【PyTorch】LeNet-5用于MNIST和CIFAR10
·
一、LeNet-5
LeNet-5 :一种经典的卷积神经网络(CNN)
LeNet-5 的总体结构:卷积层1+池化层1+卷积层2+池化层2+全连接层1+全连接层2+输出层
下面对各层参数进行详细介绍
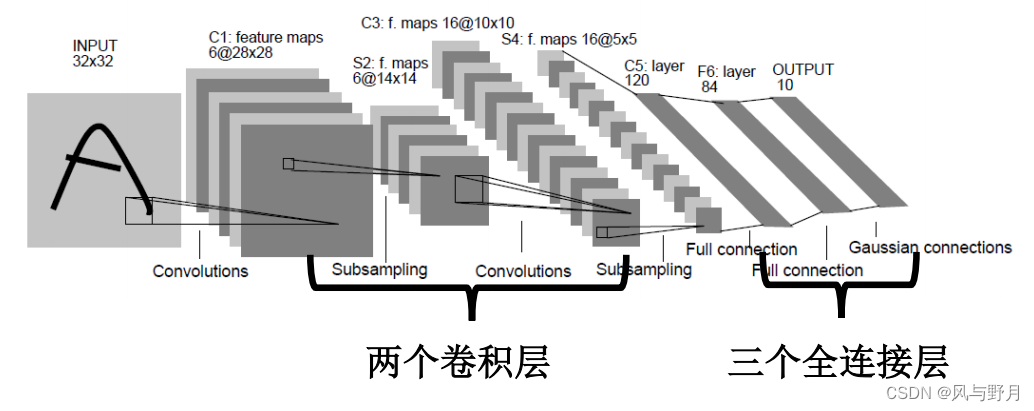
- 输入层:接受输入图像数据,通常为灰度图像(单通道),若为彩色图片为3个通道(R,G,B)。输入的图片需要是32x32像素,如果小于(比如28x28)则需要填充边缘。
- 卷积层 C1:对输入的每个通道的图,使用 6 个大小为 5x5 的卷积核进行特征提取,得到 6 个特征图。特征图的大小为28x28,即 6@28x28。(沿边长32的图连续取边长为5的图,32-5+1=28;6为图的个数)
- 池化层 S2:对C1得的每个特征图进行 2x2 的池化,将尺寸减小一半(6@14x14)
- 卷积层 C3:对S2得到的每个特征图,使用 16 个大小为 5x5 的卷积核进行特征提取,得到 16 个特征图。14-5+1=10,所以为 16@10x10
- 池化层 S4:对C3得到的每个特征图进行 2x2 的池化,将尺寸减小一半( 16@5x5)
- 全连接层 F5:将特征图展平成一维向量(所以得到的一维向量元素数为16x5x5=400),并连接到一个包含 120 个神经元的全连接层上。
- 全连接层 F6:包含 84 个神经元的全连接层。
- 输出层:根据任务需求,输出相应的分类结果,通常为 10 个类别(比如识别手写数字,类别即为0-9 的数字)。
需注意,以上模型参数是最初用于32x32的手写数字图像识别任务的参数,根据不同的任务可以有不同的设置。可调整参数如下:
- 卷积核大小(不一定是5x5)
- 卷积层的输入通道数和输出通道数(比如输入时,灰度图通道数为1,RGB通道数为3)
- 池化层的池化核大小(不一定是2x2)
- 全连接层的输入神经元数量和输出神经元数量(不一定是120和84)
二、数据集介绍
2.1 MNIST数据集
MNIST数据集是一个手写体数字数据集,其中训练集包含60000个样本,测试集包含10000个
样本,总共包含数字0-9十个类别,每张图像的分辨率为28×28。
2.2 CIFAR-10数据集
Cifar-10数据集由60000张32×32的RGB彩色图片构成,共10个类别;50000张训练,10000张
测试。
三、LeNet-5用于MNIST数据集实战代码详解
3.1 导入需要的模块
import torch
import torch.nn as nn #可提供基本的nn(神经网络)模型
import torch.nn.functional as F #提供神经网络常用函数
import torch.optim as optim #提供神经网络常用优化方法
from torchvision import datasets, transforms #用于计算机视觉任务的常用工具,比如用于加载、预处理、可视化图像数据的函数3.2 导入数据
分别导入MNIST的训练数据集和测试数据集。
torchvision.datasets 模块提供了常见的计算机视觉数据集,如 MNIST、CIFAR10等。torchvision.transforms 模块提供了数据预处理操作,如缩放、裁剪、翻转、归一化等。torch.utils.data.DataLoader 类用于创建数据加载器,方便地加载和迭代数据集。
BATCH_SIZE=512 # 批次大小
EPOCHS=20 # 总训练迭代次数
DEVICE='cpu' # 使用cpu
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)3.2 定义模型架构
- torch.nn.Conv2d (in_channels, out_channels, kernel_size, stride=1, padding=0) :用于定义二维卷积层,前3个为必选参数,分别为输入通道数,输出通道数(卷积核数),卷积核大小。除此之外,可定义stride(卷积操作的步长)和padding(边缘填充大小)
- torch.nn.MaxPool2d (kernel_size) :用于定义二维最大池化层。参数为池化窗口的大小,可以是一个整数(表示正方形窗口的边长)或一个元组(表示矩形窗口的高度和宽度)。
- torch.nn.Linear (in_features, out_features):用于定义全连接层,参数分别为输入特征向量长度和输出特征向量长度
class ConvNet(nn.Module):
def __init__(self):
#调用父类nn.Module的构造函数,初始化父类
super().__init__()
#通道数为1,卷积核数为6,卷积核大小5x5,每个边缘填充2个像素,从28x28填充为32x32
self.conv1 = nn.Conv2d(1, 6, 5, padding=2) # output:6@28x28(所以下一卷积层通道数为6)
self.pool1 = nn.MaxPool2d(2, 2) # 尺寸减半,28x28 -> 14x14
#通道数为6,卷积核数为6,卷积核大小5x5,input:14x14
self.conv2 = nn.Conv2d(6, 16, 5) # output:16@10x10
self.pool2 = nn.MaxPool2d(2, 2) # 尺寸减半,10x10 -> 5x5
self.fc1 = nn.Conv2d(16*5*5,120) #展平为一维 output:120
self.fc2 = nn.Linear(120,84) # output:120
self.fc3 = nn.Linear(84, 10) # output:10
def forward(self,x):
in_size = x.size(0)
out = self.conv1(x)
out = F.relu(out)
out = self.pool1(out)
out = self.conv2(out)
out = F.relu(out)
out = self.pool2(out)
out = out.view(-1, 16*5*5) #展平为1*400列向量
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(self.fc3(x),dim=1) #分类
return out3.3 训练函数
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader): #对于当前批次
# 将数据和目标标签移动到指定的设备(如GPU,CPU)上进行加速计算
data, target = data.to(device), target.to(device)
# 梯度清零。每个批次训练前将梯度清零,以避免之前批次的梯度对当前批次的参数更新产生影响
optimizer.zero_grad()
# 模型预测的输出值
output = model(data)
# 使用负对数似然损失函数计算损失
loss = F.nll_loss(output, target)
loss.backward()
# 优化器使用梯度信息来更新模型的参数
optimizer.step()
# 输出训练过程中平均loss和accuracy
if(batch_idx+1)%30 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))3.4 测试函数
def test(model, device, test_loader):
model.eval()
test_loss = 0 #初始化
correct = 0 #初始化
#测试过程不需要优化模型,即不需要计算梯度,关闭梯度计算节约计算资源
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# 加上此批的损失和,得到当前所有批次的损失和
test_loss += F.nll_loss(output, target, reduction='sum').item()
# 找到概率最大的下标,取出相应的值作为预测值
pred = output.max(1, keepdim=True)[1]
#比较数据的预测值是否与标签相等,相等则预测正确,加到正确的总数上
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset) #计算并输出测试集的平均Loss和Accuracy
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))3.5 训练模型
#使用的模型
model = ConvNet()
#使用的优化方法
optimizer = optim.Adam(model.parameters())
#迭代,每次完整地遍历过训练数据集后就进行测试
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)3.6 LeNet-5+MNIST总代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
BATCH_SIZE=512 # 批次大小
EPOCHS=20 # 总共训练批次
DEVICE='cpu'
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5, padding=2) # 28x28
self.pool1 = nn.MaxPool2d(2, 2) # 14x14
self.conv2 = nn.Conv2d(6, 16, 5) # 10x10
self.pool2 = nn.MaxPool2d(2, 2) # 5x5
self.conv3 = nn.Conv2d(16, 120, 5)
self.fc1 = nn.Linear(120,84)
self.fc2 = nn.Linear(84, 10)
def forward(self,x):
in_size = x.size(0)
out = self.conv1(x) #24
out = F.relu(out)
out = self.pool1(out) #12
out = self.conv2(out) #10
out = F.relu(out)
out = self.pool2(out)
out = self.conv3(out)
out = out.view(in_size,-1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out,dim=1)
return out
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if(batch_idx+1)%30 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # 将一批的损失相加
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == "__main__":
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
model = ConvNet()
optimizer = optim.Adam(model.parameters())
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)四、LeNet-5+CIFAR-10
总体与上面的相似,只是此数据集为RGB图,输入为3通道;且像素为32x32,不需要填充。对模型参数略作修改即可
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
BATCH_SIZE=512 # 批次大小
EPOCHS=20 # 总共训练批次
DEVICE='cpu'
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5, stride=1) # 输入为3@32*32,卷积核5*5,6个卷积核,输出为6@28x28
self.pool1 = nn.MaxPool2d(2, 2) # 过滤器2*2,6@14x14,所以下一层通道数为6
self.conv2 = nn.Conv2d(6, 16, 5,stride=1) # 6个通道,卷积核5*5,指定16个卷积核,14-6+1=10,输出16@10x10
self.pool2 = nn.MaxPool2d(2, 2) # 过滤器2*2,16@5x5
self.fc1 = nn.Linear(16*5*5, 120) #展平,为元素数16x5x5=400的一维向量,然后接120个神经元的全连接层fc1
self.fc2 = nn.Linear(120, 84) #120个神经元到84个神经元的全连接层
self.fc3 = nn.Linear(84,10) #输出层,也可以看成是84个神经元分类至10类的全连接层
def forward(self,x): #前向操作
x = F.relu(self.conv1(x)) # input(3,32,32) output(6,28,28)
x = self.pool1(x) # output(6, 14, 14)
x = F.relu(self.conv2(x)) # output(16, 10, 10)
x = self.pool2(x) # output(16, 5, 5)
x = x.view(-1, 16*5*5) # 展平,output(16*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = F.log_softmax(self.fc3(x),dim=1) # output(10)
return x
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if(batch_idx+1)%30 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # 将一批的损失相加
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == "__main__":
train_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])),
batch_size=BATCH_SIZE, shuffle=True)
model = ConvNet()
optimizer = optim.Adam(model.parameters())
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)五、测试结果
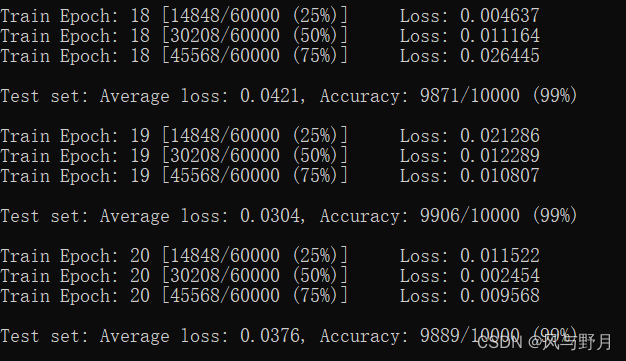
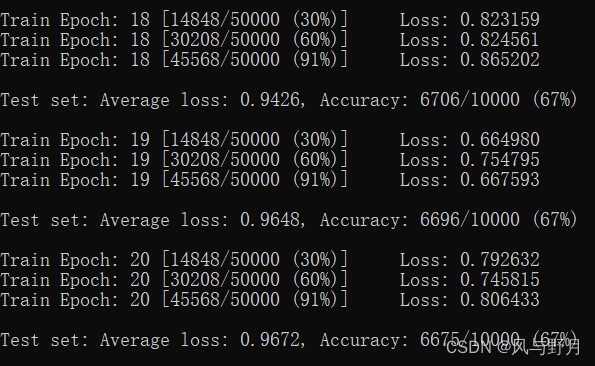
当前参数设置下,MNIST测试Accuracy可以稳定在99%,效果很好;CIFAR-10稳定在约67%。用LeNet-5测试CIFAR-100数据集,Accuracy仅达到34%左右。
可见,LeNet-5 的网络优势在于结构简洁、层次清晰,能够很好地解决较简单的问题,但对于大规模复杂数据集上的性能可能有限。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)