2D 3D 多通道卷积及pytorch实现
很多人容易混淆2D卷积和3D卷积的概念,把多通道的2D卷积当成3D卷积,本文展示了一种直观理解2D卷积和3D卷积的方式。2D卷积单通道首先了解什么是卷积核,卷积核(filter)是由一组参数构成的张量,卷积核相当于权值,图像相当于输入量,卷积的操作就是根据卷积核对这些输入量进行加权求和。我们通常用卷积来提取图像的特征。直观理解如下:下图使用的是 3x3卷积核(height x width,简写H
2D卷积
单通道
卷积核(filter)是由一组参数构成的张量,卷积核相当于权值,图像相当于输入量,卷积的操作就是根据卷积核对这些输入量进行加权求和。通常用卷积来提取图像的特征。
直观理解如下:下图使用的是 3x3卷积核(height x width,简写H × W ) 的卷积,padding为1(周围的虚线部分,卷积时为了使卷积后的图像大小与原来一致,会对原图像进行填充),两个维度上的strides均为1(滑动步长,这里体现为每次滑动几个小方格)。
上图是通道数为1的2维图像的卷积操作,静态表示为: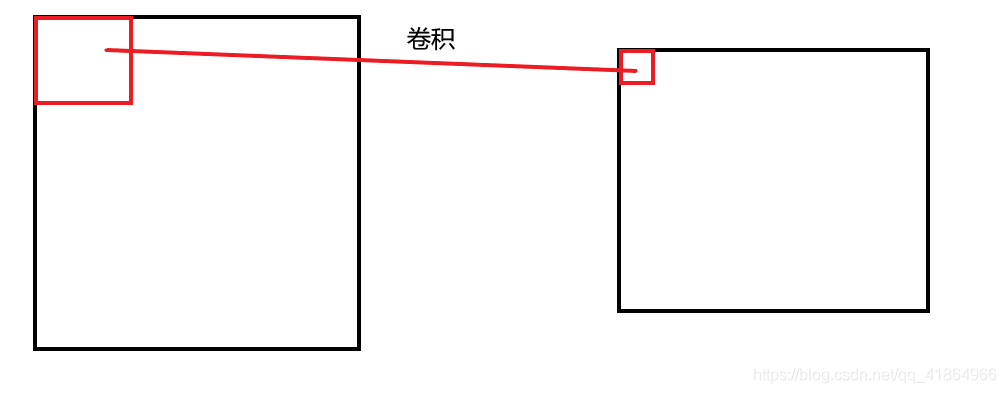
多通道
了解了单通道图像的卷积之后,再来看多通道图像的卷积,灰度图像只有一个通道,而 RGB 图像有R、G、B三个通道。
多通道图像的一次卷积要对所有通道上同一位置的元素做加权和,因此卷积核的shape变成了 H × W ×channels,卷积核变成了3维,但这不是3维卷积,因为我们区分几维卷积看的是卷积核可以在几个维度上的滑动,卷积核是不能在channels上滑动的,卷积核只在二维图像上滑动,因为上面提到每次卷积都要关联所有通道上同一位置上的元素。
3通道的卷积表示如下,比如输入是RGB三通道的图像,其中filter1、filter2和filter3是3个2*2的卷积核,因为输入是3个通道,所以卷积核的大小变为3*2*2,其中每个通道上的2*2卷积核的参数不一样,卷积过程如下:首先每个filter在对应的输入通道图像上进行卷积,然后将3个通道卷积的结果进行element wise加操作得到输出。
上图将3个通道分开表示,卷积核也分开表示,filter1、filter2、filter3均为二维卷积核,堆叠在一起便形成了H × W × 3 的卷积核,同样的我们将3个通道也堆叠在一起,于是形成了下面的3维表示图: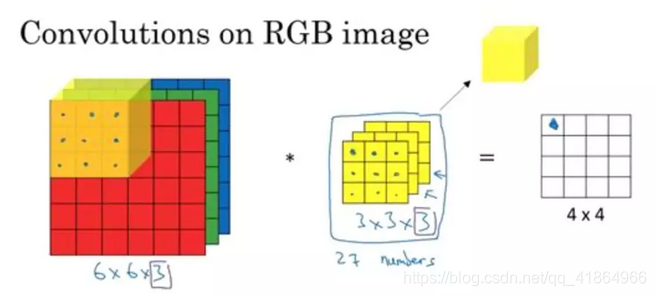
3D卷积
单通道
用类似的方法先分析单通道图像的3D卷积,3D卷积的对象是三维图像,因此卷积核变成了ddepth×height×width简写为D × H × W 。单通道的3D卷积动态图如下:
将上述静态表示成: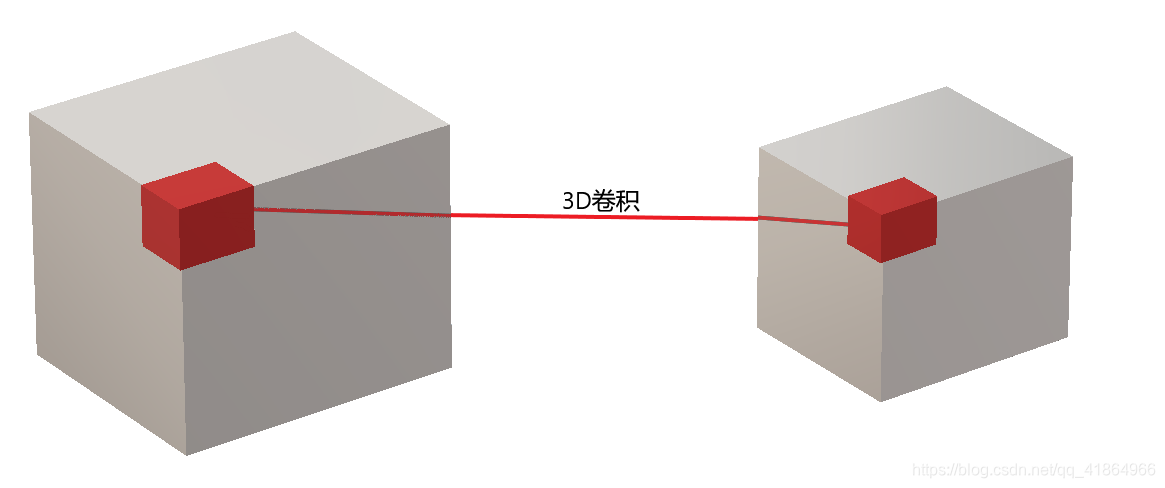
多通道
多通道的3D卷积核shape为D×H×W×channels,将各通道分开画: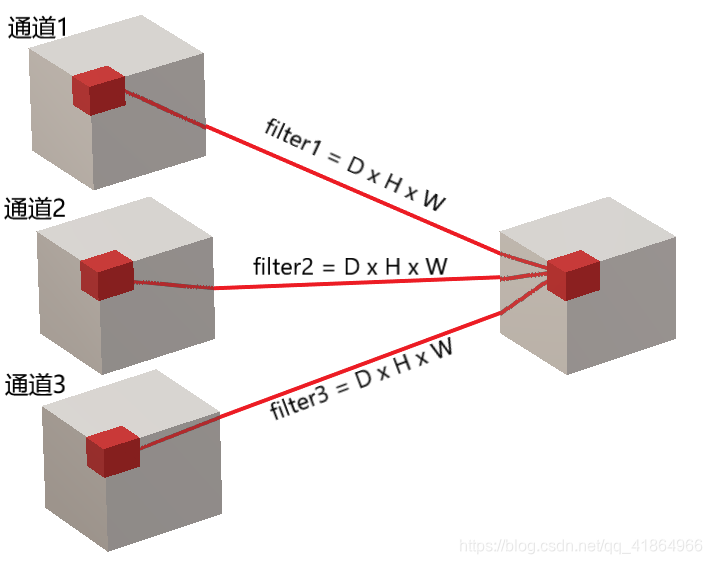
然后将filter1、filter2、filter3堆叠在一起形成一个4维卷积核D × H × W × 3 ,同理将各通道堆叠在一起就形成了多通道的3D卷积输入图像。
pytorch中卷积的实现
pytorch中的Conv3d函数
3D卷积核相比于2D卷积核引入了时间尺度,并且在宽、高、深度(不是单张图像的通道数,这个深度可以理解为帧间)方向上进行滑窗。
在pytorch中,输入数据的维数可以表示为(N,C,D,H,W),其中:N为batch_size,C为输入的通道数,D为深度(D这个维度上含有时序信息),H和W分别是输入图像的高和宽。3维卷积核的维数可以表示为(Cout,C,FD,FH,FW),其中:Cout为输出通道数,(FD,FH,FW)为3维滤波器的尺寸。特别的FD为深度方向的滤波器尺寸,它所关联的是时序信息,FD越大表示在一次滤波过程中考虑到的时序信息越长;FD越小表示在一次滤波过程中考虑到的时序信息越短。输出数据的维数为(N,Cout,Dout,Hout,Wout)
nn.Conv3D(in_channels,out_channels,kernel_size=(FD,FH,FW),stride,padding)
单通道2D卷积
以图像为例,单通道是指输入图像的channel为1,如MNIST数据集中的灰度图像。
- 以MNIST数据集中的图像为例,输入图像的shape为(1,1,28,28),第一个‘1’表示batchsize为1,第二个‘1’表示图像channel为1,图像大小为28*28。
- 单通道2D卷积中的卷积核shape为(1,kernel_height,kernel_width),因为卷积核的in_channel与输入图像的channel必须一致,输入图像的channel为1,所以卷积核的in_channel为1。卷积核大小为kernel_height×kernel_width。参数数量为:1×kernel_height×kernel_width×out_channels。
- 单通道2D卷积的过程可以视为上图的中(a)的情况,卷积核在图像中从左向右,从上到下滑动来提取特征。卷积之后的output是2D的。
直接使用torchvision.datasets.MNIST()导入MNIST数据集,取其中一张图像为例,使用3×3的卷积核进行卷积:
import torch
import torchvision
import torch.nn as nn
##data是数据集中的一张图片
input_2d=data
print(input_2d.shape)
##out: torch.Size([1, 1, 28, 28])
## '1'是in_channels,‘2’是out_channels
conv_2d_1=nn.Conv2d(1, 2, kernel_size=3,stride=1, padding=0)
output=conv_2d_1(input_2d)
print(output.shape)
##out:torch.Size([1, 2, 26, 26])
print(conv_2d_1.weight.size())
##out:torch.Size([2, 1, 3, 3])
多通道2D卷积
与单通道相对应,多通道是指输入图像的channel有多个,常见的是彩色图像,其有RGB三个通道,如CIFAR-10数据集中的图像。
- 以CIFAR-10数据集中的图像为例,输入图像的shape为(1,3,32,32),‘1’表示batchsize,‘3’表示图像channel(R,G,B),图像大小为32*32。
- 多通道2D卷积中的卷积核shape为(3,kernel_height,kernel_width),输入图像的channel决定了卷积核的in_channel。卷积核大小为kernel_height×kernel_width。参数数量为:3×kernel_height×kernel_width×out_channels,且每个通道的卷积核参数不同。
- 多通道2D卷积的过程可以视为上图的中(b)的情况,卷积核在图像中从左向右,从上到下滑动来提取特征,卷积过程与单通道卷积区别不大。卷积之后的output是2D的。
直接使用torchvision.datasets.CIFAR10()导入CIFAR10数据集,取其中一张图像为例,使用3×3的卷积核进行卷积:
import torch
import torchvision
import torch.nn as nn
##data是CIFAR10数据集中的一个样本
input_3d=data
print(input_3d.shape)
##out: torch.Size([1, 3, 32, 32])
## '3'是in_channels,‘1’是out_channels
conv_2d_3=nn.Conv2d(3, 1, kernel_size=5,stride=1, padding=0)
output=conv_2d_3(input_3d)
print(output.shape)
##out:torch.Size([1, 1, 28, 28])
print(conv_2d_3.weight.size())
##out:torch.Size([1, 3, 5, 5])
print(conv_2d_3.weight)
##out:将每个通道的卷积核参数打印下来,发现不同通道参数不一样。
#Parameter containing:
#tensor([[[[-0.0600, -0.0141, -0.0144, 0.1019, -0.0315],
# [ 0.0584, 0.0127, -0.0456, -0.0332, -0.0799],
# [ 0.0907, 0.0177, -0.0280, 0.0516, 0.1063],
# [-0.0778, 0.0547, -0.0803, -0.0821, 0.1050],
# [ 0.0043, -0.0023, 0.0605, 0.0147, 0.0778]],
# [[-0.0456, 0.0874, 0.1106, -0.0932, -0.1071],
# [ 0.0710, -0.0980, -0.0349, -0.0049, -0.0561],
# [ 0.0739, -0.0542, -0.0015, 0.0583, 0.0964],
# [ 0.0017, 0.0645, 0.0116, 0.0480, 0.0664],
# [-0.0622, 0.1145, -0.0708, -0.0958, 0.0587]],
# [[ 0.0913, -0.0239, 0.0371, -0.0304, 0.0454],
# [ 0.0646, 0.1053, -0.0504, 0.0908, 0.0729],
# [ 0.0518, 0.0235, -0.0326, -0.0338, -0.0240],
# [-0.0689, -0.0707, 0.0543, 0.1041, -0.0868],
# [-0.0684, -0.0483, -0.0327, -0.0383, -0.0138]]]], requires_grad=True)
3D卷积
3D卷积同样有单通道卷积和多通道卷积,与2D卷积类似,这里不再赘述,只强调区别。
- 同样以图像为例,3D卷积在医疗图像中使用较多,如CT,MRI等原始数据往往有多个切片构成。
- 3D卷积中输入图像的shape为(1,channel,depth,height,weight),这里的depth是区别于2D卷积的关键,2D卷积的输入可以看出是3D卷积的特殊情况,即depth为1。
- 3D卷积中卷积核的shape为(input_channels , kernel_depth , kernel_height, kernel_width),与2D卷积相比,3D卷积的卷积核多了kernel_depth这个维度。卷积核大小为kernel_depth×kernel_height×kernel_width。参数数量为:input_channels×kernel_depth×kernel_height×kernel_width×out_channels,且每个通道的卷积核参数不同。
- 3D卷积的过程可以视为上图的中(c)的情况,卷积核除了在3D图像中从左向右,从上到下滑动来提取特征外,还需要往一个额外的depth维度上滑动(可以看出除了在一个平面上往左右,上下滑动外,还要往里走,就是另外一个维度,想象一下,我不太会形容唉),因此3D卷积可以在空间中提取更强的特征信息,3D卷积后的output仍然是3D的。
以CT数据集中的一个nii.gz文件为例,就是一个样本,利用SimpleITK中的SimpleITK.GetArrayFromImage()提取nii.gz中的array信息,可以得到该样本的shape为(301, 512, 512),即depth为301,height为512,weight为512。利用2×3×3的卷积核进行卷积:
import torch
import torchvision
import torch.nn as nn
import SimpleITK as sitk
import numpy as np
##这是一个CT数据集中的样本
filename='./coronacases_001.nii.gz'
itkimage = sitk.ReadImage(filename)
numpyImage = sitk.GetArrayFromImage(itkimage)
print(numpyImage.shape)
##out:(301, 512, 512)
##将输入reshape为网络输入数据的格式(batchsize,channel,depth,height,weight)
input_=torch.Tensor(numpyImage.reshape(1,1,301,512,512))
print(input_.shape)
##out:torch.Size([1, 1, 301, 512, 512])
##'1'是in_channels,‘2’是out_channels
##(2,3,3)分别对应kernel_depth,kernel_height,kernel_width
conv_3d=nn.Conv3d(1, 2, kernel_size=(2,3,3),stride=1, padding=0)
output=conv_3d(input_)
print(output.shape)
##out:torch.Size([1, 2, 300, 510, 510])
print(conv_3d.weight.size())
##out:torch.Size([2, 1, 2, 3, 3])
print(conv_3d.weight)
##out:每个通道的卷积核参数不同
#Parameter containing:
#tensor([[[[[-0.2320, -0.1497, -0.0779],
# [-0.0511, -0.1489, -0.0866],
# [ 0.1233, -0.2222, 0.0528]],
# [[-0.0779, 0.2237, -0.0941],
# [ 0.0026, 0.0426, 0.2323],
# [ 0.2230, -0.0586, 0.2127]]]],
# [[[[ 0.0393, -0.0342, -0.1338],
# [ 0.0640, 0.0879, -0.2289],
# [-0.0047, -0.1611, 0.2131]],
# [[ 0.1573, -0.0108, 0.2327],
# [-0.0824, -0.1601, -0.2348],
# [ 0.1938, -0.0731, 0.1490]]]]], requires_grad=True)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)