百度AI比赛-用户购买预测-LGBM模型-当月top1
1:报名地址https://aistudio.baidu.com/aistudio/competition/detail/512:排名分数3:证书登场位置先空着4:模型源码废话不多说,直接上源码import pandas as pdimport numpy as npimport pickle#数据加载raw=pd.read_csv('./train.csv')train_raw=raw[raw[
1:报名地址
https://aistudio.baidu.com/aistudio/competition/detail/51
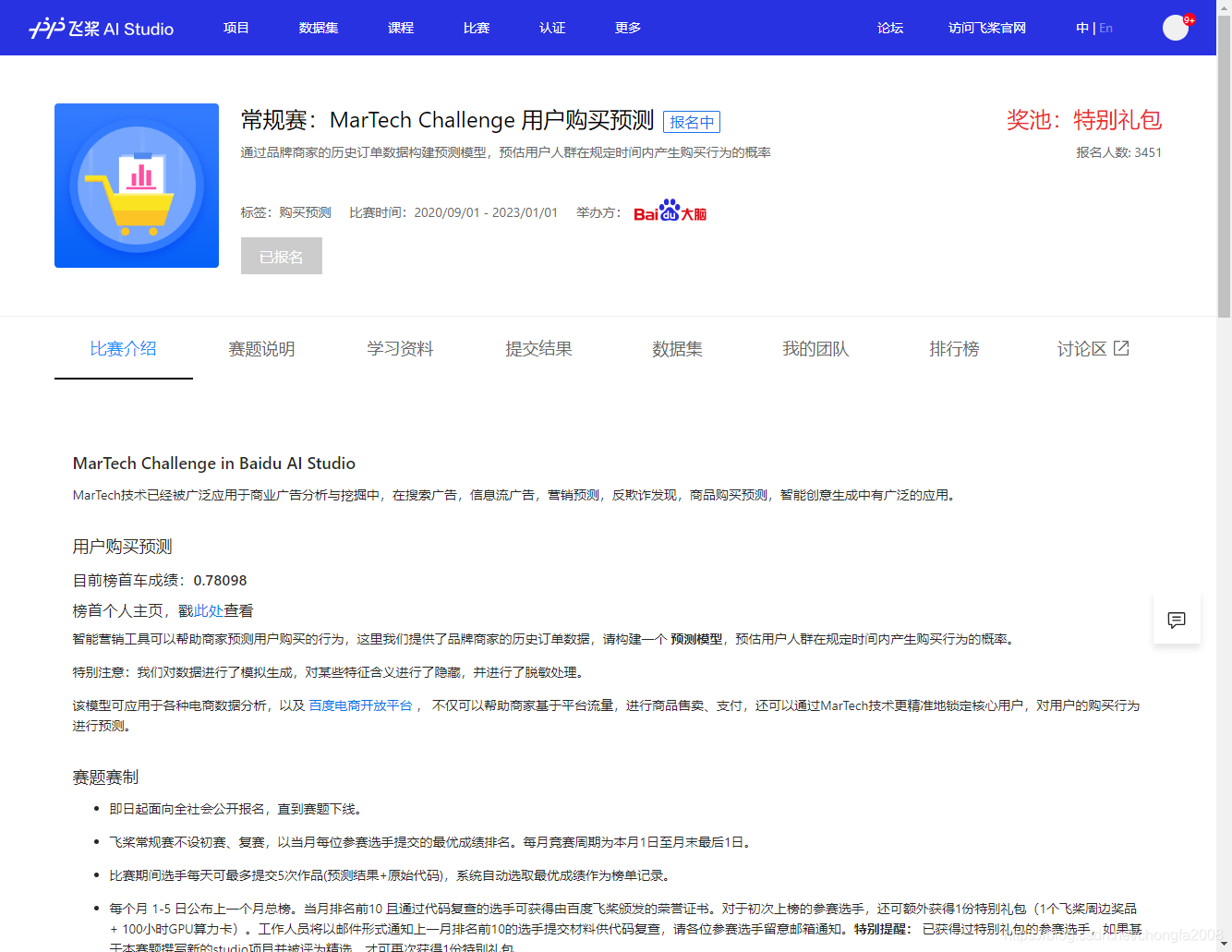
2:排名分数
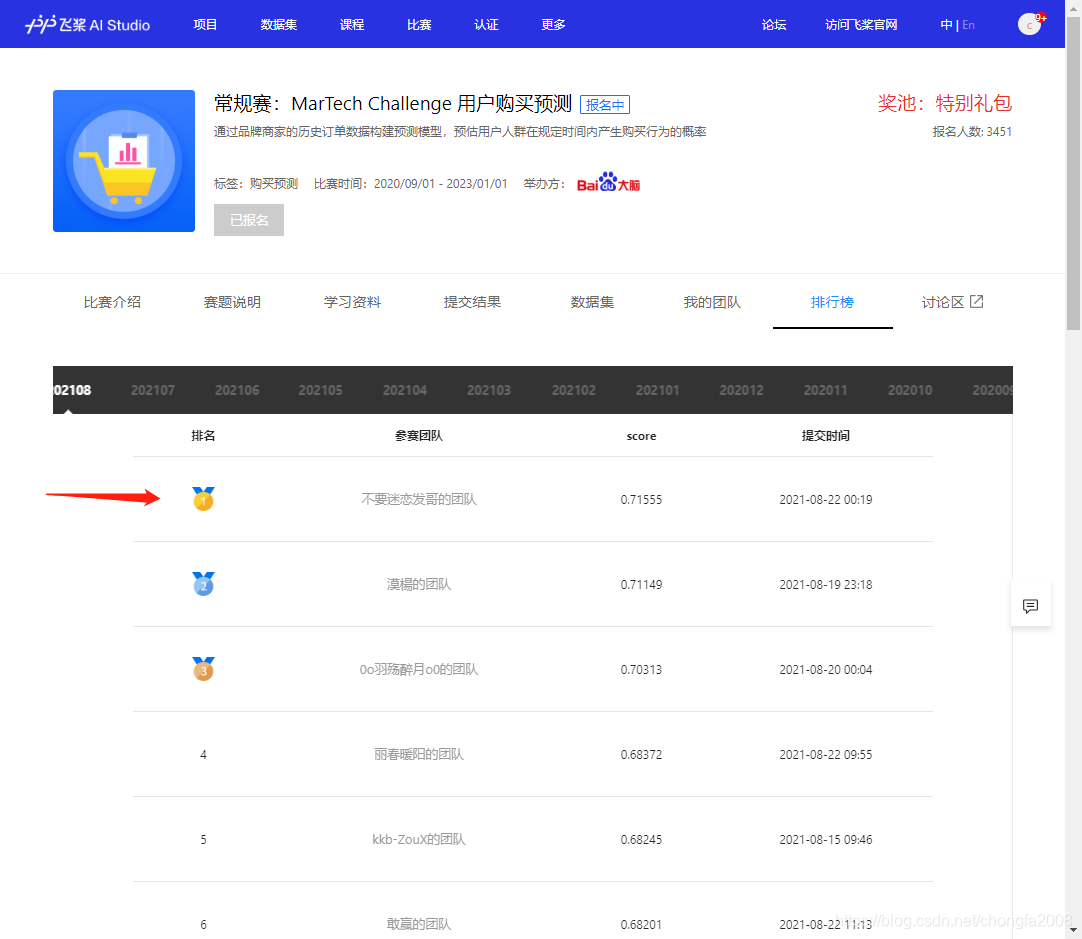
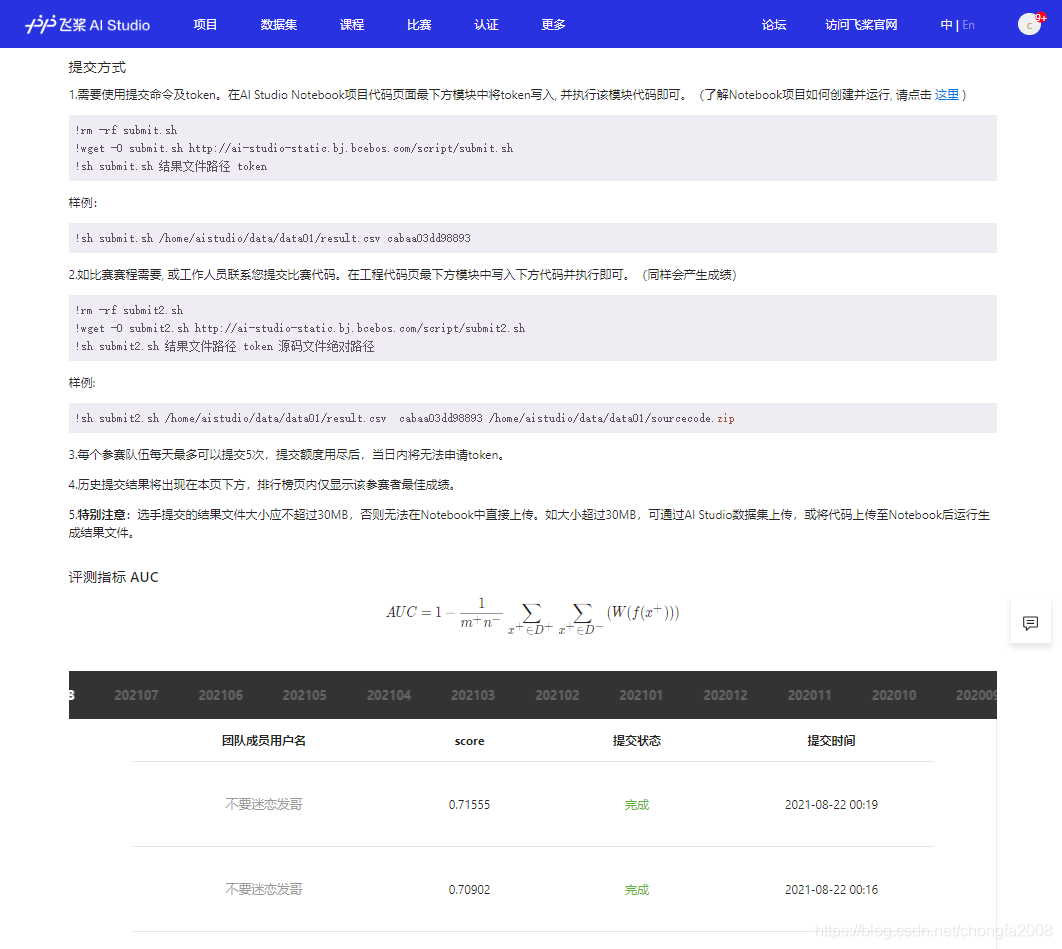
3:证书登场
位置先空着
4: 模型源码
废话不多说,直接上源码
import pandas as pd
import numpy as np
import pickle
#数据加载
raw=pd.read_csv('./train.csv')
train_raw=raw[raw['order_pay_time']<='2013-07-31 23:59:59']
raw.sort_values('order_pay_time',ascending=True,inplace=True)
#下个月8月份 购买的用户集合
label_raw=set(raw[raw['order_pay_time']>'2013-07-31 23:59:59']['customer_id'].dropna())
#数据预处理
def preprocess(raw,train = 'train'):
# 按照customer_id ,统计特征
data = pd.DataFrame(
# 如果 gender 为空, 则填充为0
raw.groupby('customer_id')['customer_gender'].last().fillna(0)
)
# 用户与商品的交互特征(最后一次行为)
data[['goods_id_last','goods_status_last','goods_price_last','goods_has_discount_last','goods_list_time_last',
'goods_delist_time_last']]= \
raw.groupby('customer_id')['goods_id','goods_status','goods_price','goods_has_discount','goods_list_time',
'goods_delist_time'].last()
# 用户与订单的交互特征(最后一次行为)
data[['order_total_num_last','order_amount_last','order_total_payment_last','order_total_discount_last','order_pay_time_last',
'order_status_last','order_count_last','is_customer_rate_last','order_detail_status_last', 'order_detail_goods_num_last',
'order_detail_amount_last','order_detail_payment_last', 'order_detail_discount_last']]= \
raw.groupby('customer_id')['order_total_num', 'order_amount','order_total_payment', 'order_total_discount', 'order_pay_time',
'order_status', 'order_count', 'is_customer_rate','order_detail_status', 'order_detail_goods_num',
'order_detail_amount','order_detail_payment', 'order_detail_discount'].last()
# 用户与会员的交互特征(最后一次行为)++
data[['member_id_last','member_status_last','is_member_actived_last']]= \
raw.groupby('customer_id')['member_id','member_status','is_member_actived'].last()
# 商品原始价格(多种统计字段)
data[['goods_price_min','goods_price_max','goods_price_mean','goods_price_std']]= \
raw.groupby('customer_id',as_index = False)['goods_price'].agg({'goods_price_min':'min','goods_price_max':'max','goods_price_mean':'mean','goods_price_std':'std'}).drop(['customer_id'],axis=1)
#订单实付金额(多种统计字段)
data[['order_total_payment_min','order_total_payment_max','order_total_payment_mean','order_total_payment_std']]= \
raw.groupby('customer_id',as_index = False)['order_total_payment'].agg({'order_total_payment_min':'min','order_total_payment_max':'max',
'order_total_payment_mean':'mean','order_total_payment_std':'std'}).drop(['customer_id'],axis=1)
#用户购买的订单数量
data[['order_count']] = raw.groupby('customer_id',as_index = False)['order_id'].count().drop(['customer_id'],axis=1)
#用户购买商品数量
data[['goods_count']] = raw.groupby('customer_id',as_index = False)['goods_id'].count().drop(['customer_id'],axis=1)
#用户所在省份
data[['customer_province']] = raw.groupby('customer_id')['customer_province'].last()
#用户所在城市
data[['customer_city']] = raw.groupby('customer_id')['customer_city'].last()
#用户是否评价,统计结果(平均,总和)
data[['is_customer_rate_mean','is_customer_rate_sum']]=raw.groupby('customer_id')['is_customer_rate'].agg([
('is_customer_rate_mean',np.mean),
('is_customer_rate_sum',np.sum)
])
#应付金额除以实付金额 ++,优惠比例越大,越容易购买
data['discount']=data['order_detail_amount_last']/data['order_detail_payment_last']
#用户的会员状态,++
data[['member_status_mean','member_status_sum']]=raw.groupby('customer_id')['member_status'].agg([
('member_status_mean',np.mean),
('member_status_sum',np.sum)
])
#订单优惠金额 订单优惠金额越多,越容易购买
data[['order_detail_discount_mean','order_detail_discount_sum']]=raw.groupby('customer_id')['order_detail_discount'].agg([
('order_detail_discount_mean',np.mean),
('order_detail_discount_sum',np.sum)
])
#商品库存状态
data[['goods_status_mean','goods_status_sum']]=raw.groupby('customer_id')['goods_status'].agg([
('goods_status_mean',np.mean),
('goods_status_sum',np.sum)
])
#会员激活状态
data[['is_member_actived_mean','is_member_actived_sum']]=raw.groupby('customer_id')['is_member_actived'].agg([
('is_member_actived_mean',np.mean),
('is_member_actived_sum',np.sum)
])
#订单状态
data[['order_status_mean','order_status_sum']]=raw.groupby('customer_id')['order_status'].agg([
('order_status_mean',np.mean),
('order_status_sum',np.sum)
])
#用户购买的goods数量
data[['order_detail_count']] = raw.groupby('customer_id')['customer_id'].count()
#商品折扣统计属性
data[['goods_has_discount_mean','goods_has_discount_sum']]= raw.groupby('customer_id')['goods_has_discount'].agg([
('goods_has_discount_mean',np.mean),
('goods_has_discount_sum',np.sum)
])
#订单实付金额 统计属性
data[['order_total_payment_mean','order_total_payment_sum']]= raw.groupby('customer_id')['order_total_payment'].agg([
('order_total_payment_mean',np.mean),
('order_total_payment_sum',np.sum)
])
#订单商品数量 统计属性
data[['order_total_num_mean','order_total_num_sum']]= raw.groupby('customer_id')['order_total_num'].agg([
('order_total_num_mean',np.mean),
('order_total_num_sum',np.sum)
])
data['order_pay_time_last'] = pd.to_datetime(data['order_pay_time_last'])
data['order_pay_time_last_m'] = data['order_pay_time_last'].dt.month
data['order_pay_time_last_d'] = data['order_pay_time_last'].dt.day
data['order_pay_time_last_h'] = data['order_pay_time_last'].dt.hour
data['order_pay_time_last_min'] = data['order_pay_time_last'].dt.minute
data['order_pay_time_last_s'] = data['order_pay_time_last'].dt.second
data['order_pay_time_last_weekday'] = data['order_pay_time_last'].dt.weekday
#计算order_pay_time_last的时间diff
t_min=pd.to_datetime('2012-10-11 00:00:00')
data['order_pay_time_last_diff'] = (data['order_pay_time_last']-t_min).dt.days
#商品最新上架时间diff :假设其实时间为2012-10-11 00:00:00
data['goods_list_time_last'] =pd.to_datetime(data['goods_list_time_last'])
data['goods_list_time_diff'] = (data['goods_list_time_last']-t_min).dt.days
#商品最新下架时间diff :假设其实时间为2012-10-11 00:00:00
data['goods_delist_time_last'] =pd.to_datetime(data['goods_delist_time_last'])
data['goods_delist_time_diff'] = (data['goods_delist_time_last']-t_min).dt.days
#商品展示时间(下架时间-上架时间)
data['goods_time_diff'] = data['goods_delist_time_diff']-data['goods_list_time_diff']
return data
#训练集预处理
train_raw2=preprocess(train_raw)
train_raw2['label']=train_raw2.index.map(lambda x:int(x in label_raw))
train_raw2.drop(['goods_list_time_last','goods_delist_time_last','order_pay_time_last'],axis=1,inplace=True)
#测试集预处理
test=preprocess(raw)
test.drop(['goods_list_time_last','goods_delist_time_last','order_pay_time_last'],axis=1,inplace=True)
#训练集与测试集-省市进行LabelEncoder
test['customer_province'] = test['customer_province'].astype('str')
test['customer_city'] = test['customer_city'].astype('str')
train_raw2['customer_province'] = train_raw2['customer_province'].astype('str')
train_raw2['customer_city'] = train_raw2['customer_city'].astype('str')
from sklearn.preprocessing import LabelEncoder
lel=LabelEncoder()
test['customer_province']=lel.fit_transform(test['customer_province'])
train_raw2['customer_province']=lel.fit_transform(train_raw2['customer_province'])
le2=LabelEncoder()
test['customer_city']=le2.fit_transform(test['customer_city'])
train_raw2['customer_city']=le2.fit_transform(train_raw2['customer_city'])
from sklearn.preprocessing import LabelEncoder
lel=LabelEncoder()
test['customer_province']=lel.fit_transform(test['customer_province'])
train_raw2['customer_province']=lel.fit_transform(train_raw2['customer_province'])
le2=LabelEncoder()
test['customer_city']=le2.fit_transform(test['customer_city'])
train_raw2['customer_city']=le2.fit_transform(train_raw2['customer_city'])
#预处理数据临时保存
import pickle
test[test.index==1585917]['customer_city']
train_raw2.to_pickle('./train_raw.pkl')
test.to_pickle('./test.pkl')
#加载预处理的文件
with open('./train_raw.pkl', 'rb') as file:
train_raw2 = pickle.load(file)
with open('./test.pkl', 'rb') as file:
test = pickle.load(file)
train_raw2=train_raw2.reset_index()
test=test.reset_index()
all_df=pd.concat([train_raw2,test],axis=0)
train_raw2=all_df[all_df['label'].notnull()]
test=all_df[all_df['label'].isnull()]
#LGBM建模
import lightgbm as lgb
# LGBMClassifier经验参数
clf = lgb.LGBMClassifier(
num_leaves=2**5-1, reg_alpha=0.25, reg_lambda=0.25, objective='binary',
max_depth=-1, learning_rate=0.005, min_child_samples=3, random_state=2021,
n_estimators=2500, subsample=1, colsample_bytree=1,
)
clf.fit(train_raw2.drop(['label','customer_id'],axis=1),train_raw2['label'])
#结果处理
#buy_num设置的值
#0.70457,300000
#0.7139,400000
#0.71512,500000
#0.70902 600000
#0.71555 450000
cols=train_raw2.columns.tolist()
cols.remove('label')
cols.remove('customer_id')
y_pred=clf.predict_proba(test.drop(['label','customer_id'],axis=1))[:,1]
result=pd.read_csv('./submission.csv')
result['result']=y_pred
result2=result.sort_values('result',ascending=False).copy()
buy_num=450000
result2.index=range(len(result2))
result2.loc[result.index<=buy_num,'result']=1
result2.loc[result.index>buy_num,'result']=0
result2.sort_values('customer_id',ascending=True,inplace=True)
result2.to_csv('./baseline_0.7155.csv',index=False)5:提分要领
1:结果集buy_num参数的调整对结果集的影响比较大
刚刚开始buy_num设置为10000左右分数比较低 0.5左右
我们在面对参数值调参的过程中可以采用2倍方式调整,例如第一次buy_num=10000,后面依次是20000,40000,80000....每次都以指数的方式增加,当出现分数有下降的趋势,则可以缩小访问,一步步的逼近当前模型的最高分
2:特征值的处理永远都是提分的关键
如何抓取到准确的特征值,更多的是考个人对当前领域场景的把控。例如本次是购买预测,可以结合自己在购买东西时候的关注点,再进行分析。
例如折扣费用,库存,优惠金额等等都是作为一个购买者考虑的问题。
6:相关知识
LGBMClassifier经验参数
import lightgbm as lgb
clf = lgb.LGBMClassifier(
num_leaves=2**5-1, reg_alpha=0.25, reg_lambda=0.25, objective='binary', max_depth=-1, learning_rate=0.005, min_child_samples=3, random_state=2021, n_estimators=2000, subsample=1, colsample_bytree=1,
)
num_leavel=2**5-1 #树的最大叶子数,对比XGBoost一般为2^(max_depth) reg_alpha,L1正则化系数
reg_lambda,L2正则化系数
max_depth,最大树的深度
n_estimators,树的个数,相当于训练的轮数
subsample,训练样本采样率(行采样)
colsample_bytree,训练特征采样率(列采样)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)