高斯分布基本概念及Python生成高斯分布数据集
高斯分布基本概念及Python生成高斯分布数据集正态分布的基本概念利用python随机产生多维高斯分布点正态分布的基本概念正态分布,又称高斯分布。其特征为:中间高、两边低,左、右对称。其主要性质如下:集中性:曲线的最高峰位于正中央,且位置为均数所在的位置。对称性:正态分布曲线以均数所在的位置为中心、左右对称,且曲线两端无线趋近于横轴。均匀变动性:正态分布曲线以均数所在的位置为中心均匀向...
高斯分布基本概念及Python生成高斯分布数据集
正态分布的基本概念
正态分布,又称高斯分布。其特征为:中间高、两边低,左、右对称。其主要性质如下:
- 集中性:曲线的最高峰位于正中央,且位置为均数所在的位置。
- 对称性:正态分布曲线以均数所在的位置为中心、左右对称,且曲线两端无线趋近于横轴。
- 均匀变动性:正态分布曲线以均数所在的位置为中心均匀向左右两侧下降。
- 面积恒等:曲线与横轴间的面积总等于1。
正态分布函数的公式如下:
f ( x ) = 1 ( 2 π ) σ e − ( x − μ ) 2 2 σ 2 \begin{aligned} &f(x)=\frac{1}{\sqrt{(2\pi)} \sigma }e^{-{\frac{(x-\mu)^2}{2\sigma^2}}} \end{aligned} f(x)=(2π)σ1e−2σ2(x−μ)2
其中,μ为均数,σ为标准差。μ决定了正态分布的位置,与μ越近,被取到的概率就越大,反之越小。σ描述的是正态分布的离散程度。σ越大,数据分布越分散曲线越扁平;反之,σ越小,数据分布越集中,曲线越陡峭。
利用python随机产生多维高斯分布点
np.random.multivariate_normal方法用于根据实际情况生成一个多元正态分布矩阵(即:从多元正态分布中抽取随机样本)。其在Python3中的定义如下:
def multivariate_normal(mean,cov,size=None,check_valid=None,tol=None)
其中,mean和cov为必须传入的参数,而size,check_valid以及tol为可选参数。
mean:1-D array_like, of length N,即:N维分布的均值,如:[1,1] 各维度的均值;
cov:2-D array_like, of shape (N, N),即:协方差矩阵,注意:协方差矩阵必须是对称的且需为半正定矩阵;
size:指定生成的正态分布矩阵的维度,int或int的元组,可选。(例如:若size=(1,1,2),则输出的矩阵的shape为:1×1×2×N(N为mean的长度))。
check_valid:该参数用于决定当cov(即:协方差矩阵)不是半正定矩阵时,程序的处理方式,它一共有三个值:warn,raise和ignore。
备注:
(1)当使用warn作为传入的参数时,如果cov不是半正定的程序会输出警告但仍旧会得到结果;
(2)当使用raise作为传入的参数时,如果cov不是半正定的程序会报错且不会计算出结果;
(3)当使用ignore时忽略这个问题即无论cov是否为半正定的都会计算出结果。
tol:检查协方差矩阵奇异值时的公差,为float类型。
范例如下:
#例1:
#生成一个形状为2X2X2的正态分布矩阵
import numpy as np
mean=(1,2)
cov=[[1,0],[0,1]]
x=np.random.multivariate_normal(mean,cov,(2,2),'raise')
print(x)
>>>
[[[-0.02035963 2.79362756]
[ 1.52210253 1.25649869]]
[[ 1.21987399 2.5292418 ]
[ 1.67013603 2.87895882]]]
#例2
#依据均值和协方差生成数据,并进行后续验证运算
import numpy as np
A1_mean=[1,1]
A1_cov=[[2.0,0.99],[1,1]]
A1=np.random.multivariate_normal(A1_mean,A1_cov,5) #依据指定的均值和协方差生成数据,size=5
print(A1)
>>>
array([[ 0.71297594, 2.47296282],
[-1.15079462, 0.26879572],
[ 1.24953037, 1.06155655],
[ 3.31932598, 2.63042057],
[ 0.52508056, 2.01427131]])
#进行后续的验证运算
np.mean(A1) #(1)求全体数的均值
>>>
1.310412520483211
np.mean(A1,axis=0) #(2)按列求均值(每列为一组)
>>>
array([0.93122365, 1.68960139])
np.mean(A1,axis=1) #(3)按行求均值(每行为一组)
>>>
array([ 1.59296938, -0.44099945, 1.15554346, 2.97487328, 1.26967593])
np.cov(A1.T) #(4)转置后求协方差(和预计的差不多)
>>>
array([[2.58793407, 1.17554392],
[1.17554392, 1.00433387]])
np.cov(A1).shape #(5)没有转置,求协方差的大小,即:5*5的矩阵
>>>
np.cov(A1) #(6)求协方差
>>>
array([[ 1.5487769 , 1.24923019, -0.16541573, -0.60623224, 1.31047809],
[ 1.24923019, 1.00761837, -0.13342291, -0.48898173, 1.0570204 ],
[-0.16541573, -0.13342291, 0.01766708, 0.06474809, -0.13996444],
[-0.60623224, -0.48898173, 0.06474809, 0.23729533, -0.51295578],
[ 1.31047809, 1.0570204 , -0.13996444, -0.51295578, 1.10884454]])
#例3
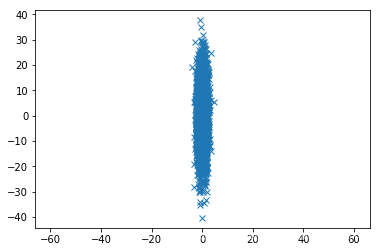
mean=[0,0]
cov=[[1,0],[0,100]]
import matplotlib.pyplot as plt
x, y = np.random.multivariate_normal(mean, cov, 5000).T #必须转置
plt.plot(x, y, 'x') #点标记为“x”
plt.axis('equal') #设置坐标轴为以(0,0)对称
plt.show() #结果见下图
#例4
mean=(1,2)
cov=[[1,0],[0,1]]
x=np.random.multivariate_normal(mean,cov,(3,4))
x.shape
>>>
(3, 4, 2)
#The following is probably true, given that 0.6 is roughly twice the standard deviation:
list((x[0,0,:]-mean)<0.6)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)