LangGraph 入门
LangGraph是LangChain团队推出的状态化工作流框架,专为构建复杂多步骤的AI代理和工作流设计。其核心是将AI应用逻辑抽象为图结构,支持循环、分支和状态持久化,适用于需要长期记忆和多轮决策的场景。与LangChain相比,LangGraph更专注于流程管理,两者常结合使用。
文章目录
1.LangGraph
LangGraph 是 LangChain 团队在 2023 年底推出的状态化工作流框架,专门用于构建复杂、多步骤、有状态的Agent和工作流。它的核心设计理念是将 AI 应用的逻辑抽象为图结构,支持循环、条件分支、状态持久化等复杂流程,特别适合构建需要长期记忆、多轮决策、工具调用迭代的智能代理(如客服机器人、代码助手、自动化工作流等)。
2.核心组件
LangGraph 的核心是图结构,主要组件包括:
-
Node(节点):图中的基本执行单元,负责处理具体任务,每个节点接收State作为输入,处理后返回新的状态,比如一个节点调用 LLM生成回答,另一个节点调用工具处理数据。
-
Edge(边):定义节点之间的连接关系,决定执行的流程走向,支持条件分支和循环。
-
State(状态):图的数据容器,存储流程中需要传递的信息,设计为不可变数据结构,每次更新都会生成新状态,确保可追溯性。
LangGraph 与 LangChain 的区别

总结
-
LangChain 是全能工具链,适合快速连接 LLM 与外部资源,构建基础 LLM 应用;
-
LangGraph 是流程引擎,专注于复杂工作流和状态化代理,适合需要多步骤决策、循环调用、长期记忆的场景。
两者通常结合使用,用 LangChain 处理数据加载、工具定义、LLM 调用,用 LangGraph 管理这些组件的执行流程,构建更强大的 AI 应用。
3.构建聊天Agent智能体
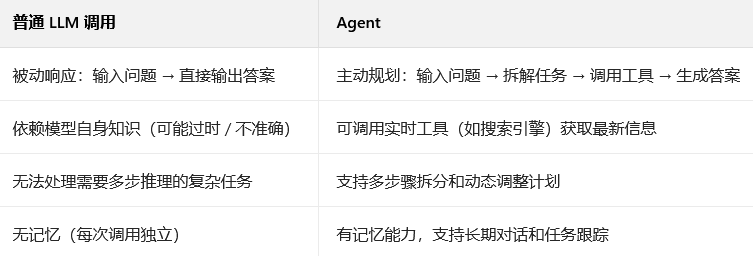
Agent 是指能够自主决策、规划行动、调用工具,并通过与用户交互完成复杂任务的智能系统。它的核心特点是自主性—— 不需要人类逐步指导,而是通过自身的推理能力解决问题。
Agent 与普通 LLM 调用的区别
LangChain访问大模型
from langchain_community.chat_models import ChatTongyi
llm = ChatTongyi(
model="qwen-plus",
api_key="API_KEY",
)
llm_result = llm.invoke("你是谁,能帮我解决什么问题")
print(llm_result.content)

LangGraph访问大模型
from langchain_community.chat_models import ChatTongyi
from langgraph.prebuilt import create_react_agent
llm = ChatTongyi(
model="qwen-plus",
api_key="API_KEY",
)
agent = create_react_agent(
model=llm,
tools=[],
prompt="You are a helpful assistant",
)
#agent.invoke({"messages":[{"role":"user","content":"你是谁?能帮我解决什么问题?"}]})
for chunk in agent.stream(
{"messages":[{"role":"user","content":"你是谁?能帮我解决什么问题?"}]},
stream_mode="updates"
):
print(chunk)
print("\n")

流式输出的stream_mode有以下几种选项:
- updates : 流式输出每个⼯具调⽤的每个步骤。
- messages: 流式输出⼤语⾔模型回复的Token。
- values: ⼀次拿到所有的chunk。默认值。
- custom : ⾃定义输出。主要是可以在⼯具内部使⽤get_stream_writer获取输⼊流,添加⾃定义的内容。
4.Tools 工具调用
Tools 工具机制是指让模型能够调用外部工具(如 API、数据库、搜索引擎等) 来扩展自身能力的技术方案,它解决了 LLM 自身存在的知识滞后、计算能力有限、无法实时交互等问题,让模型从纯文本生成升级为能执行具体操作的实用系统。
执行流程: “用户提问→模型决策→工具调用→结果处理→生成回答”。
from datetime import datetime
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
API_SECRET_KEY = "API_KEY"
BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
def get_current_date():
"""获取今天日期"""
return datetime.today().strftime("%Y-%m-%d")
# 初始化模型
llm = ChatOpenAI(
model='qwen-plus',
api_key=API_SECRET_KEY,
base_url=BASE_URL,
temperature=0
)
# 创建代理
agent = create_react_agent(
model=llm,
tools=[get_current_date],
prompt="You are a help assistant"
)
agent_result = agent.invoke({"messages":[{"role":"user","content":"今天是几月几号"}]})
print("代理调用结果:")
print(agent_result["messages"][-1].content)

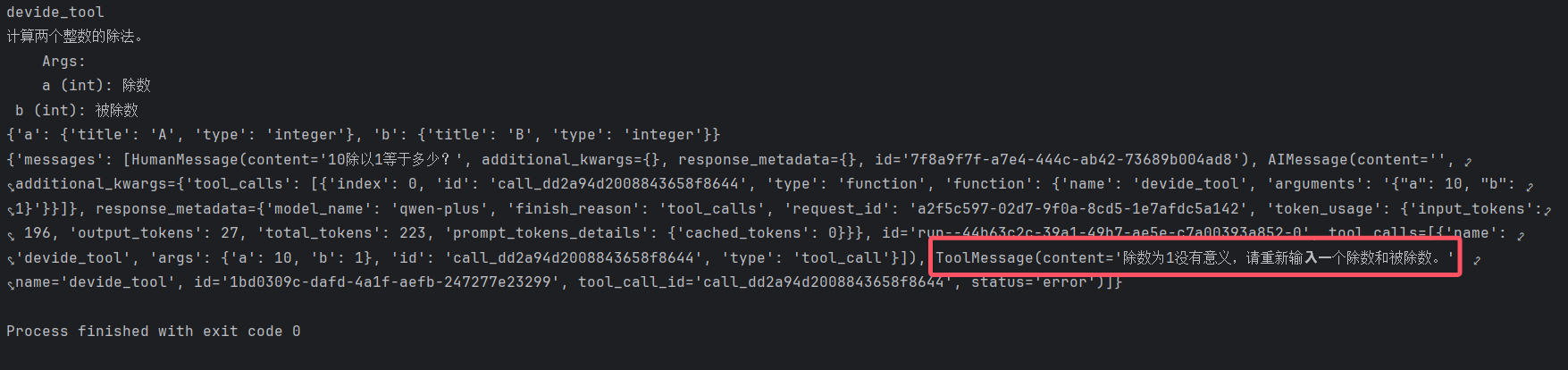
如果⼯具执⾏时出错了,LangGraph也提供了主动处理异常信息的能⼒。
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode, create_react_agent
# 定义⼯具 return_direct=True 表示直接返回⼯具的结果
@tool("devide_tool",return_direct=True)
def devide(a : int,b : int) -> float:
"""计算两个整数的除法。
Args:
a (int): 除数
b (int): 被除数"""
# ⾃定义错误
if b == 1:
raise ValueError("除数不能为1")
return a/b
print(devide.name)
print(devide.description)
print(devide.args)
# 定义⼯具调⽤错误处理函数
def handle_tool_error(error: Exception) -> str:
"""处理⼯具调⽤错误。
Args:
error (Exception): ⼯具调⽤错误"""
if isinstance(error, ValueError):
return "除数为1没有意义,请重新输⼊⼀个除数和被除数。"
elif isinstance(error, ZeroDivisionError):
return "除数不能为0,请重新输⼊⼀个除数和被除数。"
return f"⼯具调⽤错误:{error}"
tool_node = ToolNode(
[devide],
handle_tool_errors=handle_tool_error
)
llm = ChatTongyi(
model="qwen-plus",
api_key="API_KEY",
)
agent_with_error_handler = create_react_agent(
model=llm,
tools=tool_node
)
result = agent_with_error_handler.invoke({"messages":[{"role":"user","content":"10除以1等于多少?"}]})
print(result)
5.消息记忆
如下对话,需要将⼤模型的交互信息进⾏保存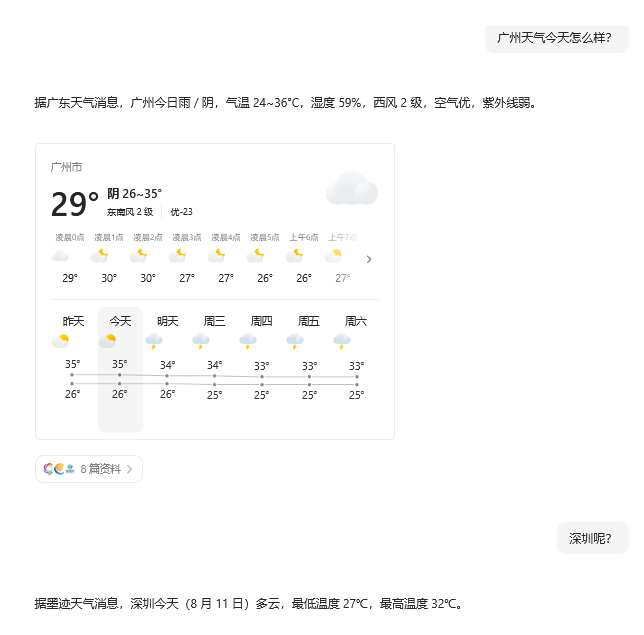
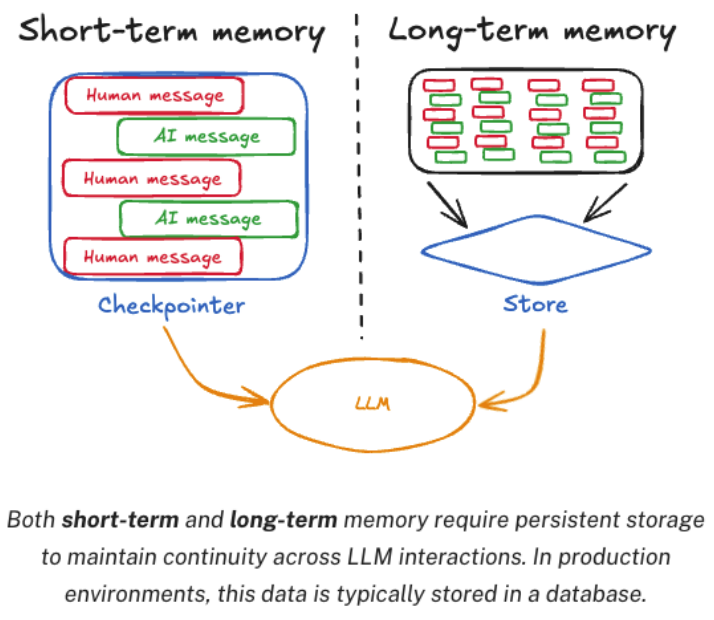
LangGraph 将 Agent 的记忆系统划分为短期记忆(Checkpoint) 和长期记忆(Store)
- 短期记忆:记录 Agent 在单次对话或任务执行过程中的实时状态,确保流程中断后可恢复,或支持多轮交互中的上下文连贯性。
- 长期记忆:独立于单次任务,长期保存用户级或应用级的通用信息,供所有对话共享复用。
5.1 短期记忆
LangGraph的Agent中只需要指定checkpointer属性,就可以实现短期记忆,在使⽤checkpointer时,需要创建⼀个单独的thread_id来区分不同的对话。
from langchain_community.chat_models import ChatTongyi
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.prebuilt import create_react_agent
checkpointer = InMemorySaver()
def get_weather(city: str) -> str:
"""获取某个城市的天⽓"""
return f"城市:{city},天⽓⼀直都是晴天!"
llm = ChatTongyi(
model="qwen-plus",
api_key="API_KEY",
)
agent = create_react_agent(
model=llm,
tools=[get_weather],
checkpointer=checkpointer
)
config = {
"configurable": {
"thread_id": "1"
}
}
gz_response = agent.invoke(
{"messages": [{"role": "user", "content": "广州天⽓今天怎么样?"}]},
config
)
print(gz_response)
# Continue the conversation using the same thread_id
bj_response = agent.invoke(
{"messages": [{"role": "user", "content": "北京呢?"}]},
config
)
print(bj_response)
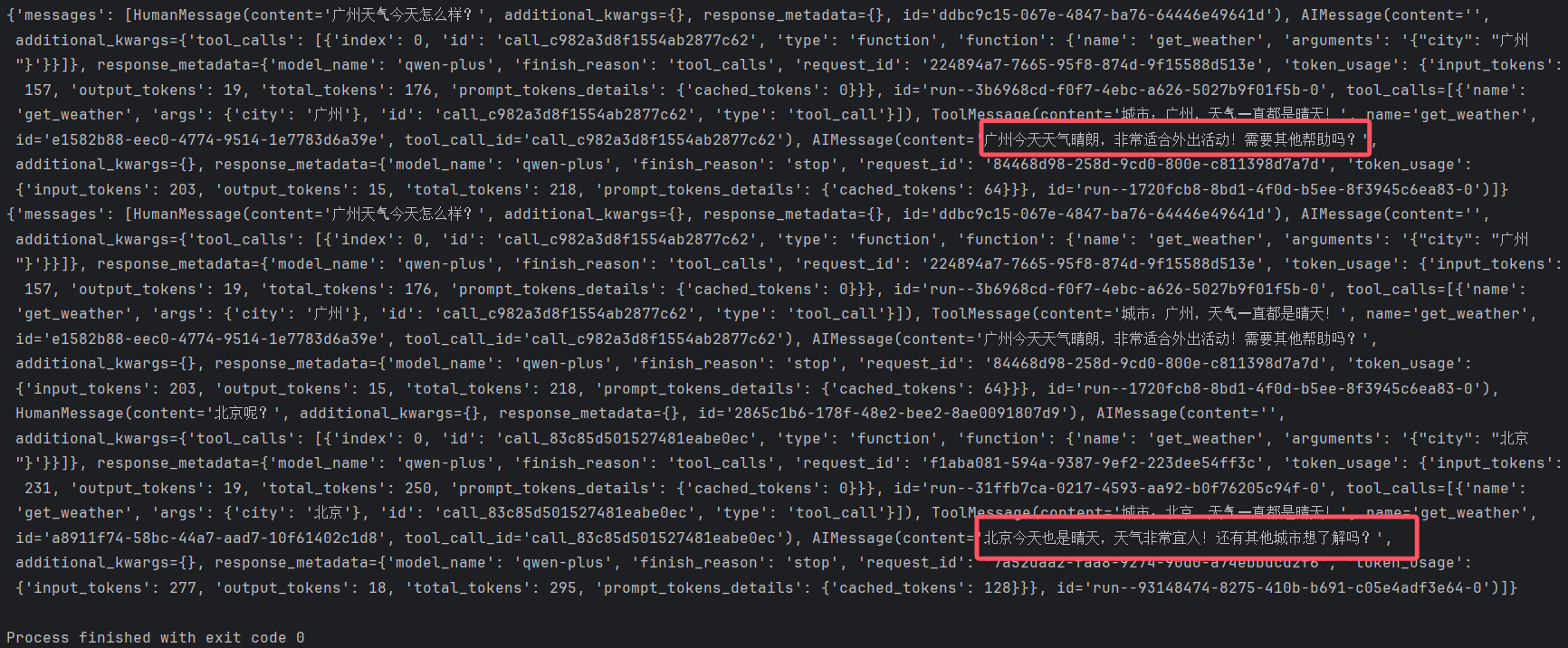
短期记忆的数据保存在内存中,当程序结束后就释放了,⽣产环境中建议保存到外部存储介质中,例如数据库、⽂件系统等。这样每次启动程序时,都可以从外部存储中加载历史记录。
LangGraph提供了⼀个pre_model_hook属性,可以在每次调⽤⼤模型之前触发,通过这个hook,就可以来定期管理短期记忆。LangGraph中管理短期记忆的⽅法主要有两种:
Summarization 总结:⽤⼤模型的⽅式,对短期记忆进⾏总结,然后再把总结的结果作为新的短期记忆。
Trimming 删除:直接把短期记忆中最旧的消息删除掉。
LangGraph提供了SummarizationNode函数,⽤于使⽤⼤模型的⽅式对短期记忆进⾏总结。
from langmem.short_term import SummarizationNode
from langchain_core.messages.utils import count_tokens_approximately
from langgraph.prebuilt import create_react_agent
from langgraph.prebuilt.chat_agent_executor import AgentState
from langgraph.checkpoint.memory import InMemorySaver
from typing import Any
# 使⽤⼤模型对历史信息进⾏总结
summarization_node = SummarizationNode(
token_counter=count_tokens_approximately,
model=llm,
max_tokens=384,
max_summary_tokens=128,
output_messages_key="llm_input_messages",
)
class State(AgentState):
# 这个状态能够保存上⼀次总结的结果,这样可以防⽌每次调⽤⼤模型时,都要重新总结历史信息。
context: dict[str, Any]
checkpointer = InMemorySaver()
agent = create_react_agent(
model=llm,
tools=tools,
pre_model_hook=summarization_node,
state_schema=State,
checkpointer=checkpointer,
)
trim_messages函数,⽤于定期清理短期记忆。
from langchain_core.messages.utils import (
trim_messages,
count_tokens_approximately
)
from langgraph.prebuilt import create_react_agent
def pre_model_hook(state):
trimmed_messages = trim_messages(
state["messages"],
strategy="last",
token_counter=count_tokens_approximately,
max_tokens=384,
start_on="human",
end_on=("human", "tool"),
)
return {"llm_input_messages": trimmed_messages}
checkpointer = InMemorySaver()
agent = create_react_agent(
model=llm,
tools=[],
pre_model_hook=pre_model_hook,
checkpointer=checkpointer,
)
LangGraph还提供了状态管理机制,⽤于保存处理过程中的中间结果。
from typing import Annotated
from langchain_community.chat_models import ChatTongyi
from langgraph.prebuilt import InjectedState, create_react_agent
from langgraph.prebuilt.chat_agent_executor import AgentState
from langchain_core.tools import tool
class CustomState(AgentState):
user_id: str
@tool(return_direct=True)
def get_user_info(
state: Annotated[CustomState, InjectedState]
) -> str:
"""查询⽤户信息."""
user_id = state["user_id"]
return "user_123⽤户的姓名:czl。" if user_id == "user_123" else "未知⽤户"
llm = ChatTongyi(
model="qwen-plus",
api_key="API_KEY",
)
agent = create_react_agent(
model=llm,
tools=[get_user_info],
state_schema=CustomState,
)
res =agent.invoke({
"messages": "查询⽤户信息",
"user_id": "user_123"
})
print(res)

5.2 长期记忆
长期记忆是通过Agent的store属性指定⼀个 实现类,与短期记忆的区别在于,短期记忆通thread_id来区分不同的对话,⽽⻓期记忆通过namespace来区分不同的命名空间。
from langchain_community.chat_models import ChatTongyi
from langchain_core.runnables import RunnableConfig
from langgraph.config import get_store
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStore
from langchain_core.tools import tool
# 定义⻓期存储
store = InMemoryStore()
# users是命名空间,user_123是key,后⾯的JSON数据是value
store.put(
("users",),
"user_123",
{
"name": "zhangsan",
"age": "99",
}
)
#定义⼯具
@tool(return_direct=True)
def get_user_info(config: RunnableConfig) -> str:
"""查找⽤户信息"""
store = get_store()
# 获取配置中的⽤户ID
user_id = config["configurable"].get("user_id")
user_info = store.get(("users",), user_id)
return str(user_info.value) if user_info else "Unknown user"
llm = ChatTongyi(
model="qwen-plus",
api_key="API_KEY",
)
agent = create_react_agent(
model=llm,
tools=[get_user_info],
store=store
)
res=agent.invoke(
{"messages": [{"role": "user", "content": "查找⽤户信息"}]},
config={"configurable": {"user_id": "user_123"}}
)
print(res)

6.Human-in-the-loop⼈类监督
在 Agent 的运行过程中,存在一个关键问题:虽然 Agent 可以集成各类Tools,但是否调用工具的决策完全由 Agent 自主判断,这可能导致 Agent 在处理某些问题时出现误判,例如不必要地调用工具或遗漏需要调用工具的场景,为解决这一问题,LangGraph 设计了 Human-in-the-loop 机制,在 Agent 执行工具调用的环节中,允许人类进行监督干预。具体来说,这需要暂停当前任务的执行流程,等待用户确认或输入指令后,再恢复任务的继续运行。
这种设计通过引入人类判断,有效弥补了 Agent 自主决策的局限性,提升了复杂场景下任务执行的准确性。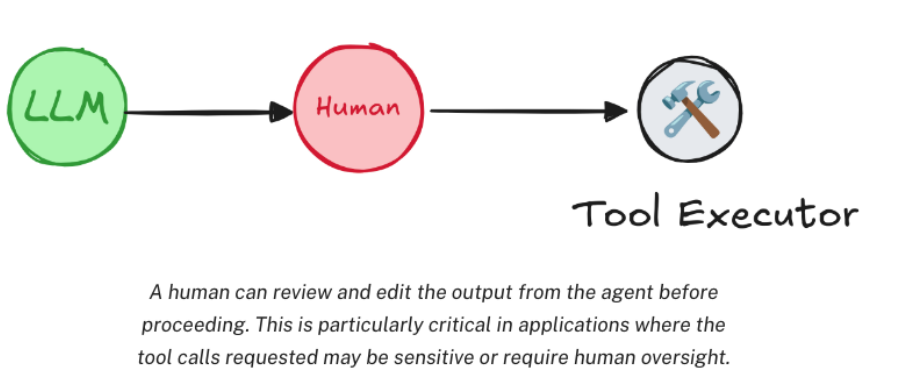
LangGraph提供了interruput()⽅法添加⼈类监督。监督时需要中断当前任务,所以通常是和stream流式⽅法配合使⽤。
from langchain_community.chat_models import ChatTongyi
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt, Command
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
# 定义需要人类监督的工具
@tool(return_direct=True)
def book_hotel(hotel_name: str):
# 触发中断,等待人类确认
response = interrupt(
f"正准备执⾏'book_hotel'⼯具预定宾馆,相关参数:{{'hotel_name': {hotel_name}}}. "
"请选择OK,表示同意,或者选择edit,提出补充意⻅."
)
# 根据人类反馈处理
if response["type"] == "OK":
pass
elif response["type"] == "edit":
hotel_name = response["args"]["hotel_name"]
else:
raise ValueError(f"未知的响应类型: {response['type']}")
return f"成功在 {hotel_name} 预定了⼀个房间."
# 初始化内存存储
checkpointer = InMemorySaver()
llm = ChatTongyi(
model="qwen-plus",
api_key="API_KEY",
)
agent = create_react_agent(
model=llm,
tools=[book_hotel],
checkpointer=checkpointer,
)
config = {
"configurable": {
"thread_id": "thread_123"
}
}
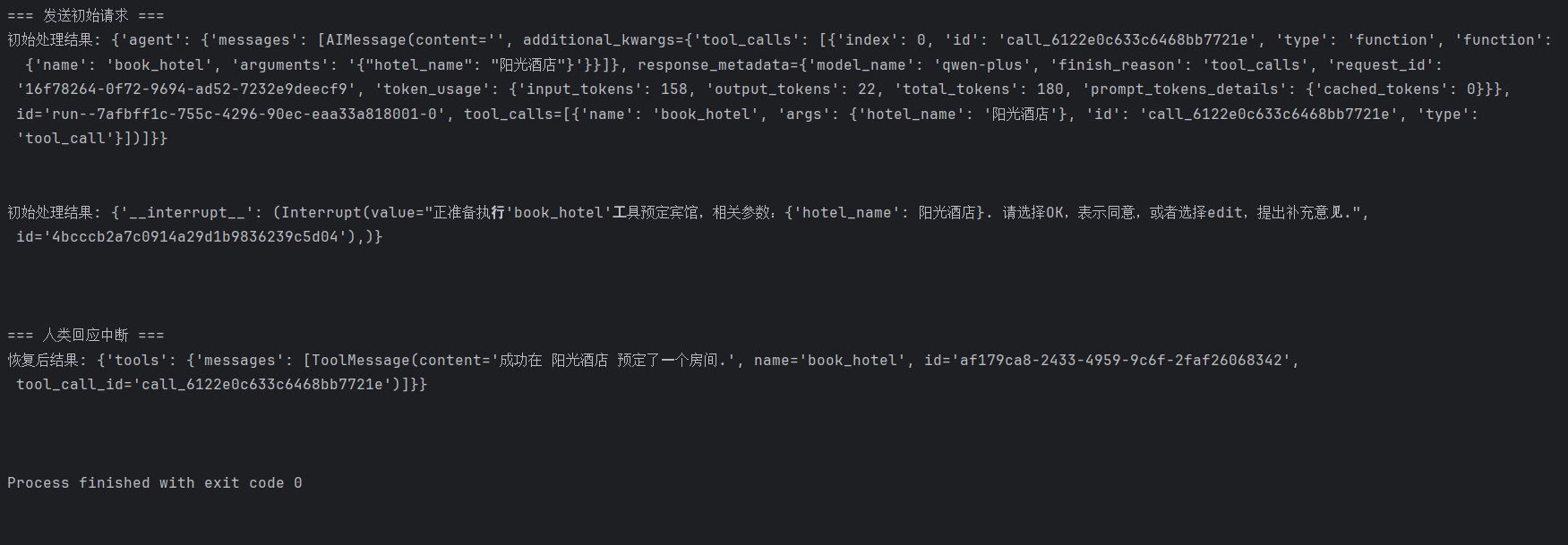
print("=== 发送初始请求 ===")
initial_input = {
"messages": [{"role": "user", "content": "帮我预订名为'阳光酒店'的房间"}]
}
# 流式处理初始请求,直到触发中断
for chunk in agent.stream(initial_input, config):
print("初始处理结果:", chunk)
if "tools" in chunk and chunk["tools"]["messages"]:
print("工具调用提示:", chunk["tools"]["messages"][-1].content)
print("\n")
# 回应中断
print("\n=== 人类回应中断 ===")
resume_input = Command(resume={"type": "OK"})
# 也可以选择修改参数:Command(resume={"type": "edit", "args": {"hotel_name": "9号宾馆"}})
# 流式处理中断后的恢复
for chunk in agent.stream(resume_input, config):
print("恢复后结果:", chunk)
if "messages" in chunk and chunk["messages"]:
print("最终回应:", chunk["messages"][-1].content)
print("\n")

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)