信息论基础:量化
1 引言
之前讲了无损压缩,适合文本信源,方法有霍夫曼编码、算术编码、字典编码。下面将介绍有损压缩。针对声音、图像、视频的编码。这些都是物理世界的信号,取值连续的。为了在计算机上保存、处理,使用目前的数字通信系统传输,取值必须要离散化。此外由于人的感觉器官不敏锐,可以容忍有损压缩。
对于这些信号,有两种有损压缩方法:1)直接对信号做量化;2)先对信号做某种处理(例如求预测误差、傅里叶变换),再对处理结果进行量化。在两种有损压缩方法中,量化是必做的。在有损压缩方法中,损失是由量化步骤引入,信号处理步骤(如求预测误差、傅里叶变换)一般不引入损失。所以,量化是有损压缩的基本问题。本节课讲信号的直接量化,下节课讲先做信号处理再进行量化的压缩方法。
量化是将信号的连续值近似为有限多个离散值的过程,也包括将大量可能的离散值近似为少量的离散值的过程。例如,1)模数转换(ADC)对模拟信号采样得到离散时间信号,再对离散时间信号做量化成为数字信号(时间离散、取值也离散);2)在数字图像的有损压缩中,原始图像的像素值已经是离散值了,但是值太多、浪费。通常灰度图像的每个像素占8比特,比如经过某种量化,将每个像素值表示为4个比特。
假设某信源输出[−10.0,10.0][−10.0,10.0][−10.0,10.0]区间的实数值。一种简单的量化方法是取整。例如:2.12→2,3.83→4。这样就可以用21个元素的集合表示无穷大的实数集合([−10.0,10.0][−10.0,10.0][−10.0,10.0]区间的所有实数),显著压缩了符号集。但是,已知重构值(即量化后的值)是3,原始值是3.1还是2.9,还是其他?无法确定。可见,量化丢失了信息,无法从量化结果精确重建原始值。有损就指的是这个意思。
执行量化操作的系统叫量化器(quantizer),分为标量量化器、矢量量化器。标量量化器的输入是标量(信源输出的单个采样),矢量量化器的输入是矢量(信源输出的固定长度的采样序列)。
2 标量量化
量化器包括编码器和解码器。下面以声音和图像为例解释了编码器和解码器的关系。
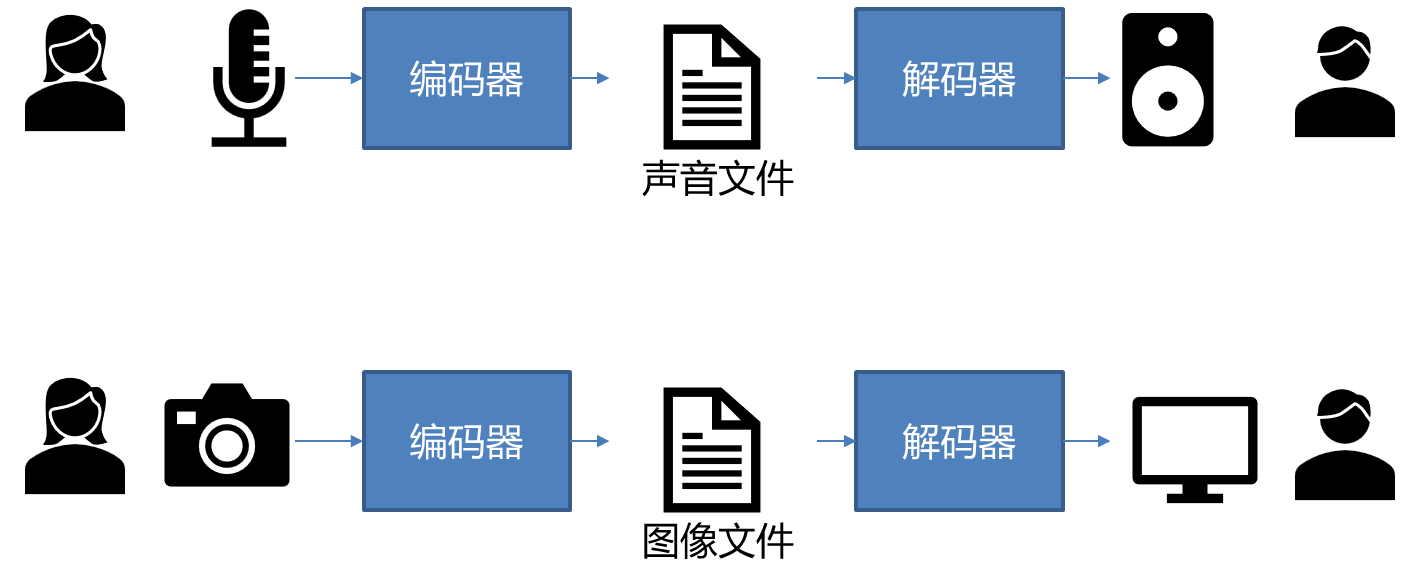
在标量量化中,编码器将样本的范围分为许多区间,每个区间分配唯一码字,落入各区间的样本映射为对应码字。解码器将码字映射为重构值(reconstruction value),即各区间最有代表性的值。
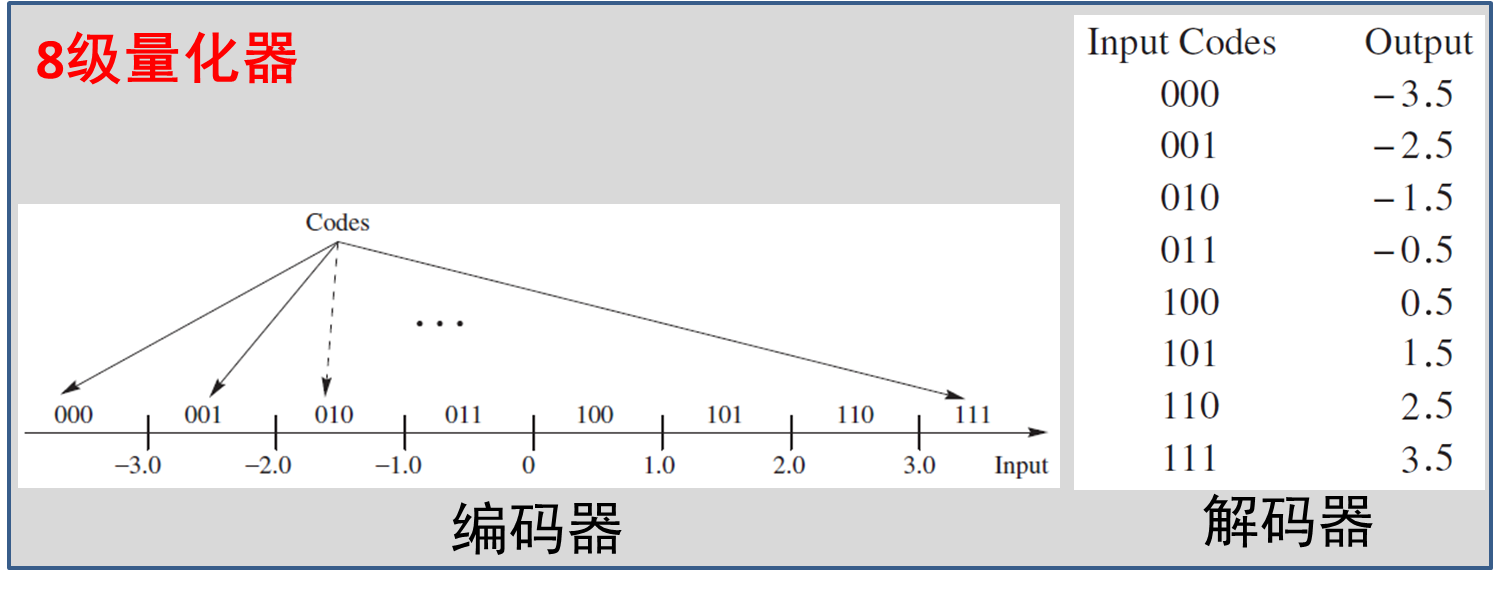
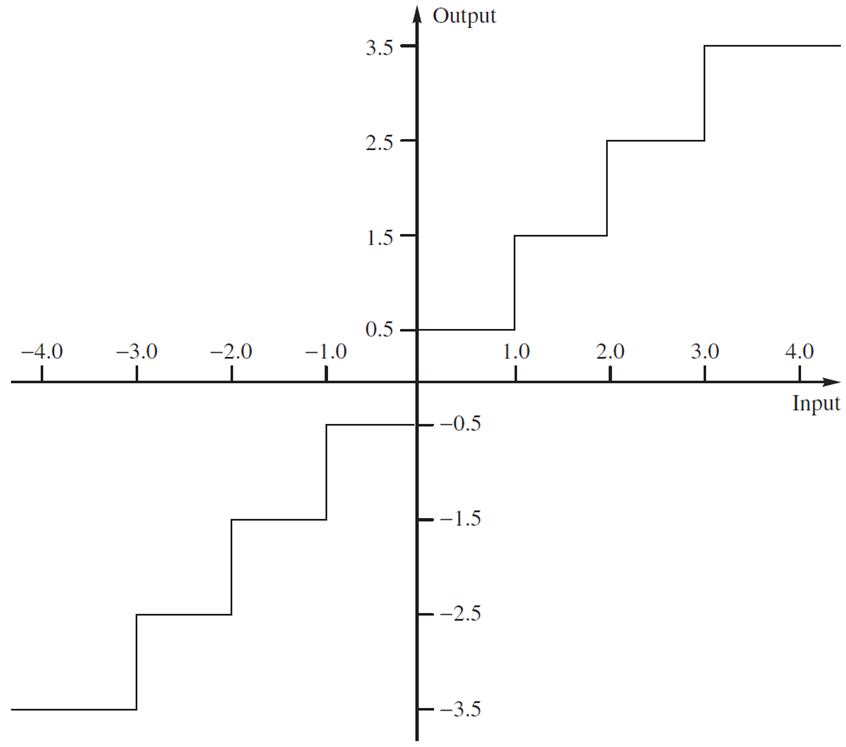
将编码器映射和解码器映射合并,得到从样本到重构值的映射,如下图所示。可见映射有失真。如果能提高量化级数(编码的码长变长),可以减小失真。
量化器的设计
设计量化器时,需考虑两个指标(码率、失真度)。设计时通常是固定某个指标,优化另一个指标。比如,给定码率,使失真度最小;或者给定失真度,使码率最低。下面引入必要的符号,对量化给出更准确的表述。
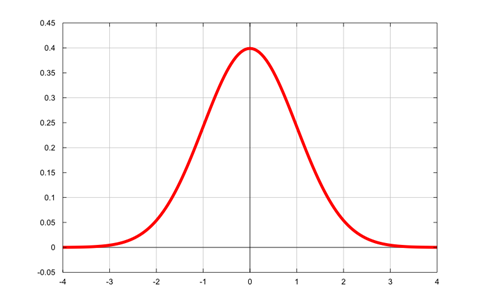
信源的输出为随机变量XXX,概率分布为fX(x)f_X (x)fX(x)。量化器用M+1M+1M+1个端点(即判别边界){bi}i=0M\{b_i\}_{i=0}^M{bi}i=0M,将XXX的值域分为MMM个区间,每个区间有一个重构值{yi}i=1M\{y_i \}_{i=1}^M{yi}i=1M。Q()Q()Q()表示量化运算,yi=Q(x),bi−1<x≤biy_i=Q(x),b_{i-1}<x≤b_iyi=Q(x),bi−1<x≤bi。下图显示了正态分布。
量化误差(也叫量化失真、量化噪声)的常用指标是均方误差
σq2=∫−∞+∞(x−Q(x))2fX(x)dxσ_q^2=∫_{-∞}^{+∞} (x-Q(x))^2 f_X (x) dxσq2=∫−∞+∞(x−Q(x))2fX(x)dx
=∑i=1M∫bi−1bi(x−yi)2fX(x)dx=∑_{i=1}^M ∫_{b_{i-1}}^{b_i} (x-y_i )^2 f_X (x)dx =i=1∑M∫bi−1bi(x−yi)2fX(x)dx
如果编码器使用定长编码,则码率R=⌈logM⌉R=⌈\log M ⌉R=⌈logM⌉。
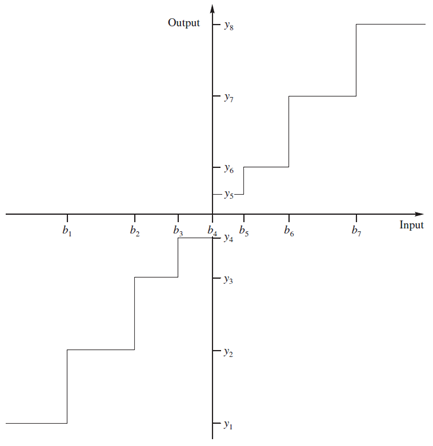
量化器设计问题有下面两种表述。
- 表述1:给定失真度约束:σq2≤D∗\sigma _q^2≤D^∗σq2≤D∗,求判定边界、重构值和码字,使码率最小。
- 表述2:给定码率约束:R≤R∗R≤R^∗R≤R∗,求判定边界、重构值和码字,使失真度最小。
均匀量化器
从最简单的均匀量化器开始。除最外侧的两个区间(正负无穷大),其他区间大小相等,区间中点为重构值,区间大小称为步长Δ\DeltaΔ。通常假设输入概率分布是对称的,量化器也对称,级数为偶数。均匀量化器的设计问题是,给定概率分布和级数MMM,确定最优步长Δ\DeltaΔ,使失真度最小。
均匀量化最适合输出服从均匀分布的信源。假设信源服从[−Xmax,Xmax][−X_{\text{max}},X_{\text{max}}][−Xmax,Xmax]的均匀分布。设计量化级数为𝑀的均匀量化器,将[−Xmax,Xmax][−X_{\text{max}},X_{\text{max}}][−Xmax,Xmax]平均分为MMM个区间。步长Δ=2Xmax/M\Delta=2X_{\text{max}}/MΔ=2Xmax/M。失真(均方误差)σq2=∆2∕12\sigma _q^2=∆^2∕12σq2=∆2∕12,量化误差服从[−∆/2,∆/2][−∆/2,∆/2][−∆/2,∆/2]的均匀分布。信噪比SNR=6.02logMSNR=6.02 \logMSNR=6.02logM dB。
下面的例子仿真了在[0,1][0,1][0,1]区域均匀分布的信源,并利用量化级数为2、4、8的均匀量化器进行量化。为了直观,将100个样本显示为灰度图像。注意,第一幅图像代表原始样本,虽然数值为浮点数,但是在显示的时候,内部会将其量化为256级(8比特)。从视觉上看,量化为3个比特(8级)的图像与原图已经很接近了。
h = 10;
x = rand(h,h); % Generate i.i.d. samples following uniform distribution
partition1 = [0.5];
codebook1 = [0.25 0.75]; % 1 bit
[index1,quants1] = quantiz(x(:),partition1,codebook1);
x1 = reshape(quants1,h,h);
partition2 = [0.25 0.5 0.75];
codebook2 = [0.125 0.375 0.625 0.875]; % 2 bits
[index2,quants2] = quantiz(x(:),partition2,codebook2);
x2 = reshape(quants2,h,h);
t = linspace(0,1,9);
partition3 = t(2:end-1);
codebook3 = (t(1:end-1)+t(2:end))/2; % 3 bits
[index3,quants3] = quantiz(x(:),partition3,codebook3);
x3 = reshape(quants3,h,h);
figure(1),subplot(2,2,1),imshow(x),title('Original image');
subplot(2,2,2),imshow(x1),title('Reconstructed image (1 bit)');
subplot(2,2,3),imshow(x2),title('Reconstructed image (2 bits)');
subplot(2,2,4),imshow(x3),title('Reconstructed image (3 bits)');

很多信源的输出不服从均匀分布 为什么还要均匀量化? 因为简单 假设某信源服从如下分布:落入[−1,1]的概率为0.95,落入[−100,−1]和[1,100]的概率均为0.025。在三个区间内,均为均匀分布。 设计量化级数为8的均匀量化器。 哪个步长的均方误差小?25 or 0.3 可见,当分布不均匀时,最优步长不是范围除以级数 均方误差是步长的函数。令其导数为0,计算出步长。对于任意分布,需要求数值解。

前面假设概率分布是正确的,而实际未必如此。如果假设的概率分布与实际不同,设计的量化器的信噪比降低(量化误差视为噪声)。下图,假设的分布函数正确(高斯分布),但是假设的方差不对。图中的曲线为信噪比随方差比(实际方差/假设方差)的变化。
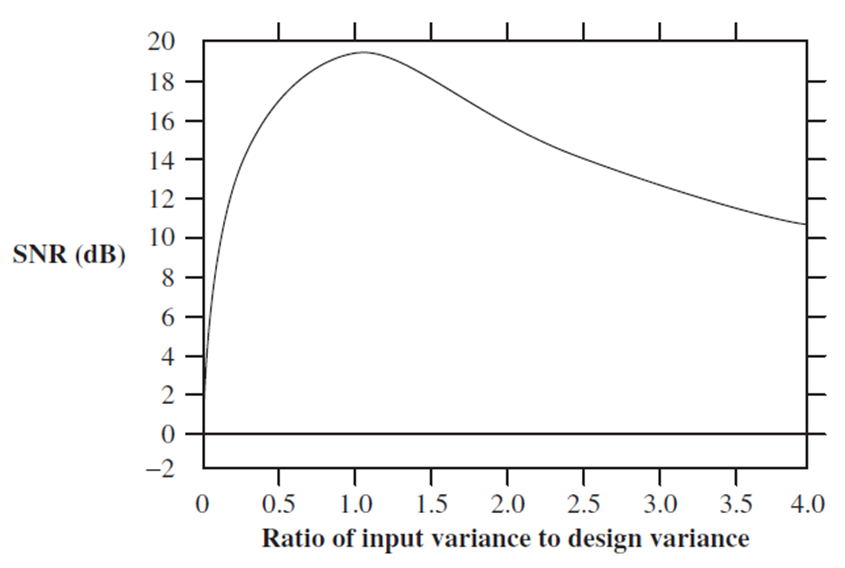
为适应信源统计特性未知或者会发生变化的情况,将量化器的输入分为数据块,对每个块进行统计分析,据此调整量化器参数。每个块的参数也需要编码,以便解码器使用。所以缺点是带来延迟。
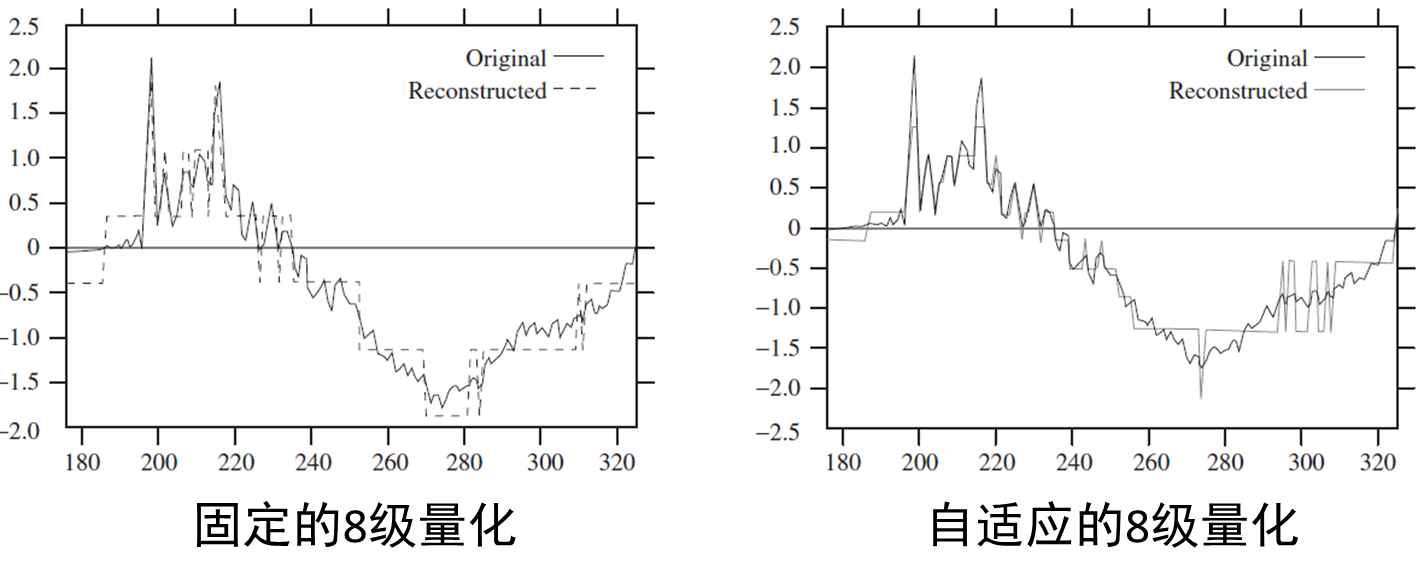
非均匀量化和Lloyd算法
如果输入是非均匀分布,均匀量化的效果肯定不是最好的。以高斯分布为例,假设量化级数已确定,如何设计量化间隔?
按照直觉,中间的量化间隔应该小一些,外围的可以大一些。虽然对外围的样本,量化误差变大,但是由于外围的概率小,总的量化误差比均匀量化小。
已知输入的概率分布,给定量化级数,量化器的设计目标是使均方误差最小。σq2=∑i=1M∫bi−1bi(x−yi)2fX(x)dxσ_q^2=∑_{i=1}^M ∫_{b_{i-1}}^{b_i} (x-y_i )^2 f_X (x)dx σq2=i=1∑M∫bi−1bi(x−yi)2fX(x)dx
变量包括𝑀+1个判别边界、𝑀个重构值。同时求解这些变量很困难。
假设知道判别边界,最优的重构值为各区间的均值。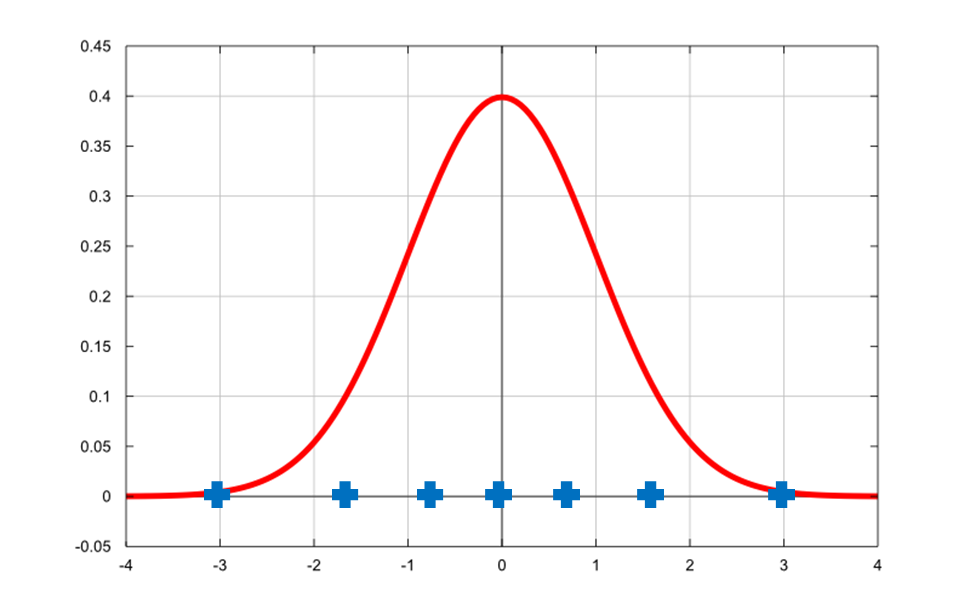
假设知道重构值,最优的判别边界为相邻重构值的中点。
利用前面2个属性,Lloyd提出迭代求解方法,可以处理(1)已知概率分布,或(2)给定训练样本(类似k-means)两种情况。
算法步骤如下:
- 首先初始化重构值;
- 然后计算判别边界,更新重构值;
- 迭代直到收敛(均方误差不降)。
下面针对给定的一组样本,调用MATLAB中的Lloyd算法求解非均匀量化器。
n = 1000;
x = rand(n, 1);
figure(1), clf
for bit_num = 1:3
[partition,codebook,distor,reldistor] = lloyds(x,2^bit_num);
subplot(3,1,bit_num), plot(partition,zeros(size(partition)),'b+',codebook,zeros(size(codebook)),'r*')
xlabel('x'); ylabel('y'); set(gca, 'xlim', [0 1])
end
下面是Lloyd算法对于均匀分布的样本找到的重构值和判别边界。
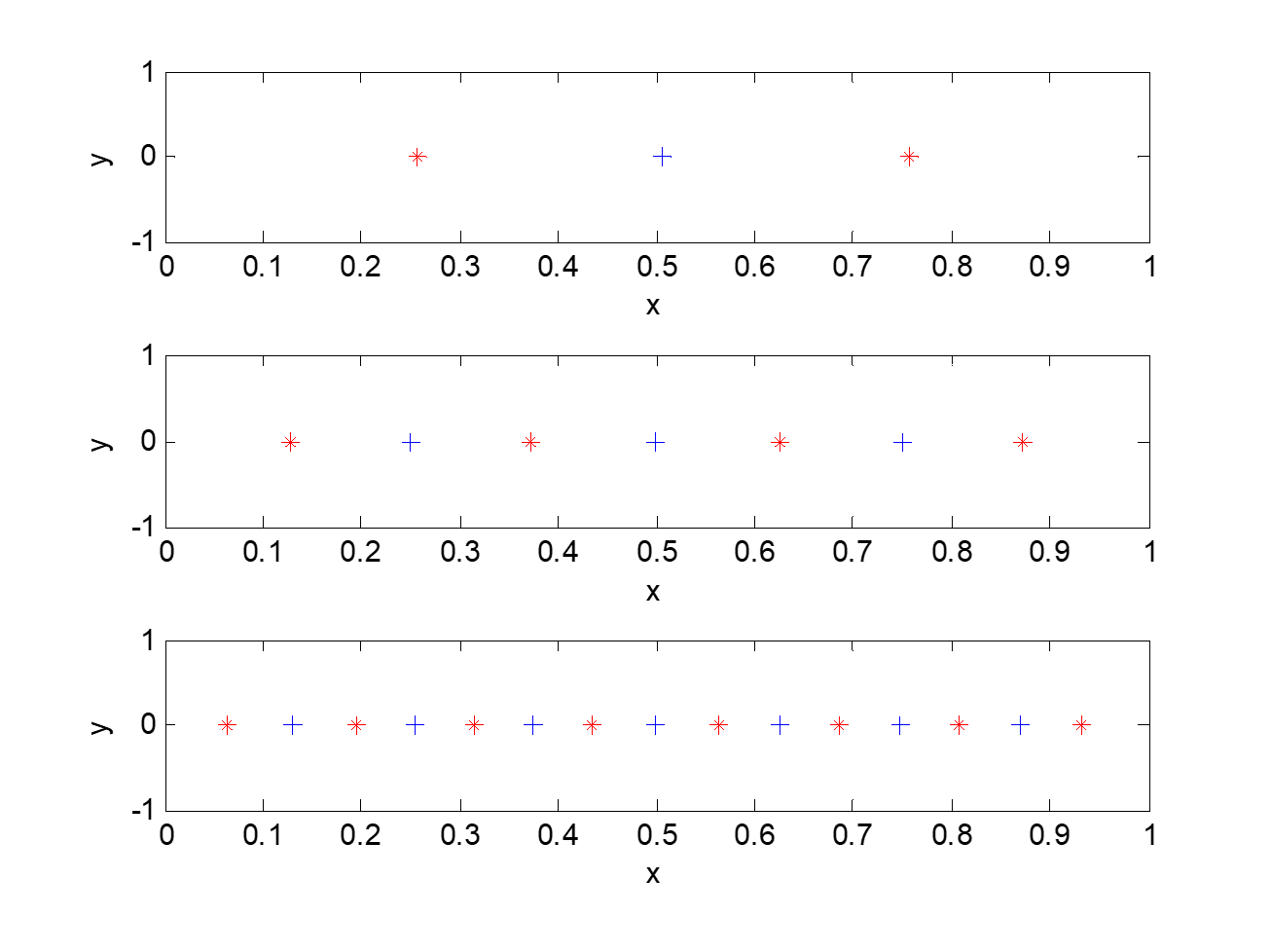
下面是Lloyd算法对于正态分布的样本找到的重构值和判别边界。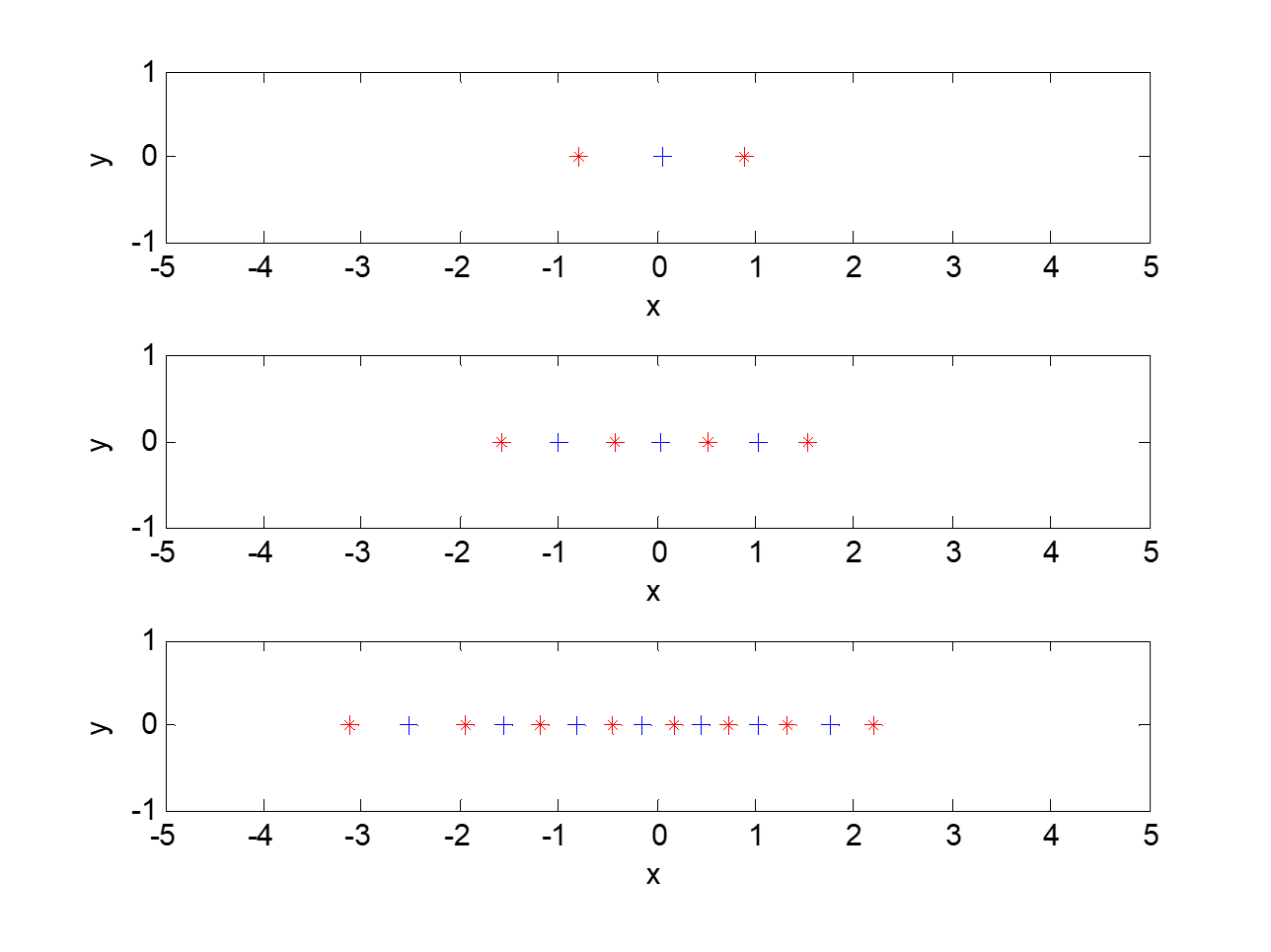
3 矢量量化
无损压缩(霍夫曼编码,算术编码)中的分组编码将信源的输出进行分组,将一个分组作为整体进行编码,压缩效果更好。这种策略对于有损压缩同样有效。将一组样本视为一个矢量,对其进行量化,称为矢量量化。矢量的例子有小段声音的采样序列、小图像块。
下面为矢量量化的示意图。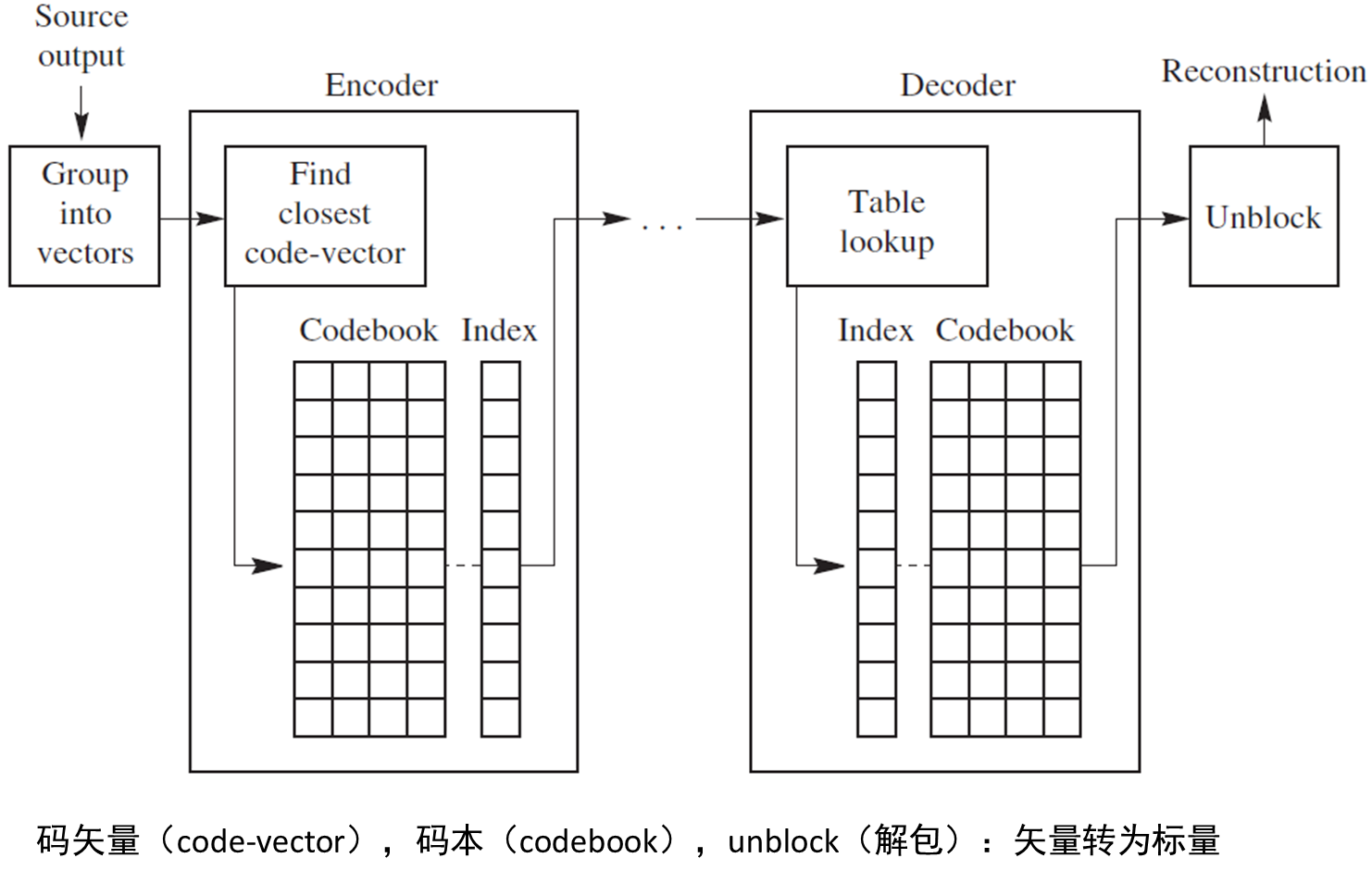
矢量量化的术语
- 码率:每个样本的比特数,单位bits/sample
- 矢量长度为𝐿,码本包含𝐾个码矢量(code-vector),码矢量索引需要⌈log𝐾 ⌉ bits
- 码率为⌈log𝐾 ⌉/𝐿
- 失真度采用均方误差(MSE),以样本为单位
- 编码:寻找码本𝒞中与输入矢量𝐱=(𝑥_1 𝑥_2⋯𝑥_𝐿)最接近的码矢量𝐲_𝑗,记录其索引
- 码本大小为𝐾的量化器称为𝐾级量化器
矢量量化相比标量量化的优势
通过一个例子解释矢量量化相比标量量化的优势。
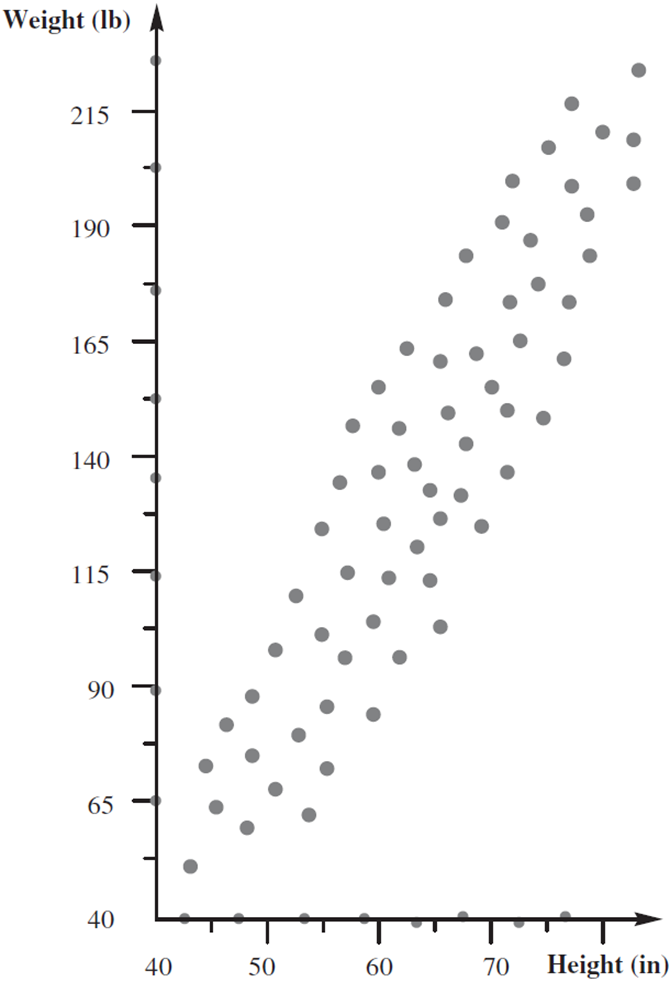
信源1:许多人的身高,ℎ_1 ℎ_2 ℎ_3 ℎ_4 ℎ_5 ℎ_6 ℎ_7 ℎ_8⋯
假设身高在40到80英寸之间均匀分布,使用8级标量量化器,划分为8个步长为5的区间。
信源2:许多人的体重,𝑤_1 𝑤_2 𝑤_3 𝑤_4 𝑤_5 𝑤_6 𝑤_7 𝑤_8⋯
假设体重在40到240磅之间均匀分布,使用8级标量量化器,划分为8个步长为25的区间。
信源3:许多人的身高和体重,ℎ_1 𝑤_1 ℎ_2 𝑤_2⋯ 仍然使用上面的标量量化器分别量化身高和体重。
即使身高和体重两个变量分别服从均匀分布,两者的联合概率分布一定不是均匀分布的。如果分别用标量量化,对于样本空间的覆盖是不合理的。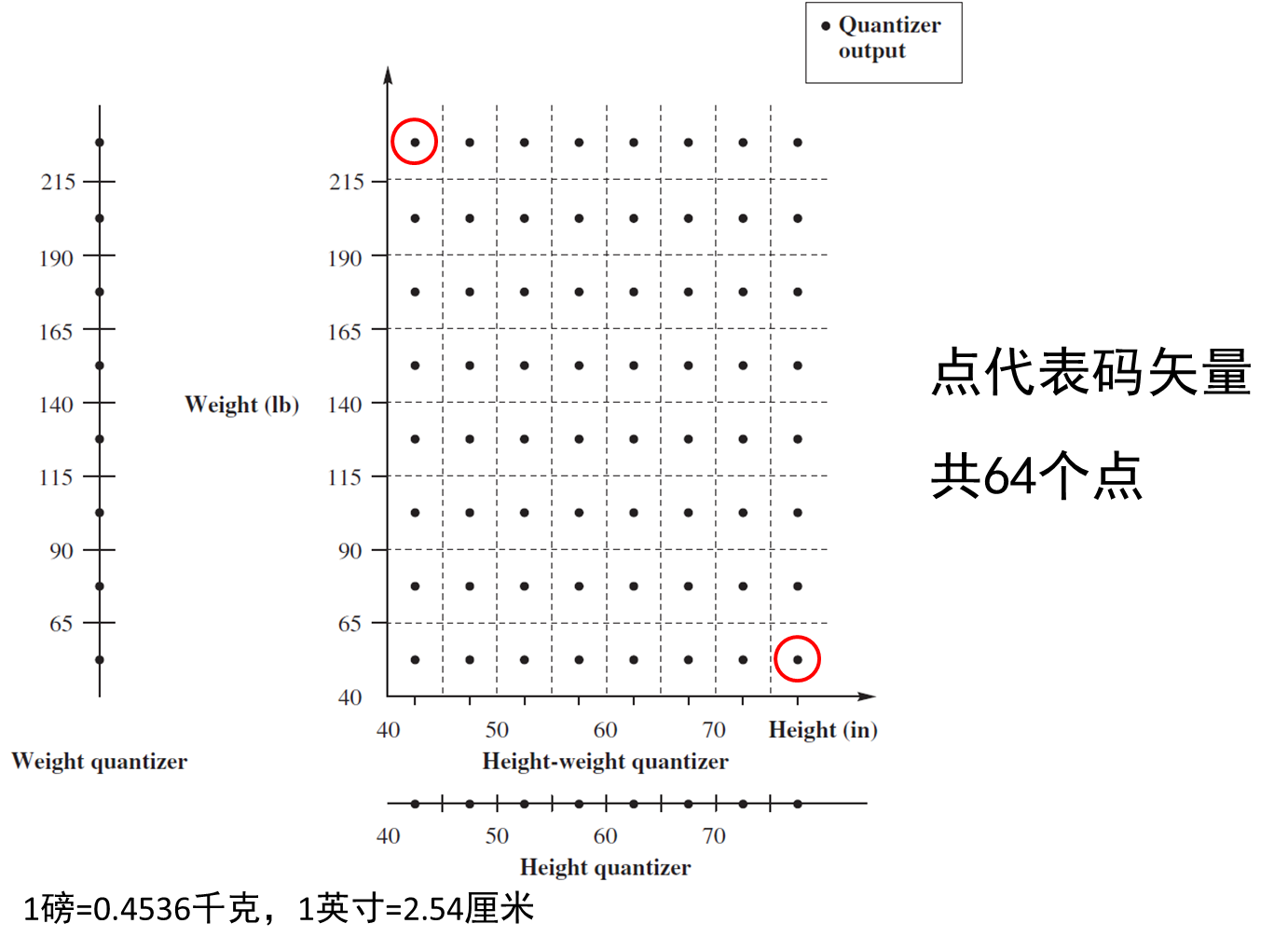
假设点数仍为64个(𝐾不变),更佳的方法是,让码向量的分布类似输入数据的分布(后面讲如何构造码本)。量化方法是,找输入矢量的最近邻。相比分别做标量量化,矢量量化的失真度小。
LBG算法
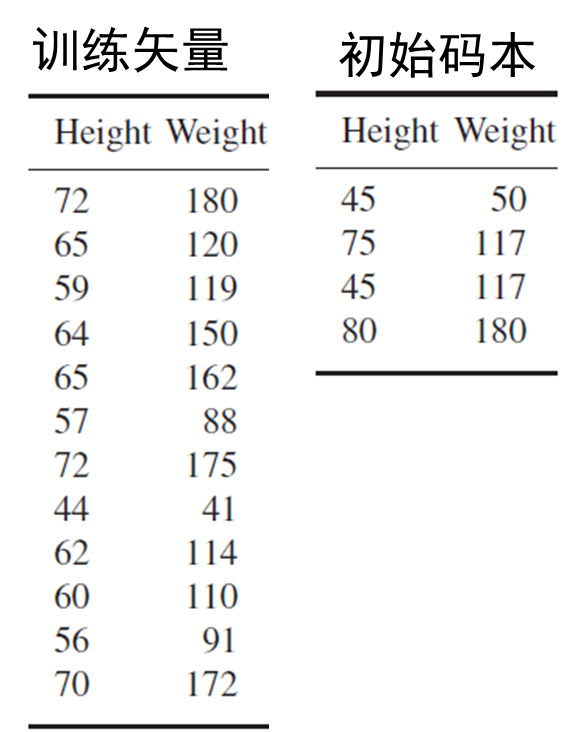
LBG算法是由Linde,Buzo,Gray三人在1980年提出的。相当于Lloyd方法的多维推广。 给定训练矢量集{xn}i=1N\{\bold{x}_n \}_{i=1}^N{xn}i=1N,码本构造方法如下:
- 初始化:使用某种方法得到初始码本。
- 将每个训练矢量归到最近的码矢量,将训练矢量集划分成𝑀个集合。
- 计算失真度,如果失真度变化不大则停止,否则继续。
- 将各码矢量更新为集合均值,转到第2步。
下面给出LBG算法对于身高体重数据构造码本的例子。
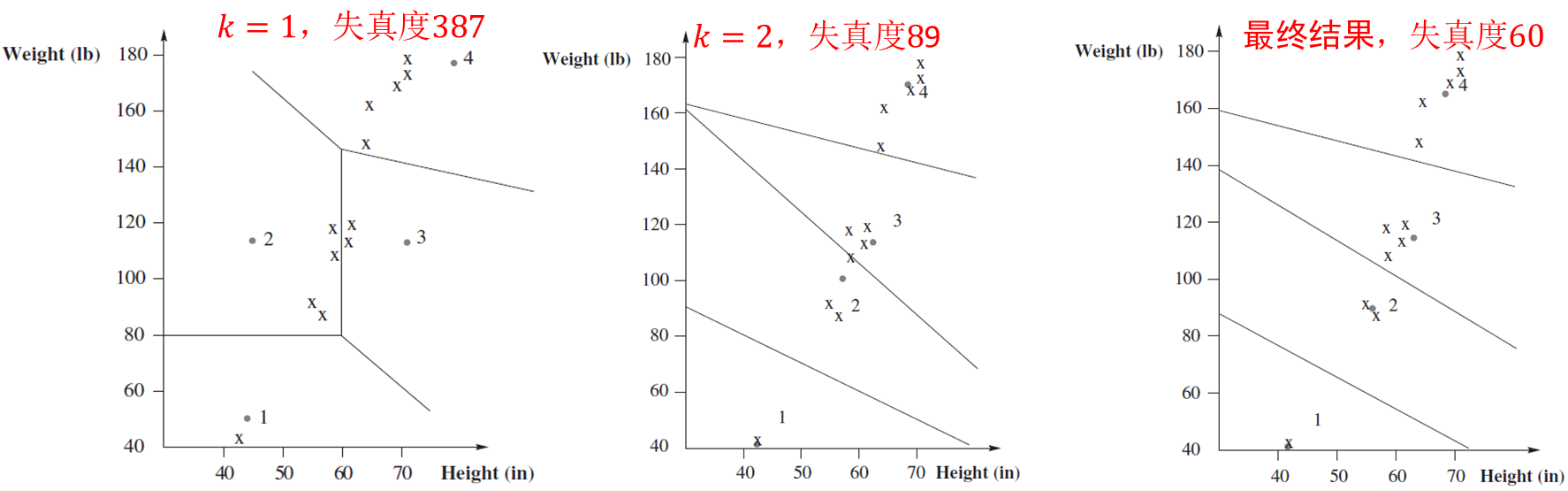
初始化对于码本有很大影响,下面是两种初始化得到的最终码本及量化区域。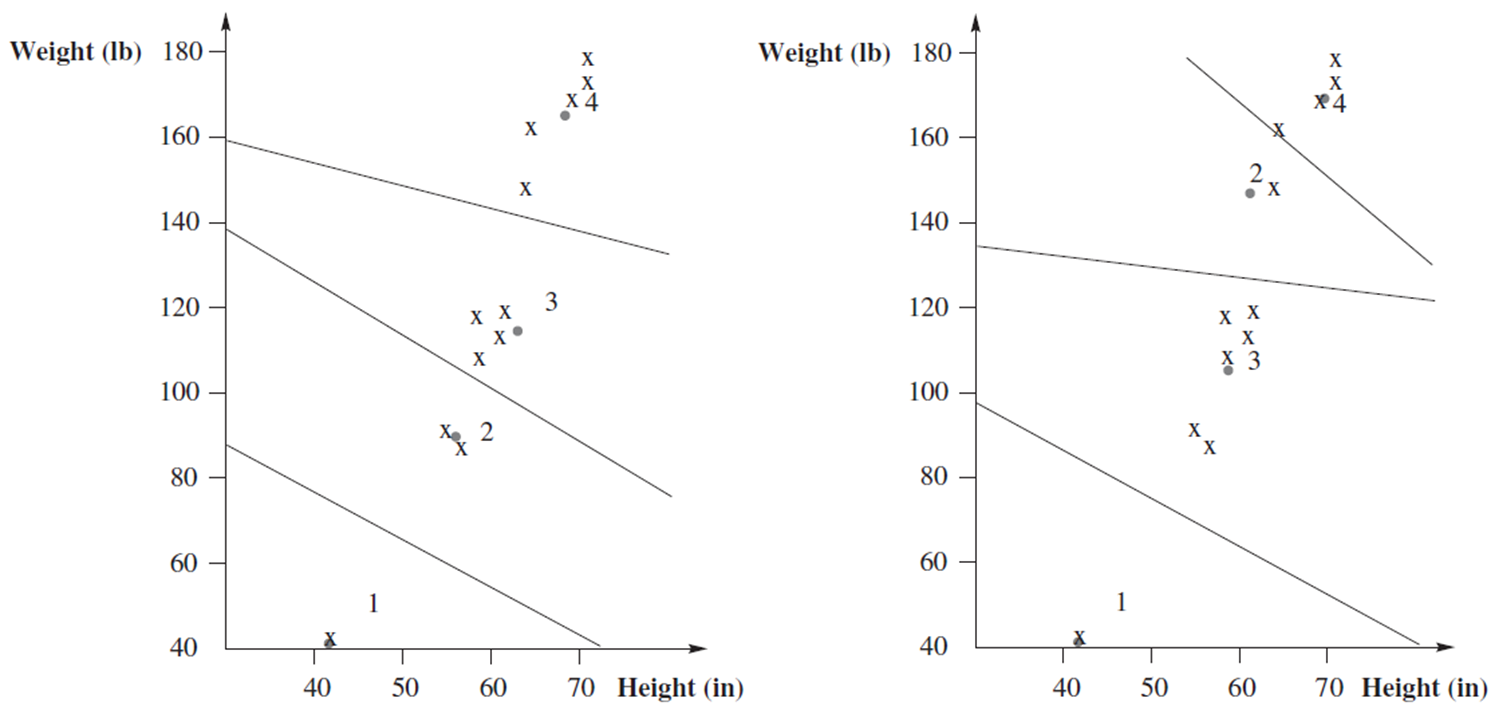
常见的四种初始化方法:
- 随机初始化(𝑘-means聚类的标准做法):随机选择𝐾个训练矢量作为初始码本,可以多次初始化,分别执行LBG算法构造码本,最后选失真最小的码本。
- 标量量化:每一维独立做均匀量化。
- LBG提出的切分技术(splitting technique)。
- 成对最近邻(Pairwise Nearest Neighbor)。
LBG提出的切分技术:
- 设计1级矢量量化器:所有训练矢量的均值为码矢量;
- 设计2级矢量量化器的初始码本:1级的码矢量作为第1个初始码矢量,1级的码矢量加扰动,得到第2个初始码矢量;利用LBG算法获得最终的2级码本;
- 设计4级矢量量化器的初始码本:2级的码矢量作为前2个初始码矢量,2级的码矢量加扰动,得到另外2个初始码矢量;利用LBG算法获得最终的4级码本;
- 迭代执行以上步骤,直到得到𝐾级码本。
成对最近邻(Pairwise Nearest Neighbor,PNN)与LBG切分相反,PNN采取合并的策略:最开始,每个训练矢量作为一个聚类。因为每个聚类只有一个训练矢量,失真度为0。每次合并一对使失真度增加最小的聚类,更新聚类均值。直到聚类数等于𝐾。有些实验表明,PNN比其他初始化方法好。但是,没有理论证明。而且,复杂度为O(𝑁^3),𝑁为训练矢量数。当训练矢量很多时,PNN运算复杂度很高。
利用LBG算法进行图像压缩。下面为原始灰度图像,每像素8比特。

4×4像素块作为输入矢量,矢量维度L=16。使用该图像中的矢量来构造码本,码本大小K分别为16、64、256、1024时的重构结果。

不考虑码本所占空间时,各个指标如下:
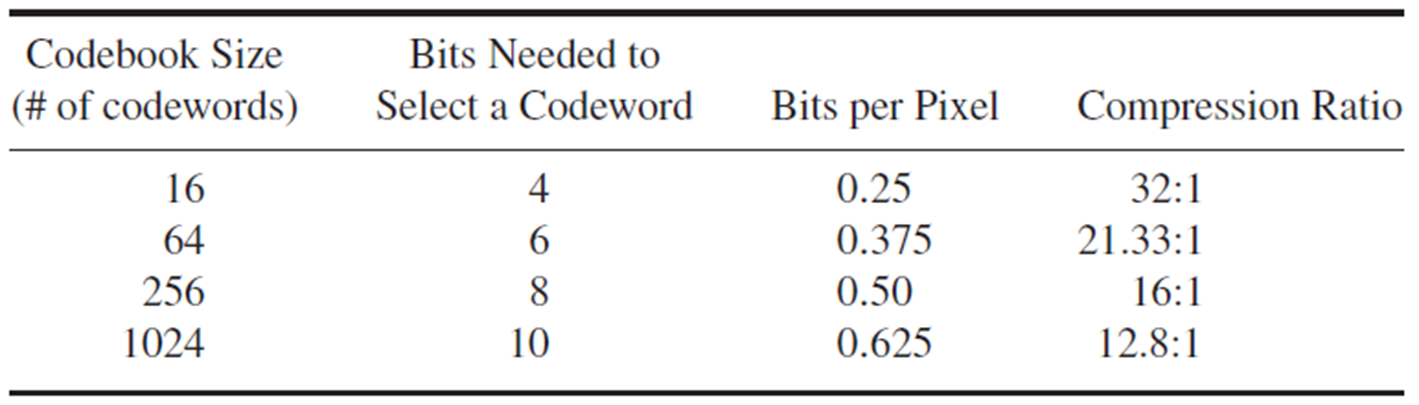
由于该码本是针对该图像的,需存储以便解码,需要考虑码本所占空间。
码本所占空间=码本大小x矢量维度x每一维的比特数
下表为码本空间分摊到每个像素的比特数。
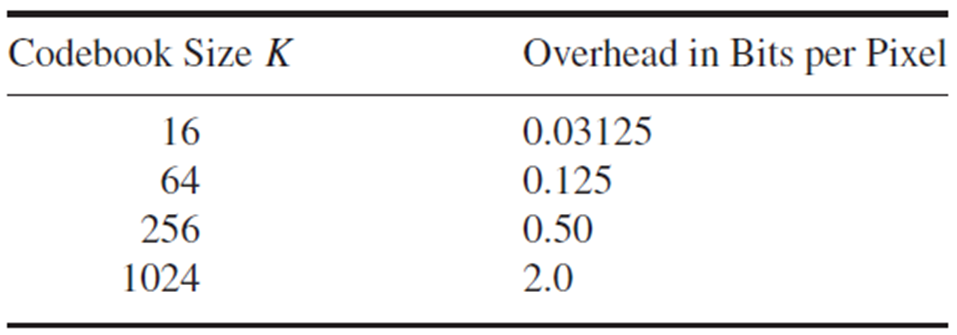
为避免专用码本的额外数据,使用通用码本(从其他图像学习的码本)。但是,利用通用码本,失真变大。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)