前馈神经网络与反向传播算法(推导过程)
前馈神经网络与反向传播算法(推导过程)
1. 符号说明
nl<script type="math/tex" id="MathJax-Element-1">n_{l}</script> :表示网络的层数,第一层为输入层
sl<script type="math/tex" id="MathJax-Element-2">s_{l}</script> :表示第l层神经元个数
f(·) :表示神经元的激活函数
W(l)∈Rsl+1×sl<script type="math/tex" id="MathJax-Element-3">W^{(l)} \in R^{ s_{_{l+1}} \times s_{_{l}} }</script>:表示第l层到第l+1层的权重矩阵
b(l)∈Rsl+1<script type="math/tex" id="MathJax-Element-4">b^{(l)} \in R^{ s_{_{l+1}} }</script>:表示第l层到第l+1层的偏置
z(l)∈Rsl<script type="math/tex" id="MathJax-Element-5">z^{(l)} \in R^{ s_{_{l}} }</script> :表示第l层的输入,其中zi(l)<script type="math/tex" id="MathJax-Element-6">{z_{i}}^{(l)}</script>为第l层第i个神经元的输入
a(l)∈Rsl<script type="math/tex" id="MathJax-Element-7">a^{(l)} \in R^{ s_{_{l}} }</script> :表示第l层的输出,其中ai(l)<script type="math/tex" id="MathJax-Element-8">{a_{i}}^{(l)}</script>为第l层第i个神经元d的输出
2. 向前传播
下图直观解释了层神经网络模型向前传播的一个例子,圆圈表示神经网络的输入,“+1”的圆圈被称为偏置节点。神经网络最左边的一层叫做输入层,最右的一层叫做输出层。中间所有节点组成的一层叫做隐藏层。
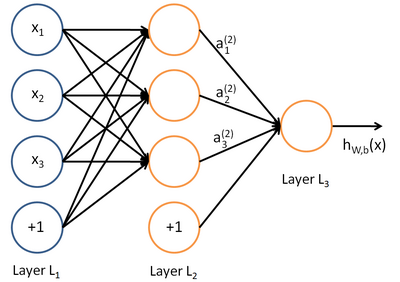
每个神经元的表达式如下:
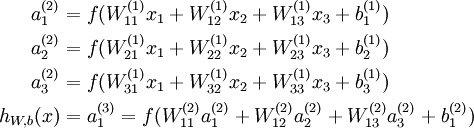
前向传播的步骤如下:
z(l)=W(l−1)a(l−1)+b(l−1)a(l)=f(z(l))⎫⎭⎬⎪⎪⇒z(l)=W(l−1)f(z(l−1))+b(l−1)<script type="math/tex" id="MathJax-Element-9">\left.\begin{matrix}\\z^{(l)}= W^{(l-1)} a^{(l-1)}+b^{(l-1)}\\a^{(l)} = f(z^{(l)})\end{matrix}\right\} \Rightarrow z^{(l)} = W^{(l-1)} f(z^{(l-1)})+b^{(l-1)}</script>
3. 反向传播算法推导过程
(1)目标函数
给定一个包含m个样本的训练集,目标函数为:
J(W,b)=1m∑mi=1J(W,b;x(i),y(i))+λ2∥W∥22<script type="math/tex" id="MathJax-Element-10">J(W,b) =\frac{1}{m} \sum_{i=1}^{m}J(W,b;x^{(i)},y^{(i)})+\frac{\lambda }{2}\parallel W\parallel_{2}^{2}</script>
=1m∑mi=1(12∥h(x(i))−y(i))∥22)+λ2∑nl−1l=1∑sli=1∑sl+1j=1(Wji(l))2<script type="math/tex" id="MathJax-Element-11"> \qquad\quad\ =\frac{1}{m} \sum_{i=1}^{m}(\frac{1}{2}\parallel h(x^{(i)})-y^{(i)})\parallel_{2}^{2})+\frac{\lambda }{2} \sum_{l=1}^{n_{_{l}}-1} \sum_{i=1}^{s_{_{l}}} \sum_{j=1}^{s_{_{l+1}}} ( {W_{ji}}^{(l)} ) ^{2} </script>
采用梯度下降方法最小化J(W,b), 参数更新方式如下:
Wnew(l)=W(l)−α⋅∂J(W,b))∂W(l)<script type="math/tex" id="MathJax-Element-12">{W_{new}}^{(l)}=W^{(l)}-\alpha \cdot \frac{\partial J(W,b))}{\partial W^{(l)}}</script>
=W(l)−α∑mi=1∂J(W,b;x(i),y(i))∂W(l)−λW<script type="math/tex" id="MathJax-Element-13"> \qquad\quad\ =W^{(l)}-\alpha\sum_{i=1}^{m}\frac{\partial J(W,b;x^{(i)},y^{(i)})}{\partial W^{(l)}}-\lambda W</script>
bnew(l)=b(l)−α⋅∂J(W,b))∂b(l)<script type="math/tex" id="MathJax-Element-14">{b_{new}}^{(l)}=b^{(l)}-\alpha \cdot \frac{\partial J(W,b))}{\partial b^{(l)}}</script>
=b(l)−α∑mi=1∂J(W,b;x(i),y(i))∂b(l)<script type="math/tex" id="MathJax-Element-15">\qquad\ \ \ =b^{(l)}-\alpha\sum_{i=1}^{m}\frac{\partial J(W,b;x^{(i)},y^{(i)})}{\partial b^{(l)}}</script>
因此,参数更新的关键在于计算 ∂J(W,b;x,y)∂W(l)<script type="math/tex" id="MathJax-Element-16">\frac{\partial J(W,b;x,y)}{\partial W^{(l)}}</script>和∂J(W,b;x,y)∂b(l)<script type="math/tex" id="MathJax-Element-17">\frac{\partial J(W,b;x,y)}{\partial b^{(l)}}</script>
(2)计算∂J(W,b;x,y)∂W(l)<script type="math/tex" id="MathJax-Element-490">\frac{\partial J(W,b;x,y)}{\partial W^{(l)}}</script>
根据链式法则可得:
∂J(W,b;x,y)∂W(l)=(∂J(W,b;x,y)∂z(l+1))T∂z(l+1)∂W(l)<script type="math/tex" id="MathJax-Element-491">\frac{\partial J(W,b;x,y)}{\partial W^{(l)}}=(\frac{\partial J(W,b;x,y)}{\partial z^{(l+1)}})^\mathrm{ T } \frac{\partial z^{(l+1)}}{\partial W^{(l)}}</script>
其中,∂z(l+1)∂W(l)=∂[W(l)⋅a(l)+b(l)]∂W(l)=a(l)<script type="math/tex" id="MathJax-Element-492">\frac{\partial z^{(l+1)}}{\partial W^{(l)}}=\frac{\partial [W^{(l)} \cdot a^{(l)}+b^{(l)}] }{\partial W^{(l)}}=a^{(l)} </script>
定义残差为: δ(l)=∂J(W,b;x,y)∂z(l)<script type="math/tex" id="MathJax-Element-493">\delta^{(l)} = \frac{\partial J(W,b;x,y)}{\partial z^{(l)}}</script>
对于输出层(第nl<script type="math/tex" id="MathJax-Element-494">n_{l}</script>层),残差的计算公式如下:(其中,f(z(nl))<script type="math/tex" id="MathJax-Element-495">f(z^{(n_{l})})</script>是按位计算的向量函数,因此其导数是对角矩阵)
δ(nl)=∂J(W,b;x,y)∂z(nl)<script type="math/tex" id="MathJax-Element-496">\delta^{(n_{l})} = \frac{\partial J(W,b;x,y)}{\partial z^{(n_{l})}}</script>
=∂12∥h(x)−y)∥22∂z(nl)<script type="math/tex" id="MathJax-Element-497">\quad\ \ \ = \frac{\partial \frac{1}{2} \parallel h(x)-y)\parallel_{2}^{2}}{\partial z^{(n_{l})}} </script>
=∂12∥f(z(nl))−y)∥22∂z(nl)<script type="math/tex" id="MathJax-Element-498">\quad\ \ \ = \frac{\partial \frac{1}{2} \parallel f(z^{(n_{l})})-y)\parallel_{2}^{2}}{\partial z^{(n_{l})}} </script>
=(a(nl)−y)⋅diag(f′(z(nl)))<script type="math/tex" id="MathJax-Element-499">\quad\ \ \ = (a^{(n_{l})} -y)\cdot diag(f^{'}(z^{(n_{l})}))</script>
=(a(nl)−y)⊙f′(z(nl))<script type="math/tex" id="MathJax-Element-500">\quad\ \ \ = (a^{(n_{l})} -y)\odot f^{'}(z^{(n_{l})})</script>
对于网络其它层,残差可通过如下递推公式计算:
δ(l)=∂J(W,b;x,y)∂z(l)<script type="math/tex" id="MathJax-Element-501">\delta^{(l)} = \frac{\partial J(W,b;x,y)}{\partial z^{(l)}}</script>
=∂a(l)∂z(l)∂z(l+1)∂a(l)∂J(W,b;x,y)∂z(l+1)<script type="math/tex" id="MathJax-Element-502">\quad\ \ = \frac{\partial a^{(l)} }{\partial z^{(l)}} \frac{\partial z^{(l+1)} }{\partial a^{(l)}} \frac{\partial J(W,b;x,y)}{\partial z^{(l+1)}}</script>
=∂f(z(l))∂z(l)⋅∂[W(l)a(l)+b(l)]∂a(l)⋅δ(l+1)<script type="math/tex" id="MathJax-Element-503">\quad\ \ = \frac{\partial f(z^{(l)}) }{\partial z^{(l)}} \cdot \frac{\partial [W^{(l)} a^{(l)}+b^{(l)}] }{\partial a^{(l)}} \cdot \delta^{(l+1)}</script>
=diag(f′(z(l)))⋅(W(l))T⋅δ(l+1)<script type="math/tex" id="MathJax-Element-504">\quad\ \ = diag(f^{'}(z^{(l)})) \cdot (W^{(l)} )^\mathrm{ T } \cdot \delta^{(l+1)}</script>
=f′(z(l))⊙(W(l))Tδ(l+1)<script type="math/tex" id="MathJax-Element-505">\quad\ \ =f^{'}(z^{(l)}) \odot (W^{(l)} )^\mathrm{ T } \delta^{(l+1)} </script>
(3)计算∂J(W,b;x,y)∂b(l)<script type="math/tex" id="MathJax-Element-33">\frac{\partial J(W,b;x,y)}{\partial b^{(l)}}</script>
与(2)计算过程同理
∂J(W,b;x,y)∂b(l)=∂z(l+1)∂b(l)∂J(W,b;x,y)∂z(l+1)<script type="math/tex" id="MathJax-Element-34">\frac{\partial J(W,b;x,y)}{\partial b^{(l)}}= \frac{\partial z^{(l+1)}}{\partial b^{(l)}} \frac{\partial J(W,b;x,y)}{\partial z^{(l+1)}}</script>
=∂[W(l)⋅a(l)+b(l)]∂b(l)δ(l+1)<script type="math/tex" id="MathJax-Element-35">\qquad\qquad \ = \frac{\partial [W^{(l)}\cdot a^{(l)}+b^{(l)}] }{\partial b^{(l)}} \delta^{(l+1)} </script>
=δ(l+1)<script type="math/tex" id="MathJax-Element-36">\qquad\qquad \ = \delta^{(l+1)} </script>
综上所述:
∂J(W,b;x,y)∂W(l)=(δ(l+1))Ta(l)<script type="math/tex" id="MathJax-Element-37">\frac{\partial J(W,b;x,y)}{\partial W^{(l)}}=(\delta^{(l+1)} )^\mathrm{ T }a^{(l)} </script>
∂J(W,b;x,y)∂b(l)=δ(l+1)<script type="math/tex" id="MathJax-Element-38">\frac{\partial J(W,b;x,y)}{\partial b^{(l)}}=\delta^{(l+1)}</script>
反向传播算法的含义是:第l 层的一个神经元的残差是所有与该神经元相连的第l+ 1 层的神经元的残差的权重和,然后在乘上该神经元激活函数的梯度。
4. 反向传播算法流程
借网上一张图,反向传播算法可表示为以下几个步骤:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)