BERT原理-Pre-training of Deep Bidirectional Transformers for Language Understanding
上图就是bert利用了transforemr的编码器结构,从最底层的结构可以看出,E2为原始的单词输入,最中输出的的E2对应的embedding向量T2其实已经综合考虑了上下文信息,因为在神经网络(编码器)内部,信息是交叉,而且特别的是,这个编码器结构恰好实现了和ELMo一样的效果,既能看到单词左边的信息,也能看到单词右边的信息,这就是自注意力的好处。官方虽然没说,但是官方的图展示了,句子的结尾其
前提背景
词向量化
词向量化是指利用向量来表征自然语言文本,也就是用一个或者是一组数据来表示自然语言,诸如用[0.1,0.23,3,45]来表示单词“hello”,如果这组数据足以准确表示这个单词,那么它对后续的NLP任务的准确性大有保证,如果这组数据本身就不准确,那么接下来的NLP任务大概率也不会准确。
在大多数的NLP任务中,甚至可以说是所有NLP的任务中,词向量化(embedding)是最基础也是最重要的一步,因为这是将文本数字化的第一步。
词向量化技术
上面介绍了词embedding技术这么重要,所以自然就有很多人一直在这方面进行努力,下面简单介绍几个主流的词向量化技术
- n-gram
n-gram技术的原理就是利用统计学原理来统计长度为n的短语的词频,通过简单统计学原理来预测下一个单词出现的概率,严格来说这种方法不涉及词embedding技术,而是可以直接完成NLP任务,只是需要实现保存一个很大的概率数据表。 - word2vec
word2vec是利用单词的共现原理来对单词进行向量化,关于word2vec的原理我在之前的文章中专门分享过一次(word2vec的原理和难点介绍(skip-gram,负采样、层次softmax),这种embedding的缺点在于是孤立的来对单词进行embedding化,直白的说就是每一个单词进行embedding的时候,并没有综合考虑上下文的信息。 - ELMo
ELMo利用的双向的lstm结构,它和word2vec的差别在于,它在整体的词embedding学习的时候,综合考虑了上下文的信息,诸如这句话
我吃西红柿
在学习“西”这个词的时候,双向的LSTM结构,会从左到右考虑“我吃”的信息,也会从右到左考虑“红柿”的信息,这样在学习的过程中就综合考虑上下文信息,能够更准确的学习得到“西”的embedding。
事实也证明ELMo的这种综合考虑上下文的embedding思路是对的,这也是后来bert的思路之一
4. OpenAI GPT
OpenAI可以说是开创性的提出了“预训练”的概念,它在第一代的GPT(GPT1 )中提出了GPT的训练大概分为两步:预训练和微调,在预训练阶段,是利用大量的未标记的文本来全量的训练GPT模型,使得能够学到词的embedding表示。而在微调阶段,则是通过我们实际要完成的任务的有标记的数据来对模型进行微调,使得模型只需要调整少量的数据就能完成实际的NLP任务。
这种两步走的方法(预训练+微调)也验证了其具有一定的效果,那为什么两步走为什么会有效呢?其实本质上就是验证了transformer这种多头注意力的结构在一定程度上具有知识迁移的能力,所谓知识迁移,其实就是预训练阶段我可以大量的进行学习,而到了微调阶段之所以只需要进行少量训练,就是因为预训练阶段的知识部分迁移了过来。这也是后来bert的思路之二
感慨一波:GPT提出来的时候其实轰动并不大,因为看起来它就只是一个transformer的decoder的简单堆叠,并没有太多的创新,但是谁又能想到,到了2023年,GPT4引领了AI时代的发展。
模型结构
那我们首先来总结一下上面讲到的两个重点:
- 模型要解决的任务
模型要解决的是词的embedding学习的问题; - 过往验证了有两个方法是相对比较有用的
2.1 像ELMo一样,综合考虑上下文信息,能够更好的学习词embedding;
2.2 像GPT一样,利用大量无标记文本来做预训练,可以得到词的通用embedding,而到了具体 的NLP任务上,只需要用少量的标记文本进行微调。这种两步走概念能够提高NLP任务的精度和工作量。也验证了transformer结构具有很好的知识迁移能力
| 技术 | 数据 | 目标 | 特点 |
|---|---|---|---|
| 预训练 | 大量无标记文本 | 得到通用词embedding | 训练需要大量数据和计算资源 |
| 微调 | 特定NLP任务的有标记文本 | 得到具体NLP任务的微调模型 | 训练只需要少量数据和计算资源 |
bert其实就是基于这一个目标和两个前提出发,提出来的模型,那我们接下来就看如何通过上面学习的到这两点(ELMo的考虑上下文、GPT的预训练+微调)来解决词embeding的学习的。
综合考虑上下文
在ELMo中,是通过双向LSTM来综合考虑词左右的上下文信息的,而在Bert中,则是利用了tranformer的编码器结构来完成上下文的捕捉。下面是从[Attention Is All You Need]这篇论文中截取的关于transformer的结构。
transformer主要是由编码器和解码器构成,而左侧的这一块就是transformer的编码器结构,这也是bert用到的结构,关于transformer的编码器和解码器的差别,其实就是多了一个掩码Mask结构,其他不做过多的讲解。而关于编码器部分,主要大框架是基于残差结构设计,内部又使用了一个前馈神经网络和一个多头自注意力块,而正是这个自注意力机制,实现了对上下文信息的综合考虑,这里不会展开关于自注意力的讲解,强烈建议在学习bert之前先学习transformer,关于transformer的原理,我前面有一篇文章详细分析过:transformer原理-Attention Is All You Need,建议看一下。当然如果你不想学,也没关系,可以通过下面bert给出的这样图来做一个宏观的了解。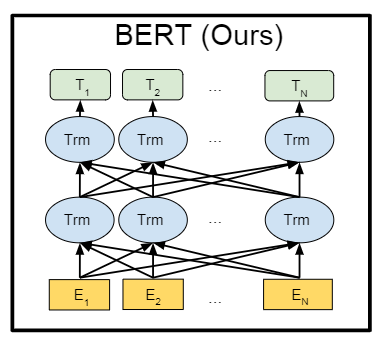
上图就是bert利用了transforemr的编码器结构,从最底层的结构可以看出,E2为原始的单词输入,最终输出的E2对应的embedding向量T2其实已经综合考虑了上下文信息,因为在神经网络(编码器)内部,信息是交叉,而且特别的是,这个编码器结构恰好实现了和ELMo一样的效果,既能看到单词左边的信息,也能看到单词右边的信息,这就是self-attention(自注意力)的好处。
这真的是太好了,本身我们就是觉得transformer结构具有良好的知识迁移能力,同时transformer的编码器结构又能够综合的考虑了上下文(既考虑单词前面的内容,又考虑了后面的内容)。那我们也就只有一个选择了,就是用transformer的编码器结构了。这就是为什么Bert选择transformer编码器作为主体的原因。
那讲到这里了,也只介绍了Bert是基于transformer的编码器组成的,到底细节是如何组成呢?Bert官方介绍,其实就是编码器的简单堆叠,一个接一个,就这么简单,官方发布了两个Bert模型,下面是是细节的参数
| 模型 | L(编码器数量) | 隐藏层大小 | 自注意力头数 | 总参数量 |
|---|---|---|---|---|
| Bert_base | 12 | 768 | 12 | 110M |
| Bert_large | 24 | 1024 | 16 | 340M |
至此关于Bert模型的结构就算是介绍完毕了。
数据结构
在上一小节中,介绍了模型是由transformer的编码器结构组成的。既然是选择了transformer结构,那自然就是要利用模型的知识迁移能力,所以大家也是遵从了GPT那一套:预训练+微调。
| 技术 | 数据 | 目标 | 特点 |
|---|---|---|---|
| 预训练 | 大量无标记文本 | 得到通用词embedding | 训练需要大量数据和计算资源 |
| 微调 | 特定NLP任务的有标记文本 | 得到具体NLP任务的微调模型 | 训练只需要少量数据和计算资源 |
微调阶段是为了解决各种各样实际的NLP任务的,诸如文本情感分类、句子包含关系、单选、多选等,这些不同的任务可以简单的归结为两类:单句子任务,多句子任务。为了能够让bert满足多种下游的任务,所以bert在预训练阶段的输入一定要兼顾单句子任务、同时也要兼顾多句子任务。
预训练
下图是官方给的关于Bert模型在预训练阶段的输入和输出的粗略结构,关于后面的讲解,可以参照这个图来理解。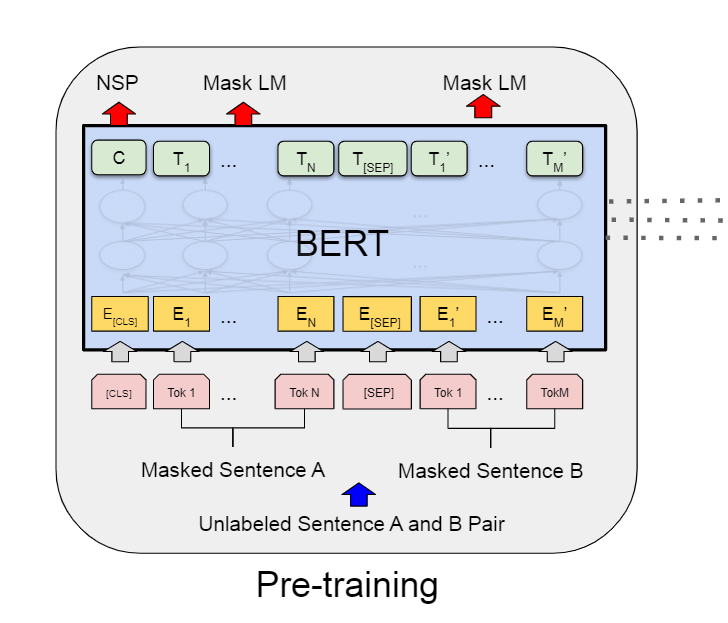
输入
上文说了bert在预训练阶段的输入一定要兼顾单句子任务、同时也要兼顾多句子任务。所以以这个为出发点,下面就是关于Bert数据输出的规则,我会逐个列出,并说明原因。
从多任务支持出发
- 对于bert的输入序列,这个序列可以是一段连续文本(可以是任意连续文本,也可以是一句话),也可以是多段连续文本。
- 多个连续文本之间用[SEP]分隔
- 序列开头必须是[CLS],其对应的bert的输出可以用来做分类
和上文说的一样,为了兼顾不同的下游任务(单句子任务、多句子任务),所以第1点这一点不用多解释,那既然支持多句子输入,那总得有个分隔符,这也就是第2点的原因。前两点是从输入层面来考虑多任务的情况。,但是输出呢?输出上一般是输入的token对应一个输出的token,那对于未来做token级别的任务,其实是没问题的,但是句子级别的任务呢?如果我们要做情感分类(二分类任务),到底要拿输出的哪一个token对应的embedding去做呢?所以这里在输入添加了[CLS],对应的输出也会有一个embedding,这个embedding通常就会用来代表整体的句子的信息,用来完成句子级别的任务,所以关于二分类任务,通常就会拿CLS对应的输出embedding去做。
从信息角度
- 添加一个Segment Embeddings ,用E表示,用来标记每一个token属于句子1,还是句子2,或则和是句子n。
- 在每一个句子中,需要标记每个token的位置编码
关于这两点,是从信息混乱角度来考虑的,首先,既然会有输入多句子的情况,那自然要做一个区分。在区分了两个句子之后,为了还要对每一个句子内部的每一个token做一个位置的编码呢?这其实是最原始的transformer就考虑的,原因在于transformer结构在加载一句话的时候是并行加载的,如果不做位置区分,就好比一揽子的数据,混乱的加载进去,但是句子里边的文字本身是有先后顺序的,所以才引入了位置编码。
基本上Bert官方关于数据输入的规定就这么多,但是其实还有一点它没说,那就是句子的结尾加什么?官方虽然没说,但是官方的图展示了,句子的结尾其实也是加的[SEP],至此所有的规则就讲完了,我先甩个图,然后把设计的所有点总结一下。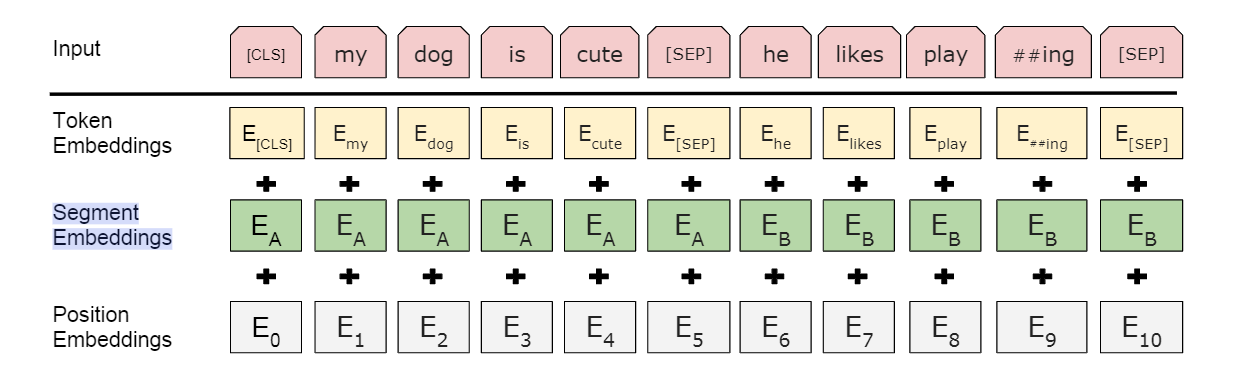
- 对于bert的输入序列,这个序列可以是一段连续文本(可以是任意连续文本,也可以是一句话),也可以是多段连续文本。
- 多个连续文本之间用[SEP]分隔
- 序列开头必须是[CLS],其对应的bert的输出可以用来做分类
- 添加一个Segment Embeddings ,用E表示,用来标记每一个token属于句子1,还是句子2,或则和是句子n。
- 在每一个句子中,需要标记每个token的位置编码
- 句子的结尾用[SEP]
输出
在输入部分已经讲解了输入的规则了,自然输出其实就是输入的每一个token对应的embedding。
模型训练
这个模型训练时预训练阶段的训练,在预训练阶段,主要考虑的是对未来具体任务的支持,首先自然首要的任务就是词embedding的学习,其次才是考虑多任务的支持(单句子任务、多句子任务)
所以预训练设计了两个预训练任务
任务1:Masked LM 掩码语言任务
因为在NLP任务中,训练得到准确的词embedding是最基础也是相对比较重要的,所以这个任务的目的就是为了得到一个准确的词embedding。
所以对于每一个输入的序列,选择随机屏蔽掉15%的token,用[MASK]替代,训练的过程就是预测这些掩码掉的MASK,训练完毕后,输出就是对应token的embedding了。这个任务也叫做掩码语言模型。
但是这由一个问题阿,这种暴力的替换为MASK之后,会有一个问题就是带入了MASK这个词的影响,而实际情况下,是不会有“MASK”这个词的输入的,所以为了解决这个问题。实际的情况下,对于要随机屏蔽的这15%的token,有80%的概率会被替换为[MASK],有10%的概率会被填充为任意的一个token,还有10%的概率是 保持原来的样子不变。那这样就最大限度的削弱了MASK本身的影响。
官方也给了一个例子如下
原始句子是
my dog is hairy
但是真实输入模型的句子如下
| 句子 | 概率 |
|---|---|
| my dog is [MASK] | 80% |
| my dog is apple | 10% |
| my dog is hairy | 10% |
任务2:Next Sentence Prediction (NSP) 下一个句子预测
这一步就是为了支持后来的多句子任务,所以在预训练的时候设计了这样的一个任务,在这个任务中,会选择50%的句子,将他们后面的句子打乱,用其他的句子替代,而50%的句子则保持不变。
通用给出官方的例子
| 输入(句子) | label | 概率 |
|---|---|---|
| [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] | IsNext | 50% |
| [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP] | IsNext | 50% |
本质上就是一个二分类,将组好的句子输入到bert模型,然后再CLS对应位置的embedding输出上做二分类。虽然没有直接的去做具体的NLP任务的训练,但是这种下一个句子的预测的预训练被证明了,其实已经学到了关于多句子的知识,这样到后来的微调部分其实就会发挥它的知识迁移的作用。
微调
微调部分其实就是涉及到了具体的NLP任务了。所以这里面涉及到的数据一般都是适合对应任务下的标记好的数据,数据搞定之后呢,就是模型,模型通常也不会用原始的bert模型,而是再bert的基础上添加不同的任务头去完成。后面实战部分会详细的讲讲具体的模型和数据组成,下面会按照官方给的几个图来粗略的介绍介绍
多分类任务
文本包含一般就是这一类的任务,就是预测这两个句子是不是包含关系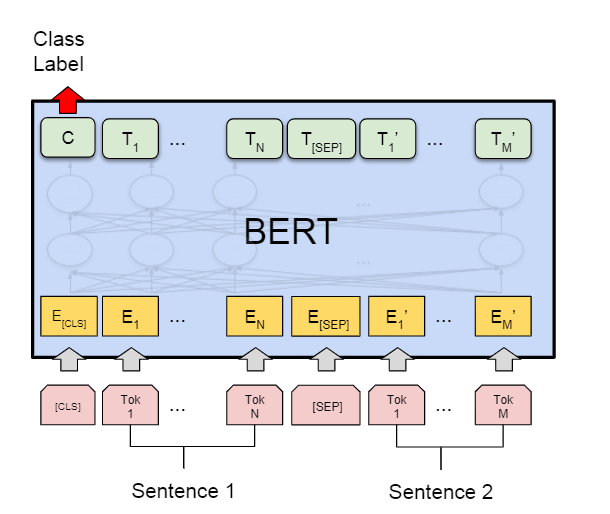
- 整体具体的组成和预训练阶段是一样的,只是从图中可以看出,句子的末尾不用加SEP
- 预测的时候拿CLS对应的输出位的embedding来做二分类。
单句子分类任务
情感分类一般就是这一类的任务,就是预测这个句子是否是正面情绪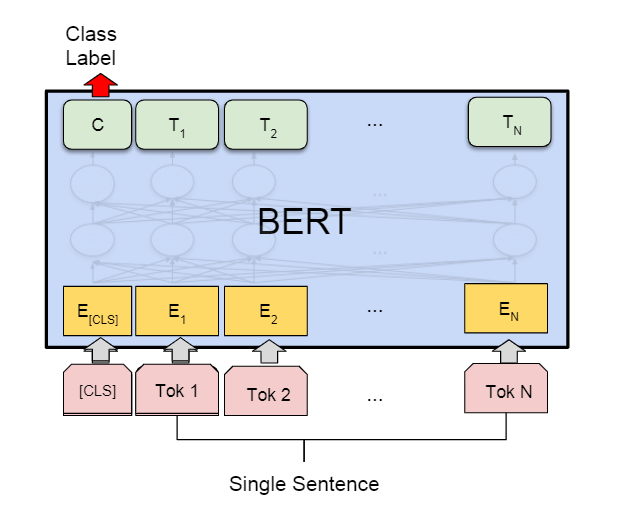
- 输入没啥说的,遵从之前的介绍;
- 输出上通用是利用CLS对应为的embedding作二分类。
命名实体识别
命名实体识别其实就是对每一个token做多分类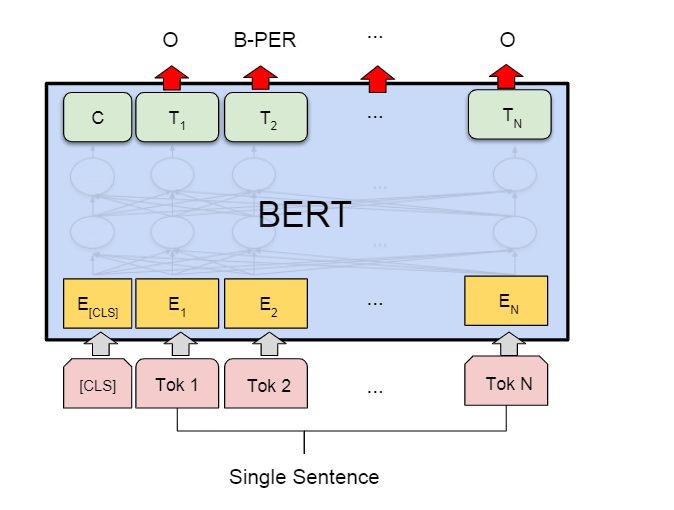
- 输入遵从之前的介绍
- 输出是对每一个token对应的输出的embedding做多分类预测。
关于Bert的介绍就到这了,也强烈建议看看初始论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)