台大李宏毅自注意力机制和Transformer详解(续)!
1)Transformer是变形金刚的意思,与BERT有很强的关联。2)Transformer是一个sequence-to-sequence(seq2seq)的模型,输出长度由模型自己决定3)encoder部分主要是self-attention,另外采用了残差网络构架和layer normalization4)decoder由AT和NAT两种方式。需要定义BEGIN和END特殊符号。AT的方式一开
台大李宏毅自注意力机制和Transformer详解(续)!
0 前言
上一篇只是总结了self-attention,接下来接着总结Transformer。视频链接如下:
【李宏毅机器学习2021】自注意力机制 (Transformer) (上)_哔哩哔哩_bilibili
还是先写总结。
1 总结
1)Transformer是变形金刚的意思,与BERT有很强的关联。
2)Transformer是一个sequence-to-sequence(seq2seq)的模型,输出长度由模型自己决定
3)encoder部分主要是self-attention,另外采用了残差网络构架和layer normalization
4)decoder由AT和NAT两种方式。需要定义BEGIN和END特殊符号。AT的方式一开始是输入BEGIN符号,最后预测产生了END符号结束。
5)encoder与decoder采用cross attention进行信息交流。decoder产生q,encoder产生k,v。所以q,k,v由一个模块产生,叫做self-attention,由不同的模块产生,叫做cross attention。
2 正文开始
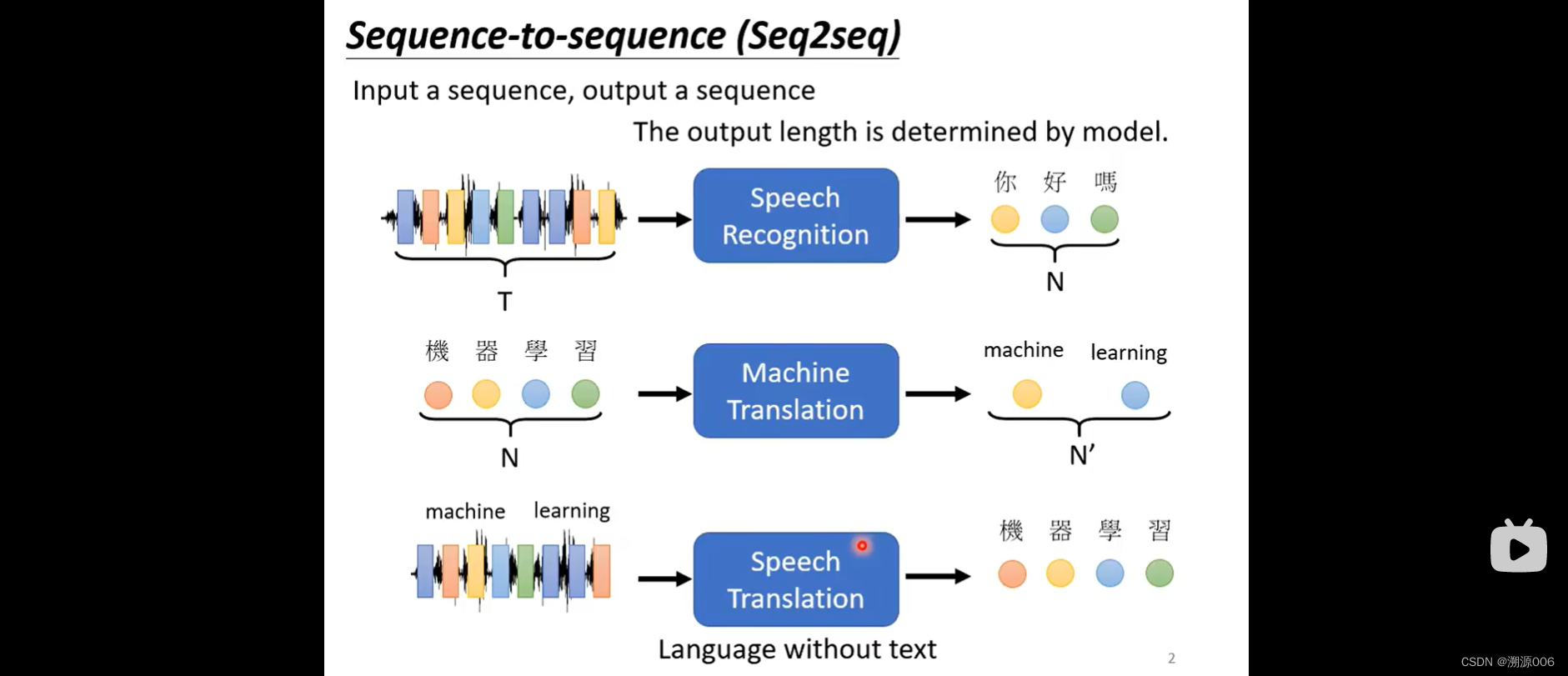
Transformer是一个sequence-to-sequence(seq2seq)的模型,输出长度不定,由模型自己来决定。seq2seq是一个非常powerful的模型。很多应用可以用seq2seq来解决。如语音识别、机器翻译以及语音翻译等,还有一些其他的场景如下:
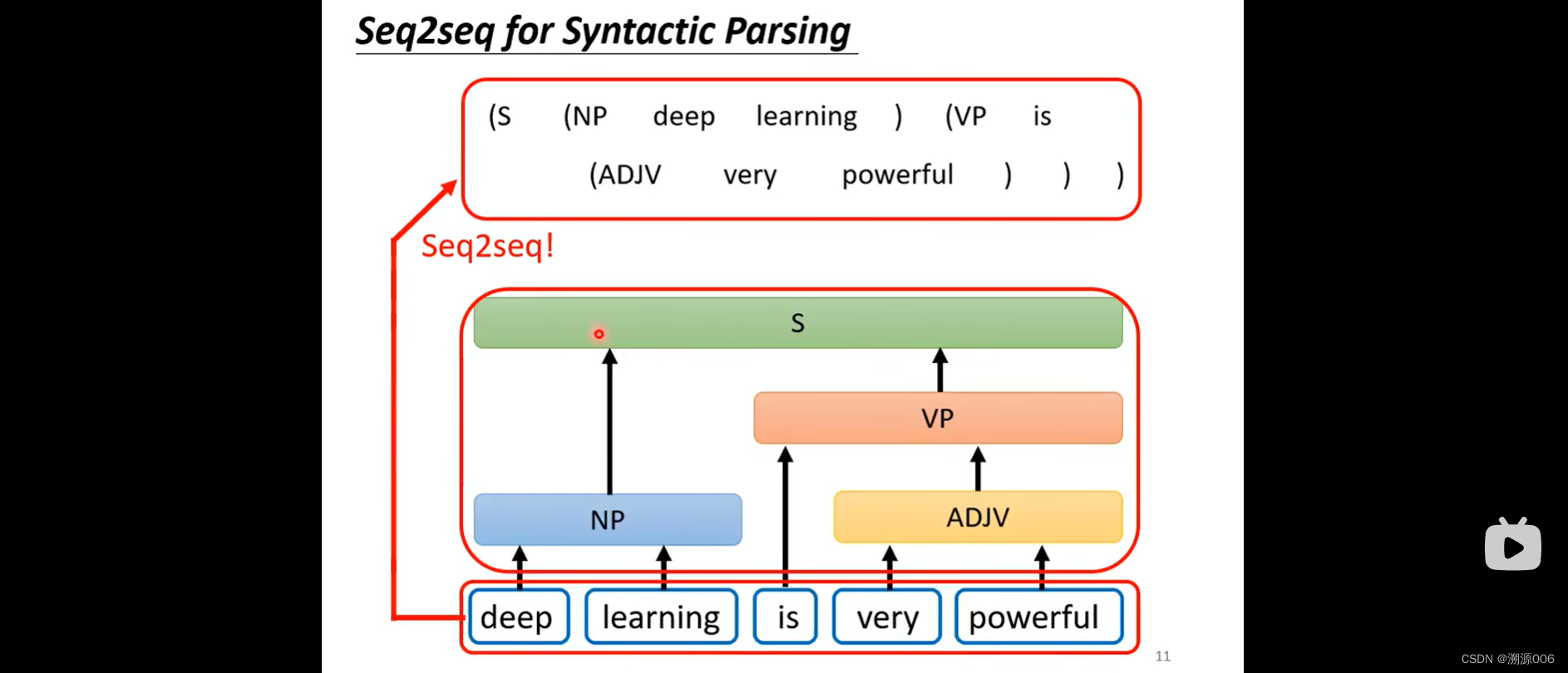
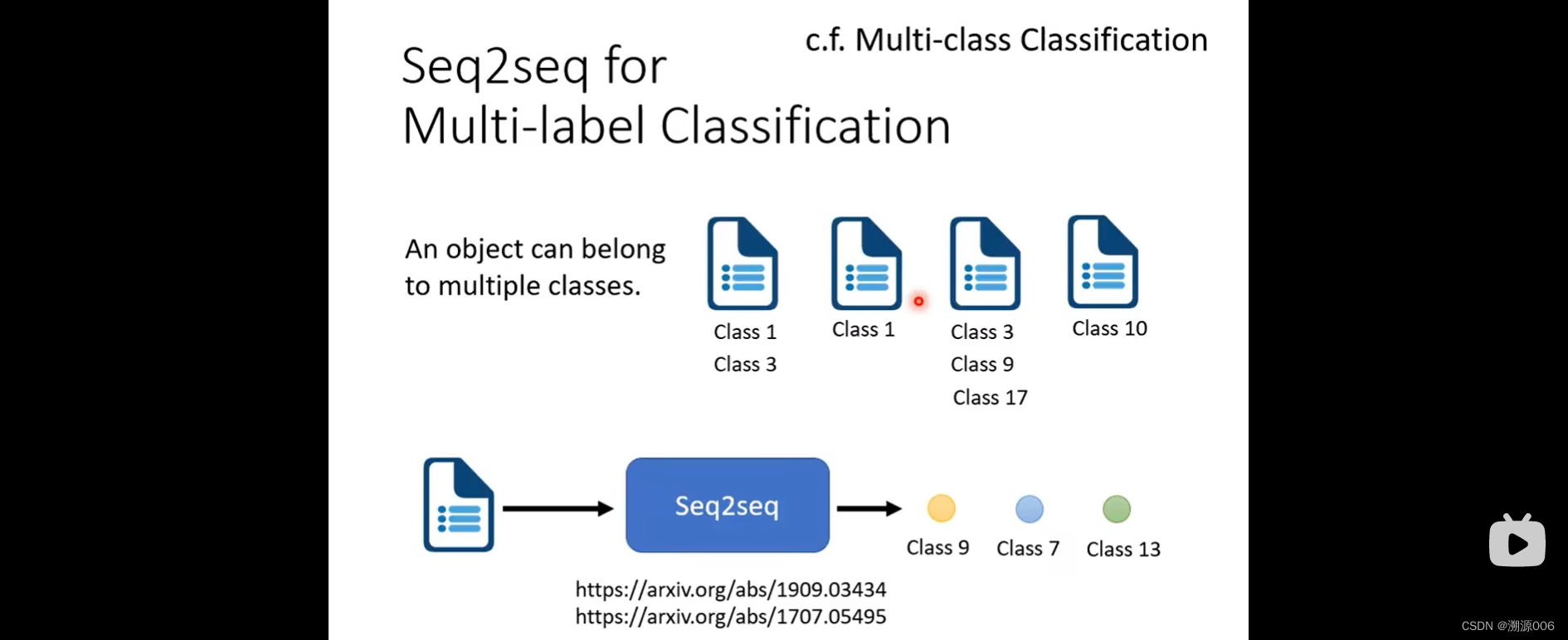
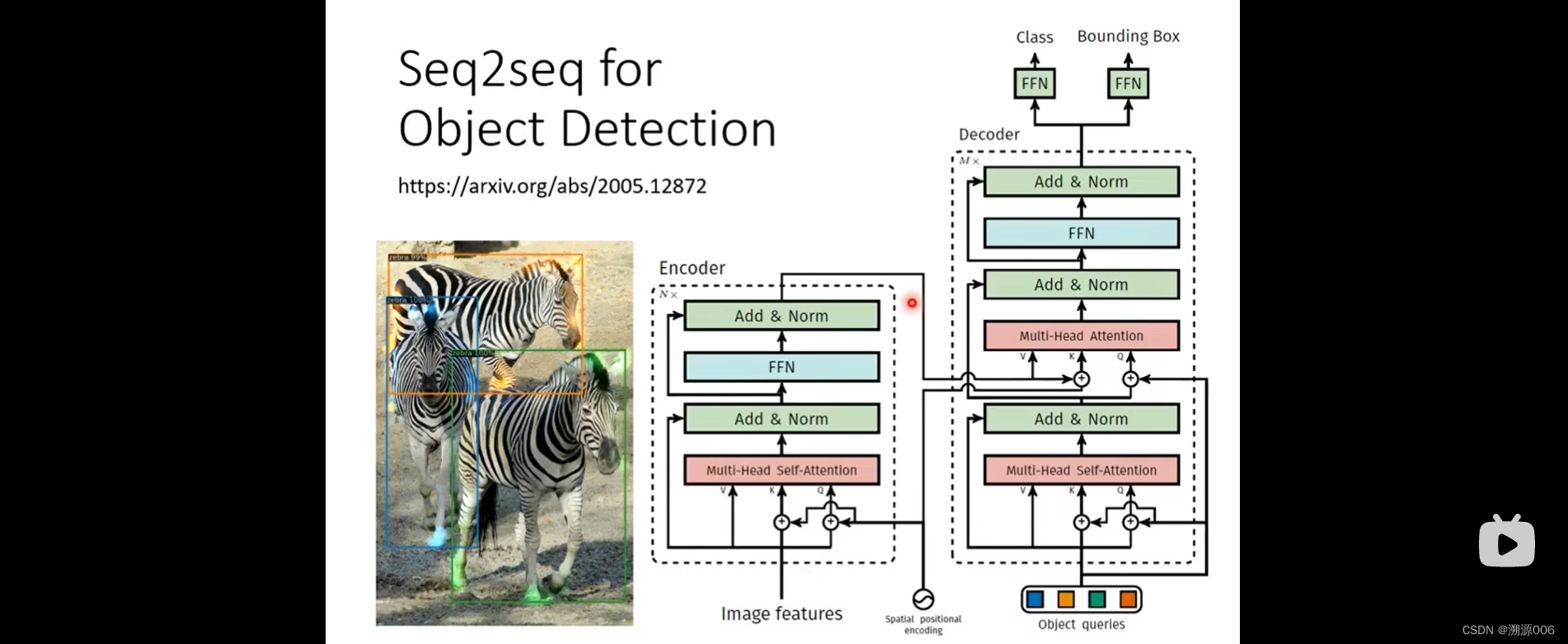
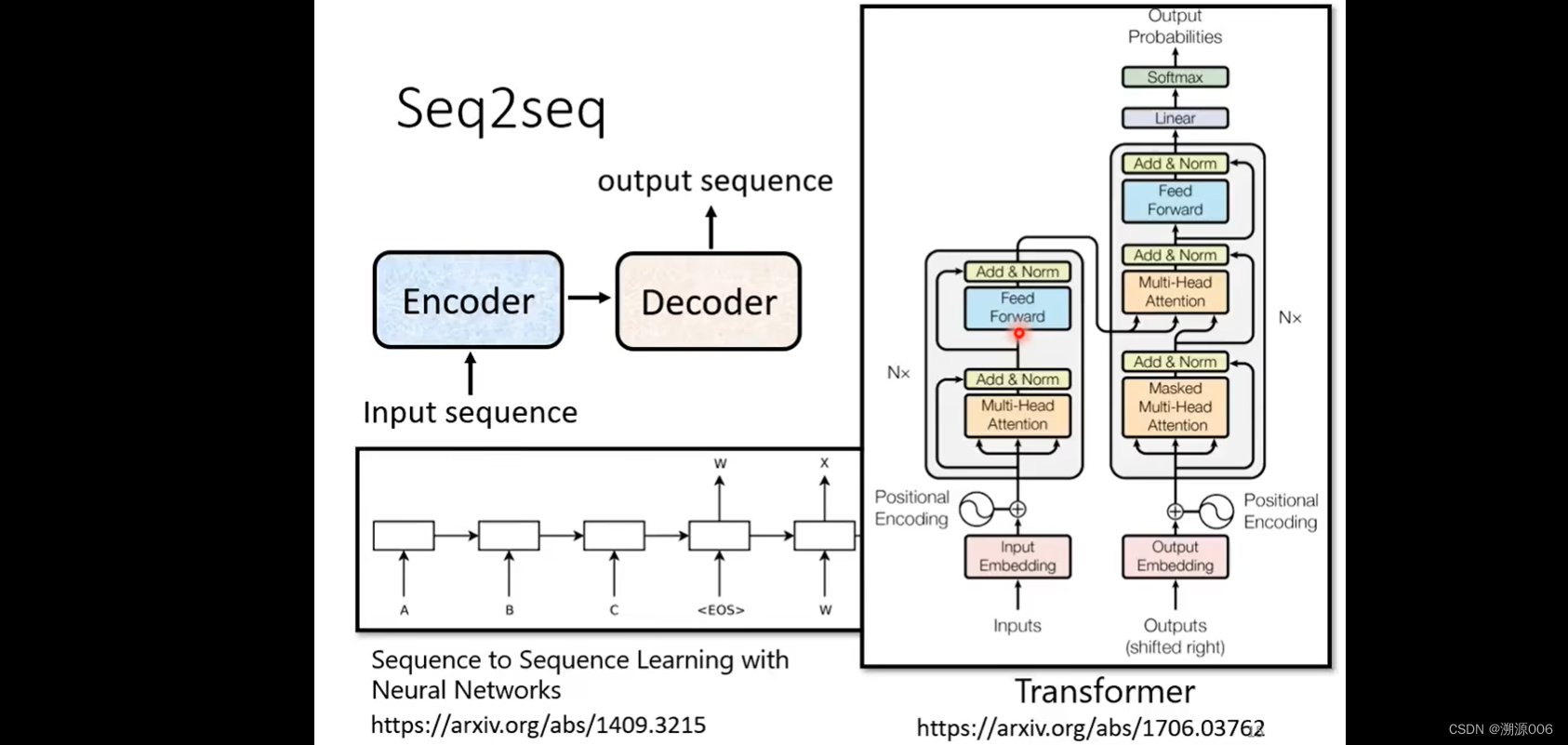
seq2seq模型有encoder和decoder组成。早在14年9月就有人研究了seq2seq模型,现在用的最多的就是transformer。也是有encoder部分和decoder部分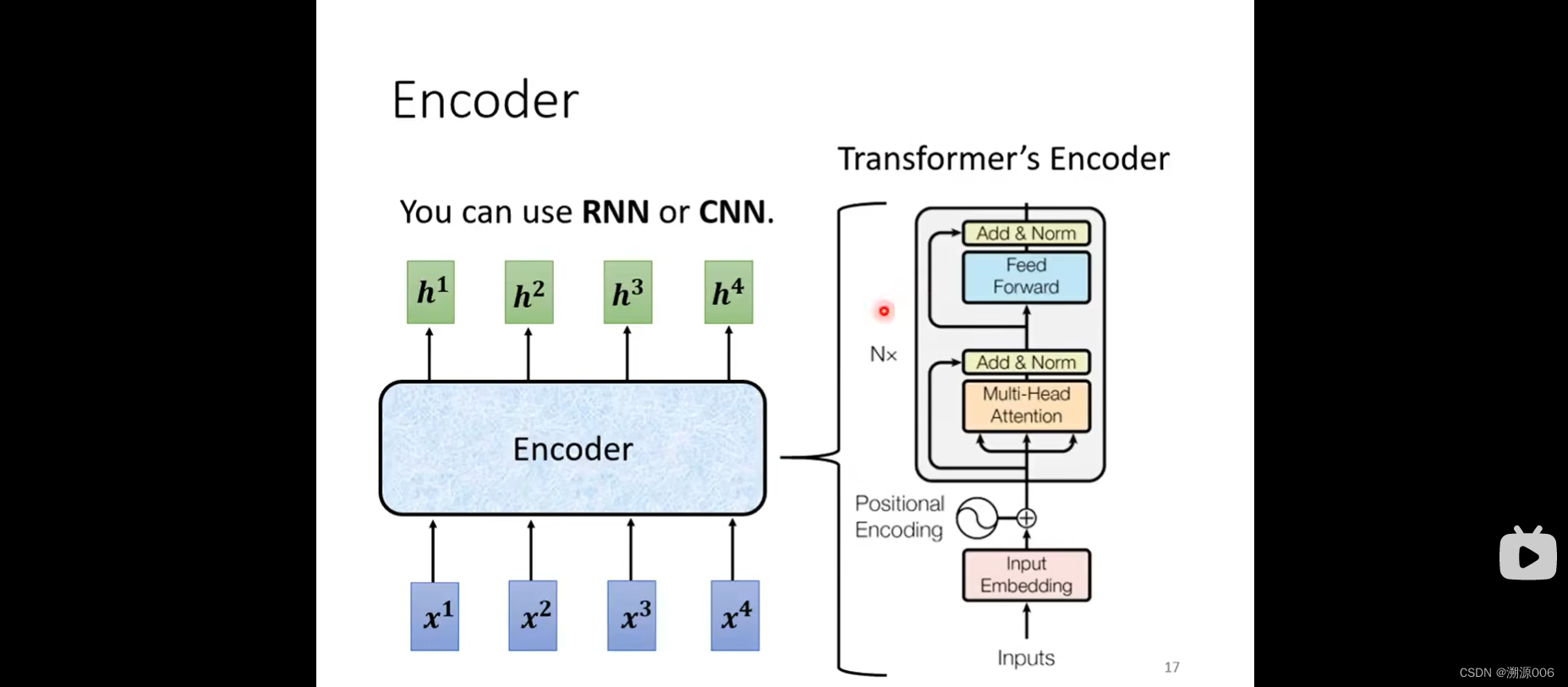
开始介绍Encoder部分。Encoder输入是一个序列(一排向量),输出也是一个序列(一排向量)。这个事情可以用很多种方式来实现,比如self-attention、RNN、CNN都可以做到这个事情。Transformer的encoder部分用的是self-attention。上面的图有点抽象,用下面的图来详细解释encoder架构: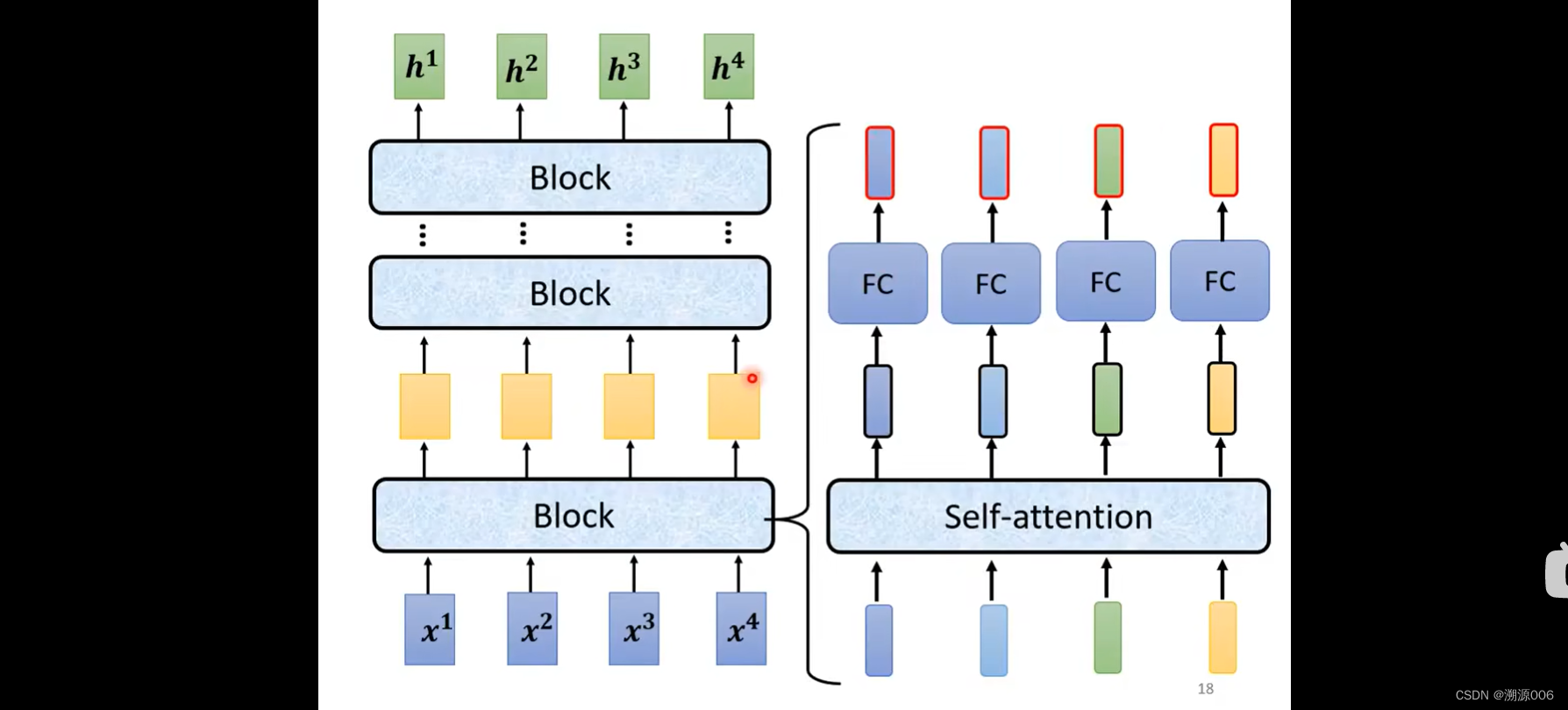
一个Encoder由很多个Block堆叠而成。之所以叫block是因为每个block由很多层组成,比如self-attention+FC。Tranformer里面做的事情要更加复杂: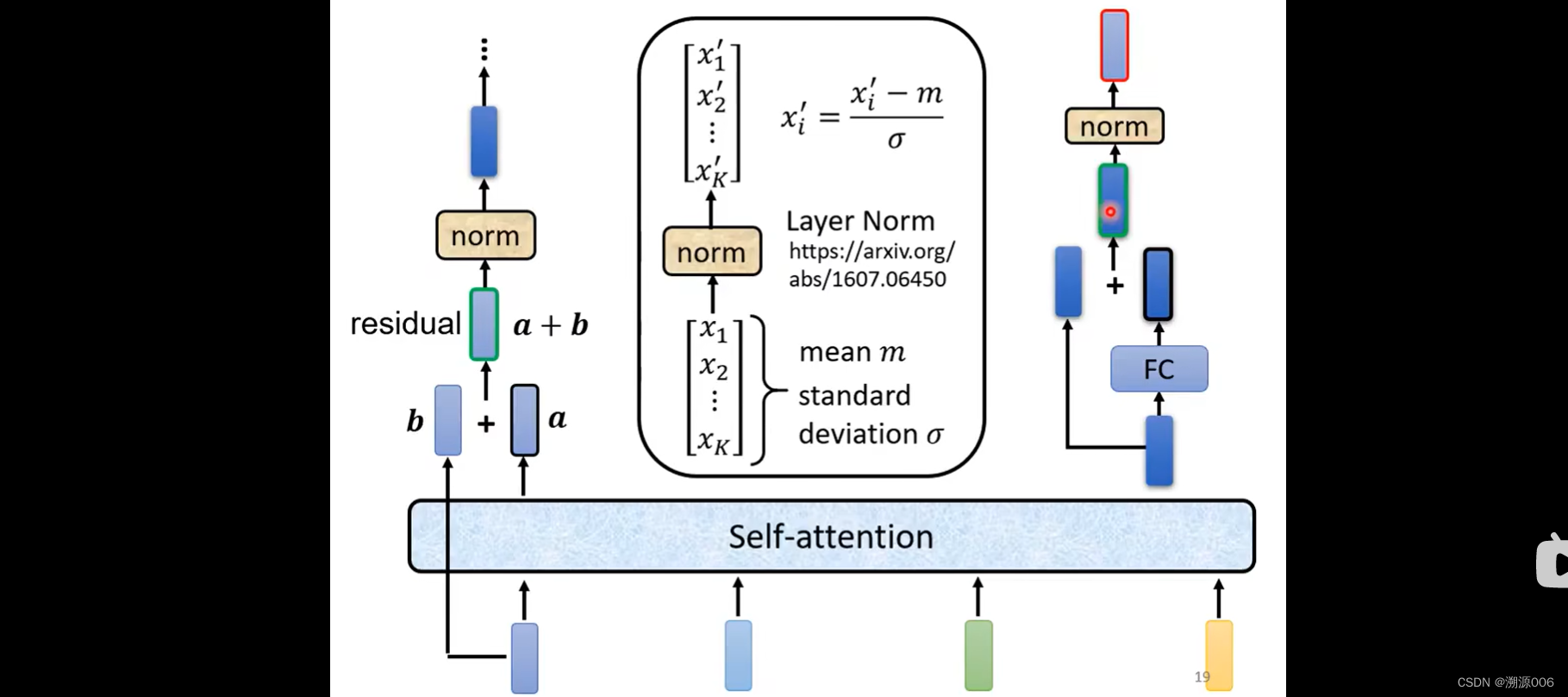
1)self-attention输入一排向量就输出一排向量,每个输出向量都考虑了所有的输入向量。在transformer里不止输出这个向量,还要加上自己对应的输入向量,得到新的输出(这种架构就是残差网络的思路)。
2)然后对输出做Layer Normalization。Layer Normalization比Batch Normalization跟简单一点。Layer Normalization的做法:输入一个向量,输出一个向量。不需要batch。计算输入向量的均值m和标准差 σ \sigma σ(这一点与Batch Normalization,Batch Normalization是很多个样本,同一个维度计算mean和标准差 σ \sigma σ),然后输出向量就是输入向量减去均值除以标准差(ppt有错误,应该是 x i ′ = x i − m σ x'_i=\frac{x_i-m}{\sigma} xi′=σxi−m)。
3)LN层的输出才是FC层的输入,FC层也有残差网络的架构,该层输出后再接一个LN层,此时的输出才是transformer block的一个输出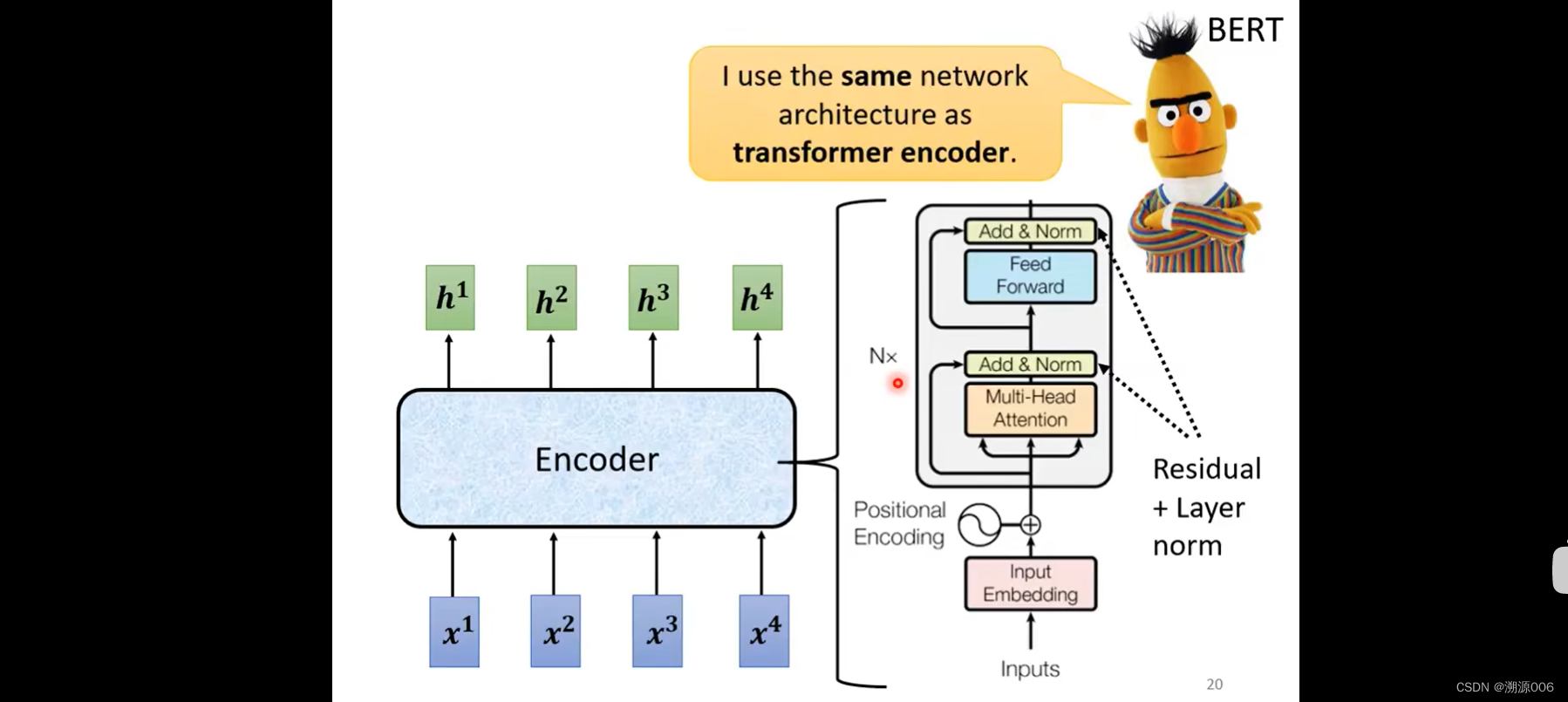
上一张ppt讲的是对这张图的详细解析。输入之前做positional Encoding加上位置的信息。attention做的是multi-head attention。Add & Norm就是残差+Layer norm,然后是FC,然后是残差+Layer norm。Nx是重复N次的意思。BERT就是transformer的encoder。
以上就是transformer论文里最原始的encoder,也会有对此的改进,不一一细说。
¥¥¥¥¥¥¥¥¥¥¥¥以上是encoder,下面是decoder部分¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥
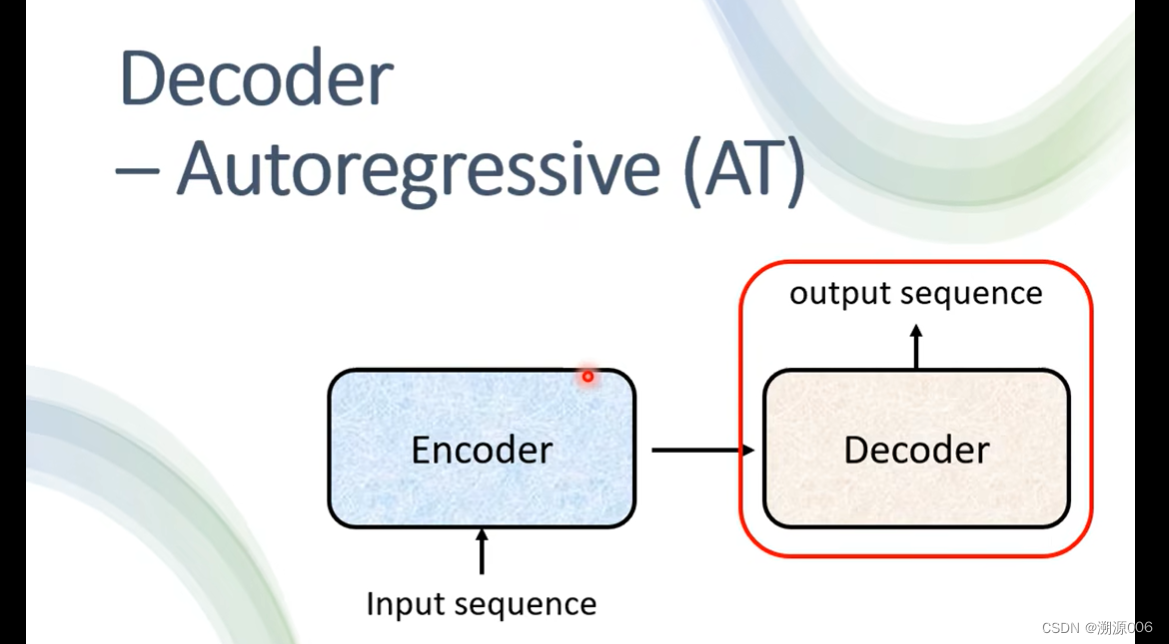
有两种decoder,主要讲比较常见的autoregressive。
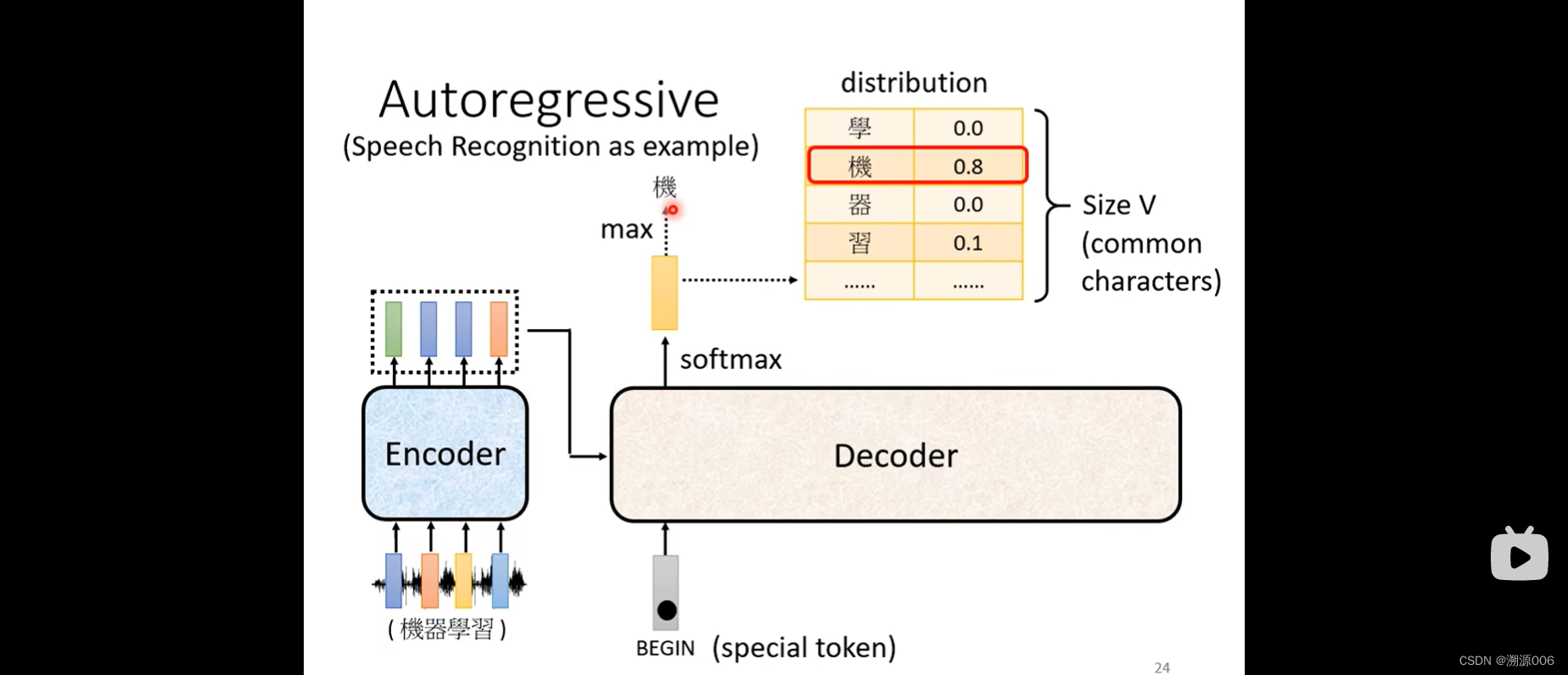
以语音识别为例,输入一段语音(一排向量)。encoder输出一排向量。decoder先把encoder的输出先读进去(怎么读进去后面讲)。
Decoder怎么产生一段文字呢?首先要给它一个符号,这个符号代表开始(这里用BEGIN)来表示(可以用one-hot的方式编码)。然后decoder会吐出一个向量,这个向量的长度和vocabulary的size是一样的。然后做一个softmax(softmax把所有输出整合到0-1之间,加起来和是1,相当于一个概率分布)。这样向量的每个维度对应一个选这个维度对应的字的概率,概率最高的说明此时应该输出这个字。比如这里“机”的概率最高,就把“机”作为decoder的第一个输出。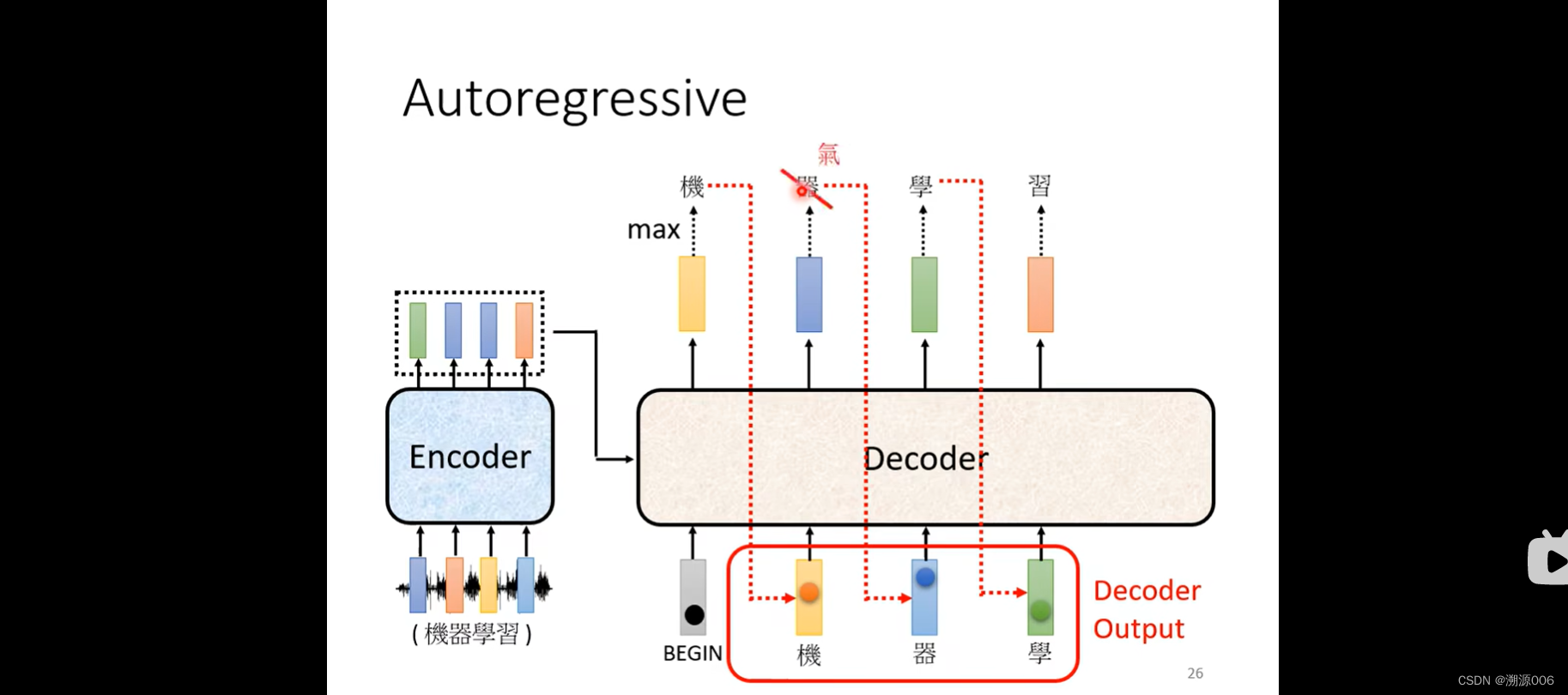
然后将“机”的onehot向量作为decoder的输入,decoder产生输出向量,代表“器”,然后把“器”的onehot向量作为decoder输入,一次类推。有可能会初夏error 传播的问题,先不管这个问题。
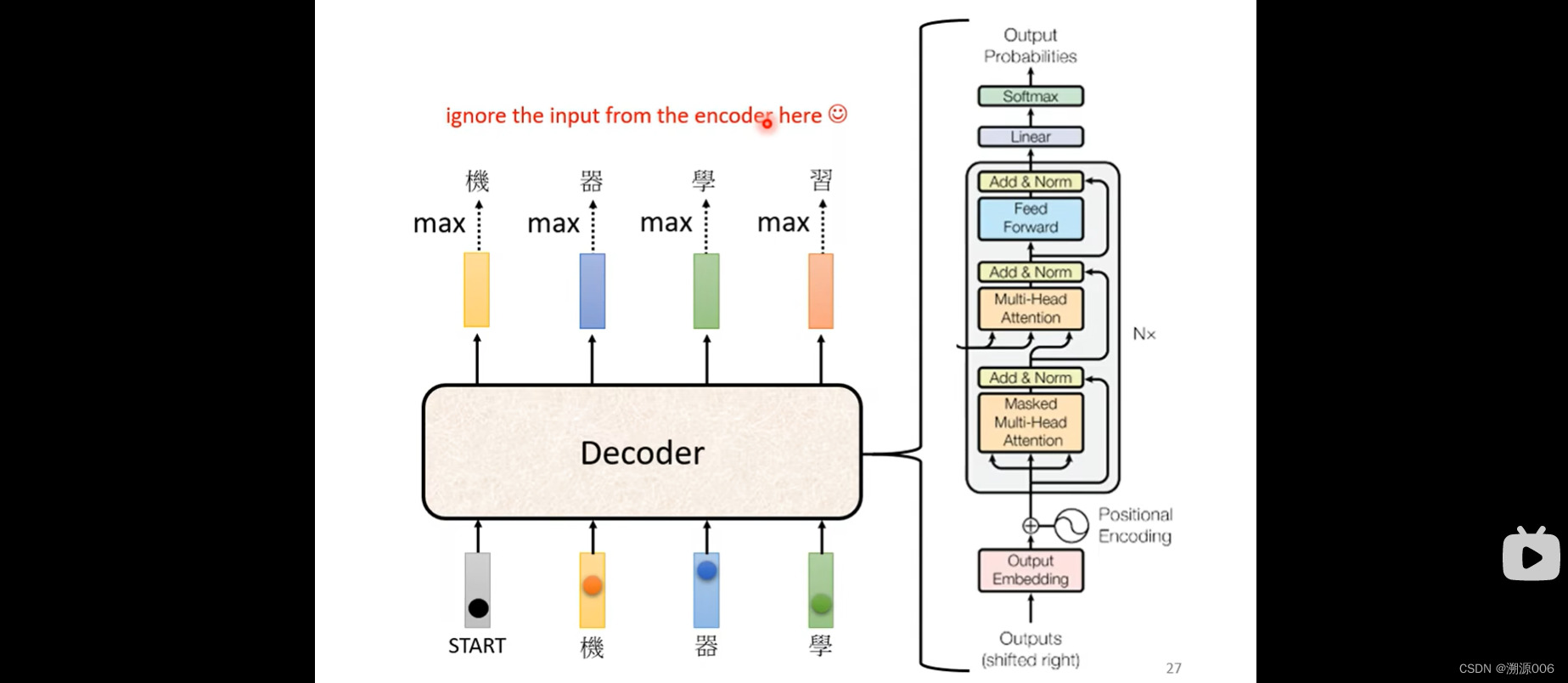
transformer里的decoder部分如上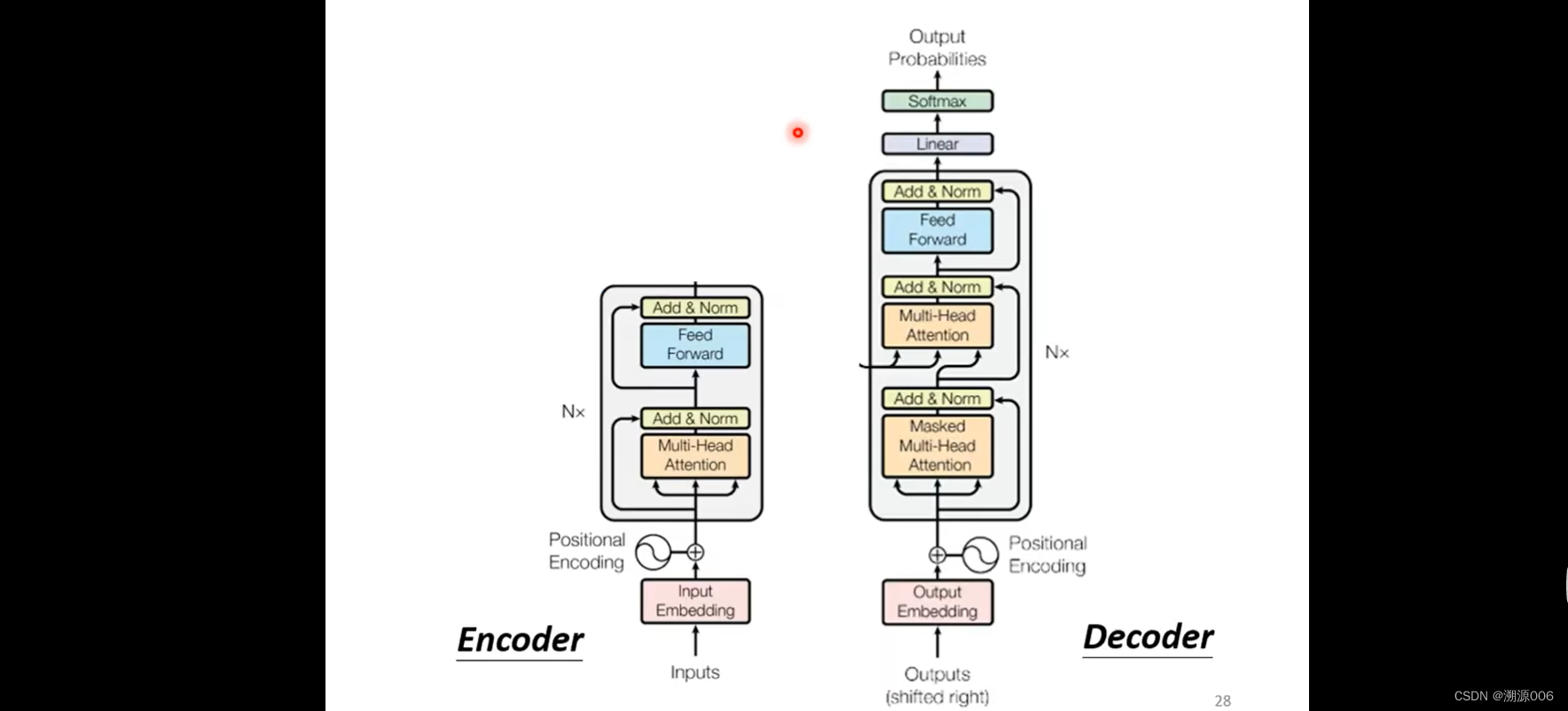
看一下transformer的encoder和decoder部分。把decoder的中间部分盖起来,encoder和decoder几乎没有差别。有一个区别是第一个层加了masked。
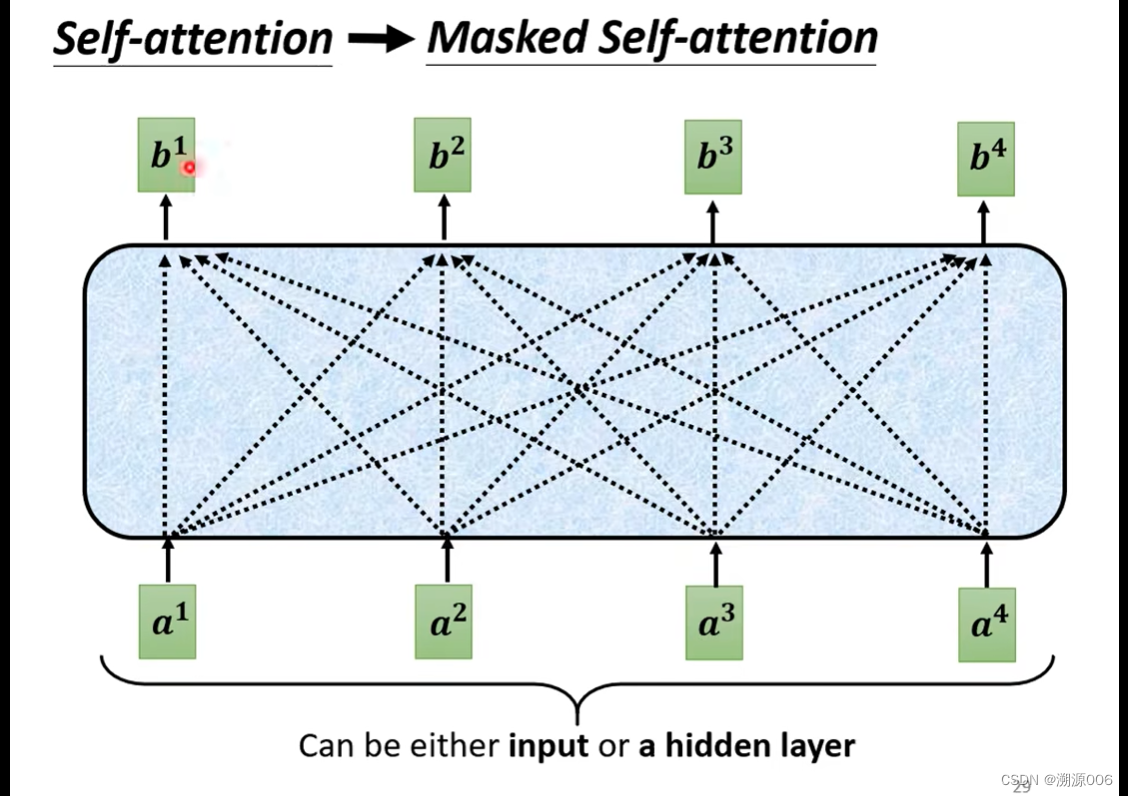

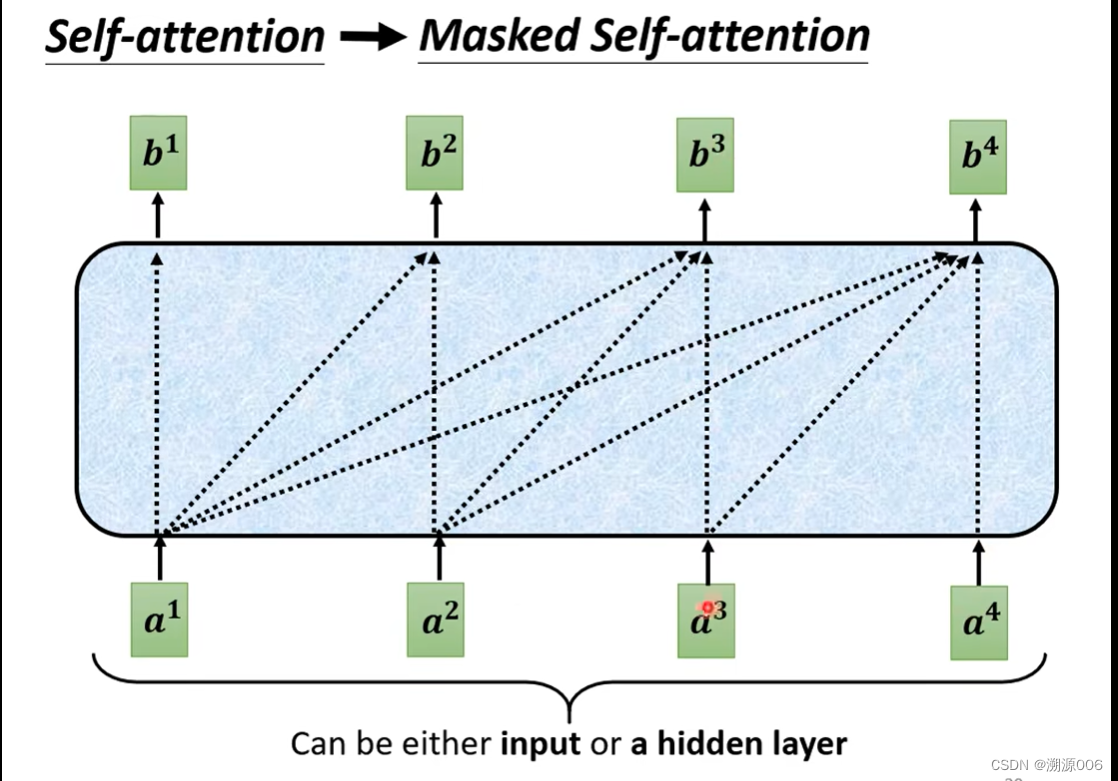
从self-attention到masked self-attention的变化是,self-attention产生每个 b i b^i bi 都需要考虑所有的 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4。而masked self-attention产生 b 1 b^1 b1只需要考虑 a 1 a^1 a1,产生 b 2 b^2 b2只需要考虑 1 , a 2 ^1,a^2 1,a2,产生 b 3 b^3 b3只需要考虑 a 1 , a 2 , a 3 a^1,a^2,a^3 a1,a2,a3. 细节来讲就是如下所示(以产生 b 2 b^2 b2为例)
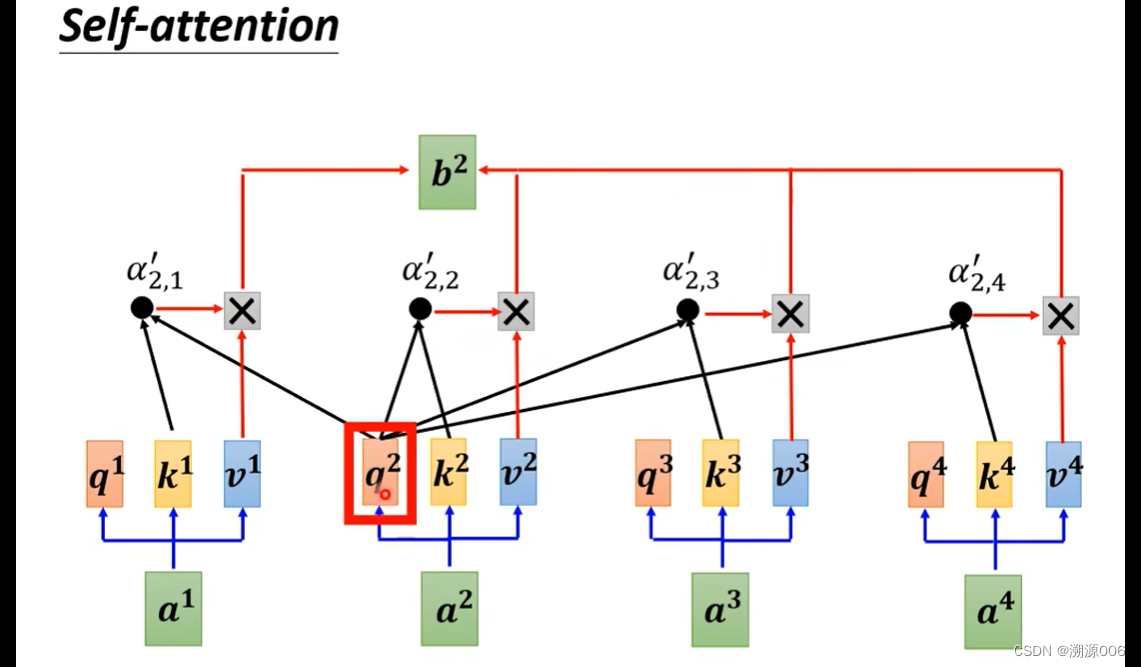
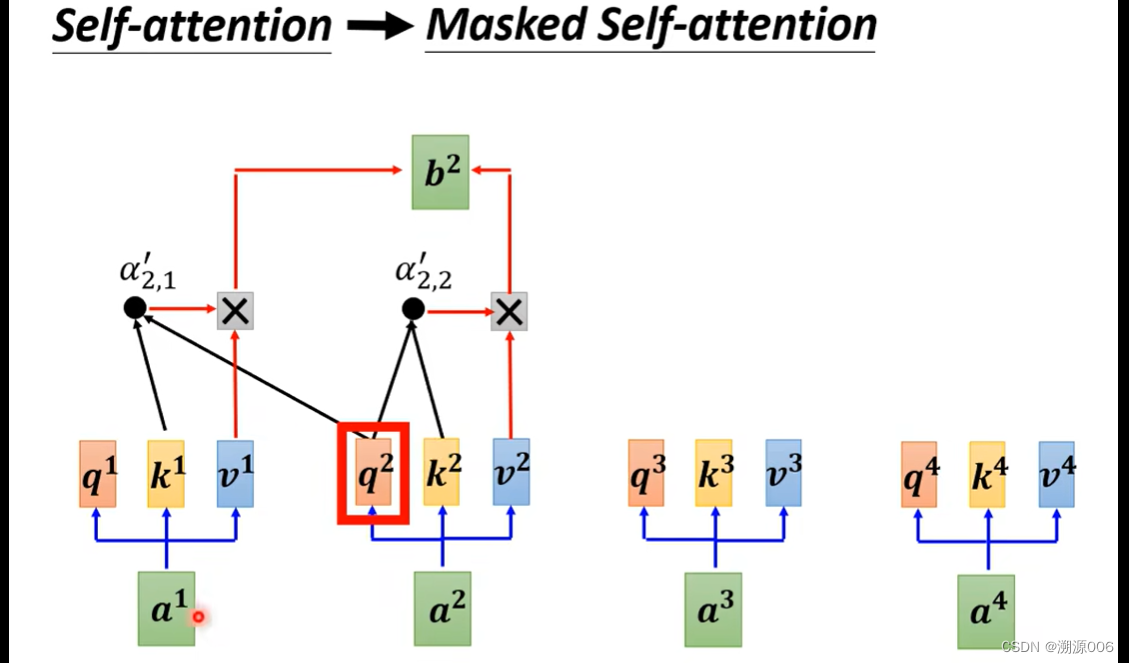
为什么要用masked self-attention,这个其实是很自然的。encoder是把所有的 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4一块输入,而decoder是一个一个输入。产生 b 2 b^2 b2的时候还没有输入 a 3 , a 4 a^3,a^4 a3,a4,自然也就不会考虑 a 3 , a 4 a^3,a^4 a3,a4的信息。
还有一个关键的问题,decoder必须自己考虑输出的序列的长度。
定义一个特殊的符号END来表示结束就好了。
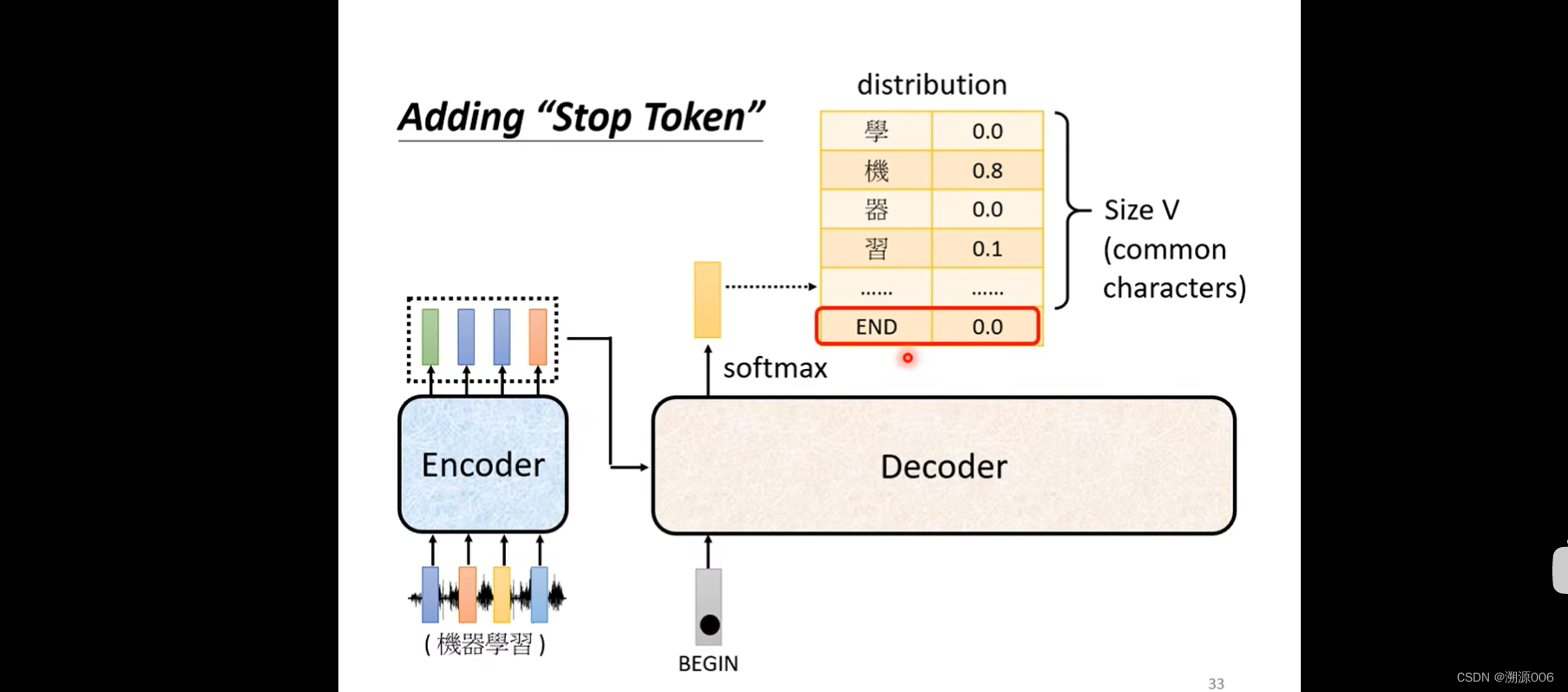
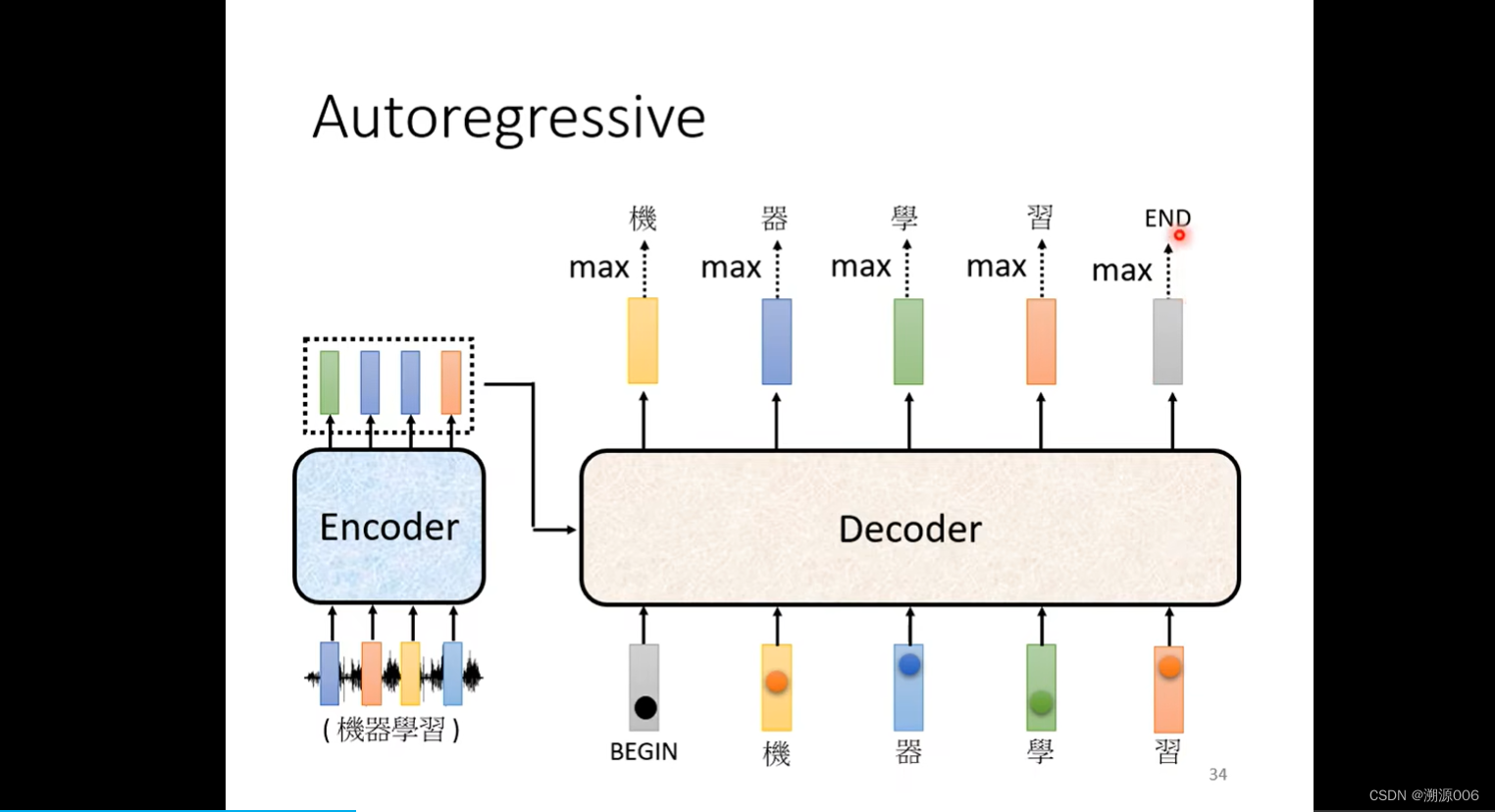
然后把“习”的onehot向量输入decoder得到“END”的向量,就认为序列结束了。
以上就是autoregressive(AT)的方式。下面简单介绍Non-autoregressive(NAT)的方式。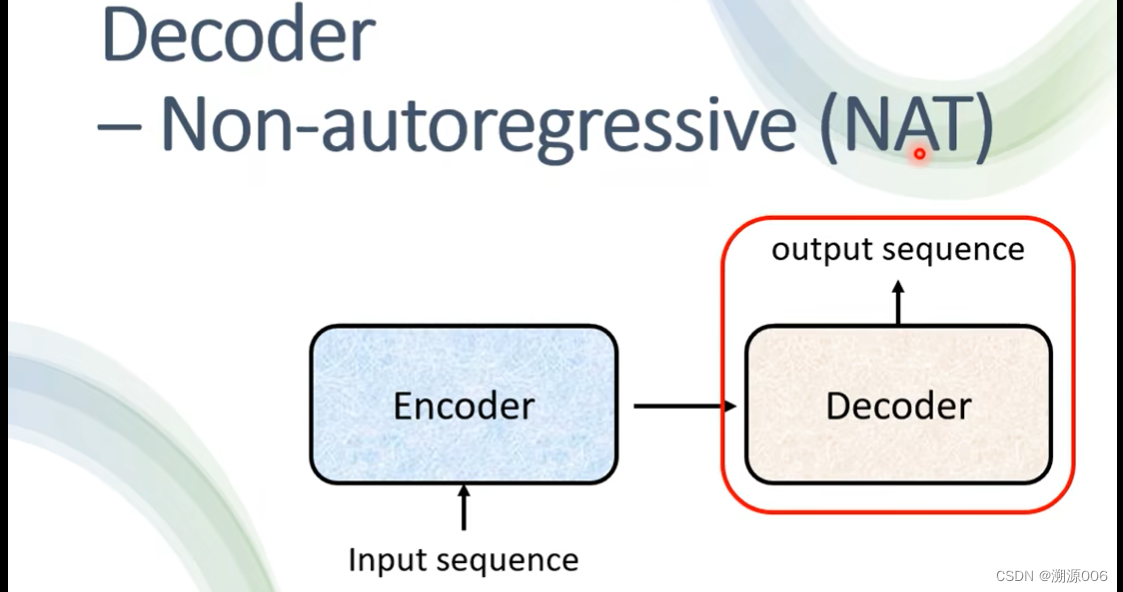
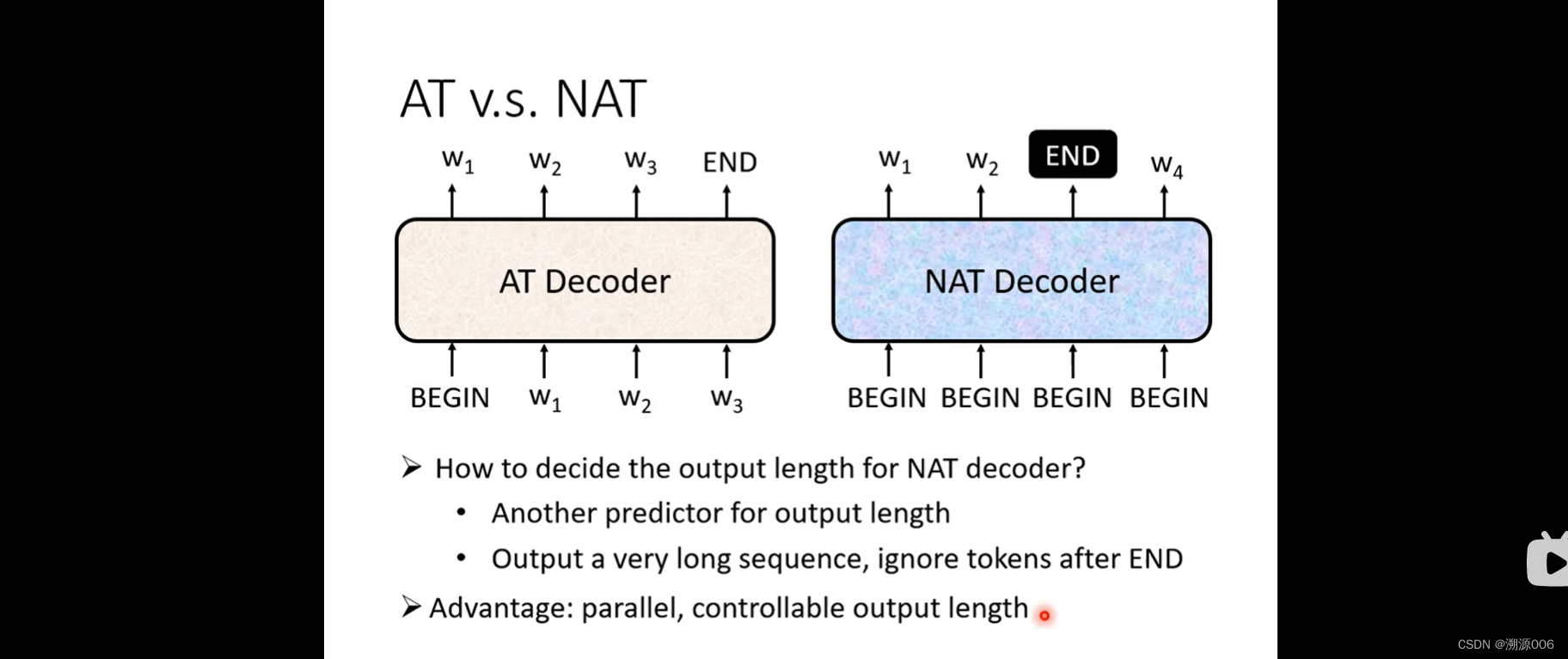
NAT是一次把整个句子产生出来。输入是N个 BEGIN 符号,直接预测整个句子。但是这里有个问题是如何知道输出的长度。一个方法就用另外一个encoder预测句子的长度。或者输出一个很长度的序列,忽略掉END后面的东西。好处是并行。但是往往性能不如AT。
¥¥¥¥¥¥¥¥¥¥¥下面将encoder和decoder之间怎么传递信息¥¥¥¥¥¥¥¥¥
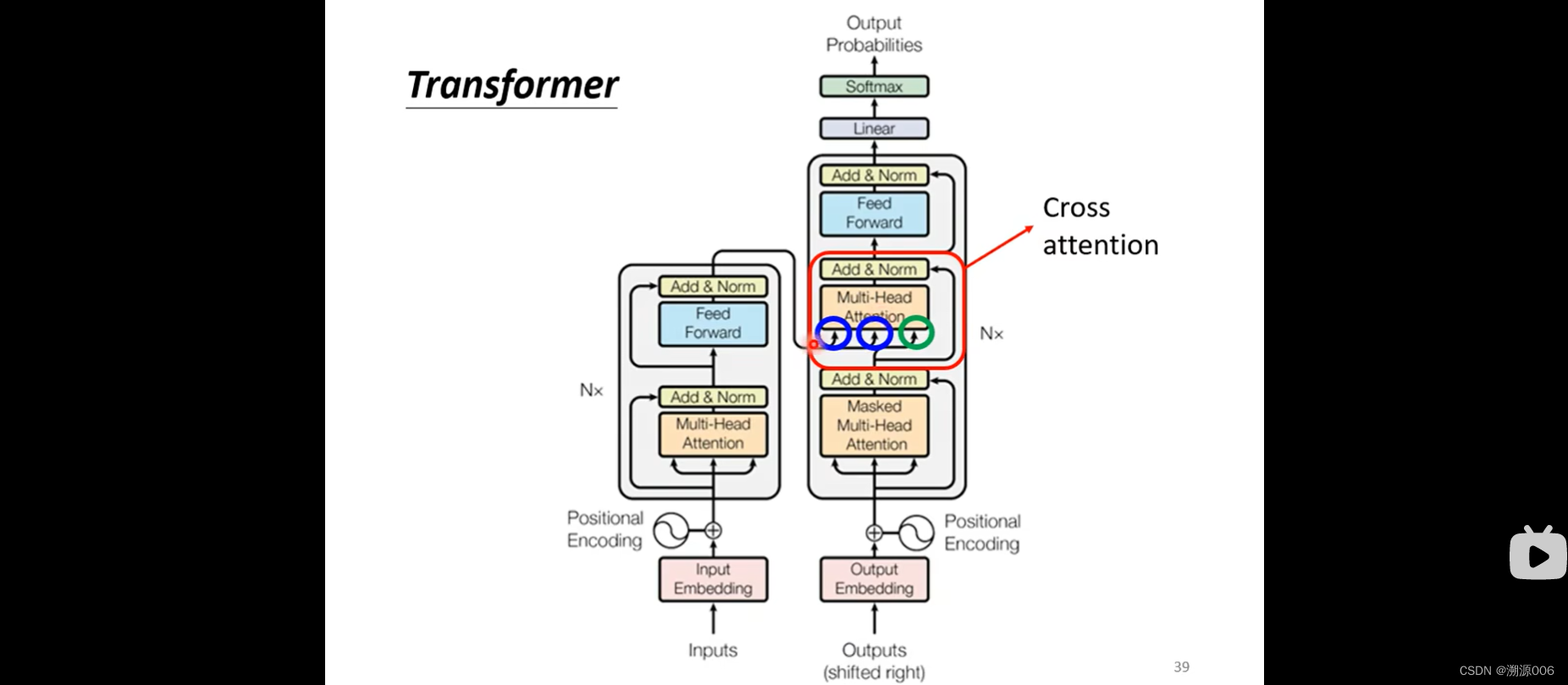
也就是刚才遮起来的那一部分。这一部分叫cross attention,是连接encoder和decoder之间的桥梁。encoder提供了两个箭头,decoder提供了一个箭头。细节如下: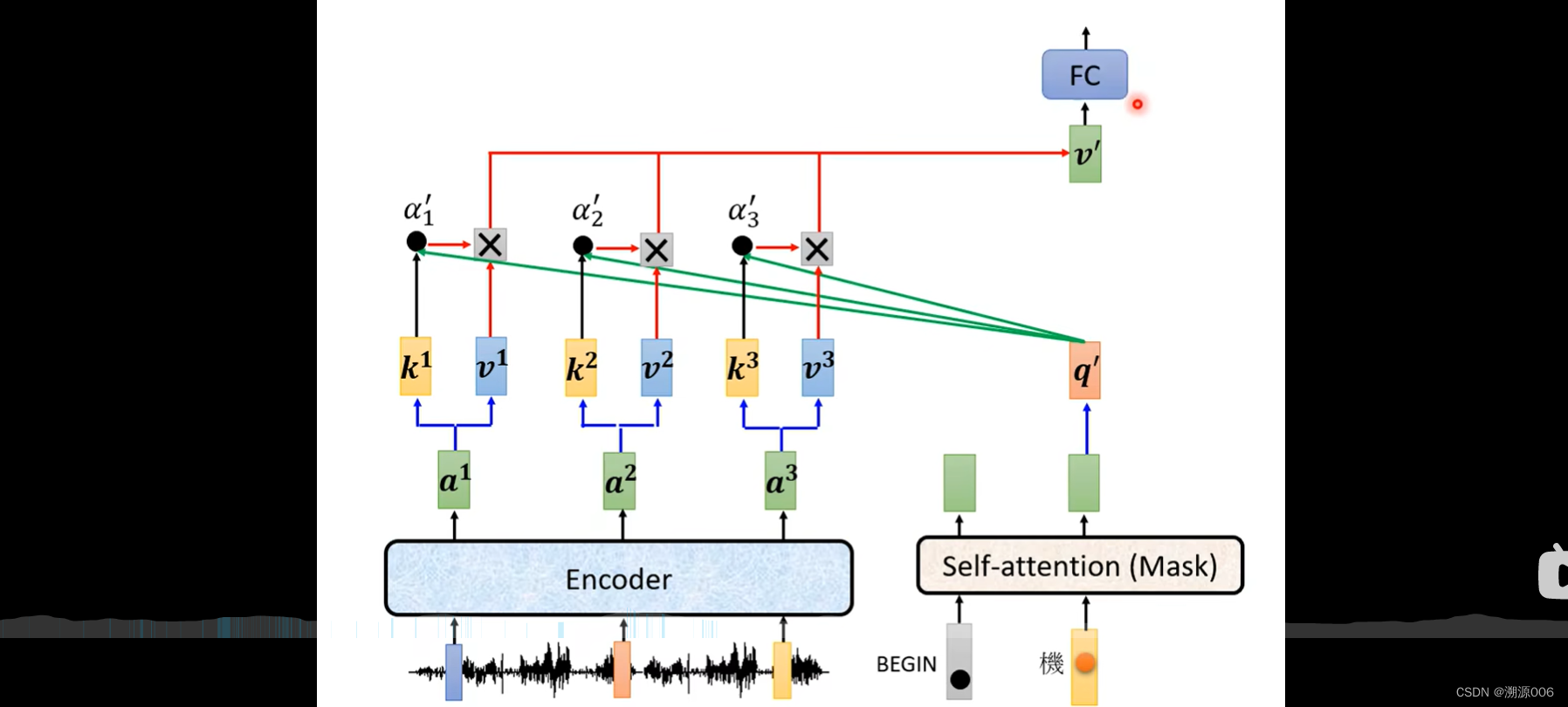
encoder输入一排向量,输出一排向量叫做 a 1 , a 2 , a 3 a^1,a^2,a^3 a1,a2,a3。decoder部分,首先会吃入BEGIN,然后做masked self-attention,得到一个向量,然后乘上一个矩阵,得到一个query q,encoder部分也都产生key: k 1 , k 2 , k 3 k^1,k^2,k^3 k1,k2,k3。把q与 k 1 , k 2 , k 3 k^1,k^2,k^3 k1,k2,k3做内积,得到 α 1 ′ , α 2 ′ , α 3 ′ \alpha'_1,\alpha'_2,\alpha'_3 α1′,α2′,α3′.然后分别乘上 v 1 , v 2 , v 3 v_1,v_2,v_3 v1,v2,v3,加起来得到 v ′ v' v′,然后进入FC。整个过程,q来自decoder,k和v来自encoder,所以整个过程叫cross attention。当然接下来,就是按照AT的方式,继续进行剩下的部分。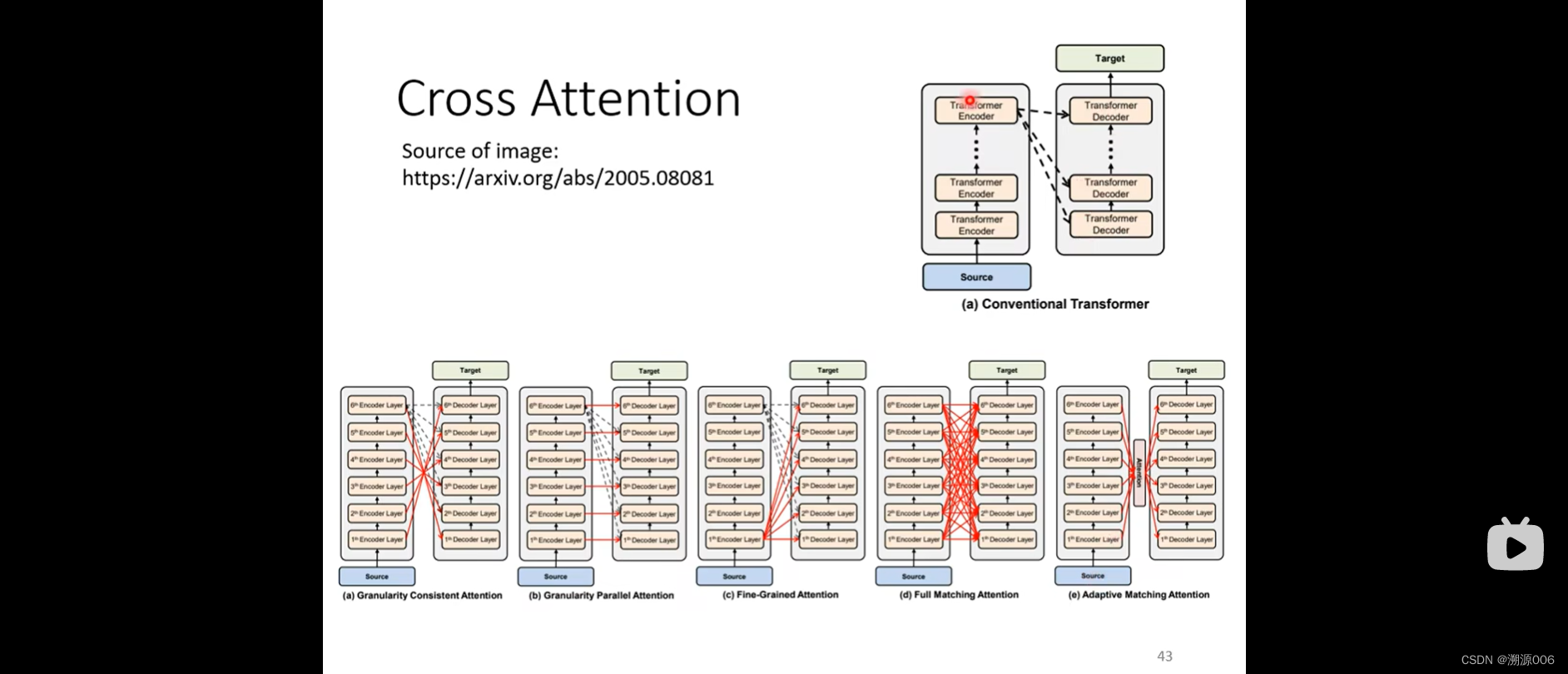
encoder有很多层,decoder有很多层。原始论文decoder的每一层都是拿encoder的最后一层做cross attention。可以涌现新的想法,也有人尝试不同的cross attention的方式。
¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥最后讲训练¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥

还是语音识别的例子。ground truth就是真实字对应的onehot向量,然后采用交叉熵,让预测的输出与ground truth的onehot向量越接近越好。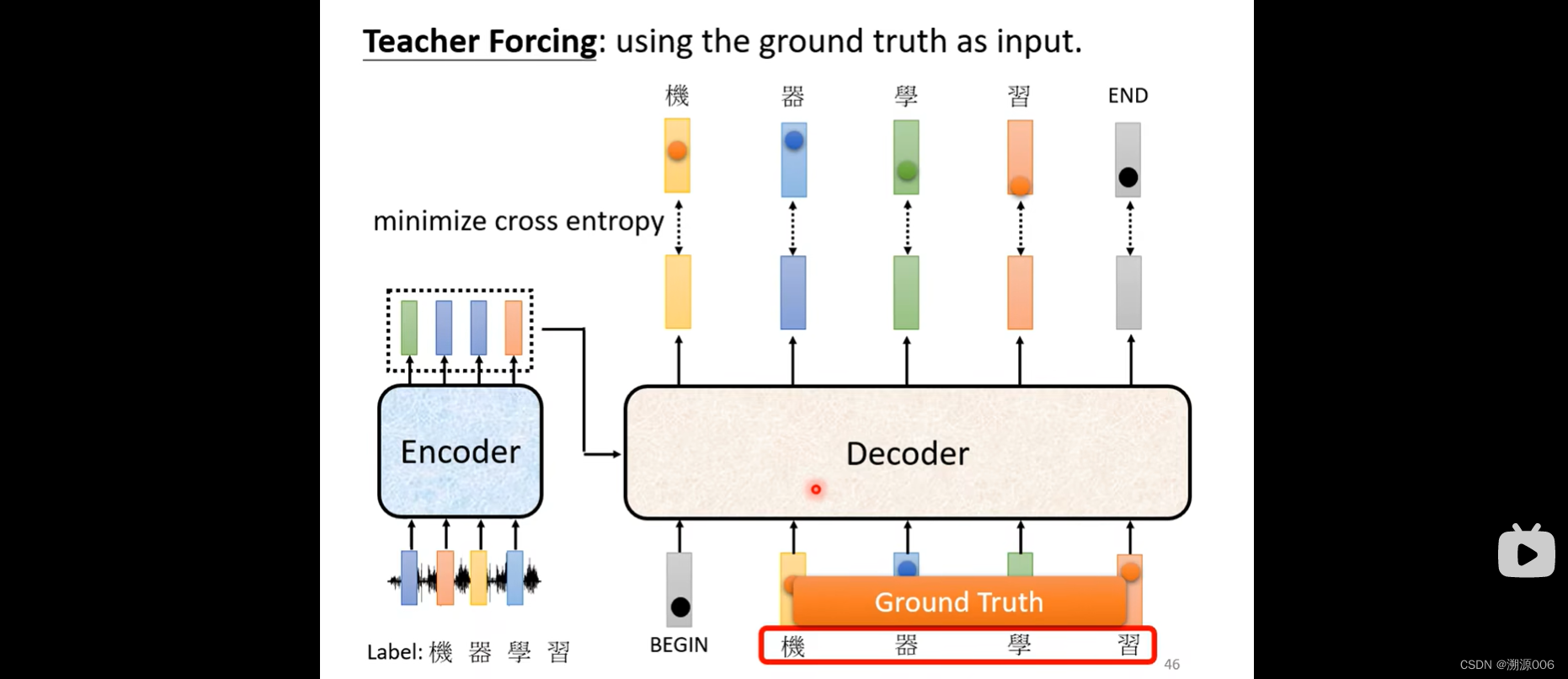
decoder的输入在训练阶段也是采用ground truth(mask的方式保证了前面的输出向量不会考虑后面的输入ground truth)。这个叫做teacher forcing。在inference阶段采用的是decoder的预测的onehot向量。这其中有个mismatch。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)