NLP学习
自然语言处理部分基础知识
(本文是跟着黑马程序视频做的笔记)
自然语言处理:计算机科学与人类语言转换的领域
一、文本预处理
1.jiba工具的使用
基本使用
import jieba
content="工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作"
jieba.cut(content,cut_all = False) //精确模式切割,返回生成器对象
jieba.lcut(content,cut_all = False) //精确模式切割,返回具体切割内容
//默认的情况下是精确分割
jieba.cut(content,cut_all = True) //全模式切割
jieba.lcut(content,cut_all = True) //全模式切割
jieba.cut_for_search(content) //搜索引擎模式分词
jieba.lcut_for_search(content) //搜索引擎模式分词

使用用户自定义词典
词典格式:词语 词频 词性
例:云计算 5 n
import jieba
result4 = jieba.lcut("八一双鹿更名为八一南昌篮球队!")
print("未使用自定义词典:",result4)
jieba.load_userdict("./userdict.txt")
result5 = jieba.lcut("八一双鹿更名为八一南昌篮球队!")

2.流行中英文分词工具hanlp
使用pip安装
pip install hanlp
import hanlp
//使用hanlp进行中文分词
tokenizer = hanlp.load('CTB6_CONVSEG')
tokenizer("工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作")
//使用hanlp进行英文分词
from hanlp.utils.lang.en.english_tokenizer import tokenize_english
tokenizer = tokenize_english
tokenizer('My Hanks bought hanks.com for 1.5 thousand dollars.')
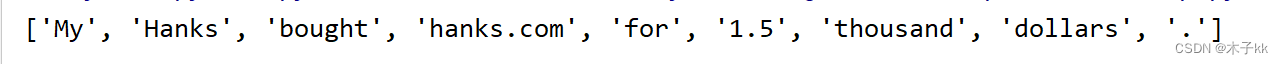
3.命名实体识别NER
使用hanlp进行中文命名实体识别
import hanlp
recognizer = hanlp.load(hanlp.pretrained.ner.MSRA_NER_BERT_BASE_ZH)
list('上海华安工业(集团)公司董事长谭旭光和秘书长晚霞来到美国纽约现代艺术博物馆参观')
recognizer(list('上海华安工业(集团)公司董事长谭旭光和秘书长晚霞来到美国纽约现代艺术博物馆参观'))
使用hanlp进行英文命名实体识别
import hanlp
recognizer = hanlp.load(hanlp.pretrained.ner.CONLL03_NER_BERT_BASE_UNCASED_EN)
recognizer(["Presient","Obama","is","speaking","at","the","White","House"])
4. 词性标注POS
使用jieba进行词性标注
import jieba.posseg as pseg
pseg.lcut("我爱北京天安门")
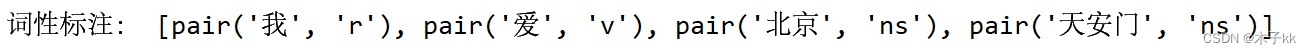
使用hanlp进行中文词性标注
import hanlp
tagger = hanlp.load(hanlp.pretained.pos.CTB5_POS_RNN_FASTTEXT_ZH)
tagger(["我","的","希望","是","希望","和平"])
使用hanlp进行英文词性标注
import hanlp
tagger = hanlp.load(hanlp.pretained.pos.PTB_POS_RNN_FASTTEXT_EN)
tagger(['I','banked','2','dollars','in','a','bank','.'])
5.文本张量的表示方法
5.1 one-hot词向量表示
优点:操作简单,容易理解
缺点:完全割裂了词与词之间的关系,而且大语料集下,每个向量的长度过大,占据大量内存
from sklearn.externals import joblib
from keras.preprocessing.text import Tokenizer
vocab ={"周杰伦","陈奕迅","鹿晗","李宗盛","李荣浩"}
//实例化一个词汇映射对象
t = Tokenizer(num_words=None,char_level=False)
//使用词汇映射器拟合现有文本数据
t.fit_on_texts(vocab)
for token in vocab:
zero_list = [0]*len(vocab) //初始化全0序列
token_index = t.texts_to_sequences([token])[0][0]-1
//取出其中的数字需要用[0][0]
zero_list[token_index] = 1
print(token,"的one-hot编码为:",zero_list)
使用jolib工具保存映射器,以便以后使用
tokenizer_path = "./Tokenizer"
joblib.dump(t,tokenizer_path)

对保存下来的映射器再次使用
from sklear.externals import joblib
t = joblib.load("./Tokenizer")
token = "周杰伦"
token_index = t.texts_to_sequences([token])[0][0]-1
zero_list = [0]*len(vocab)
zero_list[token_index] = 1
print(token,"的one-hot编码为:",zero_list)
5.2 word2vec词向量表示
- 表示成向量的无监督训练方法,包含CBOW和skipgram两种训练模式。One-hot表示无法显示出两个词之间的相似关系
- Word2vec 本质上是一种降维操作:把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示
- 模型为浅层双层的神经网络,用来训练以重新构建语言学之词文本。
- 网络以词表现,并且需要猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。
- 缺点:没有考虑多义词、窗口长度有限、没有考虑全局的文本信息、不是严格意义的语序
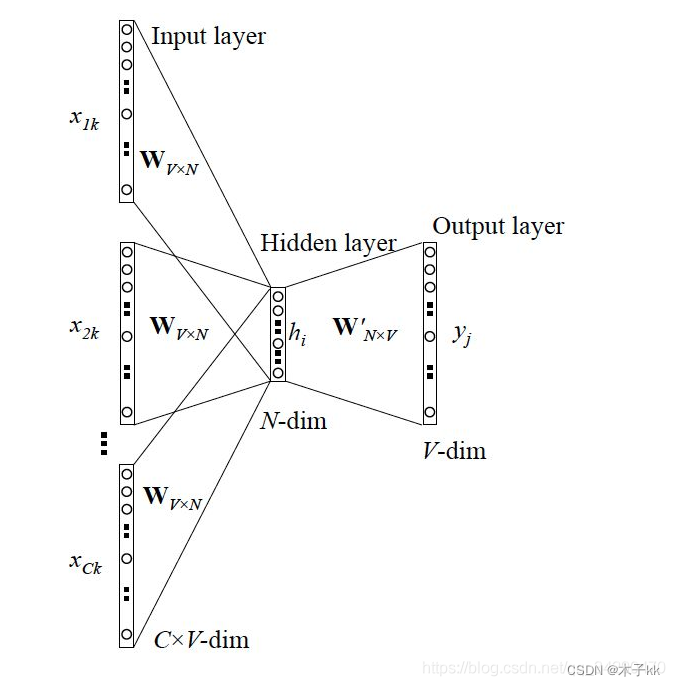
- CBOW(Continous bag of words)模式:使用上下文词汇预测目标词汇
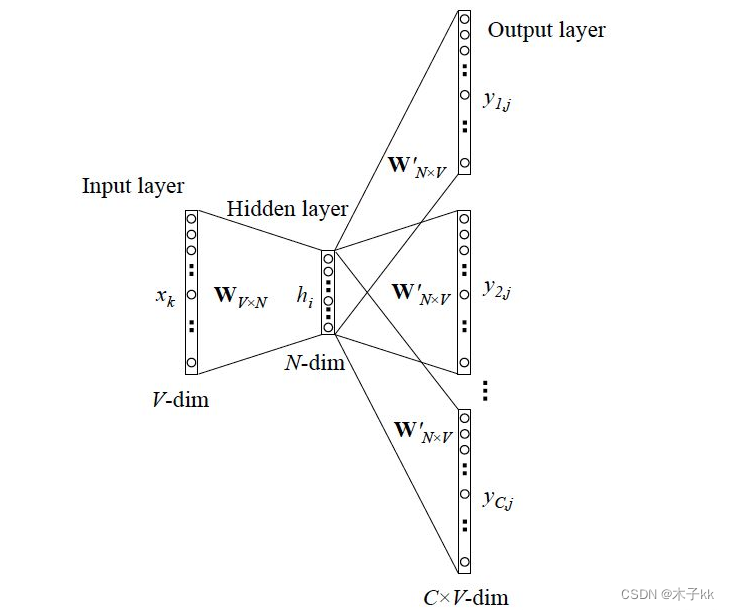
- skipgram模式使用目标词汇预测上下文词汇
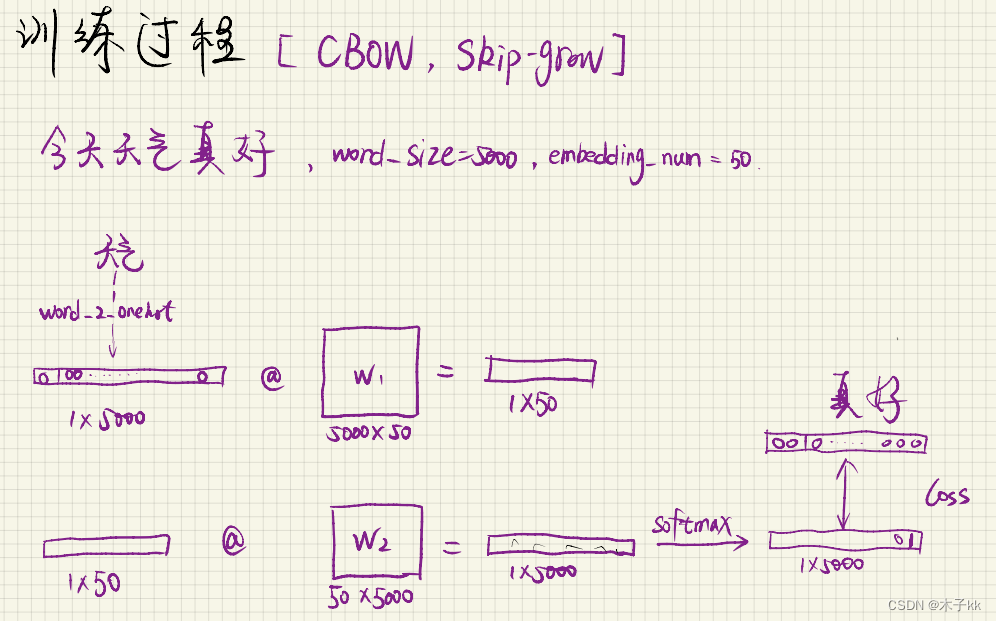
隐藏层的神经元应该设置多少个,取决于希望得到的词向量的维数,google给出的经验值是300。
假设某词向量的编码是8维的,隐藏层神经元有3个,那隐藏层的权重就是一个8行3列的矩阵。
网络训练完成后,隐藏层权重的每一行代表一个词向量。
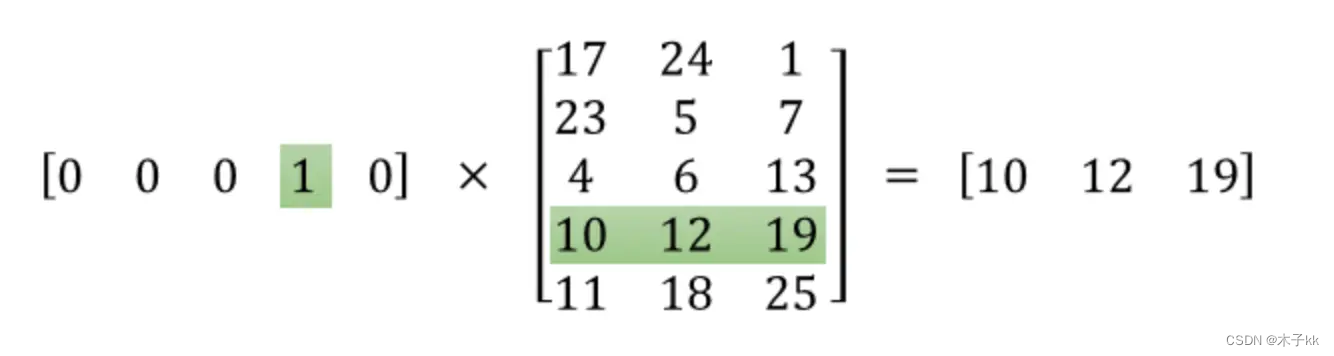
只需要保存隐藏层的权重矩阵,又因为输入是one-hot编码,所以用输入向量乘以这个权重矩阵就得到了对应的词向量
CBOW计算流程的不同之处在于隐藏层不再是取一个词的词向量各维,而是上下文C个词的词向量各维的平均值
一般来说, Skip-Gram模型比CBOW模型更好,因为:
- Skip-Gram模型有更多的训练样本。Skip-Gram是一个词预测n个词,而CBOW是n个词预测一个词。
- 误差反向更新中,CBOW是中心词误差更新n个周边词,这n个周边词被更新的力度是一样的。而Skip-Gram中,每个周边词都可以根据误差更新中心词,所以Skip-Gram是更细粒度的学习方法。
- Skip-Gram效果更好,但是缺点就是训练次数更多,时间更长。
word2vec理论:https://www.jianshu.com/p/21787731ca87
https://zhuanlan.zhihu.com/p/27234078
https://zhuanlan.zhihu.com/p/375614469
word2vec两种优化解法以及fastText 模型---->https://blog.csdn.net/m0_64375823/article/details/121581268。负采样用得较多,因为构建霍夫曼树比较麻烦
- fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
- fastText只有CBOW模型,对应fastText.train_supervised 没有model参数。
- Word2Vec有两种模型,所以fastText.train_unsupervised可以选择model={cbow, skipgram} ,默认skipgram。
- fastText 本身是词袋模型,为了分类的准确性,所以加入了 N-gram 特征提取词序信息。
- n-gram的问题是词表会急剧扩大 ,没有机器扛得住。所以使用散列法(Hash)对n-gram特征进行压缩。
- 代码实践1
import numpy as np
import pandas as pd
import pickle
import jieba
import os
from tqdm import tqdm
def load_stop_words(file="stopwords.txt"):
with open(file, "r", encoding="utf-8") as f:
return f.read().split("\n")
# 用\n切分
def cut_words(file="数学原始数据.csv"):
# 停用词列表
stop_words = load_stop_words()
# 结果列表
result = []
all_data = pd.read_csv(file, encoding="gbk", names=["data"])["data"]
for words in all_data:
c_words = jieba.lcut(words)
# 去掉停用词
result.append([word for word in c_words if word not in stop_words])
return result
def get_dict(data):
index_2_word = []
# 对词库遍历
for words in data:
for word in words:
# 检查是否已经存在于词库里面,若不存在则加进去
if word not in index_2_word:
index_2_word.append(word)
word_2_index = {word:index for index,word in enumerate(index_2_word)}
word_size = len(word_2_index)
word_2_onehot = {}
for word, index in word_2_index.items():
# 先构建全为0的向量
one_hot = np.zeros((1, word_size))
# 相应位置赋值为1
one_hot[0, index] = 1
# 添加键值对
word_2_onehot[word] = one_hot
return word_2_index, index_2_word, word_2_onehot
def softmax(x):
ex = np.exp(x)
# axis指定求和的方向,keepdims保持维度
return ex/np.sum(ex, axis=1, keepdims=True)
if __name__ == "__main__":
data = cut_words()
word_2_index, index_2_word, word_2_onehot = get_dict(data)
word_size = len(word_2_index)
# 预设的词向量维度,一般是100——300
embedding_num = 107
# 学习率
lr = 0.01
# 训练次数
epoch = 10
# 相关词数量
n_gram = 3
# 初始化矩阵
w1 = np.random.normal(-1, 1, size=(word_size, embedding_num))
w2 = np.random.normal(-1, 1, size=(embedding_num, word_size))
for e in range(epoch):
for words in tqdm(data):
for n_index, now_word in enumerate(words):
now_word_onehot = word_2_onehot[now_word]
# 获取上下文
other_words = words[max(n_index-n_gram, 0):n_index] + words[n_index+1:n_index+1+n_gram]
for other_word in other_words:
other_word_onehot = word_2_onehot[other_word]
# 隐藏层
hidden = now_word_onehot @ w1
p = hidden @ w2
pre = softmax(p)
# loss = -np.sum(other_word_onehot * np.log(pre))
# A @ B = C
# delta_C = G
# delta_A = G @ B.T
# delta_B = A.T @ G
G2 = pre - other_word_onehot
delta_w2 = hidden.T @ G2
G1 = G2 @ w2.T
delta_w1 = now_word_onehot.T @ G1
w1 -= lr * delta_w1
w2 -= lr * delta_w2
with open("word2vec.pkl", "wb") as f:
pickle.dump([w1, word_2_index, index_2_word], f) # word2vec 负采样
import pickle
import numpy as np
# w1, voc_index, index_voc, w2 = pickle.load(open('word2vec.pkl', 'rb'))
w1, voc_index, index_voc = pickle.load(open('word2vec.pkl', 'rb'))
def word_voc(word):
return w1[voc_index[word]]
def voc_sim(word, top_n):
v_w1 = word_voc(word)
word_sim = {}
for i in range(len(voc_index)):
v_w2 = w1[i]
theta_sum = np.dot(v_w1, v_w2)
theta_den = np.linalg.norm(v_w1) * np.linalg.norm(v_w2)
theta = theta_sum / theta_den
word = index_voc[i]
word_sim[word] = theta
words_sorted = sorted(word_sim.items(), key=lambda kv: kv[1], reverse=True)
for word, sim in words_sorted[:top_n]:
print(word, sim)
voc_sim('整数',20)

5.3 word embedding
- 通过一定的方式将词汇映射到指定维度的空间
- 广义的word embedding包括所有密集词汇向量的表示方法,Word2vec可认为是word embedding的一种
- 狭义的word embedding是指在神经网络中加入的embedding层,对整个网络训练的同时产生的embedding矩阵。
6.文本数据分析
作用:理解数据语料
常用方法:
- 标签数量分布
- 句子长度分布
- 词频统计与关键词云
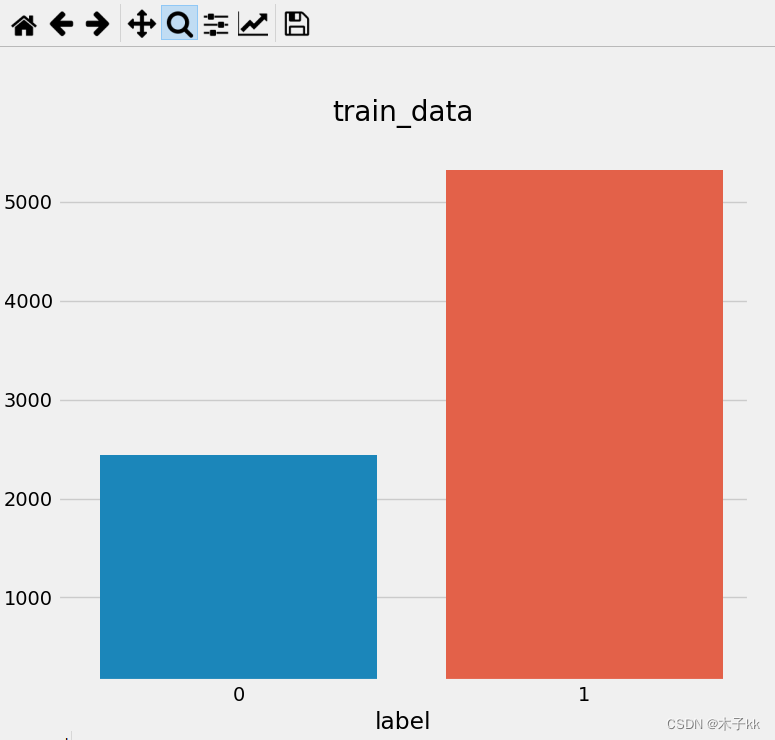
6.1 标签数量分布
在深度学习模型评估中, 我们一般使用ACC作为评估指标, 若想将ACC的基线定义在50%左右,
则需要我们的正负样本比例维持在1:1左右, 否则就要进行必要的数据增强或数据删减.
若训练和验证集正负样本都稍有不均衡, 可以进行一些数据增强.
 https://www.jianshu.com/p/15af3193be5b
https://www.jianshu.com/p/15af3193be5b
# comments.tsv中的数据内容共分为2列, 第2列数据review代表具有感情色彩的评论文本; 第1列数据label, 0或1, 代表每条文本数据是积极或者消极的评论, 0代表消极, 1代表积极.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 设置显示风格
plt.style.use('fivethirtyeight')
# 读取训练tsv
train_data = pd.read_csv("./data/comments.csv",sep=",")
# 获得训练数据标签数量分布
sns.countplot("label",data = train_data)
plt.title("train_data")
plt.show()
6.2 句子长度分布
通过绘制句子长度分布图, 可以得知语料中大部分句子长度的分布范围, 因为模型的输入要求为固定尺寸的张量,
合理的长度范围对之后进行句子截断补齐(规范长度)起到关键的指导作用.
# 在训练数据中添加新的句子长度列, 每个元素的值都是对应的句子列的长度
train_data["sentence_length"] = list(map(lambda x: len(x), train_data["review"]))
# 绘制句子长度列的数量分布图
sns.countplot("sentence_length", data=train_data)
# 主要关注count长度分布的纵坐标, 不需要绘制横坐标, 横坐标范围通过dist图进行查看
plt.xticks([])
plt.show()
# 绘制dist长度分布图
sns.distplot(train_data["sentence_length"])
# 主要关注dist长度分布横坐标, 不需要绘制纵坐标
plt.yticks([])
plt.show()
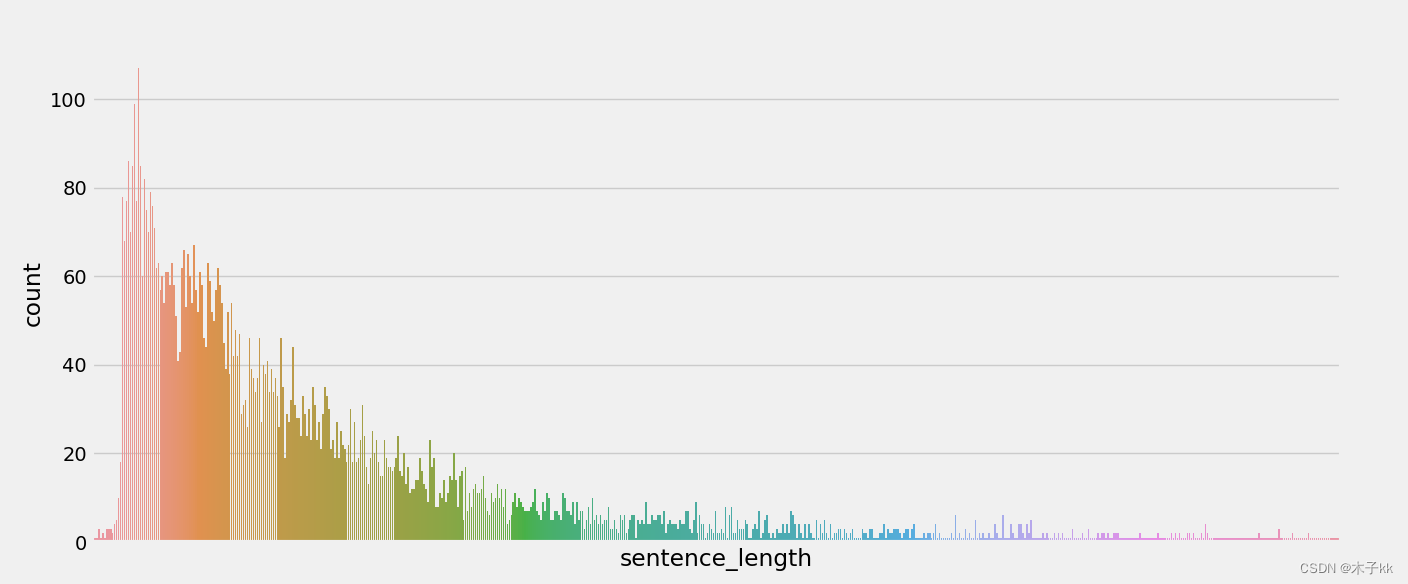
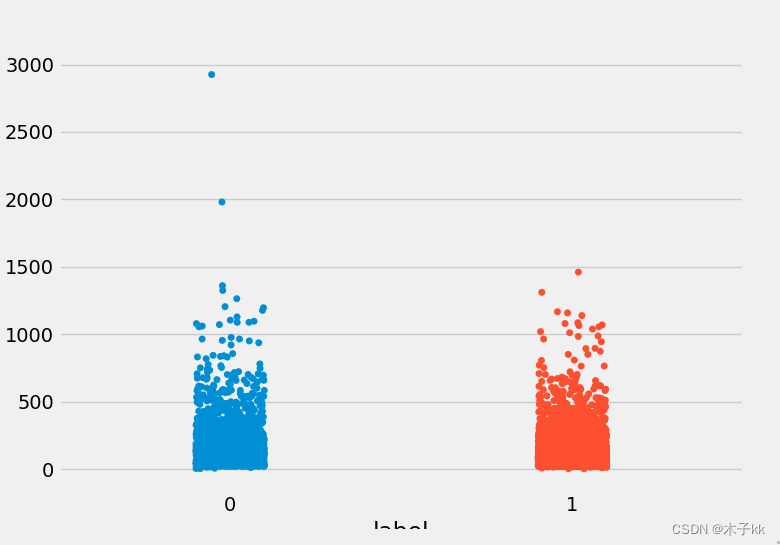
散点分布图:通过查看正负样本长度散点图, 可以有效定位异常点的出现位置, 帮助我们更准确进行人工语料审查.
# 绘制长度分布的散点图
sns.stripplot(y='sentence_length',x='label',data=train_data)
plt.show()
6.3 获得数据集不同词汇总数统计
chain的作用
from itertools import chain
a = [1, 2, 3, 4]
b = [‘x’, ‘y’, ‘z’]
for x in chain(a, b):
print(x)
输出:
1
2
3
4
x
y
z
# 导入jieba用于分词
# 导入chain方法用于扁平化列表
import jieba
from itertools import chain
# 进行数据集的句子进行分词, 并统计出不同词汇的总数
train_vocab = set(chain(*map(lambda x: jieba.lcut(x), train_data["review"])))
print("数据集共包含不同词汇总数为:", len(train_vocab))
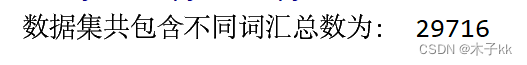
6.4 获得数据集上正负的样本的高频形容词词云
根据高频形容词词云显示, 我们可以对当前语料质量进行简单评估, 同时对违反语料标签含义的词汇进行人工审查和修正, 来保证绝大多数语料符合训练标准.
# 使用jieba中的词性标注功能
import jieba.posseg as pseg
import matplotlib.pyplot as plt
from itertools import chain
# 导入绘制词云的工具包
from wordcloud import WordCloud
import pandas as pd
def get_a_list(text):
"""用于获取形容词列表"""
# 使用jieba的词性标注方法切分文本,获得具有词性属性flag和词汇属性word的对象,
# 从而判断flag是否为形容词,来返回对应的词汇
r = []
for g in pseg.lcut(text):
if g.flag == "a":
r.append(g.word)
return r
def get_word_cloud(keywords_list):
# 实例化绘制词云的类, 其中参数font_path是字体路径, 为了能够显示中文,
# max_words指词云图像最多显示多少个词, background_color为背景颜色
wordcloud = WordCloud(font_path="/data/simkai.ttf", max_words=100, background_color="white")
# 将传入的列表转化成词云生成器需要的字符串形式
keywords_string = " ".join(keywords_list)
# 生成词云
wordcloud.generate(keywords_string)
# 绘制图像并显示
plt.figure()
# interpolation参数,此参数显示了不同图像之间的插值方式
# https://matplotlib.org/stable/gallery/images_contours_and_fields/interpolation_methods.html
plt.imshow(wordcloud, interpolation="bilinear")
# 关闭坐标轴
plt.axis("off")
plt.show()
# 设置显示风格
plt.style.use('fivethirtyeight')
train_data = pd.read_csv("./data/comments.csv", sep=",")
train_data["review"] = '"'+train_data["review"].astype(str)+'"'
# 获得训练集上正样本
p_train_data = train_data[train_data["label"]==1]["review"]
# 对正样本的每个句子的形容词
train_p_a_vocab = chain(*map(lambda x: get_a_list(x), p_train_data))
# 获得训练集上负样本
n_train_data = train_data[train_data["label"]==0]["review"]
# 获取负样本的每个句子的形容词
train_n_a_vocab = chain(*map(lambda x: get_a_list(x), n_train_data))
# 调用绘制词云函数
get_word_cloud(train_p_a_vocab)
get_word_cloud(train_n_a_vocab)


7. 文本特征处理
文本特征处理包括为语料添加具有普适性的文本特征, 如:n-gram特征, 以及对加入特征之后的文本语料进行必要的处理, 如: 长度规范. 这些特征处理工作能够有效的将重要的文本特征加入模型训练中, 增强模型评估指标。
常见的文本特征处理方法:添加n-gram特征、文本长度规范
7.1 n-gram特征
给定一段文本序列, 其中n个词或字的相邻共现特征即n-gram特征, 常用的n-gram特征是bi-gram和tri-gram特征, 分别对应n为2和3。
例:
假设给定分词列表: ["是谁", "敲动", "我心"],对应的数值映射列表为: [1, 34, 21]
我们可以认为数值映射列表中的每个数字是词汇特征.
除此之外, 我们还可以把"是谁"和"敲动"两个词共同出现且相邻也作为一种特征加入到序列列表中,
假设1000就代表"是谁"和"敲动"共同出现且相邻
此时数值映射列表就变成了包含2-gram特征的特征列表: [1, 34, 21, 1000]
这里的"是谁"和"敲动"共同出现且相邻就是bi-gram特征中的一个.
"敲动"和"我心"也是共现且相邻的两个词汇, 因此它们也是bi-gram特征.
假设1001代表"敲动"和"我心"共同出现且相邻
那么, 最后原始的数值映射列表 [1, 34, 21] 添加了bi-gram特征之后就变成了 [1, 34, 21, 1000, 1001]
# 一般n-gram中的n取2或者3, 这里取2为例
ngram_range = 2
def create_ngram_set(input_list):
# """
# description: 从数值列表中提取所有的n-gram特征
# :param input_list: 输入的数值列表, 可以看作是词汇映射后的列表,
# 里面每个数字的取值范围为[1, 25000]
# :return: n-gram特征组成的集合
#
# eg:
# >>> create_ngram_set([1, 4, 9, 4, 1, 4])
# {(4, 9), (4, 1), (1, 4), (9, 4)}
# """
return set(zip(*[input_list[i:] for i in range(ngram_range)]))
input_list = [1, 3, 2, 1, 5, 3]
res = create_ngram_set(input_list)
print(res)
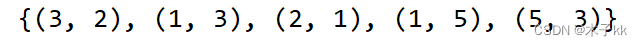
n-gram模型
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。 这些概率可以通过直接从语料中统计N个词同时出现的次数得到。
常用的是二元的Bi-Gram和三元的Tri-Gram。

ngram应用:https://zhuanlan.zhihu.com/p/32829048
N-gram特征的优缺点: N-gram特征的优点是简单易用,可以捕捉文本中的局部信息,对于文本分类、信息检索等任务效果较好;缺点是需要考虑N的取值,当N取值较大时,特征空间会变得非常庞大,可能会导致维数灾难。
N-gram特征的改进方法: 为了克服N-gram特征的缺点,可以采用一些改进方法,例如,使用tf-idf权重对N-gram进行加权,使用停用词过滤掉一些无用的N-gram,使用词干提取等方法对N-gram进行预处理。
7.2 文本长度规范
一般模型的输入需要等尺寸大小的矩阵, 因此在进入模型前需要对每条文本数值映射后的长度进行规范, 此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度, 对超长文本进行截断, 对不足文本进行补齐(一般使用数字0), 这个过程就是文本长度规范.
from keras.preprocessing import sequence
# cutlen根据数据分析中句子长度分布,覆盖90%左右语料的最短长度.
# 这里假定cutlen为10
cutlen = 10
def padding(x_train):
"""
description: 对输入文本张量进行长度规范
:param x_train: 文本的张量表示, 形如: [[1, 32, 32, 61], [2, 54, 21, 7, 19]]
:return: 进行截断补齐后的文本张量表示
"""
# 使用sequence.pad_sequences即可完成
return sequence.pad_sequences(x_train, cutlen)
# 假定x_train里面有两条文本, 一条长度大于10, 一天小于10
x_train = [[1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1],
[2, 32, 1, 23, 1]]
res = padding(x_train)
print(res)

7.3 文本数据增强
回译数据增强目前是文本数据增强方面效果较好的增强方法, 一般基于google翻译接口, 将文本数据翻译成另外一种语言(一般选择小语种),之后再翻译回原语言, 即可认为得到与与原语料同标签的新语料, 新语料加入到原数据集中即可认为是对原数据集数据增强.
回译数据增强优势:操作简便, 获得新语料质量高.
回译数据增强存在的问题:在短文本回译过程中, 新语料与原语料可能存在很高的重复率, 并不能有效增大样本的特征空间.
高重复率解决办法::进行连续的多语言翻译, 如: 中文-->韩文-->日语-->英文-->中文, 根据经验, 最多只采用3次连续翻译, 更多的翻译次数将产生效率低下, 语义失真等问题.
代码实现:由于google翻译接口不免费了,这里用的有道翻译接口。
import requests
import time
import random
import hashlib
def youdao_translate_advance(text, src_lang, to_lang):
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
headers = {
'User-Agent': user_agent,
'Referer': 'http://fanyi.youdao.com/',
'Origin': 'http://fanyi.youdao.com',
'X-Requested-With': 'XMLHttpRequest',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'fanyi.youdao.com',
'cookie': '_ntes_nnid=937f1c788f1e087cf91d616319dc536a,1564395185984; OUTFOX_SEARCH_USER_ID_NCOO=; OUTFOX_SEARCH_USER_ID=-10218418@11.136.67.24; JSESSIONID=; ___rl__test__cookies=1'
}
lts = str(round(time.time() * 1000))
salt = lts + str(random.randint(1, 10))
strange_str = 'n%A-rKaT5fb[Gy?;N5@Tj' # 'p09@Bn{h02_BIEe]$P^nG'
sign = hashlib.md5(('fanyideskweb' + text + salt + strange_str).encode('utf-8')).hexdigest()
bv = hashlib.md5(user_agent.encode('utf-8')).hexdigest()
data = {
'i': text,
'from': src_lang,
'to': to_lang,
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': salt, # 当前毫秒时间戳与10以内随机数字字符串的拼接
'sign': sign, # 'fanyideskweb' + text + salt + strange_str的md5值
'lts': lts, # 当前毫秒时间戳
'bv': bv, # 浏览器平台和版本信息的md5值
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_CLICKBUTTION',
}
response = requests.post(url=url, headers=headers, data=data)
res = response.json()['translateResult'][0][0]['tgt']
return res
p_sample1 = "酒店设施非常不错"
p_sample2 = "这家价格很便宜"
n_sample1 = "拖鞋都发霉了, 太差了"
n_sample2 = "电视不好用, 没有看到足球"
translations = []
for yuanwen in [p_sample1, p_sample2, n_sample1, n_sample2]:
translations.append(youdao_translate_advance(yuanwen,'zh-CHS', 'ko'))
print(translations)
cn_res = []
for yiwen in translations:
cn_res.append(youdao_translate_advance(yiwen, 'ko', 'zh-CHS',))
print(cn_res)

transpose(a,b,c):https://blog.csdn.net/liuqihang11/article/details/119777836
torch.cat: https://blog.csdn.net/qq_39709535/article/details/80803003

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)