When Model Meets New Normals: Test-Time Adaptation for Unsupervised Time-Series Anomaly Detection
时间序列异常检测通过从观察序列中学习正态性来处理检测异常时间步长的问题。然而,正态性的概念随着时间的推移而演变,导致了“新正态性问题”,其中正态性的分布可能由于训练数据和测试数据之间的分布变化而改变。本文强调了无监督时间序列异常检测研究中新常态问题的普遍存在。为了解决这个问题,我们提出了一种基于趋势估计的简单而有效的测试时间适应策略,以及一种在推理过程中学习新常态的自监督方法。对现实世界基准的大量
系列文章目录
当模型遇到新常态时:无监督时间序列异常检测的测试时间适应
摘要
时间序列异常检测通过从观察序列中学习正态性来处理检测异常时间步长的问题。 然而,正态性的概念随着时间的推移而演变,导致了“新正态性问题”,其中正态性的分布可能由于训练数据和测试数据之间的分布变化而改变。 本文强调了无监督时间序列异常检测研究中新常态问题的普遍存在。 为了解决这个问题,我们提出了一种基于趋势估计的简单而有效的测试时间适应策略,以及一种在推理过程中学习新常态的自监督方法。 对现实世界基准的大量实验表明,与基线相比,将所提出的策略纳入异常检测器可以持续提高模型的性能,从而提高分布变化的鲁棒性。
一、引言
在现实世界的监控系统中,众多传感器的连续运行会产生大量的实时测量结果。 时间序列异常检测旨在识别一系列观测值中偏离正态性概念的观测值(Ruff et al. 2021;Pang et al. 2022)。 异常事件的例子包括对工业系统的物理攻击(Mathur 和 Tippenhauer 2016;Han 等人 2021)、不可预测的机器人行为(Park、Hoshi 和 Kemp 2018)、宽传感器网络中的故障传感器(Wang、Kuang 和 Duan) 2015;Rassam、Maarof 和 Zainal 2018)、对服务器监控系统的网络安全攻击(Su 等人,2019;Abdulaal、Liu 和 Lancewicki 2021)以及基于遥测传感器数据的航天器故障(Hundman 等人,2018;Shin 等人) 等,2020;刘、刘和彭,2016)。
然而,由于多种因素,检测异常时间步长面临着巨大的挑战。 首先,系统动力学的复杂性(以多个传感器的协调为特征)使任务变得复杂。 其次,监控系统收到的信号量不断增加也增加了难度。 最后,获取异常行为的标签是有问题的。 为了应对这些挑战,出现了无监督时间序列异常检测模型(Xu et al. 2022;Audibert et al. 2020;Su et al. 2019;Park, Hoshi, and Kemp 2018;Malhotra et al. 2016),重点关注 从可用的训练数据集中学习正常模式并在训练后部署。
然而,正态性的概念会随着时间的推移而变化,被广泛称为分布变化(QuinoneroCandela et al. 2008;Kim et al. 2022b;Sun et al. 2020;Gulrajani and Lopez-Paz 2021;Wang et al. 2021, 2022) ),如图1-(a)所示。 我们观察到,现成的模型很容易受到这种变化的影响,从而导致“新常态问题”,即测试时间内的正态分布不能仅根据训练数据来完全表征。 在不考虑分布变化的情况下,这些模型往往依赖于过去的观测结果并产生误报,从而损害了监测系统的一致性(Dragoi 等人,2022 年;Cao、Zhu 和 Pang,2023 年)。
最近,人们提出了测试时间适应机制(Wang et al. 2021, 2022;Niu et al. 2022)来调整模型,以减轻由于训练和测试数据集之间的分布变化而导致的性能下降,特别是在计算机视觉领域。 测试时适应方法更新模型参数以推广到不同的数据分布,而不依赖于标签的额外监督或对训练数据的访问。 时间序列异常检测任务也有应用测试时间适应策略的动机; 由于监测系统是实时运行的,频繁访问过去的数据以进行适应成本高昂(Abdulaal、Liu 和 Lancewicki 2021;Shin 等人,2020 年;Su 等人,2019),并且需要在没有监督的情况下更新模型,因为获取标签通常是 有限(Geiger 等人,2020 年;Ruff 等人,2021 年;Audibert 等人,2020 年)。 受这些进步的推动,我们提出了一种测试时间适应方法,用于分布变化下的无监督时间序列异常检测。
我们的论文强调了时间序列异常检测文献中新常态问题的普遍存在。 为了正确解决这个问题,我们提出了一种简单而有效的适应策略,使用趋势估计和基于模型预测本身的正常实例的模型更新。 趋势估计由观测值的指数移动平均值给出,遵循时间序列的预期值,并以计算效率适应不断变化的条件(Muth 1960)。 模型部署后,我们使用归一化输入序列更新模型参数,并通过减去趋势估计来消除趋势,以学习仅通过趋势估计无法捕获的复杂动态。 我们提出的方法使模型对这种分布变化具有鲁棒性,从而提高探测器性能,如图 1-(b) 和图 1-© 所示。
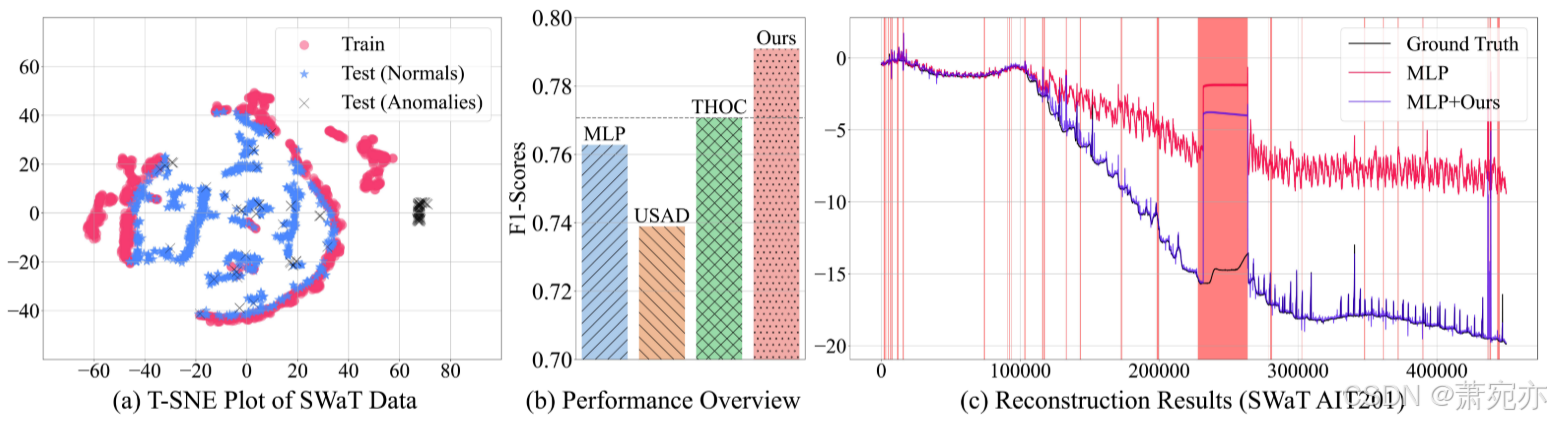
图 1:学习新常态的动机。 (a) SWaT 基准的 T-SNE 可视化(Mathur 和 Tippenhauer 2016)揭示了训练数据(红色)和测试数据(蓝色)之间的不同行为。 (b) 我们的测试时间适应策略在 F1 分数方面超越了以前最先进的时间序列异常检测模型,即使使用简单的基线(例如基于 MLP 的自动编码器)也是如此。 © 这种改进源于有效处理时间序列数据中的重大分布变化。 随着时间的推移,现成的模型无法适应这些新常态,而我们的方法对这种分布变化表现出鲁棒性。 因此,之前的方法(Audibert et al. 2020;Shen, Li, and Kwok 2020)会由于模型无法跟上不断变化的动态而产生误报案例,从而“在世界发生变化时,模型停留在过去。” ”
我们的贡献可概括如下: • 我们发现新的正态问题对分布变化下的无监督时间序列异常检测建模提出了重大挑战。 • 我们根据时间序列数据的趋势估计提出了一种简单而有效的适应策略,并使用去趋势序列更新模型参数来解决这些问题。 • 通过对各种真实数据集进行广泛的实验,我们的方法在面临训练数据和测试数据之间严重的分布偏移问题时不断提高模型的性能。
二、Related Works
无监督时间序列异常检测。 无监督时间序列异常检测(Su et al. 2019;Audibert et al. 2020;Xu et al. 2022)旨在检测与正态性有很大偏差的观测值,假设不存在可用标签。 就传统的异常检测方法(Breunig et al. 2000;Schölkopf et al. 1999;Tax and Duin 1999)和基于深度学习的异常检测方法(Zong et al. 2018;Ruff et al. 2018)而言,无监督的时间- 系列异常检测模型旨在构建一个可以对序列的时间动态进行建模的架构。
无监督时间序列异常检测模型的主要类别包括基于重构的模型、基于聚类的模型和基于预测的模型。 基于正常实例比异常实例具有更好重建性能的假设,基于重建的模型涵盖了一系列涉及 LSTM 的方法(Malhotra 等人,2016 年;Park、Hoshi 和 Kemp,2018 年;Su 等人,2019 年)和 MLP (Audibert 等人,2020)架构,以及 GAN 的集成(Schlegl 等人,2017;Geiger 等人,2020;Han 等人,2021)。 基于聚类的方法包括一类支持向量机方法的扩展(Schölkopf et al. 1999;Tax and Duin 1999)、用于异常检测的基于张量分解的聚类方法(Shin et al. 2020)以及利用 聚类的潜在表示(Ruff et al. 2018;Shen、Li 和 Kwok 2020)。 基于预测的方法依赖于通过识别过去序列和真实标签之间的实质性偏差来检测异常,例如使用 ARIMA (Pena, de Assis, and Jr. 2013)、LSTM (Hundman et al. 2018) 和 Transformer (Xu) 等2022)。
时间序列数据的分布变化。 由于时间动态不断变化的性质,缓解分布变化成为时间序列数据分析中的一个关键问题,特别是在时间序列预测(Kim et al. 2022b;Liu et al. 2022)和异常等任务中 检测(Sankararaman 等人,2022 年;Dragoi 等人,2022 年)。
在线 RNN-AD(Saurav 等人,2018)通过 RNN 架构适应概念漂移,该架构使用所有流数据通过异常分数的反向传播来更新模型。 我们的工作与这项工作的不同之处在于引入了用于模型更新的去趋势模块,并以自我监督的方式选择性地学习一组正常实例。 尽管最近的工作(Sankararaman 等人,2022)也提出了一种用于异常检测的适应性框架,但它取决于应用于历史数据流的动态窗口机制。 值得注意的是,我们的方法不同于他们对过去序列的可访问性的假设; 我们将模型参数放在手边,立即处理输入序列,然后逐出。
测试时间适应。 为了减轻分布偏移引起的性能下降,无监督域适应(Ganin et al. 2016;Zou et al. 2018;Yoo,Chung,and Kwak 2022;Liang,Hu,and Feng 2020)方法已在各个领域得到发展。 从解决协变量偏移问题的角度来看,这些方法与我们的工作相一致。 近年来,出现了完全测试时间适应(TTA)(Wang et al. 2021)方法,通过在推理过程中使用未标记的测试样本进行实时适应来增强模型在测试数据上的性能,而不依赖于对训练数据的访问 。 大多数 TTA 方法采用熵最小化(Wang et al. 2021;Niu et al. 2022;Choi et al. 2022)或伪标签(Wang et al. 2022)来使用未标记的测试样本更新模型参数。 然而,简单地采用以前的TTA方法可能无法直接适用于无监督的时间序列异常检测。 这是由于使用所有测试样本更新模型时模型存在漏洞,因为异常测试样本有可能破坏其功能。 因此,这项工作旨在成功地将测试时间适应的概念应用于无监督时间序列异常检测任务。
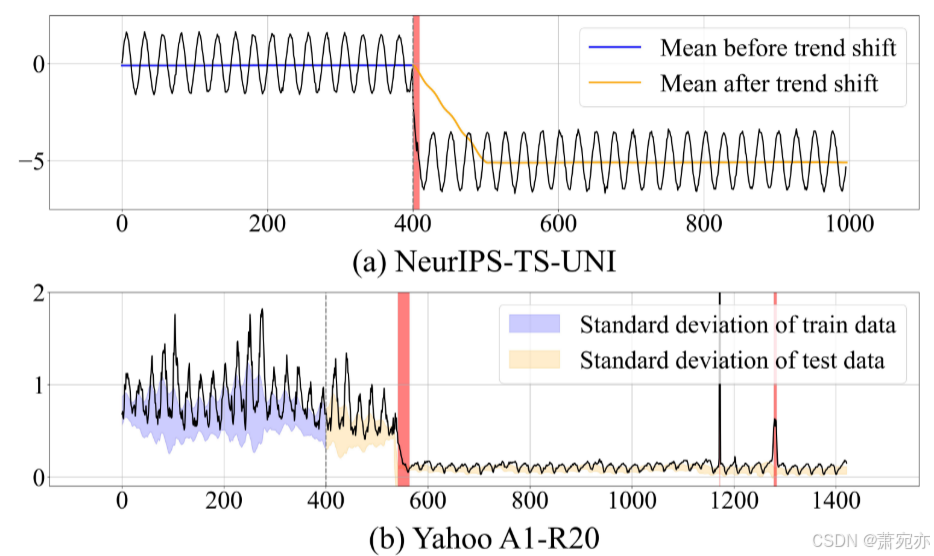
图 2:说明估计趋势和测试时间适应的必要性。 (a) NeurIPS-TS-UNI 显示了基于先前工作(Lai 等人,2021)生成的合成数据,揭示了趋势的突然转变,同时保留了潜在的动态。 趋势估计模块的目标是成功适应这种趋势转变。 (b) 仅依靠趋势估计可能不足以充分捕捉动态,正如 Yahoo-A1-R20 系列所证明的那样。 紫色和黄色阴影区域分别代表训练数据和测试数据的标准偏差。 为了对这种动态变化进行建模(仅通过趋势估计无法完全捕获这种变化),有必要通过直接概述的测试时模型更新来学习分布变化。
三、 Method
Problem Statement
无监督时间序列异常检测旨在通过学习正态性的概念,在没有明确监督的情况下检测测试时间内的异常时间步长。 正态性的概念被定义为数据 D 上的概率分布 P,它是给定任务中正常行为的基本事实法则 (Ruff et al. 2021)。 因此,一组异常被定义为在这种分布下具有足够小的概率的数据,即 p(x) < ϵ。 我们解决的新正态问题可以表述为基础分布 P 不平稳的现象,即 P t r a i n ≠ P t e s t \mathbb{P}_{train}\neq\mathbb{P}_{test} Ptrain=Ptest。
对于具有 F 个特征的 N 个时间步长的观察,时间序列数据由序列 D = { X 1 , X 2 , . . . , X N } \mathcal{D}=\{X_{1},X_{2},...,X_{N}\} D={X1,X2,...,XN} 指定,其中每个 X i ∈ R F X_{i}\in\mathbb{R}^{F} Xi∈RF。 异常检测器旨在将每个观察结果映射到类标签 y = {0, 1},其中 y = 0 和 y = 1 分别表示正常和异常时间步长。 检测器由异常评分函数 A : R F → R \mathcal{A} : \mathbb{R}^F \to \mathbb{R} A:RF→R 以及决策阈值 τ 指定。 具体来说,如果 A ( X t ) > τ \mathcal{A}(X_{t}) > \tau A(Xt)>τ,则观测值 X t X_t Xt 被分类为异常。 我们将训练时间实例集表示为 Dtrain,将测试时间实例集表示为 Dtest。 因此,测试时间正常值和异常值可以各自定义为 { X ∈ D t e s t ∣ y = 0 } \{X\in\mathcal{D}_{test}\mid y=0\} {X∈Dtest∣y=0} 且 { X ∈ D t r i a n ∣ y = 1 } \{X\in\mathcal{D}_{trian}\mid y=1\} {X∈Dtrian∣y=1}。
为了反映时间序列数据的时间上下文以检测异常时间步长,使用滑动窗口设置对一组观测值 D 进行预处理。 具体来说,我们将时间步 t 之前的 w 个观测值序列表示为 X w , t = [ X t − w + 1 , X t − w + 2 , . . . , X t − 1 , X t ] \mathcal{X}_{w,t} = [X_{t-w+1},X_{t-w+2},...,X_{t-1},X_{t}] Xw,t=[Xt−w+1,Xt−w+2,...,Xt−1,Xt]及其相应的类标签和模型的预测 为 Y w , t = [ y t − w + 1 , y t − w + 2 , . . . , y t − 1 , y t ] \mathcal{Y}_{w,t} = [y_{t-w+1},y_{t-w+2},...,y_{t-1},y_t] Yw,t=[yt−w+1,yt−w+2,...,yt−1,yt]且 Y ^ w , t \hat{\mathcal{Y}}_{w,t} Y^w,t= [ y ^ t − w + 1 , y ^ t − w + 2 , . . . , y ^ t − 1 , y ^ t ] [\hat{y}_{t-w+1},\hat{y}_{t-w+2},...,\hat{y}_{t-1},\hat{y}_{t}] [y^t−w+1,y^t−w+2,...,y^t−1,y^t]遵循时间序列异常检测文献的传统方法(Shen、Li 和 Kwok 2020;Su 等人 2019)。
Input Normalization Using Trend Estimate
趋势估计模块旨在适应趋势显着不同的新常态,同时保留序列的基本动态。 因此,之前的工作 (Lai et al. 2021) 将趋势异常值定义为: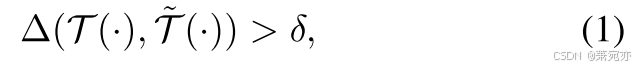
其中 Δ 是衡量两个函数之间差异的函数。 T ~ \tilde{\mathcal{T}} T~是一个返回正常序列趋势的函数。 T {\mathcal{T}} T 是任意序列的趋势,用于与正常序列的趋势进行比较。 图 2-(a) 说明了正确估计正态性趋势的重要性。 尽管转变之前和之后的序列具有相同的动态,但趋势转变后的观察结果被归类为异常,而没有适当适应趋势。 为了解决这个问题,我们简单地使用指数移动平均统计数据来进行趋势估计。 从技术上讲,我们估计趋势为: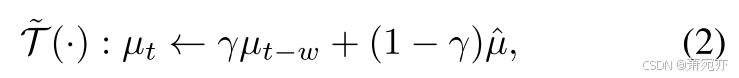
其中 μ ^ = 1 w Σ i = t − w + 1 t X i \hat{\mu} = \frac{1}{w}\Sigma_{i=t-w+1}^tX_i μ^=w1Σi=t−w+1tXi,这是流数据的经验平均值,γ 是一个超参数,控制指数移动平均更新率以跟踪数据流的趋势。 此过程是通过均值调整消除非平稳趋势分量的一种形式(Shumway 和 Stoffer 2017),允许模型以数值稳定性进行更新。 具体而言,如图 3 所示,与基于重建的异常检测模型一起,该模型重建去趋势序列 X w , t − μ t \mathcal{X}_{w,t}-\mu_t Xw,t−μt而不是 X w , t \mathcal{X}_{w,t} Xw,t,并通过添加最终输出的估计趋势来对重建序列进行反规范化。
Model Update with New Normals
模型更新的测试时间适应旨在了解时间序列数据的潜在动态,仅通过趋势估计无法完全捕获这些动态,如图 2-(b) 所示。 具体来说,我们的方法在测试期间以完全无监督的方式不断更新具有正常序列的模型参数。 形式上,测试时观察期间的正常实例可以表示为 {X ∈ Dtest | y = 0}。 为了在测试期间更新模型参数 θ,模型本身的预测 V ^ \hat{\mathcal{V}} V^ 充当过滤正常时间步长的选择标准。 该模型使用以下方案基于在线梯度下降(Zinkevich 2003)进行更新: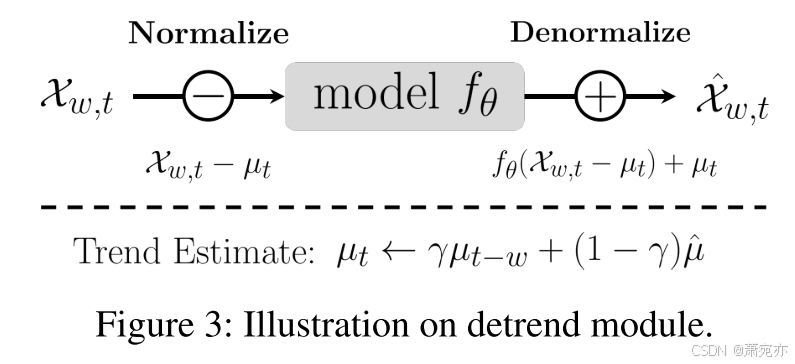
其中 η 是模型更新的测试时学习率。 τ 表示对异常时间步进行分类的阈值。 具体来说,我们的方法使用自动编码器架构和重建损失。 因此,上述更新方案可以进一步描述为:
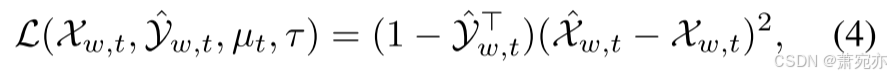
其中 X ^ w , t \hat{\mathcal{X}}_{w,t} X^w,t表示模型的重构输出, Y ^ w , t \hat{\mathcal{Y}}_{w,t} Y^w,t表示预测标签,其中 0 和 1 分别表示正常和异常。
尽管我们利用整个时间序列数据进行趋势估计,但我们仅结合正常实例来根据模型的预测更新模型。 该策略背后的基本原理源于这样的假设:在模型部署之前使用正常数据训练无监督异常检测器。 因此,在测试期间包含用于模型更新的异常样本可能会对模型的性能产生不利影响。 相反,为了即使在变化很大的场景中也能进行趋势估计,必须合并可能被异常检测器预测为异常的正常实例。
四、Experiments
Experiment Setups
数据集。 我们根据以下标准选择实验数据集:(i) 时间序列异常检测文献 (SWaT) 中广泛使用的数据集,(ii) 与常用数据集(SMD、MSL、SMAP)相比具有显着分布变化的子集,(iii) ) 包括大量分布变化的数据集(WADI、Yahoo),(iv) 具有最小分布变化的数据集(CreditCard)。
我们使用的现实世界数据集的描述如下。 (1) SWaT(Mathur 和 Tippenhauer 2016)和 WADI 1 由从水处理系统测试台收集的测量值组成。 SWaT 数据集涵盖 51 个传感器 11 天的测量,而 WADI 数据集涵盖 123 个传感器 16 天的测量。 (2) SMD 数据集 (Su et al. 2019) 包括来自 28 个不同服务器机器的 5 周数据,这些服务器具有 38 维传感器输入。 在实验中,由于分布转移问题,选择了两台特定的服务器机器(机器 1-4 和机器 2-1)。 (3) SMAP 和 MSL (Hundman et al. 2018) 数据集来自航天器监测系统。 SMAP 数据集包含来自 28 台独特机器(具有 55 个遥测通道)的监控数据,而 MSL 数据集包含来自 19 台独特机器(具有 27 个遥测通道)的数据。 我们的实验选择了来自两台具有分布偏移的特定机器 MSL (P-15) 和 SMAP (T-3) 的数据。 (4) 信用卡数据集 2 由两天的交易日志组成。 它包含 28 个 PCA 匿名功能以及时间和交易金额信息。 (5) Yahoo 数据集 3 是真实数据集 (A1) 和合成数据集 (A2、A3、A4) 的组合。 Yahoo-A1 数据集包含 67 个单变量现实世界数据集,特别关注表现出分布偏移问题的两个数据集(A1-R20 和 A1-R55)。 数据集的更多详细信息和主要统计数据可以在补充材料中找到。
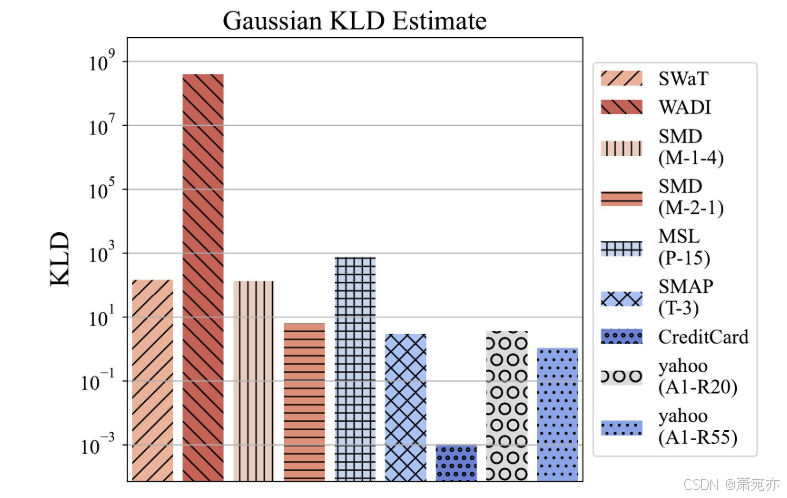
图 4:各种数据集的 Kullback-Leibler 散度 (KLD)。 给出了 DKL(Dtest||Dtrain),这意味着在给定 Dtrain 的情况下,需要多少附加信息才能完全描述 Dtest。 该度量量化了数据集的分布偏移问题。
基线。 我们将我们的方法与 5 个基线进行比较:基于 MLP 的自动编码器 (MLP)、LSTMencDec (LSTM) (Malhotra et al. 2016)、USAD (Audibert et al. 2020)、THOC (Shen、Li 和 Kwok 2020) 和异常转换器 (AT)(Xu 等人,2022)。 根据每篇论文的描述重新实现了LSTM、USAD和THOC。 我们的实验中使用了异常转换器4的官方实现。我们使用他们论文中描述的THOC、USAD和AT的超参数和默认设置。 MLP 和 LSTM 默认使用潜在维度 128。 由于所有方法都是完全无监督的,我们在训练数据集正态性的假设下训练了所有模型。 在测试期间,我们的方法获取 w 个非重叠窗口的输入,该输入与训练时间窗口大小相同。 超参数的详细信息可以在补充中找到。 评估指标。 我们报告了一种称为 F1-PA 的指标(Xu 等人,2018 年),该指标在最近的时间序列异常检测研究中广泛使用(Xu 等人,2022 年;Shen、Li 和 Kwok,2020 年;Audibert 等人,2020 年;Su 等人) 等2019)。 如果片段中的任何时间步被分类为异常,则该度量将整个连续异常片段视为已正确检测到。 请注意,F1-PA 指标高估了分类器性能(Kim 等人,2022a),尽管该指标具有实际合理性(Xu 等人,2018 年)。
因此,我们考虑三个额外的评估指标,即F1分数、受试者工作特征曲线下面积(AUROC)和精确回忆曲线下面积(AUPRC)。 与F1-PA不同,F1分数可以衡量每个单独时间步的异常检测状态,这直接反映了异常检测器的性能。 我们还报告了测试数据异常分数的 AUROC 和 AUPRC,它给出了所有可能的阈值 τ 候选者的异常检测器性能的总体总结。 AUROC 考虑了所有可能的决策阈值的性能,使其对特定阈值的选择不太敏感。 我们测量 AUPRC,它非常适合不平衡的分类场景(Saito 和 Rehmsmeier 2015;Sørbø 和 Ruocco 2023)。 为简洁起见,我们在主论文中报告了这四个指标。 补充材料中提供了调整后和未调整指标的其他指标,包括准确度、精确度、召回率、F1 和混淆矩阵(真阴性、假阳性、假阴性和真阳性的数量)。
Comparison with Baselines
主要结果。 为了验证我们方法的有效性,我们对无监督时间序列异常检测模型和结合我们方法的 MLP 模型进行了比较分析。 如表 1 所示,结果表明我们的方法在各种评估指标上持续提高了 MLP 模型的性能。 值得注意的是,我们在 WADI 数据集的 AUROC 中实现了高达 13% 的显着改进,在 MSL (P-15) 的 AUPRC 中实现了 51% 的显着改进,这表现出了如图 4 所示的分布偏移问题。 雅虎 A1R20 数据集,如图 2-(b) 所示,我们的方法在 F1 分数方面展示了最高的性能增益。 与大多数数据集相比,我们的方法在信用卡数据集中仅显示出微小的改进。
这是由于数据集存在最小分布偏移问题,导致性能增益有限。 与现成基线相比,表现出较低 F1 性能的数据集是 WADI。 这种差异是由于测试异常分数的阈值设置造成的。 具体来说,使用 USAD 模型的 WADI 列车数据的最大异常分数为 0.225,而生成表中报告的 F1 分数的阈值是 585.845,明显更高。 因此,尽管 USAD 和 LSTM 模型在 F1 方面表现出较高的分数,但 AUROC 测量的整体分类器性能较低。
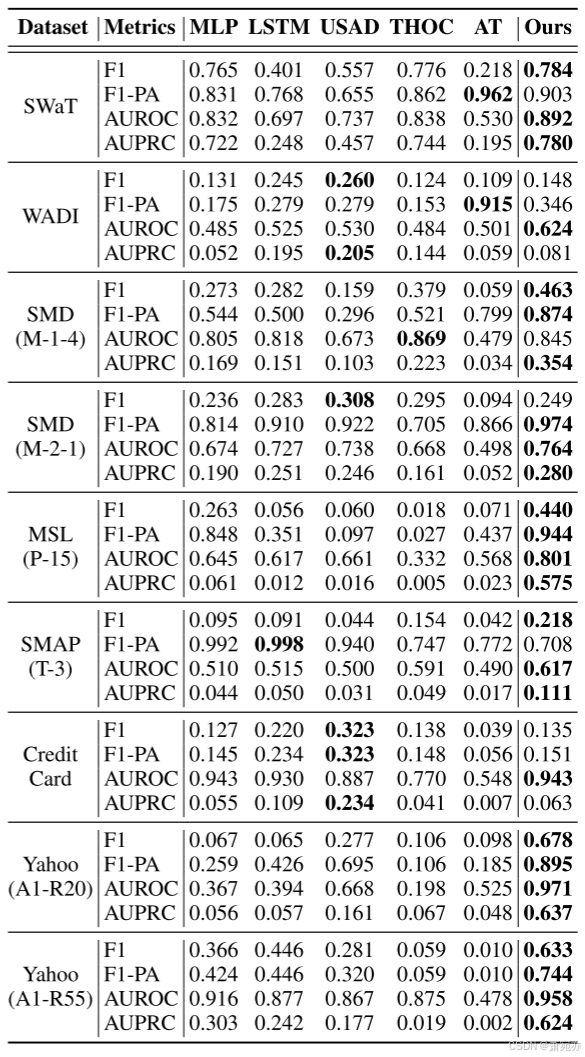
表 1:与现有基线的比较。 所有结果均基于五次独立试验。 该表报告了每个指标五次试验的平均值。 补充材料中报告了带有置信区间的完整结果。
此外,我们将我们的方法与最先进的方法之一异常变压器(AT)进行了比较。 虽然 AT 在 F1-PA 方面表现出相当的性能,但在 F1 分数、AUROC 和 AUPRC 方面却有所不足。 出现这种差异的原因是异常转换器以一定的间隔生成正预测,而不是指定异常点的确切时刻。 基线测试时间异常分数的详细信息在补充报告中报告。 ROC 和 Precision-Recall 曲线分析。 我们的方法在除 SMD (M-1-4) 之外的所有数据集上的 AUROC 方面始终优于以前的方法,在除 WADI 和 Creditcard 之外的所有数据集上的 AUPRC 方面,我们的方法始终优于以前的方法。 这表明以前的现成基线对阈值设置很敏感,这对难以找到最佳阈值的现实场景中的鲁棒性提出了挑战。 图 5 显示了我们方法的接收者操作曲线(ROC 曲线)和精确回忆曲线以及基线的可视化。 一致地,对于两者,我们的方法(红色)显着改善了现成的分类器结果(蓝色)。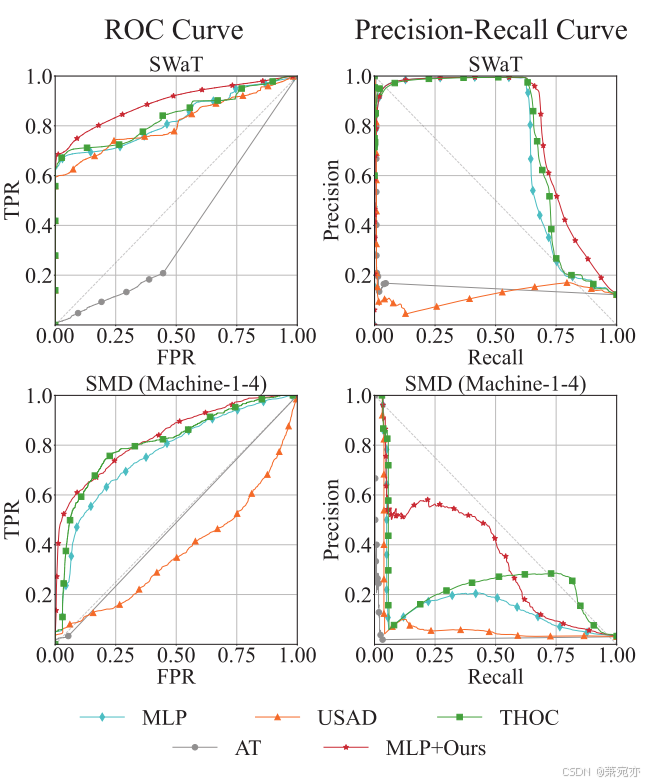
图 5:ROC 曲线(左)精确召回曲线(右)基线和 MLP+Ours 的可视化。
Results on AnoShift Benchmark
AnoShift 基准(Dragoi 等人,2022)为分布偏移问题下异常检测算法的鲁棒性提供了一个测试平台。 该数据集跨越十年,分为涵盖 2006-2010 年期间的训练集和两个不同的测试集,分别表示为 NEAR (2011-2013) 和 FAR (2014-2015)。 如图 6-(a) 所示,随着时间的推移,数据分布逐渐偏离训练集。 AnoShift 基准评估的主要目标是研究我们提出的算法针对此类分布变化的有效性。 评估需要三个指标,即接收者操作特征曲线下面积 (AUROC)、以异常值作为正类的精确召回曲线下面积 (AUPRC-in) 和以异常值作为正类的精确召回曲线下面积 继之前的工作之后,正类(AUPRC-out)(Dragoi et al. 2022)。 我们的方法的性能与其他基于深度学习的基线进行了比较,包括 SO-GAAL (Liu et al. 2020)、deepSVDD (Ruff et al. 2018)、LUNAR (Goodge et al. 2022)、ICL (Shenkar and Wolf 2022),BERT(Devlin 等人 2019)用于异常。
表 2 表明,当我们的方法集成到基于 MLP 的自动编码器中时,性能显着提高,AUROC 增加高达 0.216 就证明了这一点。 尽管很简单,但我们的方法显着增强了基线 MLP 性能,而之前的 MLP 性能较差。 这种改进在 FAR 分割中尤其重要,与 NEAR 分割相比,FAR 分割会带来严重的分布偏移问题。 虽然我们的实验侧重于 MLP,但值得注意的是我们的模块可以无缝添加到其他基线。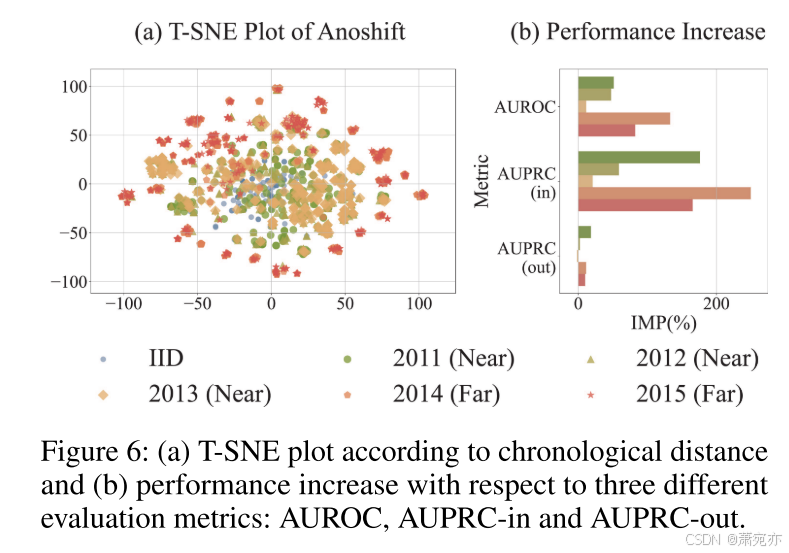
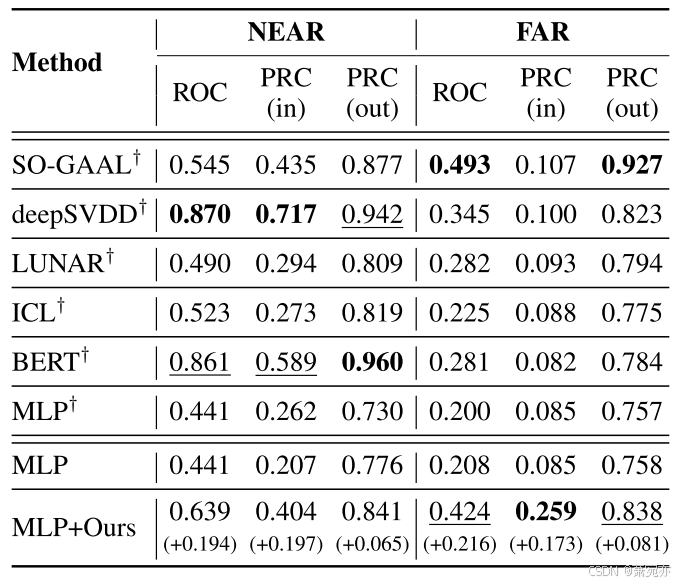
表 2:Anoshift 基准测试的性能。 † 表示指标是根据原始论文的结果报告的。 AUROC和AUPRC分别表示为ROC和PRC。
Ablation Study
如表 3 所示,我们对我们的方法进行了消融研究,以分析每个组件的有效性。 与单独使用(MLP+DT、MLP+TTA)和不使用(MLP)的情况相比,具有去趋势模块的 MLP 以及模型更新的测试时间自适应始终显示出更好的结果。 这里,DT和TTA分别表示去趋势模块和模型更新的测试时间适应。 此外,图 7 还表明,当选择适当的阈值时,使用我们的完整方法的 MLP 模型始终优于这些基线,包括现成的 MLP 模型的最佳性能。 这种行为可以在图 8-(a) 中进一步描述,同时说明这四个选项。 (1) 与现成的 MLP(蓝色)相比,我们的方法(红色)显示出更好的重建效果。 即使在总体趋势转变之后,现成的 MLP 模型也会不断产生重建误差,从而导致许多误报情况。 (2) 此外,单独的去趋势模块无法检测异常,与我们的方法相比,其灵敏度较低,尽管它们共享相同的 EMA 参数 γ。 这表明模型更新可以提高异常检测器的灵敏度,因为它会根据最近的观察结果不断更新。 (3) 如果没有正确更新这种趋势估计,仅通过模型更新进行测试时适应(绿色)可能会损害模型的稳健性,因为它可能会过度拟合趋势转变之前的序列,缺乏适应新趋势的能力 即将到来的序列。
 表 3:我们提出的方法的消融研究。 DT 和 TTA 分别表示去趋势模块和测试时间自适应。
表 3:我们提出的方法的消融研究。 DT 和 TTA 分别表示去趋势模块和测试时间自适应。
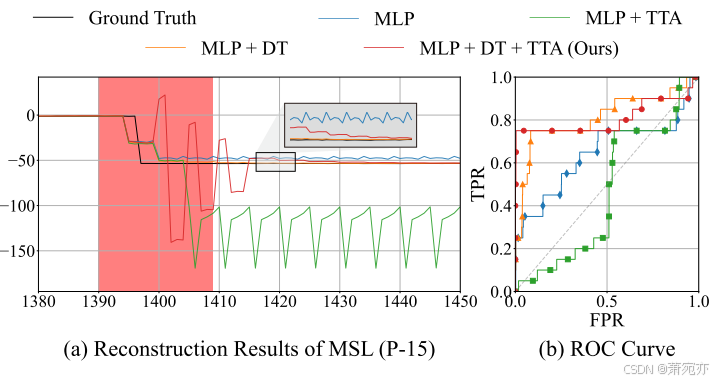
图 8:使用 MSL (P-15) 数据集对所提出的方法进行消融研究
Discussion and Limitation
异常检测阈值。 现有的无监督时间序列异常检测研究(Audibert et al. 2020;Xu et al. 2022)有一个主要局限性,因为它们通过推断整个测试数据并根据最佳性能进行选择来确定正态性阈值。 然而,这种方法在现实场景中实际上并不可行。 因此,我们报告 AUROC 来评估整体性能,并根据实验中的训练数据统计来确定阈值。 我们认为通过适当选择阈值可以进一步增强异常检测器的性能。
异常检测中的标签不一致。 在时间序列异常检测任务中,每个场景的异常标准各不相同,因此很难建立一致的标签。 因此,区分训练集中与正常样本存在显着差异的测试样本是异常样本还是具有分布变化的正态样本是具有挑战性的。 在我们的例子中,基于测试集中有更多正常实例的假设,我们采用趋势估计和模型预测来进行测试时间适应。 为了提高适应性能,采用主动学习(Ren et al. 2021),其中人类注释者为测试数据子集提供标签可能是一个有价值的研究方向。
Conclusion
在这项工作中,我们强调了无监督时间序列异常检测中的分布偏移问题。 我们已经表明,常态的概念可能会随着时间而改变。 这对于设计强大的时间序列异常检测框架来说可能是一个重大挑战,导致许多误报,从而损害系统的一致性。 为了缓解这个问题,我们提出了一种简单而有效的策略,通过遵循趋势估计和测试时间适应,将新常态纳入模型架构中。 具体来说,我们的方法始终优于具有此类问题的现实世界基准的标准基线。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)