推荐系统经典模型YouTubeDNN代码
上一篇讲到过YouTubeDNN论文部分内容,但是没有代码部分。最近网上教学视频里看到一段关于YouTubeDNN召回算法的代码,现在我分享一下给大家参考看一下,并附上一些我对代码的理解。代码中提到的离散特征和变长特征该如何选择?答:首先我们要理解一下什么事离散特征,什么是变长特征?离散特征:是指具有有限取值或离散类别的特征,例如性别、国家、城市等(用户画像信息)。对于离散特征,可以使用embed
·
前言
- 上一篇讲到过YouTubeDNN论文部分内容,但是没有代码部分。最近网上教学视频里看到一段关于YouTubeDNN召回算法的代码,现在我分享一下给大家参考看一下,并附上一些我对代码的理解。
数据预处理部分
- 首先我们需要对数据集进行预处理,数据集格式如下图所示
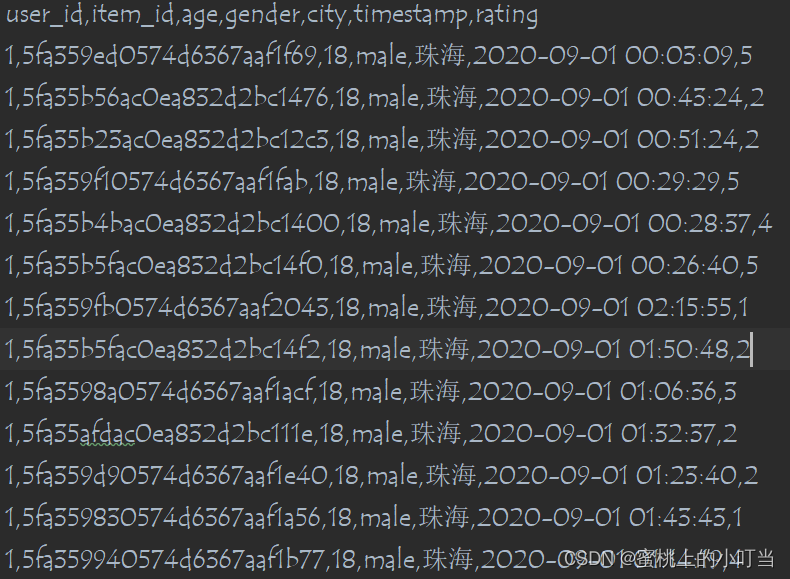
- 根据YouTubeDNN论文,输入的数据是用户的信息、视频的ID序列、用户搜索的特征和一些地理信息等其他信息。到了基于文章内容的信息流产品中,就变成了用户 ID、年龄、性别、城市、阅读的时间戳再加上视频的ID。我们把这些内容可以组合成YouTubeDNN需要的内容,最后处理成需要的Embedding。
from tqdm import tqdm
import numpy as np
import random
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
def gen_data_set(data, negsample=0):
# 根据timestamp排序数据,并替换
data.sort_values("timestamp", inplace=True)
#根据item_id进行去重
item_ids = data['item_id'].unique()
# 构建训练与测试list
train_set = list()
test_set = list()
for reviewrID, hist in tqdm(data.groupby('user_id')):
# 正样本列表
pos_list = hist['item_id'].tolist()
rating_list = hist['rating'].tolist()
if negsample > 0:
# 候选集中去掉用户看过的item项目
candidate_set = list(set(item_ids) - set(pos_list))
# 随机选择负采样样本
neg_list = np.random.choice(candidate_set, size=len(pos_list) * negsample, replace=True)
for i in range(1, len(pos_list)):
if i != len(pos_list) - 1:
# 训练集和测试集划分
train_set.append((reviewrID, hist[::-1], pos_list[i], 1, len(hist[:: -1]), rating_list[i]))
for negi in range(negsample):
train_set.append((reviewrID, hist[::-1], neg_list[i * negsample + negi], 0, len(hist[::-1])))
else:
test_set.append((reviewrID, hist[::-1], pos_list[i], 1, len(hist[::-1]), rating_list[i]))
# 打乱数据集
random.shuffle(train_set)
random.shuffle(test_set)
return train_set, test_set
def gen_model_input(train_set, user_profile, seq_max_len):
# 用户id
train_uid = np.array([line[0] for line in train_set])
# 历史交互序列
train_seq = [line[1] for line in train_set]
# 物品id
train_iid = np.array([line[2] for line in train_set])
# 正负样本标签
train_label = np.array([line[3] for line in train_set])
# 历史交互序列长度
train_hist_len = np.array([line[4] for line in train_set])
train_seq_pad = pad_sequences(train_seq, maxlen=seq_max_len, padding='post', truncating='post', value=0 )
train_model_input = {"user_id": train_uid, "item_id": train_iid, "hist_item_id": train_seq_pad, "hist_len": train_hist_len}
for key in {"gender", "age", "city"}:
train_model_input[key] = user_profile.loc[train_model_input['user_id']][key].values
return train_model_input, train_label
- 代码解释:
- **gen_data_set() **主要作用是接收数据集(data)和一个负采样(negsample)参数,返回一个训练集列表(trainset)和一个测试集列表(testset)。具体流程是先通过timetamp列对数据进行排序,根据item_id进行去重;然后根据user_id分组形成正负样本(正样本为购买过的,负样本为没有购买过的),对于negsample大于0,我们就要进行负采样,也就是随机选择一些没有购买过的商品为负样本,然后将它们保存到训练集中;最后,将正负样本数据以及其他信息(如历史交互序列、用户 ID 和历史交互序列的长度)保存到训练集列表和测试集列表中。
- gen_model_input() 主要作用就是接收一个训练集列表、用户画像信息和序列最大长度参数,返回训练模型的输入和标签。首先将训练集列表拆分成 5 个列表(train_uid train_seq train_iid train_label train_hist_len);然后使用pad_sequences() 函数对历史交互序列进行填充处理,将其变成长度相同的序列。最后,将用户画像信息(gender age city)加入到训练模型的关键字中,返回训练模型的输入和标签。
- pad_sequences():pad_sequences()这个函数是来自于TensorFlow中数据预处理的一种方法,主要就是数据预填充。在TensorFlow2.8版本之前可以通过
from tensorflow.python.keras.preprocessing.sequence import pad_sequences调用,后期版本则是在keras.utils里,这里建议使用低版本tesorflow2,具体版本信息请参考链接。
模型训练预测部分
- 进入模型训练阶段,我们需要先了解一下,代码里我们所使用的一些包和函数介绍
- sklearn.preprocessing.LabelEncoder:对数据进行特征编码
- deepctr.feature_column.SparseFeat, VarLenSparseFeat:用户构建用户和物品特征输入。
- deepmatch:用于构建和训练推荐模型
- faiss:高效向量相似性搜索库
- models.recall.preprocess.gen_data_set, gen_model_input:数据预处理部分(自建)
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from models.recall.preprocess import gen_data_set, gen_model_input
from deepctr.feature_column import SparseFeat, VarLenSparseFeat
from tensorflow.python.keras import backend as K
from tensorflow.python.keras.models import Model
import tensorflow as tf
from deepmatch.models import *
from deepmatch.utils import recall_N
from deepmatch.utils import sampledsoftmaxloss
import numpy as np
from tqdm import tqdm
import faiss
class YouTubeModel(object):
def __init__(self, embedding_dim=32):
self.SEQ_LEN = 50
self.embedding_dim = embedding_dim
self.user_feature_columns = None
self.item_feature_columns = None
def training_set_construct(self):
# 数据加载
data = pd.read_csv('../../data/read_history.csv')
# 负采样个数
negsample = 0
# 特征编码
features = ["user_id", "item_id", "gender", "age", "city"]
features_max_idx={}
for feature in features:
lbe = LabelEncoder()
data[feature] = lbe.fit_transform(data[feature]) + 1
features_max_idx[feature] = data[feature].max() + 1
# 抽取用户、物品特征(并去重)
user_info = data[["user_id", "gender", "age", "city"]].drop_duplicates('user_id')
item_info = data[["item_id"]].drop_duplicates('item_id')
# 构建输入数据
train_set, test_set = gen_data_set(data, negsample)
# 转化模型输入
train_model_input, train_label = gen_model_input(train_set, user_info, self.SEQ_LEN)
test_model_input, test_label = gen_model_input(test_set, user_info, self.SEQ_LEN)
# 用户端特征输入
self.user_feature_columns = [SparseFeat('user_id', features_max_idx['user_id'], 16),
SparseFeat('gender', features_max_idx['gender'], 16),
SparseFeat('age', features_max_idx['age'], 16),
SparseFeat('city', features_max_idx['city'], 16),
VarLenSparseFeat(SparseFeat('hist_item_id', features_max_idx['item_id'],
self.embedding_dim, embedding_name='item_id'),
self.SEQ_LEN, 'mean', 'hist_len')
]
# 物品端特征输入
self.item_feature_columns = [SparseFeat('item_id', features_max_idx['item_id'], self.embedding_dim)]
return train_model_input, train_label, test_model_input, test_label, train_set, test_set, user_info, item_info
def training_model(self, train_model_input, train_label):
K.set_learning_phase(True)
if tf.__version__ >= '2.0.0':
tf.compat.v1.disable_eager_execution()
# 定义模型
model = YoutubeDNN(self.user_feature_columns, self.item_feature_columns, num_sampled=100,
user_dnn_hidden_units=(128, 64, self.embedding_dim))
# 使用adam优化,损失函数使用softmax+cross_entropy
model.compile(optimizer="adam", loss=sampledsoftmaxloss)
# 训练并保存训练过程中的数据
model.fit(train_model_input, train_label, batch_size=512, epochs=20, verbose=1, validation_split=0.0,)
return model
# 提取用户和物品的embedding layer
def extract_embedding_layer(self, model, test_model_input, item_info):
all_item_model_input = {"item_id": item_info['item_id'].values, }
# 获取用户、item的embedding_layer
user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
user_embs = user_embedding_model.predict(test_model_input, batch_size=2 ** 12)
item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
print(user_embs.shape)
print(item_embs.shape)
return user_embs, item_embs
# 计算召回率和命中率
def eval(self, user_embs, item_embs, test_model_input, item_info, test_set):
test_true_label = {line[0]: line[2] for line in test_set}
index = faiss.IndexFlatIP(self.embedding_dim)
index.add(item_embs)
D, I = index.search(np.ascontiguousarray(user_embs), 50)
s = []
hit = 0
# 统计预测结果
for i, uid in tqdm(enumerate(test_model_input['user_id'])):
try:
pred = [item_info['item_id'].value[x] for x in I[i]]
recall_score = recall_N(test_true_label[uid], pred, N=50)
s.append(recall_score)
if test_true_label[uid] in pred:
hit += 1
except:
print(i)
# 计算召回率和命中率
recall = np.mean(s)
hit_rate = hit / len(test_model_input['user_id'])
return recall, hit_rate
def scheduler(self):
# 构建训练集、测试集
train_model_input, train_label, test_model_input, test_label, \
train_set, test_set, user_info, item_info = self.training_set_construct()
self.training_model(train_model_input, train_label)
# 获取用户、item的layer
user_embs, item_embs = self.extract_embedding_layer(model, test_model_input, item_info)
# 评估模型
recall, hit_rate = self.eval(user_embs, item_embs, test_model_input, item_info, test_set)
print(recall, hit_rate)
if __name__ == '__main__':
model = YouTubeModel()
model.scheduler()
- 代码解释:
- training_set_construct:加载数据集,特征编码,数据集预处理,使用deepctr库中的SparseFeat(离散), VarLenSparseFeat(变长)实现用户物品的特征输入。
- training_model:YoutubeDNN构建训练模型,compile编译训练模型,fit模型训练。
- extract_embedding_layer:提取用户和物品的Embedding Layer。
- eval:评估模型计算召回率和命中率,使用faiss中的faiss.IndexFlatIP(余弦距离搜索并非余弦相似度),统计预测结果,计算召回率为recall_score的平均值;命中率则是集中次数hit与test_model_input的总数。
- scheduler:串联整个召回代码的函数,负责调用。
总结与问答
- 代码中提到的离散特征和变长特征该如何选择?
- 答:首先我们要理解一下什么事离散特征,什么是变长特征?
- 离散特征:是指具有有限取值或离散类别的特征,例如性别、国家、城市等(用户画像信息)。对于离散特征,可以使用embedding来将其映射到低维连续向量空间中。这使得模型能够学习离散特征之间的相关性和交互关系。通常情况下,离散特征需要经过编码(例如one-hot multi-hot)并与其他特征一起输入到模型中。
- 变长特征:是指具有可变长度的特征,例如用户的历史行为序列或商品的标签列表。对于变长特征,可以使用循环神经网络(RNN)或Transformer等模型来建模。这些模型可以处理可变长度的序列,并捕捉序列中的时序关系和上下文信息。
- 所以对于多特征输入,通常需要混合使用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)