使用 A2A 协议和 MCP 在 Elasticsearch 中创建一个 LLM agent 新闻室:第二部分
摘要 本文介绍了在Elasticsearch环境中使用A2A协议和MCP架构构建LLM代理新闻室的实际应用。文章展示了新闻室工作流中代理间的协作过程:从选题分配到文章撰写、审核和发布的全流程。通过混合架构设计,A2A负责代理间协调,MCP提供工具访问能力,实现了灵活性与标准化的结合。配套代码仓库提供了实际运行示例,包括代理间消息传递和工具调用的详细实现。这种混合方法既保留了多代理系统的组织优势,又
作者:来自 Elastic Justin Castilla

Agent Builder 现在作为技术预览版提供。使用 Elastic Cloud 试用即可开始,并在这里查看 Agent Builder 文档。
A2A 和 MCP:代码实战
这是文章 “在 Elasticsearch 中使用 A2A 协议和 MCP 创建一个 LLM agent 新闻室” 的配套内容,该文章解释了在同一个 agent 中同时实现 A2A 和 MCP 架构以真正获得两个框架独特优势的好处。我们也提供了一个代码仓库,方便你自己运行这个演示。
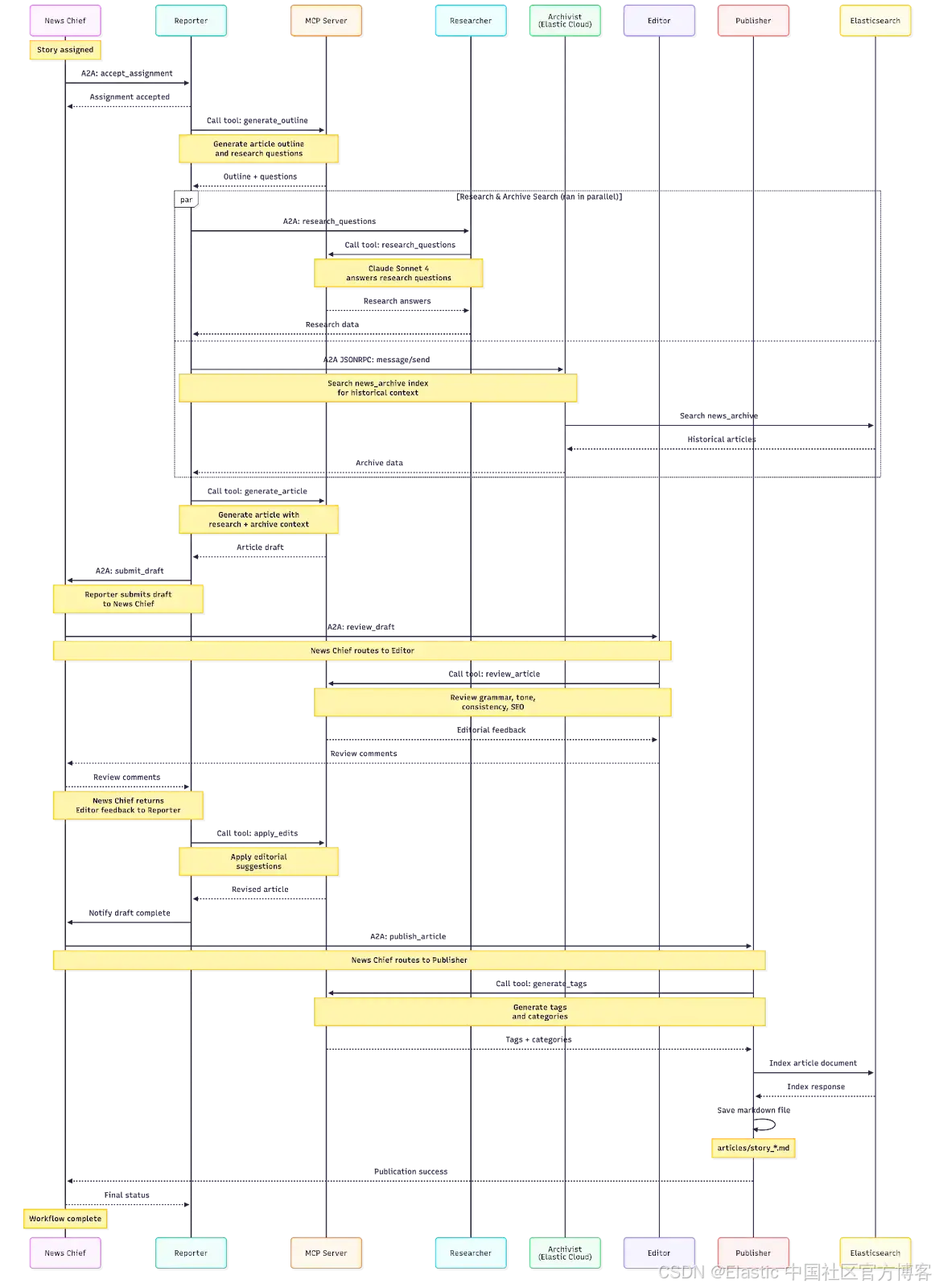
让我们来看看新闻室的 agent 如何同时使用 A2A 和 MCP 协作完成一篇新闻文章。你可以在这里找到配套的代码仓库,查看这些 agent 的实际运作。
步骤 1:选题分配
新闻主管(作为 client)分配一个选题:
{
"message_type": "task_request",
"sender": "news_chief",
"receiver": "reporter_agent",
"payload": {
"task_id": "story_renewable_energy_2024",
"assignment": {
"topic": "Renewable Energy Adoption in Europe",
"angle": "Policy changes driving solar and wind expansion",
"target_length": 1200,
"deadline": "2025-09-30T18:00:00Z"
}
}
}步骤 2:记者请求调研
Reporter agent 发现它需要背景信息,并通过 A2A 将任务委派给 Researcher agent:
{
"message_type": "task_request",
"sender": "reporter_agent",
"receiver": "researcher_agent",
"payload": {
"task_id": "research_eu_renewable_2024",
"parent_task_id": "story_renewable_energy_2024",
"capability": "fact_gathering",
"parameters": {
"queries": [
"EU renewable energy capacity 2024",
"Solar installations growth Europe",
"Wind energy policy changes 2024"
],
"depth": "comprehensive"
}
}
}步骤 3:记者向 Archive agent 请求历史背景
Reporter agent 意识到历史背景会强化报道。它通过 A2A 将任务委派给由 Elastic 的 A2A agent 驱动的 Archive agent,在新闻室的 Elasticsearch 驱动文章档案中进行搜索:
{
"message_type": "task_request",
"sender": "reporter_agent",
"receiver": "archive_agent",
"payload": {
"task_id": "archive_search_renewable_2024",
"parent_task_id": "story_renewable_energy_2024",
"capability": "search_archive",
"parameters": {
"query": "European renewable energy policy changes and adoption trends over past 5 years",
"focus_areas": ["solar", "wind", "policy", "Germany", "France"],
"time_range": "2019-2024",
"result_count": 10
}
}
}步骤 4:Archive agent 使用带 MCP 的 Elastic A2A agent
Archive agent 使用 Elastic 的 A2A agent,而这个 A2A agent 又使用 MCP 来访问 Elasticsearch 工具。这个过程展示了混合架构:A2A 负责 agent 协作,而 MCP 提供工具访问:
# Archive Agent using Elastic A2A Agent
async def search_historical_articles(self, query_params):
# The Archive Agent sends a request to Elastic's A2A Agent
elastic_response = await self.a2a_client.send_request(
agent="elastic_agent",
capability="search_and_analyze",
parameters={
"natural_language_query": query_params["query"],
"index_pattern": "newsroom-articles-*",
"filters": {
"topics": query_params["focus_areas"],
"date_range": query_params["time_range"]
},
"analysis_type": "trend_analysis"
}
)
# Elastic's A2A Agent internally uses MCP tools:
# - platform.core.search (to find relevant articles)
# - platform.core.generate_esql (to analyze trends)
# - platform.core.index_explorer (to identify relevant indices)
return elastic_responseArchive agent 从 Elastic 的 A2A agent 收到全面的历史数据,并将其返回给 Reporter:
{
"message_type": "task_response",
"sender": "archive_agent",
"receiver": "reporter_agent",
"payload": {
"task_id": "archive_search_renewable_2024",
"status": "completed",
"archive_data": {
"historical_articles": [
{
"title": "Germany's Energiewende: Five Years of Solar Growth",
"published": "2022-06-15",
"key_points": [
"Germany added 7 GW annually 2020-2022",
"Policy subsidies drove 60% of growth"
],
"relevance_score": 0.94
},
{
"title": "France Balances Nuclear and Renewables",
"published": "2023-03-20",
"key_points": [
"France increased renewable target to 40% by 2030",
"Solar capacity doubled 2021-2023"
],
"relevance_score": 0.89
}
],
"trend_analysis": {
"coverage_frequency": "EU renewable stories increased 150% since 2019",
"emerging_themes": ["policy incentives", "grid modernization", "battery storage"],
"coverage_gaps": ["Small member states", "offshore wind permitting"]
},
"total_articles_found": 47,
"search_confidence": 0.91
}
}
}这一步展示了 Elastic 的 A2A agent 是如何融入新闻室工作流的。Archive agent(新闻室的专用 agent)与 Elastic 的 A2A agent(第三方专家)协作,从而利用 Elasticsearch 强大的搜索和分析能力。Elastic 的 agent 在内部使用 MCP 来访问 Elasticsearch 工具,体现了 agent 协作(A2A)与工具访问(MCP)之间清晰的分离。
步骤 5:Researcher 使用 MCP 服务器
Researcher agent 访问多个 MCP 服务器来收集信息:
# Researcher Agent using MCP to access tools
async def gather_facts(self, queries):
results = []
# Use News API MCP Server
news_data = await self.mcp_client.invoke_tool(
server="news_api_mcp",
tool="search_articles",
parameters={
"query": queries[0],
"date_range": "2024-01-01 to 2024-09-30",
"sources": ["reuters", "bloomberg", "euractiv"]
}
)
# Use Statistics MCP Server
stats_data = await self.mcp_client.invoke_tool(
server="eurostat_mcp",
tool="get_energy_statistics",
parameters={
"metrics": ["solar_capacity_mw", "wind_capacity_mw"],
"countries": ["EU27"],
"year": 2024
}
)
# Use Fact-Checking MCP Server
verified_facts = await self.mcp_client.invoke_tool(
server="factcheck_mcp",
tool="verify_claims",
parameters={
"claims": [
"EU solar capacity increased 40% in 2024",
"Germany leads in wind installations"
]
}
)
return self._synthesize_research(news_data, stats_data, verified_facts)步骤 6:Researcher 将数据返回给 Reporter
Researcher agent 通过 A2A 将完整的调研结果发回:
{
"message_type": "task_response",
"sender": "researcher_agent",
"receiver": "reporter_agent",
"payload": {
"task_id": "research_eu_renewable_2024",
"status": "completed",
"research_data": {
"key_facts": [
{
"claim": "EU solar capacity reached 260 GW in 2024",
"source": "Eurostat Q3 2024 Report",
"confidence": 0.95,
"verified": true
},
{
"claim": "Germany installed 12 GW of wind capacity in 2024",
"source": "German Federal Network Agency",
"confidence": 0.92,
"verified": true
}
],
"statistics": {
"solar_growth_rate": "35%",
"wind_growth_rate": "28%"
},
"sources_count": 15
}
}
}步骤 7:Reporter 撰写文章
Reporter agent 使用调研数据和自身的 LLM 能力来撰写文章。在写作过程中,Reporter 使用 MCP 服务器来获取风格和模板:
# Reporter Agent writing with MCP assistance
async def write_article(self, research_data, assignment):
# Get style guidelines via MCP
style_guide = await self.mcp_client.get_resource(
server="newsroom_mcp",
resource="style://editorial/ap_style_guide"
)
# Get article template via MCP
template = await self.mcp_client.get_resource(
server="newsroom_mcp",
resource="template://articles/news_story"
)
# Generate article using LLM + research + style
draft = await self.llm.generate(
prompt=f"""
Write a news article following these guidelines:
{style_guide}
Using this template:
{template}
Based on this research:
{research_data}
Assignment: {assignment}
"""
)
# Self-evaluate confidence in claims
confidence_check = await self._evaluate_confidence(draft)
return draft, confidence_check步骤 8:低置信度触发重新调研
Reporter agent 评估其草稿后发现有一个观点置信度较低。它向 Researcher agent 发送另一个请求:
{
"message_type": "collaboration_request",
"sender": "reporter_agent",
"receiver": "researcher_agent",
"payload": {
"request_type": "fact_verification",
"claims": [
{
"text": "France's nuclear phase-down contributed to 15% increase in renewable capacity",
"context": "Discussing policy drivers for renewable growth",
"current_confidence": 0.45,
"required_confidence": 0.80
}
],
"urgency": "high"
}
}Researcher 使用 fact-checking MCP 服务器验证该观点,并返回更新的信息:
{
"message_type": "collaboration_response",
"sender": "researcher_agent",
"receiver": "reporter_agent",
"payload": {
"verified_claims": [
{
"original_claim": "France's nuclear phase-down contributed to 15% increase...",
"verified_claim": "France's renewable capacity increased 18% in 2024, partially offsetting reduced nuclear output",
"confidence": 0.88,
"corrections": "Percentage was 18%, not 15%; nuclear phase-down is gradual, not primary driver",
"sources": ["RTE France", "French Energy Ministry Report 2024"]
}
]
}
}步骤 9:Reporter 修改并提交给 Editor
Reporter 将已验证的事实纳入文章,并通过 A2A 将完成的草稿发送给 Editor agent:
{
"message_type": "task_request",
"sender": "reporter_agent",
"receiver": "editor_agent",
"payload": {
"task_id": "edit_renewable_story",
"parent_task_id": "story_renewable_energy_2024",
"content": {
"headline": "Europe's Renewable Revolution: Solar and Wind Surge 30% in 2024",
"body": "[Full article text...]",
"word_count": 1185,
"sources": [/* array of sources */]
},
"editing_requirements": {
"check_style": true,
"check_facts": true,
"check_seo": true
}
}
}步骤 10:Editor 使用 MCP 工具进行审核
Editor agent 使用多个 MCP 服务器来审核文章:
# Editor Agent using MCP for quality checks
async def review_article(self, content):
# Grammar and style check
grammar_issues = await self.mcp_client.invoke_tool(
server="grammarly_mcp",
tool="check_document",
parameters={"text": content["body"]}
)
# SEO optimization check
seo_analysis = await self.mcp_client.invoke_tool(
server="seo_mcp",
tool="analyze_content",
parameters={
"headline": content["headline"],
"body": content["body"],
"target_keywords": ["renewable energy", "Europe", "solar", "wind"]
}
)
# Plagiarism check
originality = await self.mcp_client.invoke_tool(
server="plagiarism_mcp",
tool="check_originality",
parameters={"text": content["body"]}
)
# Generate editorial feedback
feedback = await self._generate_feedback(
grammar_issues,
seo_analysis,
originality
)
return feedbackEditor 批准文章并将其发送出去:
{
"message_type": "task_response",
"sender": "editor_agent",
"receiver": "reporter_agent",
"payload": {
"status": "approved",
"quality_score": 9.2,
"minor_edits": [
"Changed 'surge' to 'increased' in paragraph 3 for AP style consistency",
"Added Oxford comma in list of countries"
],
"approved_content": "[Final edited article]"
}
}步骤 11:Publisher 通过 CI/CD 发布
最后,Printer agent 使用 MCP 服务器操作 CMS 和 CI/CD 流水线来发布已批准的文章:
# Publisher Agent publishing via MCP
async def publish_article(self, content, metadata):
# Upload to CMS via MCP
cms_result = await self.mcp_client.invoke_tool(
server="wordpress_mcp",
tool="create_post",
parameters={
"title": content["headline"],
"body": content["body"],
"status": "draft",
"categories": metadata["categories"],
"tags": metadata["tags"],
"featured_image_url": metadata["image_url"]
}
)
post_id = cms_result["post_id"]
# Trigger CI/CD deployment via MCP
deploy_result = await self.mcp_client.invoke_tool(
server="cicd_mcp",
tool="trigger_deployment",
parameters={
"pipeline": "publish_article",
"environment": "production",
"post_id": post_id,
"schedule": "immediate"
}
)
# Track analytics
await self.mcp_client.invoke_tool(
server="analytics_mcp",
tool="register_publication",
parameters={
"post_id": post_id,
"publish_time": datetime.now().isoformat(),
"story_id": metadata["story_id"]
}
)
return {
"status": "published",
"post_id": post_id,
"url": f"https://newsroom.example.com/articles/{post_id}",
"deployment_id": deploy_result["deployment_id"]
}Publisher 通过 A2A 确认文章已发布:
{
"message_type": "task_complete",
"sender": "printer_agent",
"receiver": "news_chief",
"payload": {
"task_id": "story_renewable_energy_2024",
"status": "published",
"publication": {
"url": "https://newsroom.example.com/articles/renewable-europe-2024",
"published_at": "2025-09-30T17:45:00Z",
"post_id": "12345"
},
"workflow_metrics": {
"total_time_minutes": 45,
"agents_involved": ["reporter", "researcher", "archive", "editor", "printer"],
"iterations": 2,
"mcp_calls": 12
}
}
}这是配套代码仓库中使用上述相同 agent 的完整 A2A 工作流序列。
| # | From | To | Action | Protocol | Description |
|---|---|---|---|---|---|
| 1 | User | News Chief | Assign Story | HTTP POST | User submits story topic and angle |
| 2 | News Chief | Internal | Create Story | - | Creates story record with unique ID |
| 3 | News Chief | Reporter | Delegate Assignment | A2A | Sends story assignment via A2A protocol |
| 4 | Reporter | Internal | Accept Assignment | - | Stores assignment internally |
| 5 | Reporter | MCP Server | Generate Outline | MCP/HTTP | Creates article outline and research questions |
| 6a | Reporter | Researcher | Request Research | A2A | Sends questions (parallel with 6b) |
| 6b | Reporter | Archivist | Search Archive | A2A JSONRPC | Searches historical articles (parallel with 6a) |
| 7 | Researcher | MCP Server | Research Questions | MCP/HTTP | Uses Anthropic via MCP to answer questions |
| 8 | Researcher | Reporter | Return Research | A2A | Returns research answers |
| 9 | Archivist | Elasticsearch | Search Index | ES REST API | Queries news_archive index |
| 10 | Archivist | Reporter | Return Archive | A2A JSONRPC | Returns historical search results |
| 11 | Reporter | MCP Server | Generate Article | MCP/HTTP | Creates article with research/archive context |
| 12 | Reporter | Internal | Store Draft | - | Saves draft internally |
| 13 | Reporter | News Chief | Submit Draft | A2A | Submits completed draft |
| 14 | News Chief | Internal | Update Story | - | Stores draft, updates status to "draft_submitted" |
| 15 | News Chief | Editor | Review Draft | A2A | Auto-routes to Editor for review |
| 16 | Editor | MCP Server | Review Article | MCP/HTTP | Analyzes content using Anthropic via MCP |
| 17 | Editor | News Chief | Return Review | A2A | Sends editorial feedback and suggestions |
| 18 | News Chief | Internal | Store Review | - | Stores editor feedback |
| 19 | News Chief | Reporter | Apply Edits | A2A | Routes review feedback to Reporter |
| 20 | Reporter | MCP Server | Apply Edits | MCP/HTTP | Revises article based on feedback |
| 21 | Reporter | Internal | Update Draft | - | Updates draft with revisions |
| 22 | Reporter | News Chief | Return Revised | A2A | Returns revised article |
| 23 | News Chief | Internal | Update Story | - | Stores revised draft, status to "revised" |
| 24 | News Chief | Publisher | Publish Article | A2A | Auto-routes to Publisher |
| 25 | Publisher | MCP Server | Generate Tags | MCP/HTTP | Creates tags and categories |
| 26 | Publisher | Elasticsearch | Index Article | ES REST API | Indexes article to news_archive index |
| 27 | Publisher | Filesystem | Save Markdown | File I/O | Saves article as .md file in /articles |
| 28 | Publisher | News Chief | Confirm Publication | A2A | Returns success status |
| 29 | News Chief | Internal | Update Story | - | Updates story status to "published" |
结论
在现代增强型 LLM 基础设施范式中,A2A 和 MCP 都扮演着重要角色。A2A 为复杂的多 agent 系统提供灵活性,但可能可移植性较低且运维复杂度更高。MCP 提供了标准化的工具集成方法,更易于实现和维护,但并非设计用于多 agent 协同。
选择并非二选一。如我们新闻室示例所示,最复杂且高效的 LLM 支持系统通常结合两种方法:agent 通过 A2A 协议进行协调和专业化,同时通过 MCP 服务器访问其工具和资源。这种混合架构在提供多 agent 系统组织效益的同时,也带来了 MCP 的标准化和生态优势。这表明,可能根本不需要选择:直接将两者作为标准方法即可。
作为开发者或架构师,你需要测试并确定两种解决方案的最佳组合,以针对你的具体用例产生最佳结果。理解每种方法的优势、局限性及适用场景,将帮助你构建更高效、可维护且可扩展的 AI 系统。
无论你是在构建数字新闻室、客户服务平台、研究助理还是其他 LLM 驱动的应用,仔细考虑你的协调需求(A2A)和工具访问需求(MCP)都将为成功奠定基础。
附加资源
- Elasticsearch Agent Builder: https://www.elastic.co/docs/solutions/search/elastic-agent-builder
- A2A Specification: https://a2a-protocol.org/latest/specification/
- A2A and MCP Integration: https://a2a-protocol.org/latest/topics/a2a-and-mcp/
- Model Context Protocol: https://modelcontextprotocol.io
原文:https://www.elastic.co/search-labs/blog/a2a-protocol-mcp-llm-agent-workflow-elasticsearch

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)