SimMTM: A Simple Pre-Training Framework for Masked Time-Series Modeling
时间序列分析有着广泛的应用领域。最近,为了减少标签费用并有利于各种任务,自监督预训练引起了人们的极大兴趣。一种主流范式是屏蔽建模,它通过学习基于未屏蔽部分重建屏蔽内容来成功地预训练深度模型。然而,由于时间序列的语义信息主要包含在时间变化中,随机屏蔽部分时间点的标准方法将严重破坏时间序列的重要时间变化,使得重建任务难以指导表示学习。因此,我们提出了 SimMTM,一个用于掩蔽时间序列建模的简单预训练
系列文章目录
SimMTM:用于掩模时间序列建模的简单预训练框架 NeurIPS 2023
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
摘要
时间序列分析有着广泛的应用领域。 最近,为了减少标签费用并有利于各种任务,自监督预训练引起了人们的极大兴趣。 一种主流范式是屏蔽建模,它通过学习基于未屏蔽部分重建屏蔽内容来成功地预训练深度模型。 然而,由于时间序列的语义信息主要包含在时间变化中,随机屏蔽部分时间点的标准方法将严重破坏时间序列的重要时间变化,使得重建任务难以指导表示学习。 因此,我们提出了 SimMTM,一个用于掩蔽时间序列建模的简单预训练框架。 通过将屏蔽建模与流形学习相关联,SimMTM 提出通过流形外部多个邻居的加权聚合来恢复屏蔽时间点,这通过组装多个屏蔽序列中被破坏但互补的时间变化来简化重建任务。 SimMTM 进一步学习揭示流形的局部结构,这有助于掩模建模。 实验上,与最先进的时间序列预训练方法相比,SimMTM 在预测和分类这两个典型时间序列分析任务中实现了最先进的微调性能,涵盖域内和跨域设置。 代码可在 https://github.com/thuml/SimMTM 获取。
提示:以下是本篇文章正文内容
一、引言
时间序列分析在广泛的现实应用中非常重要,例如金融分析、能源规划等[47, 51]。 从物联网和可穿戴设备中逐渐收集大量时间序列。 然而,时间序列的语义信息主要隐藏在人类无法察觉的时间变化中,导致标注困难。 最近,自监督预训练得到了广泛的探索[23, 15],它有利于从大规模未标记数据上学习的借口知识中获得深层模型,并进一步提高各种下游任务的性能。 主要是,作为一种公认的预训练范式,掩模建模在许多领域取得了巨大的成功,例如掩模语言建模(MLM)[7,31,32,3,10]和掩模图像建模(MIM)[11] , 50, 20]。 本文将预训练方法扩展到时间序列,特别是掩模时间序列建模(MTM)。
屏蔽建模的规范技术是通过学习基于未屏蔽部分重建屏蔽内容来优化模型[7]。 然而,与图像和自然语言的块或单词包含大量甚至冗余的语义信息不同,我们观察到时间序列的有价值的语义信息主要包含在时间变化中,例如趋势、周期性和峰谷,它们可以对应 现实世界中独特的天气过程、异常故障等。 因此,直接屏蔽一部分时间点会严重破坏原始时间序列的时间变化,这使得重建任务难以指导时间序列的表示学习。 (图1)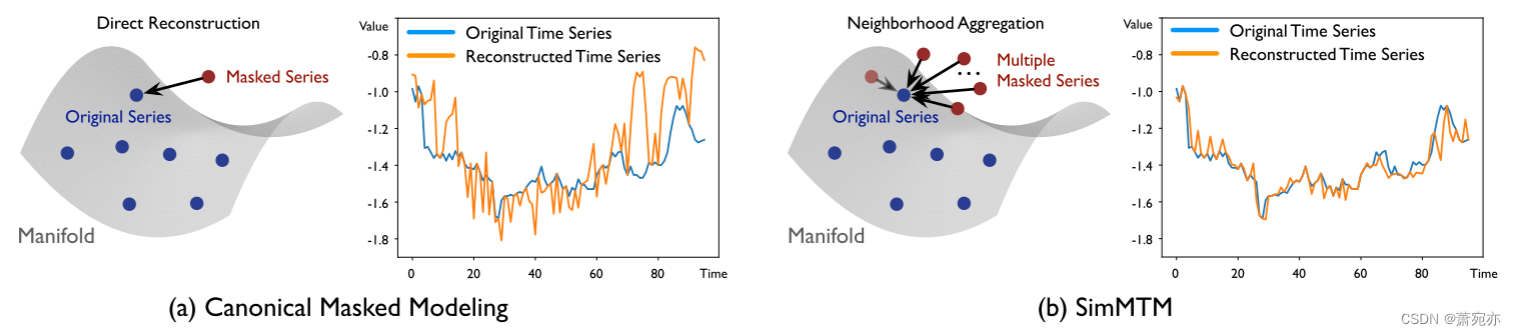
图 1:(a) 规范掩模建模和 (b) SimMTM 在流形视角和重建性能方面的比较。 展示的是恢复 50% 的屏蔽时间序列。
根据堆叠去噪自动编码器[40]的分析,如图1所示,我们可以将随机屏蔽序列视为流形外原始时间序列的“邻居”,而重建过程是将屏蔽序列投影回 原始系列的流形。 然而,正如我们上面分析的,直接重建可能会失败,因为基本的时间变化被随机掩蔽破坏了。 受流形视角的启发,我们超越了掩模建模的直接重建惯例,并提出了从多个“邻居”(即多个掩模序列)重建原始数据的自然想法。 尽管原始时间序列的时间变化在每个随机屏蔽序列中已被部分删除,但多个随机屏蔽序列将相互补充,使得重建过程比直接从单个屏蔽序列重建原始序列更容易。 这个过程还将预训练模型以隐式地揭示时间序列流形的局部结构,从而有利于掩蔽建模和表示学习[35, 41]。
基于上述见解,我们在本文中提出 SimMTM 作为一种简单但有效的时间序列预训练框架。 SimMTM 不是直接从未屏蔽部分重建屏蔽时间点,而是从多个随机屏蔽时间序列中恢复原始时间序列。 从技术上讲,SimMTM 提出了一种用于重建的邻域聚合设计,即根据在系列表示空间中学习到的相似性来聚合时间序列的逐点表示。 除了重建损失之外,还提出了约束损失来指导基于时间序列流形的邻域假设的序列表示学习。 在上述设计的支持下,SimMTM 在将预训练模型微调到下游任务时,在各种时间序列分析任务中实现了一致的最先进水平,涵盖低级预测和高级分类任务,即使 预训练和微调数据集之间存在明显的领域转变。 总的来说,我们的贡献总结如下:
• 受掩蔽流形视角的启发,我们提出了掩蔽时间序列建模的新任务,即基于流形外的多个掩蔽序列重建流形上的原始时间序列。
• 从技术上讲,我们将 SimMTM 作为一个简单但有效的预训练框架,它根据在系列表示空间中学习的相似性聚合逐点表示以进行重建。
• SimMTM 在典型的时间序列分析任务中始终如一地实现最先进的微调性能,包括低级预测和高级分类,涵盖域内和跨域设置。
二、 相关工作
2.1 自监督预训练
自监督预训练是从大规模数据中学习可泛化和共享知识并进一步有利于下游任务的重要研究课题[15]。 最初,这个话题在计算机视觉和自然语言处理领域得到了广泛的探索。 提出了精心设计的手动自监督任务,可大致分为对比学习 [12, 5, 4] 和屏蔽建模 [7, 11]。 最近,遵循完善的对比学习和掩模建模范式,提出了一些时间序列的自监督预训练方法[9,27,34,33,36,54,52,6]。
对比学习。 对比学习的关键见解是根据手动设计的正负对来优化表示空间。 其中正对的表示被优化为彼此接近。 相反,负面的往往相距很远 [48, 14]。 SimCLR [37] 中提出的规范设计将同一样本的不同增强视为正对,将不同样本之间的增强视为负对。
最近,在时间序列预训练中,利用时间序列的不变性,提出了许多正负对的设计。 具体来说,为了使表示学习与时间变化无缝相关,TimCLR [53] 采用 DTW [25] 来生成相移和幅度变化增强,这更适合时间序列上下文。 TS2Vec [55]将多个时间序列分割成多个补丁,并进一步定义了实例和补丁方面的对比损失。 TS-TCC [8] 提出了一种新的时间对比学习任务,使增强预测彼此的未来。 混合[45]利用了一种数据增强方案,其中通过混合两个数据样本来生成新样本。 LaST [42] 旨在基于变分推理解开潜在空间中的季节趋势表示。 随后,CoST [46] 在时域和频域中采用对比损失来学习有区别的季节性和趋势表示。 此外,TF-C[57]提出了一种新颖的时频一致性架构,并优化同一示例的基于时间和基于频率的表示,使其彼此接近。 请注意,对比学习主要关注高级信息[49],而系列或补丁表示本质上与低级任务(例如时间序列预测)不匹配。 因此,在本文中,我们重点关注掩模建模范式。
蒙面造型。 屏蔽建模范例通过学习从未屏蔽部分重建屏蔽内容来优化模型。 这种范式在计算机视觉和自然语言处理中得到了广泛的探索,即分别预测句子的屏蔽词[7]和图像的屏蔽补丁[2,11,50]。 对于时间序列分析,TST [56]遵循规范的掩模建模范式,并学习根据剩余时间点预测删除的时间点。 接下来,PatchTST [26]提出预测屏蔽子系列级补丁以捕获局部语义信息并减少内存使用。 Ti-MAE [21] 使用掩模建模作为辅助任务来提高基于 Transformer 的先进方法的预测和分类性能。 然而,正如我们之前所说,直接屏蔽时间序列会破坏基本的时间变化,使得重建太难指导表示学习。 与之前工作中的直接重建不同,SimMTM 提出了一种新的屏蔽建模任务,即从多个随机屏蔽序列中重建原始时间序列。
2.2 Understanding Masked Modeling
掩蔽建模已在堆叠去噪自动编码器中进行了探索[40],其中掩蔽被视为向原始数据添加噪声,而掩蔽建模是将掩蔽数据从邻域投影回原始流形,即去噪。 它最近被广泛应用于预训练,可以无监督地从数据中学习有价值的低级信息[49]。 受流形视角的启发,我们超越了经典的去噪过程,通过聚合邻域内的多个屏蔽时间序列将屏蔽数据投影回流形。
三、SimMTM
如上所述,为了解决随机屏蔽时间序列会破坏本质时间变化信息的问题,SimMTM提出从多个屏蔽时间序列重建原始时间序列。 为了实现这一点,SimMTM 首先学习系列表示空间中多个时间序列之间的相似性,然后根据预先学习的系列相似性聚合这些时间序列的逐点表示。 接下来,我们将详细介绍模型架构和预训练协议方面的技术。
3.1 整体架构
SimMTM的重建过程涉及以下四个模块:掩蔽、表示学习、系列相似性学习和点式重建。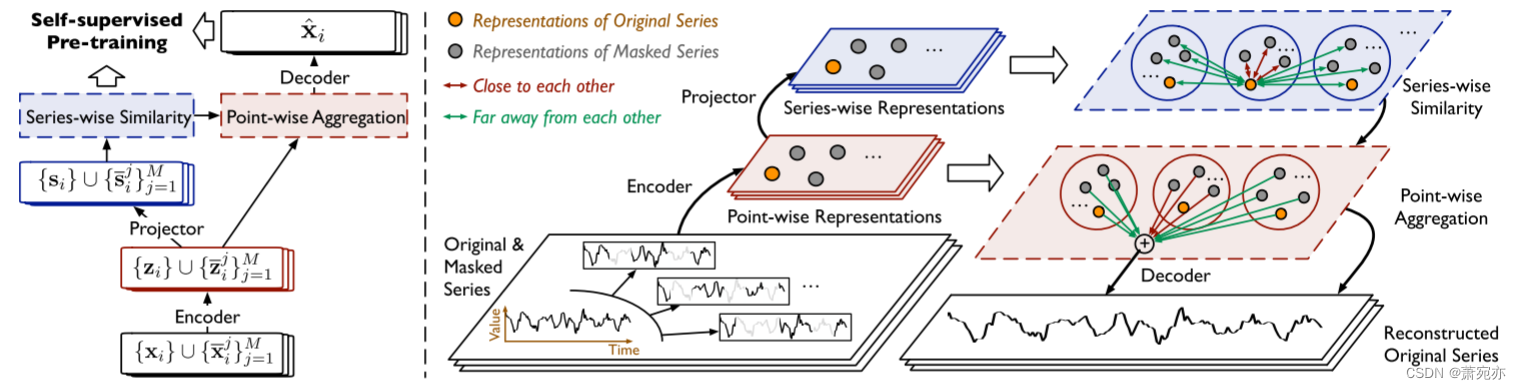
图2:SimMTM的架构,它通过自适应聚合多个屏蔽时间序列来重建原始时间序列,基于从数据中对比学习到的
序列方式的相似性。
MASKING 给定 { x i } i = 1 N \{\mathbf{x}_i\}_{i=1}^N {xi}i=1N作为N个时间序列样本的小批次,其中 x i ∈ R L × C \mathbf{x}_i\in\mathbb{R}^{L\times C} xi∈RL×C包含L个时间点和C个观测变量,我们可以通过沿时间维度随机屏蔽一部分时间点,为每个样本 x i x_i xi生成一组屏蔽序列,形式化如下:
{ x ‾ i j } j = 1 M = M a s k r ( x i ) , \{\overline{\mathbf{x}}_i^j\}_{j=1}^M=\mathrm{Mask}_r(\mathbf{x}_i), {xij}j=1M=Maskr(xi),
其中 r ∈ [ 0 , 1 ] r\in[0,1] r∈[0,1]表示被屏蔽的部分。M是掩蔽时间序列数量的超平行网络。 x ‾ i j ∈ R L × C \overline{\mathbf{x}}_i^j\in\mathbb{R}^{L\times C} xij∈RL×C表示 x i x_i xi的第j个掩蔽时间序列,其中掩蔽时间点的值被零替换。通过上述过程,我们可以得到一批增广的时间序列。
为了清楚起见,我们将所有的 ( N ( M + 1 ) ) (N(M+1)) (N(M+1))输入序列表示为 X = ⋃ i = 1 N ( { x i } ∪ { x ‾ i j } j = 1 M ) \mathcal{X}=\bigcup_{i=1}^{N}\left(\{\mathbf{x}_{i}\}\cup\{\overline{\mathbf{x}}_{i}^{j}\}_{j=1}^{M}\right) X=⋃i=1N({xi}∪{xij}j=1M)。
表象学习。在编码器和投影器层之后,我们可以获得逐点表示Z和逐串表示S,它们可以形式化
为: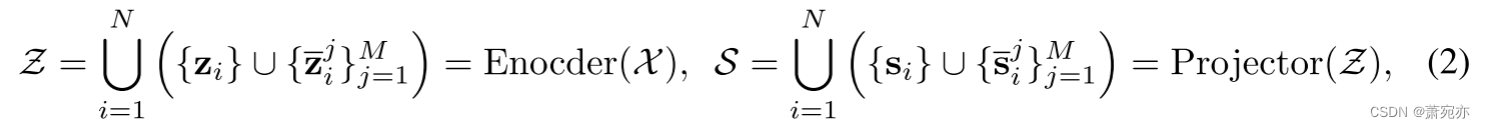
其中 z i , z ˉ i j ∈ R L × d m o d e l a n d s i , s ˉ i j ∈ R 1 × d m o d e l . \mathbf{z}_i,\mathbf{\bar{z}}_i^j\in\mathbb{R}^{L\times d_{\mathrm{model}}}\mathrm{~and~}\mathbf{s}_i,\mathbf{\bar{s}}_i^j\in\mathbb{R}^{1\times d_{\mathrm{model}}}. zi,zˉij∈RL×dmodel and si,sˉij∈R1×dmodel.。 Encoder(·)表示模型编码器,它可以将输入数据投影为深度表示,并在微调过程中传输到下游任务。 在本文中,我们将编码器实现为公认的 Transformer [39] 和 ResNet [13]。 对于 Projector(·),我们沿时间维度采用简单的 MLP 层来获得系列表示。 更多细节可以在第 4 节中找到。从技术上讲,编码器单独应用于输入序列,即 ⋃ i = 1 N ( E n c o d e r ( x i ) ∪ { E n c o d e r ( x ‾ i j ) } j = 1 M ) \bigcup_{i=1}^N(\mathrm{Encoder}(\mathbf{x}_i)\cup\{\mathrm{Encoder}(\mathbf{\overline{x}}_i^j)\}_{j=1}^M) ⋃i=1N(Encoder(xi)∪{Encoder(xij)}j=1M),投影也是如此。 为了简洁起见,这里我们采用集合式形式化。
系列相似性学习。 请注意,直接对多个屏蔽时间序列进行平均将导致过度平滑问题[40],从而阻碍表示学习。 因此,为了精确地重建原始时间序列,我们尝试利用系列表示 S 之间的相似性进行加权聚合,即利用时间序列流形的局部结构。 为了简化,我们将系列相似度的计算形式化如下:
R = S i m ( S ) ∈ R D × D , D = N ( M + 1 ) , R u , v = u v T ∥ u ∥ ∥ v ∥ , u , v ∈ S , \mathbf{R}=\mathrm{Sim}(\mathcal{S})\in\mathbb{R}^{D\times D},D=N(M+1),\quad\mathbf{R}_{\mathbf{u},\mathbf{v}}=\frac{\mathbf{u}\mathbf{v}^{\mathsf{T}}}{\|\mathbf{u}\|\|\mathbf{v}\|},\mathbf{u},\mathbf{v}\in\mathcal{S}, R=Sim(S)∈RD×D,D=N(M+1),Ru,v=∥u∥∥v∥uvT,u,v∈S,
其中 R 是串联表示空间中 (N(M+ 1)) 个输入样本的成对相似度矩阵,通过余弦距离来测量。 Ru,v 是串联表示 u, v ∈ S 之间计算的相似度。
逐点聚合。 如图2所示,基于学习到的序列相似性,第i个原始时间序列的聚合过程为:
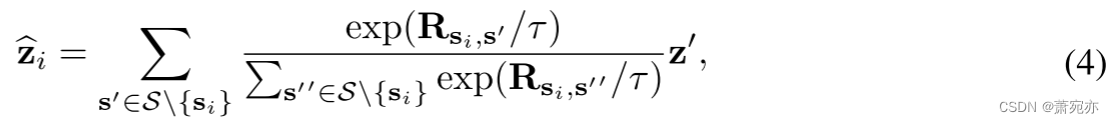
其中 z′ 表示 s′ 对应的逐点表示,即 z ′ = Projector ( s ′ ) \begin{aligned}\mathbf{z}'&=\text{Projector}(\mathbf{s}')\end{aligned} z′=Projector(s′)。 $\widehat{\mathbf{z}}_i\in $ R L × d m o d e l \mathbb{R}^{L\times d_{\mathrm{model}}} RL×dmodel 是重建的逐点表示。 τ 表示用于系列相似性的 softmax 归一化的温度超参数。 值得注意的是,如方程式中所述。 (4),对于每个时间序列xi,重建不仅仅基于其自身的屏蔽序列 { x ‾ i j } j = 1 M . \{\overline{\mathbf{x}}_i^j\}_{j=1}^M. {xij}j=1M.。 我们还将其他序列表示 S \ { s i } \mathcal{S}\backslash\{\mathbf{s}_{i}\} S\{si}引入到聚合中,这要求模型抑制相关性较小的噪声序列的干扰,并精确地学习屏蔽序列和原始序列的相似表示,即引导模型学习流形 结构更好。 经过解码器之后,我们可以得到重构后的原始时间序列,即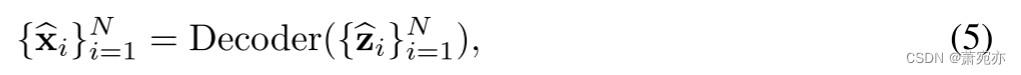
其中 x ^ i ∈ R L × C \widehat{\mathbf{x}}_i\in\mathbb{R}^{L\times C} x
i∈RL×C是对 x i x_i xi的重建。decoder(·)被实例化为沿着以下信道维度的简单MLP层[50]
3.2 自监督预训练
遵循掩模建模范例,SimMTM 由重建损失来监督:
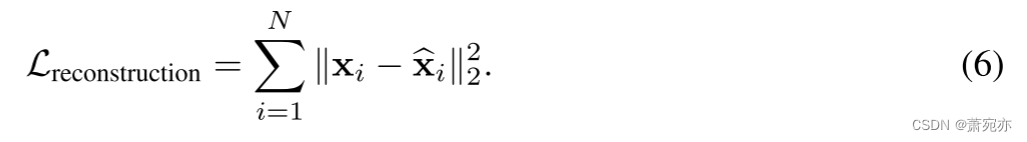
请注意,重建过程直接基于系列相似性,而在系列表示空间中没有明确约束的情况下,很难保证模型捕获精确的相似性。 因此,为了避免琐碎聚合,我们还利用时间序列流形的邻域假设来校准序列表示空间 S 的结构。为了清楚起见,我们通过定义正负对来形式化邻域假设,如下所示: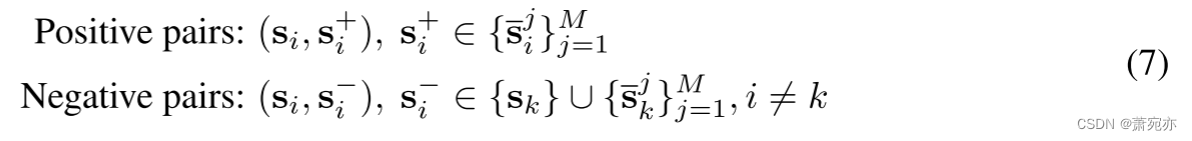 其中 s i + and s i − \mathbf{s}_i^+\text{ and }\mathbf{s}_i^- si+ and si−分别表示假设距离 si 较近和较远的元素。 等式。 (7) 表明原始时间序列及其屏蔽序列将呈现接近的表示,并且远离 S 中其他序列的表示。对于每个系列表示 s ∈ S,我们将其假设的接近序列的集合定义为 S + ⊂ S \mathcal{S}^+\subset\mathcal{S} S+⊂S。请注意,为了避免主导表示,我们假设 s ∉ S + \mathrm{s}\notin\mathcal{S}^{+} s∈/S+。 通过上述形式化,我们可以将级数表示空间的流形约束定义为:
其中 s i + and s i − \mathbf{s}_i^+\text{ and }\mathbf{s}_i^- si+ and si−分别表示假设距离 si 较近和较远的元素。 等式。 (7) 表明原始时间序列及其屏蔽序列将呈现接近的表示,并且远离 S 中其他序列的表示。对于每个系列表示 s ∈ S,我们将其假设的接近序列的集合定义为 S + ⊂ S \mathcal{S}^+\subset\mathcal{S} S+⊂S。请注意,为了避免主导表示,我们假设 s ∉ S + \mathrm{s}\notin\mathcal{S}^{+} s∈/S+。 通过上述形式化,我们可以将级数表示空间的流形约束定义为: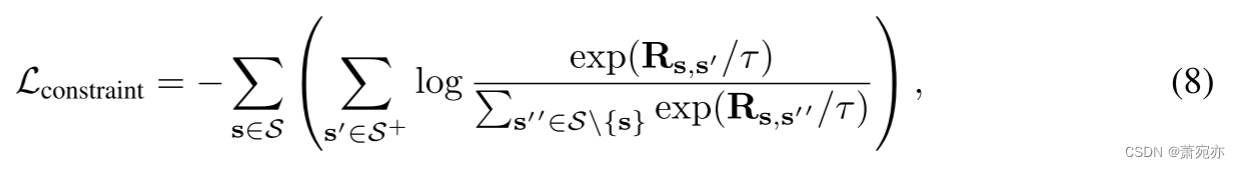
它可以优化学习的系列表示以满足方程中的邻域假设。 (7)更好。 最后,SimMTM的整体优化流程可以表示为: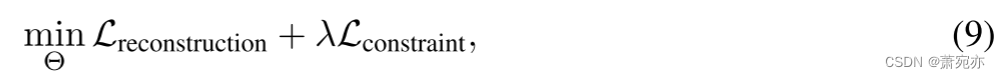
其中 θ 表示深层架构的所有参数的集合。 权衡方程式中的两个部分。 (9),我们采用[17]提出的调整策略,它可以根据每个损失的同方差不确定性自适应地调整超参数λ。
四、实验
为了全面评估SimMTM,我们对两个典型的时间序列分析任务进行了实验:预测和分类,涵盖低级和高级表示学习。 此外,我们还展示了在域内和跨域设置下每个任务的微调性能。
基准。 我们在表1中总结了实验基准,包括12个现实世界数据集,涵盖两个主流时间序列分析任务:时间序列预测和分类。 具体来说,我们遵循 Autoformer [47] 中的标准实验设置进行预测任务,并遵循 TF-C [57] 提出的分类实验设置。
实施。 我们将 SimMTM 与六种最先进的竞争基线方法进行比较,包括对比学习方法:TF-C [57]、CoST [46]、TS2Vec [55]、LaST [42],掩模建模方法:TiMAE [21],TST [56]。 TF-C [57]和TiMAE [21]是之前最好的预训练方法。 我们对域内和跨域设置进行实验。 对于域内设置,我们使用相同的数据集对模型进行预训练和微调。 至于跨域设置,我们在某个数据集上预训练模型,并针对不同的数据集微调编码器。 附录 A 提供了更多详细信息。
统一编码器。 为了进行公平的比较,我们尝试统一这些预训练方法的编码器。 具体来说,我们采用具有通道独立性[26]的vanilla Transformer [39]作为预测的统一编码器。 通道无关的设计使得模型能够完成不同变量数的数据集之间的跨域传输。 至于分类,我们使用 1D-ResNet [13] 作为[57]之后的共享编码器。 值得注意的是,对于LaST [42]和TFC [57],由于它们的设计与模型结构密切相关,我们直接报告他们论文的结果或用官方代码重现。 对于其他基线和SimMTM,正文中的结果来自统一编码器。 附录 A.2 中还比较了他们官方论文的结果。 对于所有基线,统一编码器的结果通常超过它们自己报告的结果。
4.1 主要结果
我们在图 3 中总结了域内和跨域设置的预测和分类结果。在所有这些设置中,SimMTM 显着优于其他基线。 还值得注意的是,虽然基于掩蔽的方法 Ti-MAE [21] 在预测任务(图 3 的 x 轴)中取得了良好的性能,但在分类任务(y 轴)中却失败了。 此外,基于对比的方法在低水平的预测任务中失败。 这些结果表明,以前的方法无法同时覆盖高层和低层任务,凸显了 SimMTM 在任务通用性方面的优势。
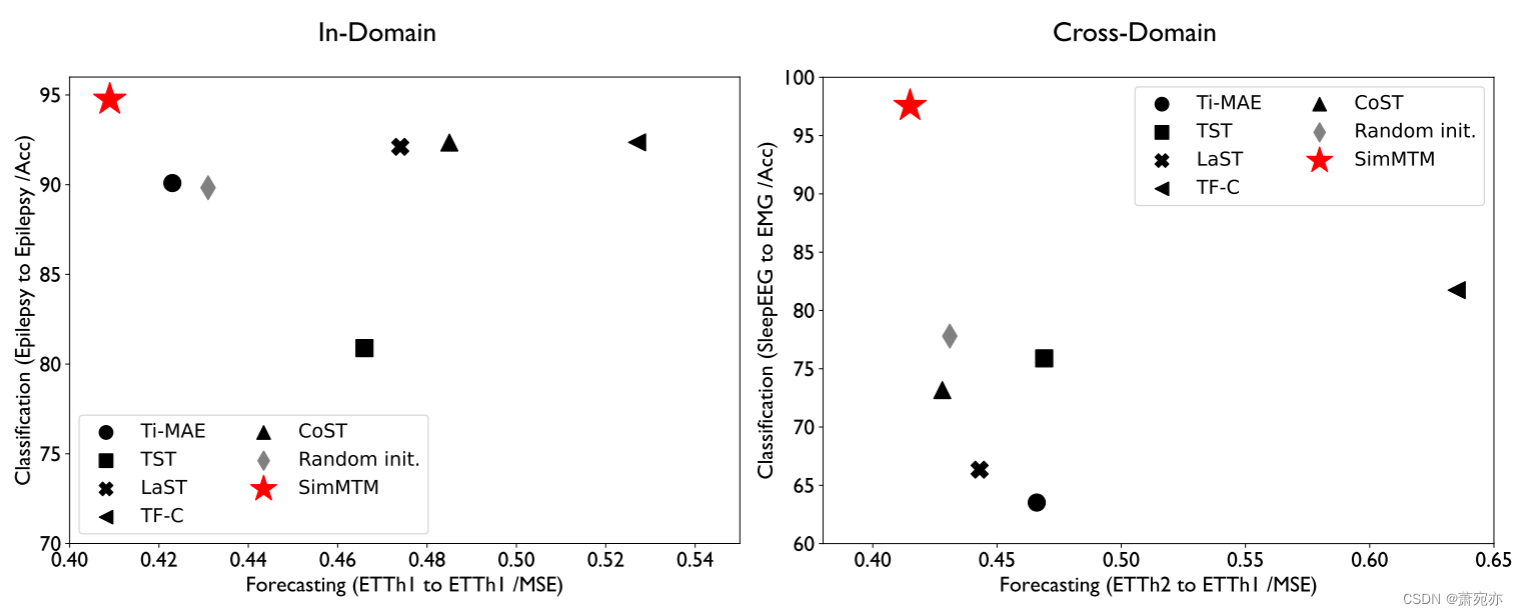
图 3:时间序列预训练方法在预测 (MSE ↓) 和分类 (Acc ↑) 任务中的性能比较,包括域内(左)和跨域(右)设置。
4.2 预测
域内。 如表2所示,通过SimMTM预训练的赋能,模型性能得到显着提升(SimMTM vs. Random init.)。 此外,SimMTM 始终优于其他预训练方法。 就所有基准的平均值而言,与高级掩模建模基线 Ti-MAE [21] 相比,SimMTM 实现了 8.3% MSE 降低和 4.3% MAE 降低,与对比基线 CoST [46] 相比,SimMTM 实现了 14.7% MSE 降低和 12.0% MAE 降低 。 还值得注意的是,Ti-MAE [21] 和 TST [56] 都优于所有基于对比的基线。 这表明基于逐点重建的掩模建模比逐序列对比预训练更适合预测任务。
表2:基于过去336个时间点预测未来O时间点的域内设置。 所有结果都是 O ∈ {96, 192, 336, 720} 4 个不同选择的平均值。 MSE 或 MAE 越小表示预测越好。 完整结果请参见附录 E。

表3:基于过去336个时间点预测未来O时间点的跨域设置。 所有结果都是 O ∈ {96, 192, 336, 720} 4 个不同选择的平均值。 MSE 或 MAE 越低表示预测越好。 完整结果见附录 E。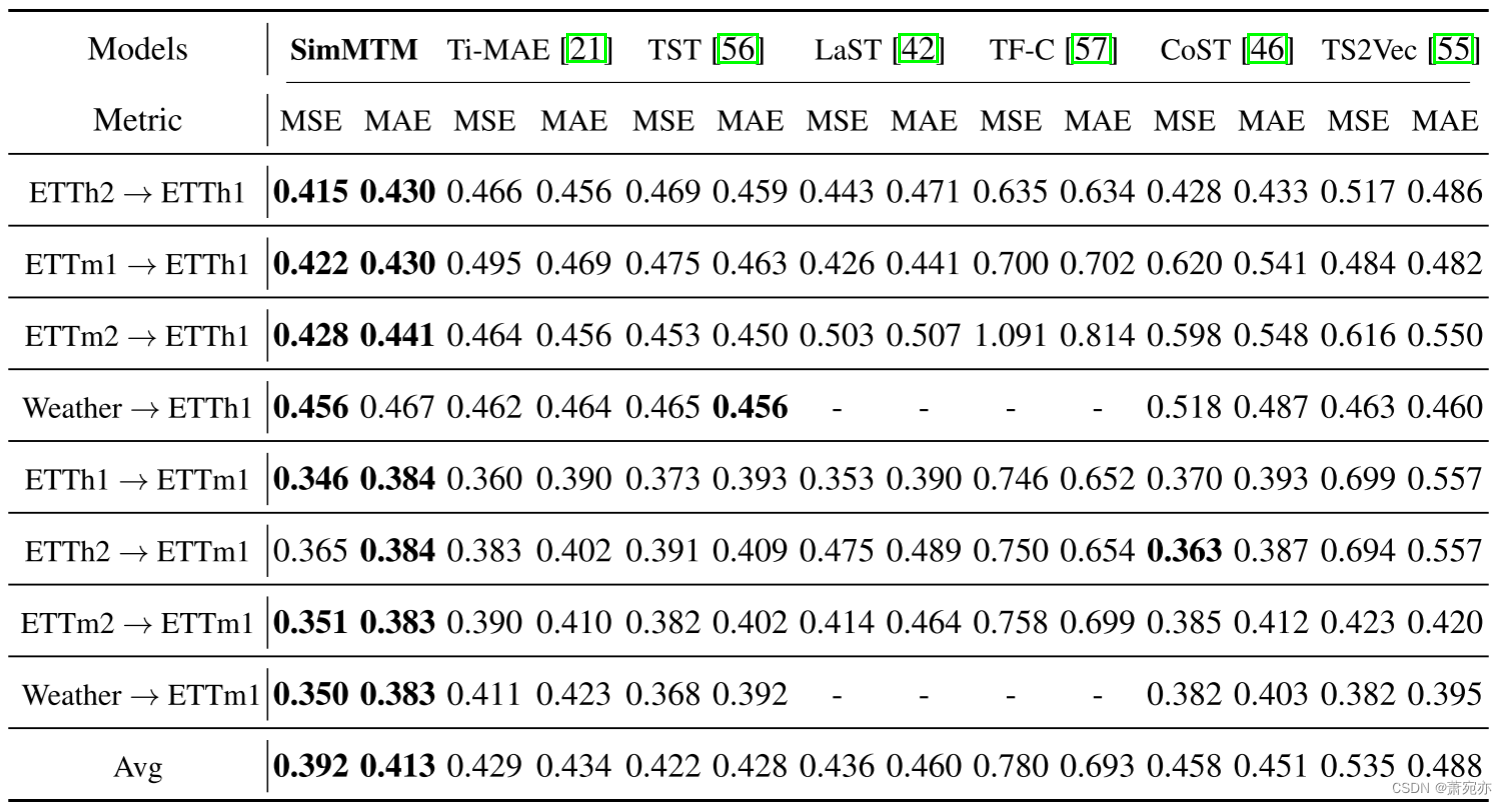
跨域。 如表 3 所示,我们提出了多种场景来验证跨域设置下的有效性,其中 SimMTM 始终优于其他基线。 请注意,通道无关的编码器使比较基线能够在具有不同变量数的数据集之间传输预训练模型:天气 → {ETTh1,ETTm1}。 但对于特定模型设计的LaST和TF-C来说,它们无法应用于这些场景。 虽然在一些跨域场景中观察到负迁移,例如天气 → ETTh1 和 ETTh2 → ETTm1,但 SimMTM 总体上仍然显着优于其他基线。
表 4:分类的域内和跨域设置。 对于域内设置,我们在同一数据集 Epilepsy 上预训练和微调模型。 对于跨域设置,我们在 SleepEEG 上预训练模型,并将其微调到多个目标数据集:癫痫、FD-B、手势、肌电图。 记录准确度 (%) 分数。 完整结果包含在附录 E 中。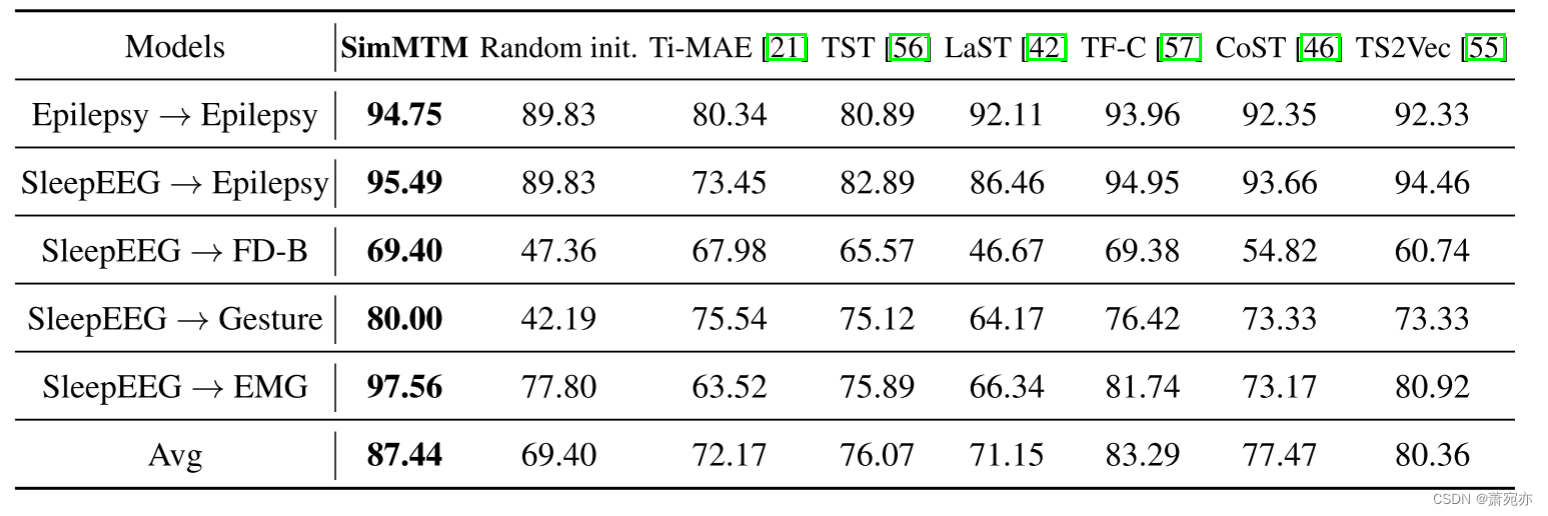
图 4:在域内和跨域设置下,SimMTM 对时间序列预测(左部分)和分类(右部分)任务中的重建损失 (Lrec.) 和约束损失 (Lcon.) 的消融。 更多消融包含在附录 E 中。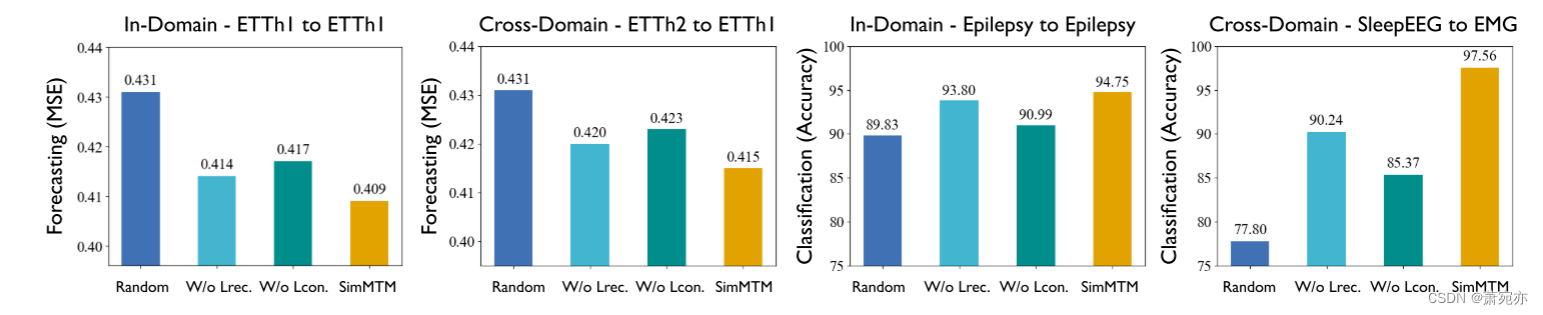
4.3 分类
域内。 我们研究了表 4 中分类任务的域内预训练效果。请注意,与预测不同,分类任务要求模型学习高级时间序列表示。 从表4中我们可以发现对比预训练基线实现了有竞争力的表现。 相比之下,基于掩蔽的模型Ti-MAE [21]和TST [56]表现不佳,与随机初始化相比,TST甚至表现出负迁移现象,表明对比学习通常更适合分类任务。 令人惊讶的是,尽管SimMTM遵循掩模建模范式,但通过我们专门设计的重建任务,它仍然可以在分类任务中取得最佳性能。 这得益于多个屏蔽序列的邻域聚合,这使得模型能够利用时间序列流形的局部结构。
跨域。 我们实验了表 4 中的四种跨域传输场景:SleepEEG → {Epilepsy、FD-B、Gesture、EMG},其中目标数据集与预训练数据集不同。 由于预训练和微调数据集之间存在较大差距,大多数情况下基线表现不佳,而 SimMTM 仍然显着超越其他基线和随机初始化。 特别是对于 SleepEEG → EMG,SimMTM 显着超越了之前最先进的 TF-C(准确率:97.56% vs. 81.74%)。 这些结果表明 SimMTM 可以从预训练数据集中精确捕获有价值的知识,并使广泛的下游数据集一致受益。
4.4 模型分析
消融。 如图 4 所示,我们在 SimMTM 中对训练损失的两个部分进行了消融。 据观察,Lreconstruction 和 Lconstraint 对于最终性能都是至关重要的。 特别是,对于 SleepEEG→EMG 实验,SimMTM 显着超越了随机初始化,其中重建和约束损失分别提供了 9.7% 和 16.0% 的绝对改进。 此外,我们还可以发现,与Lreconstruction相比,Lconstraint对最终结果的贡献更大。 这来自我们的设计,即约束损失揭示了一个适当的时间序列流形,有助于从多个屏蔽序列进行重建,否则邻域聚合将退化为平凡的平均值。
表 5:分类和预测任务中不同方法的表征分析。 对于每个模型,我们计算第一个和最后一个编码器层的表示之间的中心核对齐(CKA)相似度(%)[18],以衡量深度模型的表示学习属性。 由于底层表示通常包含低级或详细信息,较小的 CKA 相似度意味着顶层包含与底层不同的信息,表明模型倾向于学习高级表示或更抽象的信息。 为了进行比较,我们还计算了|ΔCKA| 预训练和微调模型之间的关系,其中较小的值表示预训练和微调之间的表示差距较小,并且表示具有更强的通用性和可移植性。
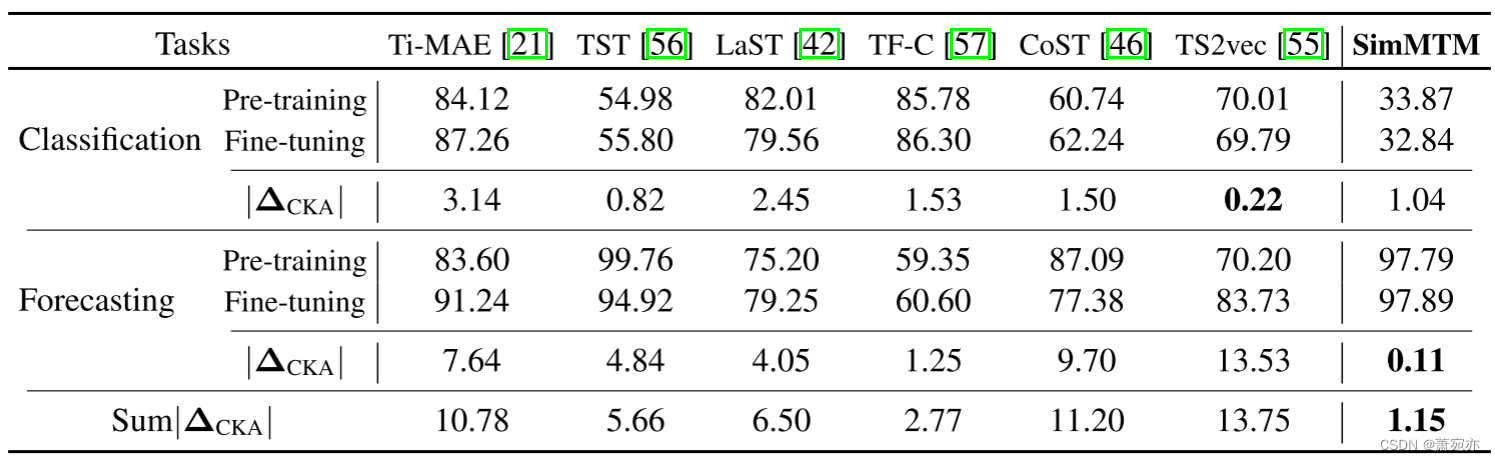
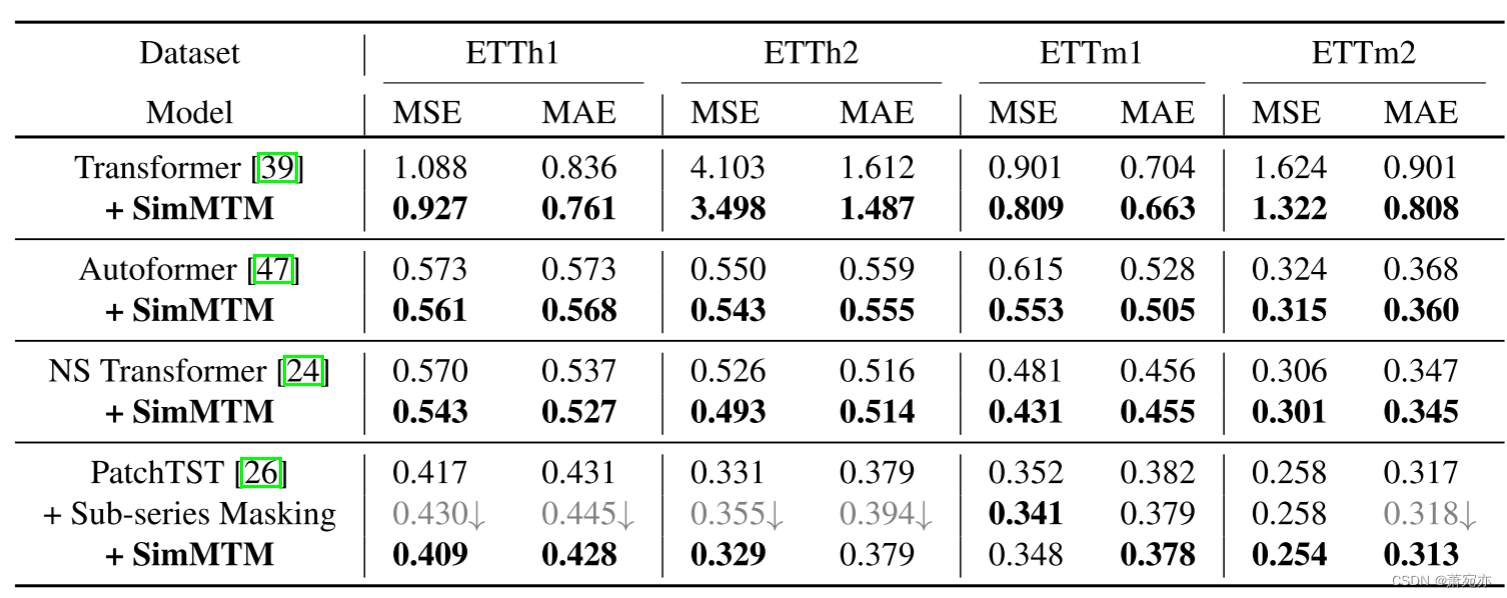
表 6:在域内设置下将 SimMTM 应用于四个高级时间序列预测模型的性能。 “+ Sub-series Masking”是指PatchTST[26]本身提出的子系列masking建模预训练方法。 MSE 和 MAE 是 {96,192,336,720} 中所有预测长度的平均值。 每个预测范围的详细结果参见附录 E。
代表性分析。 为了直观地说明 SimMTM 的优势,我们在表 5 中提供了代表性分析,其中我们可以找到以下观察结果。 首先,我们可以发现SimMTM在分类任务中的CKA值明显小于预测任务中的值,前者是高级任务,后者需要低级表示。 这些结果表明 SimMTM 可以学习不同任务的自适应表示,这可以受益于我们在预训练损失中的设计。 具体来说,分类预训练数据集的时间变化比预测数据集更加多样化。 这样,Lconstraint将更容易分类优化,得到更小的CKA值。 其次,从 |ΔCKA| 可以看出,SimMTM 预训练的模型在表示学习属性方面相对于最终的微调模型差距较小,这就是 SimMTM 能够持续改进下游任务的原因。
模型的通用性。 从表6中我们可以发现,作为通用时间序列预训练框架,SimMTM可以持续提高各种高级基础模型的预测性能,甚至对于最先进的时间序列预测模型PatchTST[26]也是如此。 这种通用性也表明我们可以通过采用高级基础模型作为编码器来进一步提高模型的性能。 还值得注意的是,与 PatchTST 论文 [26] 中使用的规范子系列掩模建模引起的负迁移现象不同,SimMTM 的一致性改进进一步验证了我们设计的有效性。
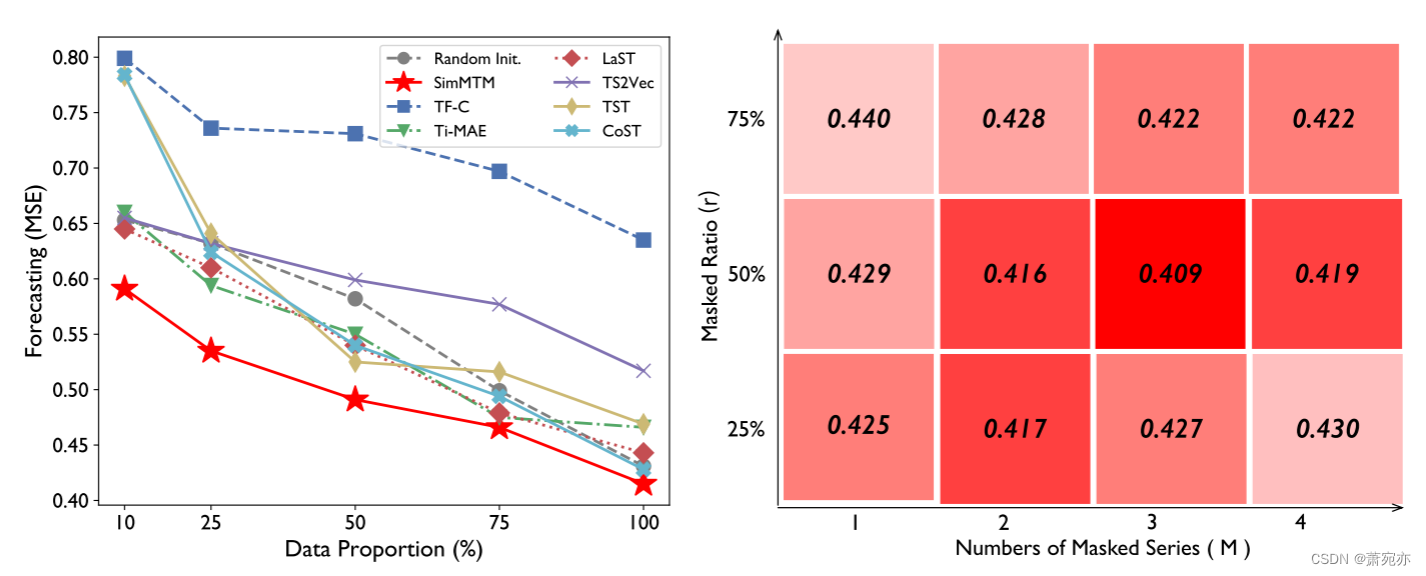
图 5:模型分析。 左侧部分用于使用有限的数据将 ETTh2 预训练模型微调为 ETTh1,其中较小的 MSE 表示更好的性能。 右侧部分展示了 SimMTM 在 ETTh1“input-336-predict-96”域内设置中具有不同屏蔽比率 r 和屏蔽序列 M 数量的 MSE 性能,其中深红色表示性能更好。
针对有限的数据场景进行微调。 预训练模型的一个重要应用是为下游任务提供先验知识,特别是对于有限的数据场景,这对于深度模型的快速适应至关重要。 因此,为了验证 SimMTM 和其他预训练方法在数据有限的场景中的有效性,我们在 ETTh2 上预训练一个模型,并通过对剩余训练数据比例的不同选择将其微调到 ETTh1。 所有结果如图5所示。我们可以发现,与其他时间序列预训练方法相比,SimMTM在不同数据比例下取得了显着的性能提升。 具体来说,对于 10% 的数据微调设置,SimMTM 显着优于基于掩蔽的高级方法 Ti-MAE [21](MSE:0.591 与 0.660)。 与基于对比的方法 TF-C [57] 相比,SimMTM 还实现了 26.0% 的 MSE 降低。 这些结果进一步验证了SimMTM即使在有限的数据场景下也可以有效地从数据集中捕获有价值的知识并提升最终性能。
掩蔽策略。 请注意,重建原始时间序列的难度随着屏蔽比率的增加而增加,但随着邻近屏蔽序列数量的增加而降低。 我们探讨了遮蔽比率与用于重建的遮蔽序列的数量之间的潜在关系,即等式中的r和M。 (1) 分别。 图5的实验结果表明,我们需要设置M∝r才能获得更好的结果。 实验上,我们选择掩蔽率为50%,并在本文中采用三个掩蔽序列进行重建。 此外,我们可以发现,仅使用一个屏蔽序列(M = 1)进行预训练通常比具有较大 M 的设置表现更差,后者使模型能够发现输入序列与其邻居之间的关系。 直观理解见图1。 这些结果进一步凸显了我们的设计在流形学习方面的优势。
五、 结论
本文介绍了 SimMTM,一个用于屏蔽时间序列建模的简单预训练框架。 SimMTM 超越了之前从未屏蔽时间点重建原始时间序列的惯例,提出了一种新的屏蔽建模任务,即从多个邻居屏蔽序列重建原始序列。 具体来说,SimMTM 基于序列相似性聚合逐点表示,这些相似性受到时间序列流形上的邻域假设的仔细约束。 实验上,SimMTM 可以最大程度地弥合预训练模型和微调模型之间的差距,从而与最先进的时间序列预训练方法相比,在不同的预测和分类任务中实现一致的最新技术,涵盖域内和 跨域设置。 未来,我们将进一步将SimMTM扩展到大规模、多样化的预训练数据集,追求时间序列分析的基础模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)