NASNet 详解
NAS 的计算代价很大,作者用于ImageNet的NAS 简称为NASNet,1 NASNet 详解1.1 NASNet 控制器在NASNet 中,完整的网络的结构还是需要手动设计的,NASNet学习的是完整网络中被堆叠,被重复使用的网络单元,为了方便将网络迁移到不同的数据集上,我们需要学习两种类型的网络块:(1)Normal cell: 输出Feature Map 和输入Feat...
NAS 的计算代价很大,作者用于ImageNet的NAS 简称为NASNet,
1 NASNet 详解
1.1 NASNet 控制器
在NASNet 中,完整的网络的结构还是需要手动设计的,NASNet学习的是完整网络中被堆叠,被重复使用的网络单元,为了方便将网络迁移到不同的数据集上,我们需要学习两种类型的网络块:
(1)Normal cell: 输出Feature Map 和输入Feature Map 的尺寸相同;(2)Reduction Cell :输出Feature Map 对输入Feature Mao 进行了一次降采样,在Reduction cell 中,对使用Input Feature 作为输入的操作(卷积或池化)会默认步长为2.
NASNet 的控制器的结构如图1所示,每个网络单元由B的网络块(block)组成,在实验中B=5,。每个块的具体形式如图1右侧部分,每个块有并行的两个卷积组成,它们会由控制器决定选择哪些Feature Map 作为输入(灰色部分)以及使用哪些运算(黄色部分)来计算输入的Feature Map。 最后它们会由控制器决定如何合并这两个Feature Map。
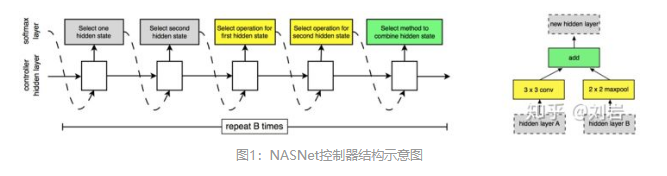
更精确的讲,NASNet 网络单元的计算分为5步:
1 从第hi-1 个Feature Map 或者第 hi 个Feature Map 或者之前已经生成的网络块中选择一个Feature Map 作为hidden layer A的输入,图2 是学习到的网络单元,从中可以看到三种不同输入Feature Map 的情况。
2 采样和1 类似的方法为hidden Layer B 选择一个输入;
3 为1 的Feature Map 选择一个运算;
4 为2 的Feature Map 选择一个元素;
5 选择一个合并3,4 得到的Feature Map 的运算。
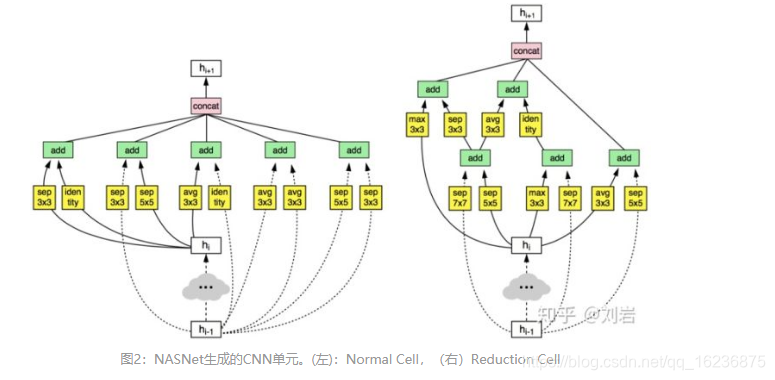
在3,4 中我们可以选择的操作有:
直接映射:
1*1 卷积;3*3 卷积;3*3 深度可分离卷积;3*3空洞卷积;3*3 平均池化;3*3 最大池化;1*3卷积+3*1 卷积;5*5 深度可分离卷积;5*5最大池化;7*7...
最后所有生成的Feature Map 通过拼接操作合成一个完整的Feature Map。
为了能让控制器同时预测Normal cell 和Reduction cell,RNN 会有2*5*B 个输出,其中前5*B个输出预测Normal cell的B个块(如图1 每个块有5个输出),后5*B个输出预测Reduction cell 的B个块,RNN 使用的是单层100个隐层节点的LSTM。
1.2 NASNet 强化学习
NASNet的强化学习思路和NAS 相同,有几个技术细节需要说明:
1 NASNet进行迁移学习时使用的优化策略是Proximal Policy Optimization (PPO)
2 作者尝试了均匀分布的搜索策略,效果略差于策略搜索。
1.3 Scheduled Drop Path
在优化类似于Inception 的多分支结构时,以一定概率随机丢弃掉部分分支是避免过拟合的一种非常有效的策略,例如DropPath[4]。 但是DropPath 对NASNet 不是非常有效。 在NASNet 的Scheduled Drop Path 中,丢弃的概率会随着训练时间的增加而线性增加。这么做的动机很好理解:训练的次数越多,模型越容易过拟合,DropPath的避免过拟合的作用才能发挥的越有效。
1.4 其他超参
在NASNet 中,强化学习的搜索空间大大减小,很多超参数已经由算法写死或者人为调整,这里介绍一下NASNet 需要人为深圳的超参数。
1 激活函数统一使用ReLU,实验结果表明ELU nonlinearity 效果略优于ReLU。
2 全部使用Valid 卷积,Padding 值由卷积核大小决定。
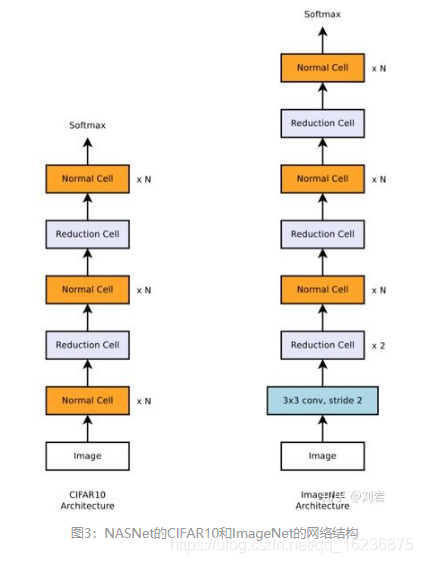
3 Reduction cell的Feature Map的数量需要乘以2,Normal Cell 数量不变,初始数量人为设定,一般来说数量越多,计算越慢,效果越好。
4 Normal cell 的重复次数(图3中的N)人为设定;
5 深度可分离娟娟在深度卷积和单位卷积中间不使用BN 或ReLU。
6 使用深度可分离卷积时,该算法执行两次;
7 所有卷积遵循ReLU->卷积->BN 的计算顺序;
8 为了保持Feature Map的数量的一致性,必要的时候添加1*1 卷积。
堆叠cell得到的CIFAR_10 和ImageNet的实验结果如图3所示。
总结
NASNet 最大贡献是解决了NAS 无法应用到大数据集上的问题,它使用的策略是先在小数据集上学习一个网络单元,然后在大数据集上堆叠更多的单元的形式来完成模型迁移的。
NASNet 已经不再是一个dataset interest的网络了,因为其中大量的参数都是人为设定的,网络的搜索空间更倾向于密集连接的方式。这种人为设定参数的一个正面影响就是减小了强化学习的搜索空间,从而提高运算速度,在相同的硬件环境下,NASNet 的速度要比NAS 快7倍。
NASNet 的网络单元本质上是一个更复杂的Inception,可以通过堆叠,网络单元的形式将其迁移到任意分类任务,乃至任意类型的任务中。论文中使用NASNet 进行的物体检测也要优于其他网络。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)