时间序列分析
时间序列分析在于检验不同时间的样本分布,这里不同时间是以时滞k来说明,一:相同时间的样本分布简单的时间序列比如当k=0时,cov(Yt1,Yt1)cov(Y_{t_1},Y_{t_1})cov(Yt1,Yt1)是为等于方差,所以相同分布,协方差就等于方差,相关系数为1,...
检验时间序列异常变化的简单方法:
利用数据统计来识别数据中可能存在的问题
控制图分析
介绍用于检查时间序列、查找模式和异常变化的数据挖掘技术,
时间序列的分析,通常包括:Trend、Seasonality、Forecasting
以上的预测我们通常采用控制图的分析,重要的是计算平均值和标准差。
时间序列分析在于检验不同时间的样本分布,这里不同时间是以时滞k来说明,
一:相同时间的样本分布
简单的时间序列比如当k=0时,cov(Yt1,Yt1)cov(Y_{t_1},Y_{t_1})cov(Yt1,Yt1)是为等于方差,所以相同分布,协方差就等于方差,相关系数为1,
平稳性检验:
称为ADF检验
平稳性定义:
业务理解:
时间序列预测,主要是预测一段时间的业务变化,kkk时间段后,业务会出现规律变化。
因此在业务上,时间序列的平稳性是数据随时间呈现规律性变化。严平稳序列是完全平稳的,因为其概率密度函数相同,因此其所有的统计特征都是相同的。
数学定义:
统计特性(平均值(E(x)E(x)E(x),方差(var(x)var(x)var(x))))不随时间的变化而变化
1,严平稳
对于一切时间间隔kkk和时间点t1,t2,t3....tnt_1,t_2,t_3....t_nt1,t2,t3....tn,都有Yt1,Yt2,Yt3,....,YtnY_{t_1},Y_{t_2},Y_{t_3},....,Y_{t_n}Yt1,Yt2,Yt3,....,Ytn与Yt1−k,Yt2−k,Yt3−k,....,Ytn−kY_{t_1-k},Y_{t_2-k},Y_{t_3-k},....,Y_{t_n-k}Yt1−k,Yt2−k,Yt3−k,....,Ytn−k的联合分布相同,则称过程Yt{Y_t}Yt为严平稳
2,弱平稳
弱平稳只要求变化过程Yt{Y_t}Yt的均值E(Yt){E(Y_t)}E(Yt)、方差Var(Yt)Var(Y_t)Var(Yt)为不随时间变化的常数,相隔时间kkk的序列协方差只与时间间隔k有关k有关k有关,而与时间t无关,满足以上三个条件被称为弱平稳。
弱平稳序列的自相关系数:
ρk=Cov(xt,xt−k)Var(xt)Var(xt−k)\rho_k=\frac{Cov(x_t, x_{t-k})}{\sqrt{Var(x_t)Var(x_{t-k})}}ρk=Var(xt)Var(xt−k)Cov(xt,xt−k)
由于弱平稳序列的的方差是相同的,所以上式又可以进行变换,ρk=Cov(xt,xt−k)Var(xt)=γkγ0\rho_k=\frac{Cov(x_t, x_{t-k})}{Var(x_t)}=\frac{\gamma_k}{\gamma_0}ρk=Var(xt)Cov(xt,xt−k)=γ0γk
相同时刻的自协方差γ0=Var(x)\gamma_0=Var(x)γ0=Var(x)
kkk可以称为步,差步相关
现实业务中,多数业务会随着时间的变化,呈现规律性的波动上升,因此一阶和二阶的的弱平稳我们也可以定义为弱平稳序列。
阶矩概念:
n阶矩再定义中为样本的n次方与对应概率密度的乘积的积分,矩是对变量分布和样本特点的一组度量。
实际计算中阶矩:
在实际计算中,阶矩代表相同变化趋势的阶段之间的阶段数,在不同阶段内,YtY_tYt与Yt−kY_{t-k}Yt−k表现出一定的相关性。
白噪声:
如果所有的序列观察值YtY_tYt都是独立同分布的,而且均值μ\muμ和方差σ2\sigma^2σ2都是有穷的常数,则称该序列为白噪声或者纯随机序列
白噪声的三个前提条件:
1;有限均值;
2;有限方差;
3;独立同分布
用简单的表达方式:平稳序列是均值μ\muμ和方差σ2\sigma^2σ2为相同值的特殊白噪声。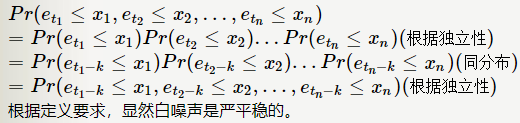
阶、步差分:
阶差分可以剔除趋势性的影响
步差分可以剔除季节性的影响.
实际造成了AR(A),ARIMA(p.d.q)模型的区别
当p,d,q为0的时候,直接去用AR(A)。
实际在运行的过程中,时间序列模型所对应的特征是固定的,所以才会做各种假设。p,d,q所对应的是周期、步长和变化趋势
相关性
针对AR模型
ACF:相关性
是XtX_tXt与Xt−1X_{t-1}Xt−1的相关关系,表达式为r0=COV(Xt,Xt−1)D(Xt)D(Xt−1)r_0=\frac{COV(X_t,X_{t-1})}{\sqrt{D(X_t)}\sqrt{D(X_t-1)}}r0=D(Xt)D(Xt−1)COV(Xt,Xt−1)
ACF刻画的是当前值与前KKK个时刻的之前所有数据的相关关系
PACF:偏自相关性
PACF刻画的是当前XtX_tXt与KKK个时刻之前的Xt−kX_{t-k}Xt−k的关系
图形描述
statsmodels.graphics.tsaplots.plot_acf是画出了在不同延迟时间下,样本与延迟样本的相关性,灰度图像是对应相关性,在95%的置信区间下不可信的区域。
statsmodels.graphics.tsaplots.plot_pacf是画出了在消除时序的影响后,corr((x0−xk),(xt−xk))corr((x_0-x_{k}),(x_t-x_{k}))corr((x0−xk),(xt−xk)),这样就消除了在时间变化过程中出现的一些残差值。
模型评价标准:
对于以往的评价标准是RSS:RSS:RSS:即残差平方和;ESS:ESS:ESS:即离差平方和,一般R2=ESSTSSR^2=\frac{ESS}{TSS}R2=TSSESS,成为样本的可决系数/判定系数
赤信息量 AIC:AIC(K)=sy2(1−R2)e2k/nAIC(K)=s_y^2(1-R^2)e^{2k/n}AIC(K)=sy2(1−R2)e2k/n
贝叶斯信息量 BIC:BIC(K)=sy2(1−R2)ek/nBIC(K)=s_y^2(1-R^2)e^{k/n}BIC(K)=sy2(1−R2)ek/n
k为模型参考个数,n为采样样本数

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)