PPO、GRPO、DAPO
公式(3)是时间拆分误差(Temporal Difference Error, TD Error)的数学表达式,常用于强化学习(Reinforcement Learning)中的值函数更新(如 TD-Learning 或 TD(λ) 算法)。详细解释如下:以一个例子来理解TD ErrorGRPO对PPO的改进如下:1)消除值函数,以组相对的方式计算优势(①为一个Prompt生成多个输出序列,②为这
参考他人知乎文章:https://zhuanlan.zhihu.com/p/1888273347013506911
https://zhuanlan.zhihu.com/p/1888273347013506911
1. PPO (近端策略优化)

公式(3)是时间拆分误差(Temporal Difference Error, TD Error)的数学表达式,常用于强化学习(Reinforcement Learning)中的值函数更新(如 TD-Learning 或 TD(λ) 算法)。详细解释如下:

以一个例子来理解TD Error



2. GRPO(组相对策略优化)

GRPO对PPO的改进如下:
1)消除值函数,以组相对的方式计算优势(①为一个Prompt生成多个输出序列,②为这些输出序列打分,③计算这些序列分值的均值、标准差,④做归一化即得到每个序列的优势。);
2)将kl散度相应的内容加入到目标函数中,而不是在条件上;
3. DAPO(解耦剪切和动态采样策略优化)
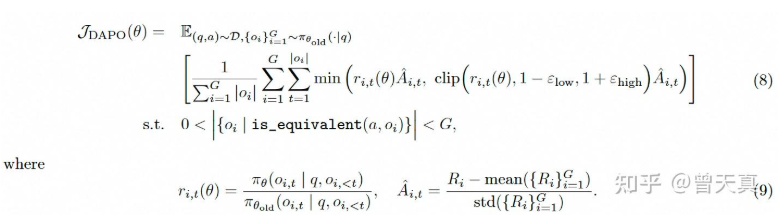
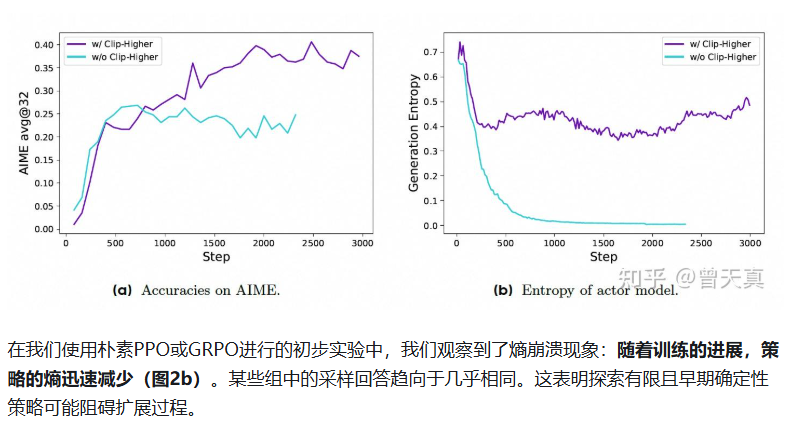
3.1 改进一、提高剪切值(通过非对称剪切调整,提高熵增)
解决方案:

关于提高剪切值,熵增加还是下降,deepseek的回答:

3.2 改进二、动态采样
对于GRPO,如果某个特定提示的所有输出都是正确的并且获得相同的奖励1,则该组的优势为零。零优势导致没有用于策略更新的梯度,从而降低了样本效率。

3.3 改进三、逐token策略梯度损失
原始的GRPO算法采用样本级损失计算,涉及首先在每个样本内按Token平均损失,然后跨样本聚合损失。在这种方法中,每个样本在最终损失计算中分配相等的权重。

由于所有样本在损失计算中分配相等的权重,较长响应中的Token对整体损失的贡献不成比例地较低,这可能导致两个不利影响。
1)对于高质量的长样本,这种效应可能会阻碍模型学习它们内部的相关推理模式。
2)过长的样本通常表现出低质量模式,如乱码和重复单词。因此,样本级损失计算由于无法有效惩罚长样本中的这些不期望模式,导致错误学习

采用了改进方法后,对所有的G个生成序列做归一化,避免长短序列对梯度贡献相同,无法惩罚长序列暴漏出的问题(如乱码和重复单词)。而在GRPO中,对每个序列做归一化,即除以序列长度,然后再聚合G个序列的损失,导致长短序列对梯度的贡献相同。两种例子展示如下,其中公式1(全局)是DPAO,公式2(逐序列)是GRPO。

3.4 改进四、过长奖励重塑(软过长惩罚(Soft Overlong Punishment))
在强化学习训练中,我们通常会设置生成的最大长度,并相应地截断过长的样本。我们发现,对于截断样本的不适当奖励塑形会引入奖励噪声,并显著扰乱训练过程。
提出软过长惩罚(Soft Overlong Punishment),旨在塑造截断样本的奖励。具体而言,当响应长度超过预定义的最大值时,我们定义了一个惩罚区间。在这个区间内,响应越长,它受到的惩罚就越大。这个惩罚被添加到原来的基于规则的正确性奖励中,从而向模型发出信号,避免过长的响应。
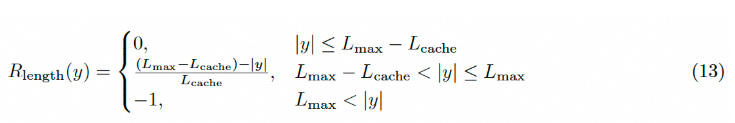

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)