Pyspark交互式编程
通过本次Pyspark交互式编程实验,我掌握了Pyspark的基本概念和API,并学会了如何使用Pyspark进行大数据处理和机器学习任务。同时,我也深刻理解了分布式计算的重要性和优势,以及如何解决在单机模式下处理大数据集时可能遇到的问题。
·
请点击这里访问百度云盘。(提取码是qdm4)
请下载 “数据集”chapter4-data01.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
|
Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure,60 Jim,DataBase,90 Jim,Algorithm,60 Jim,DataStructure,80 …… |
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
(1)该系总共有多少学生;
line = sc.textFile("file:///opt/module/spark-3.0.3-bin-without-hadoop/mycode/chapter4-data01.txt")
rdd = line.map(lambda x:x.split(",")).map(lambda x:x[0])
sum = rdd.distinct()
sum.count()
(2)该系共开设了多少门课程;
line = sc.textFile("file:///opt/module/spark-3.0.3-bin-without-hadoop/mycode/chapter4-data01.txt")
rdd1 = line.map(lambda x:x.split(",")).map(lambda x:x[1])
sum1 = rdd1.distinct()
sum1.count()
(3)Tom同学的总成绩平均分是多少;
line = sc.textFile("file:///opt/module/spark-3.0.3-bin-without-hadoop/mycode/chapter4-data01.txt")
rdd2 = line.map(lambda x:x.split(",")).filter(lambda x:x[0]=="Tom")
rdd2.foreach(print)
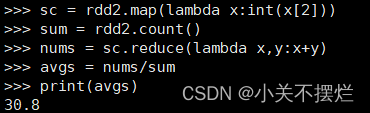
sc = rdd2.map(lambda x:int(x[2]))
sum = rdd2.count()
nums = sc.reduce(lambda x,y:x+y)
avgs = nums/sum
print(avgs)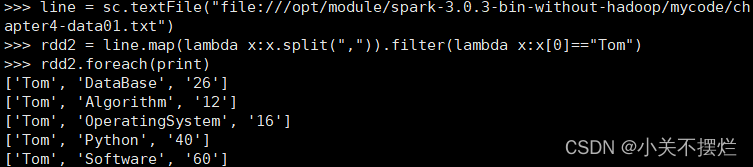
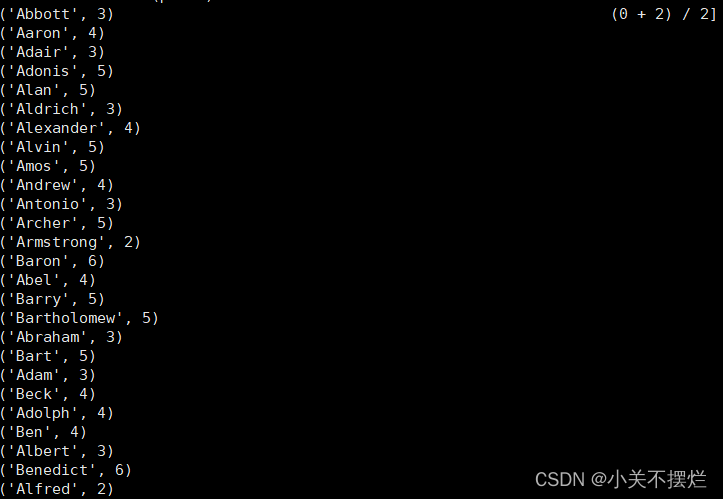
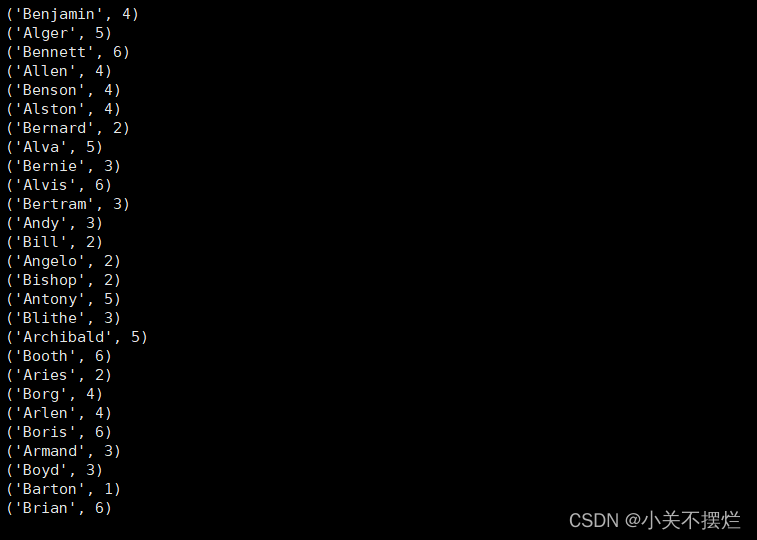
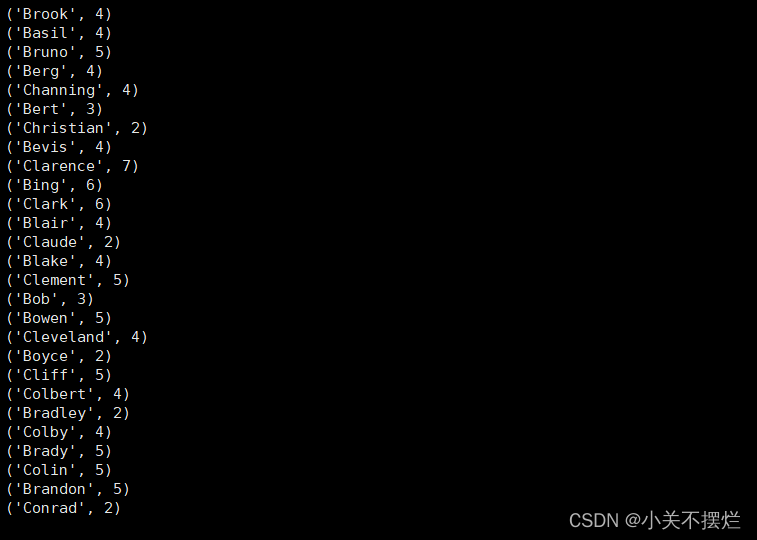
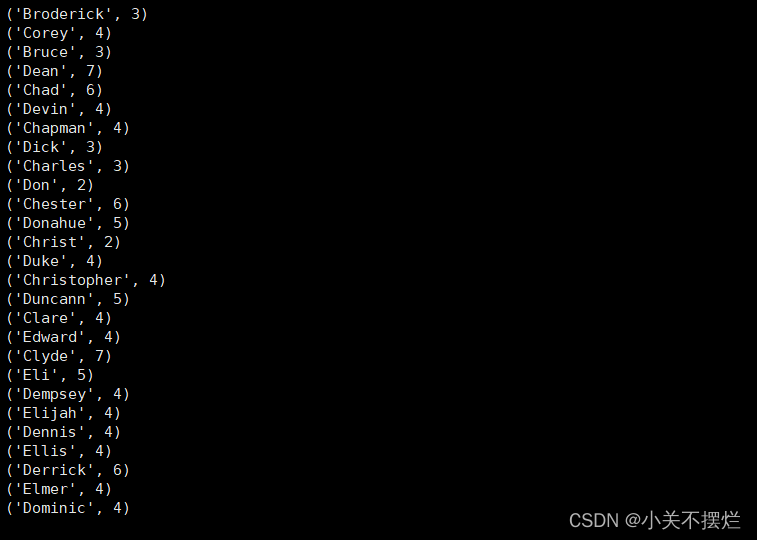
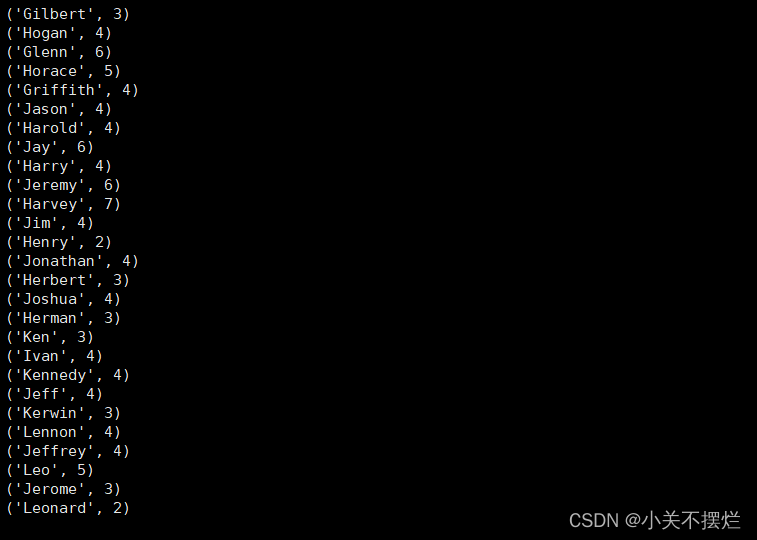
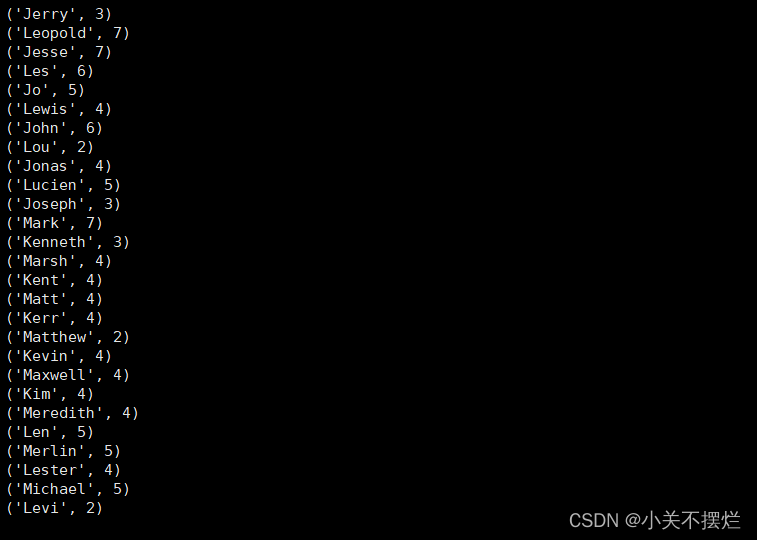
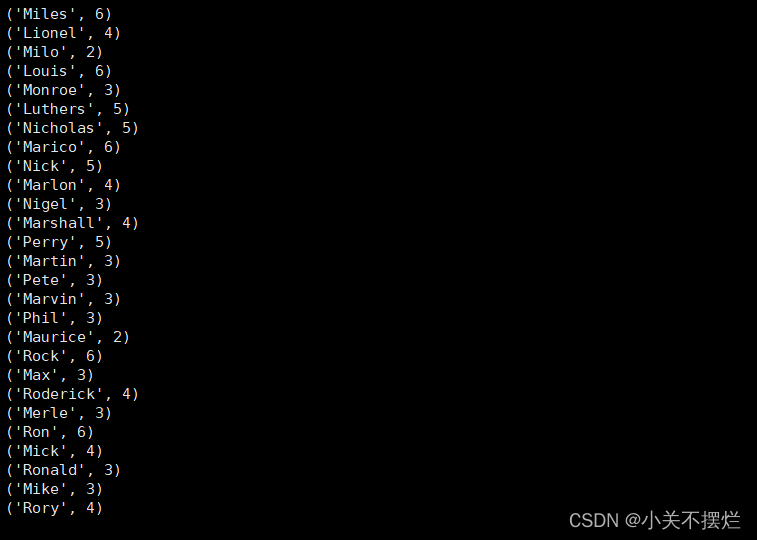
(4)求每名同学的选修的课程门数;
line = sc.textFile("file:///opt/module/spark-3.0.3-bin-without-hadoop/mycode/chapter4-data01.txt")
rdd3 = line.map(lambda x:x.split(",")).map(lambda x:(x[0],1))
sums2 = rdd3.reduceByKey(lambda x,y:x+y)
sums2.foreach(print)

(5)该系DataBase课程共有多少人选修;
line = sc.textFile("file:///opt/module/spark-3.0.3-bin-without-hadoop/mycode/chapter4-data01.txt")
rdd5 = line.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")
rdd5.count()
(6)各门课程的平均分是多少;
line = sc.textFile("file:///opt/module/spark-3.0.3-bin-without-hadoop/mycode/chapter4-data01.txt")
rdd6 = line.map(lambda x:x.split(",")).map(lambda x:(x[1],(int(x[2]),1)))
sum6 = rdd6.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
avg2 = sum6.map(lambda x:(x[0],round(x[1][0]/x[1][1],2)))
avg2.foreach(print)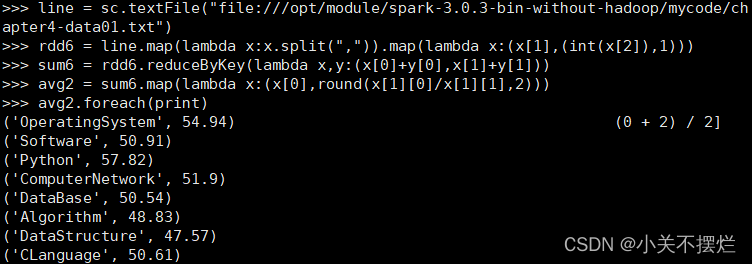
(7)使用累加器计算共有多少人选了DataBase这门课。
line = sc.textFile("file:///opt/module/spark-3.0.3-bin-without-hadoop/mycode/chapter4-data01.txt")
rdd7 = line.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")
sum7=sc.accumulator(0)
rdd7.foreach(lambda x:sum7.add(1))
sum7.value
总结
- 通过本次Pyspark交互式编程实验,我掌握了Pyspark的基本概念和API,并学会了如何使用Pyspark进行大数据处理和机器学习任务。同时,我也深刻理解了分布式计算的重要性和优势,以及如何解决在单机模式下处理大数据集时可能遇到的问题。
- 编程中也遇到很多问题,如:使用rdd.foreach(print)报错NameError、使用rdd.collect()时,会出现不正常的u字母,比如[(u'DataStructure', 5), (u'Music', 1), (u'Algorithm', 5), (u'DataBase', 5)],原因是因为pyspark里自带一个Python2版本,所以可以通升级pyspark自带的python版本来解决。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)