卡方分布与卡方检验
1.卡方分布卡方分布(chi-square distribution, χ2χ2\chi^2-distribution)是概率统计里常用的一种概率分布,也是统计推断里应用最广泛的概率分布之一,在假设检验与置信区间的计算中经常能见到卡方分布的身影。我们先来看看卡方分布的定义:若k个独立的随机变量Z1,Z2,⋯,Zk,且符合标准正态分布N(0,1),则这k个随机变量的平方和X=∑i...
1.卡方分布
卡方分布(chi-square distribution, χ2χ2<script type="math/tex" id="MathJax-Element-1">\chi^2</script>-distribution)是概率统计里常用的一种概率分布,也是统计推断里应用最广泛的概率分布之一,在假设检验与置信区间的计算中经常能见到卡方分布的身影。
我们先来看看卡方分布的定义:
若k个独立的随机变量Z1,Z2,⋯,Zk,且符合标准正态分布N(0,1),则这k个随机变量的平方和
为服从自由度为k的卡方分布,记为:
也可以记为:
卡方分布的期望与方差分为为:
E(χ2)=nE(χ2)=n<script type="math/tex" id="MathJax-Element-5">E(\chi^2) = n</script>,D(χ2)=2nD(χ2)=2n<script type="math/tex" id="MathJax-Element-6">D(\chi^2) = 2n</script>,其中n为卡方分布的自由度。
2.卡方检验
χ2χ2<script type="math/tex" id="MathJax-Element-7">\chi^2</script>检验是以χ2χ2<script type="math/tex" id="MathJax-Element-8">\chi^2</script>分布为基础的一种假设检验方法,主要用于分类变量。其基本思想是根据样本数据推断总体的分布与期望分布是否有显著性差异,或者推断两个分类变量是否相关或者独立。
一般可以设原假设为 H0H0<script type="math/tex" id="MathJax-Element-9">H_0</script>:观察频数与期望频数没有差异,或者两个变量相互独立不相关。
实际应用中,我们先假设H0H0<script type="math/tex" id="MathJax-Element-10">H_0</script>成立,计算出χ2的值,χ2χ2<script type="math/tex" id="MathJax-Element-11">\chi^2</script>表示观察值与理论值之间的偏离程度。根据χ2χ2<script type="math/tex" id="MathJax-Element-12">\chi^2</script>分布,χ2χ2<script type="math/tex" id="MathJax-Element-13">\chi^2</script>统计量以及自由度,可以确定在H0H0<script type="math/tex" id="MathJax-Element-14">H_0</script>成立的情况下获得当前统计量以及更极端情况的概率p。如果p很小,说明观察值与理论值的偏离程度大,应该拒绝原假设。否则不能拒绝原假设。
χ2χ2<script type="math/tex" id="MathJax-Element-15">\chi^2</script>的计算公式为:
其中,A为实际值,T为理论值。
χ2χ2<script type="math/tex" id="MathJax-Element-17">\chi^2</script>用于衡量实际值与理论值的差异程度,这也是卡方检验的核心思想。χ2χ2<script type="math/tex" id="MathJax-Element-18">\chi^2</script>包含了以下两个信息:
- 实际值与理论值偏差的绝对大小。
- 差异程度与理论值的相对大小。
3.卡方检验做特征选择
卡方检验经常被用来做特征选择。举个网络上的例子,假设我们有一堆新闻标题,需要判断标题中包含某个词(比如吴亦凡)是否与该条新闻的类别归属(比如娱乐)是否有关,我们只需要简单统计就可以获得这样的一个四格表:
| 组别 | 属于娱乐 |
不属于娱乐 |
合计 |
|---|---|---|---|
不包含吴亦凡 |
19 | 24 | 43 |
包含吴亦凡 |
34 | 10 | 44 |
| 合计 | 53 | 34 | 87 |
通过这个四格表我们得到的第一个信息是:标题是否包含吴亦凡确实对新闻是否属于娱乐有统计上的差别,包含吴亦凡的新闻属于娱乐的比例更高,但我们还无法排除这个差别是否由于抽样误差导致。那么首先假设标题是否包含吴亦凡与新闻是否属于娱乐是独立无关的,随机抽取一条新闻标题,属于娱乐类别的概率是:(19 + 34) / (19 + 34 + 24 +10) = 60.9%
理论值的四格表为:
| 组别 | 属于娱乐 |
不属于娱乐 |
合计 |
|---|---|---|---|
不包含吴亦凡 |
43 * 0.609 = 26.2 | 43 * 0.391 = 16.8 | 43 |
包含吴亦凡 |
44 * 0.609 = 26.8 | 44 * 0.391 = 17.2 | 44 |
显然,如果两个变量是独立无关的,那么四格表中的理论值与实际值的差异会非常小。
则χ2χ2<script type="math/tex" id="MathJax-Element-49">\chi^2</script>值为:
标准的四格表χ2χ2<script type="math/tex" id="MathJax-Element-51">\chi^2</script>值可以用以下方式进行计算:
其中,N=A+B+C+DN=A+B+C+D<script type="math/tex" id="MathJax-Element-53">N = A+B+C+D</script>
得到χ2χ2<script type="math/tex" id="MathJax-Element-54">\chi^2</script>的值以后,怎样可以得知无关性假设是否可靠?接下来我们应该查询卡方分布的临界值表了。
首先我们明确自由度的概念:自由度v=(行数-1)*(列数-1)。
然后看卡方分布的临界概率,表如下: 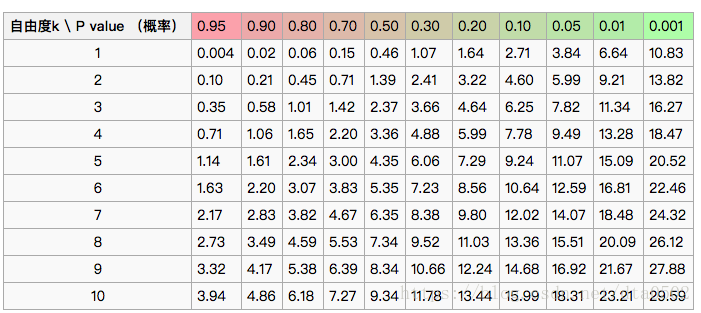
一般我们取p=0.05,也就是说两者不相关的概率为0.05时,对应的卡方值为3.84。显然10.0>3.84,那就说明包含吴亦凡的新闻不属于娱乐的概率小于0.05。换句话说,包含吴亦凡的新闻与娱乐新闻相关的概率大于95%!
总结一下:我们可以通过卡方值来判断特征是否与类型有关。卡方值越大,说明关联越强,特征越需要保留。卡方值越小,说明越不相关,特征需要去除。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)