature):
'''
使用KNeighborsRegressor对test_feature进行分类
:param train_feature: 训练集数据
:param train_label: 训练集标签
:param test_feature: 测试集数据
:return: 测试集预测结果
'''
#********* Begin *********#
clf=KNeighborsRegressor()
clf.fit(train_feature, train_label)
return clf.predict(test_feature)
#********* End *********#4、分析红酒数据
本关任务:编写Python代码,实现平均酒精含量的功能。
编程要求
请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充,完成alcohol_mean函数。该函数需要完成返回红酒数据中的平均酒精含量。其中函数的参数解释如下:
data:红酒数据对象。
import numpy as np
def alcohol_mean(data):
'''
返回红酒数据中红酒的酒精平均含量
:param data: 红酒数据对象
:return: 酒精平均含量,类型为float
'''
#********* Begin *********#
return data.data[:,0].mean()
#********* End **********#
5、对数据进行标准化
本关任务:编写Python代码,实现标准化数据的功能。
编程要求
请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充,完成scaler函数。该函数需要完成是返回标准化后的数据。其中函数的参数解释如下:
data:红酒数据对象。
from sklearn.preprocessing import StandardScaler
def scaler(data):
'''
返回标准化后的红酒数据
:param data: 红酒数据对象
:return: 标准化后的红酒数据,类型为ndarray
'''
#********* Begin *********#
scaler=StandardScaler()
after_scaler=scaler.fit_transform(data['data'])
return after_scaler
#********* End **********#
6、使用kNN算法进行预测
本关任务:编写Python代码,实现红酒分类功能。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
def classification(train_feature, train_label, test_feature):
'''
对test_feature进行红酒分类
:param train_feature: 训练集数据,类型为ndarray
:param train_label: 训练集标签,类型为ndarray
:param test_feature: 测试集数据,类型为ndarray
:return: 测试集数据的分类结果
'''
#********* Begin *********#
scaler=StandardScaler()
train_feature=scaler.fit_transform(train_feature)
test_feature=scaler.transform(test_feature)
clf=KNeighborsClassifier()
clf.fit(train_feature,train_label)
return clf.predict(test_feature)
#********* End **********#
注:本文仅供机器学习参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)