第TR1周: Transformer 算法详解
Transformer 网络架构由 Ashish Vaswani 等人在 Attention Is All You Need 一文中提出,并用于机器翻译任务,和以往网络架构有所区别的是,该网络架构中,编码器和解码器没有采用 RNN 或 CNN 等网络架构,而是采用完全依赖注意力机制的架构。网络架构如下所示:Transformer改进了RNN被人诟病的训练慢的特点,利用self-attention可
本人往期文章可查阅: 深度学习总结
1. 介绍
Transformer 网络架构由 Ashish Vaswani 等人在 Attention Is All You Need 一文中提出,并用于机器翻译任务,和以往网络架构有所区别的是,该网络架构中,编码器和解码器没有采用 RNN 或 CNN 等网络架构,而是采用完全依赖注意力机制的架构。网络架构如下所示:
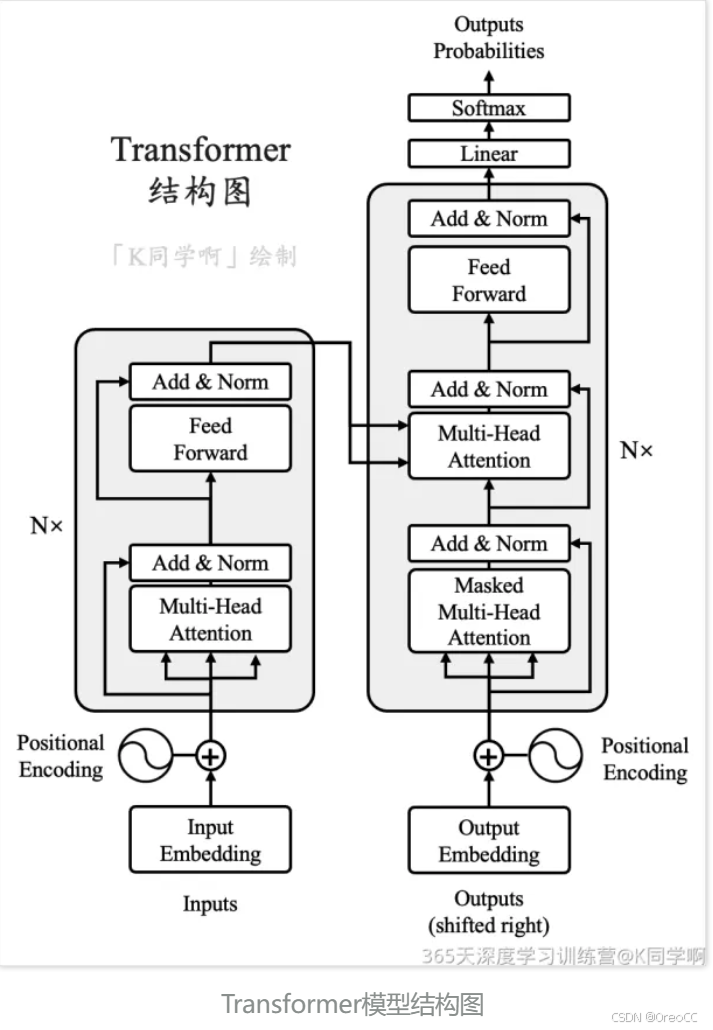
Transformer改进了RNN被人诟病的训练慢的特点,利用self-attention可以实现快速并行。下面的章节会详细介绍Transformer的各个组成部分。
2. Transformer直观认识
Transformer 主要由 encoder 和 decoder 两部分组成。在Transformer 的论文中,encoder和decoder均由6个encoder layer和decoder layer组成,通常我们称之为encoder block。
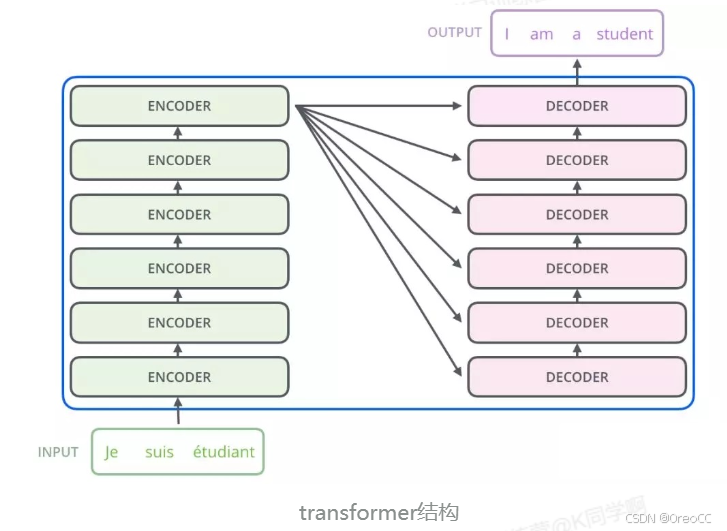
每一个encoder和decoder的内部简版结构如下图:
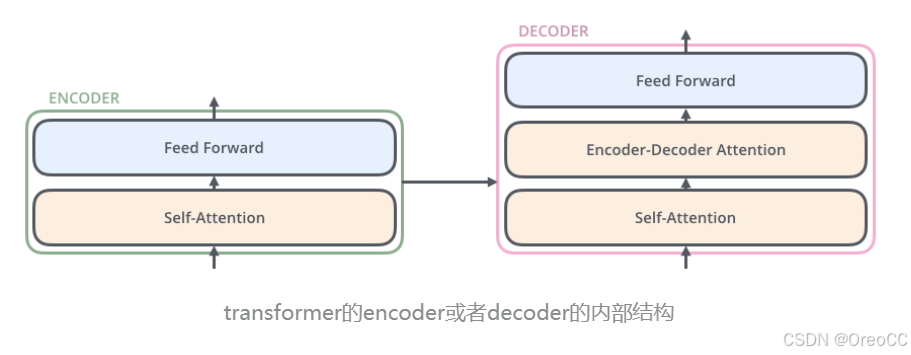
对于encoder,包含两层,一个self-attention 层和一个前馈神经网络,self-attention 能帮助当前节点不仅仅只关注当前的词,还能获取到上下文的语义。
decoder 也包含 encoder 提到的两层网络,但是在这两层中间还有一层 attention 层,帮助当前节点获取到当前需要关注的重点内容。
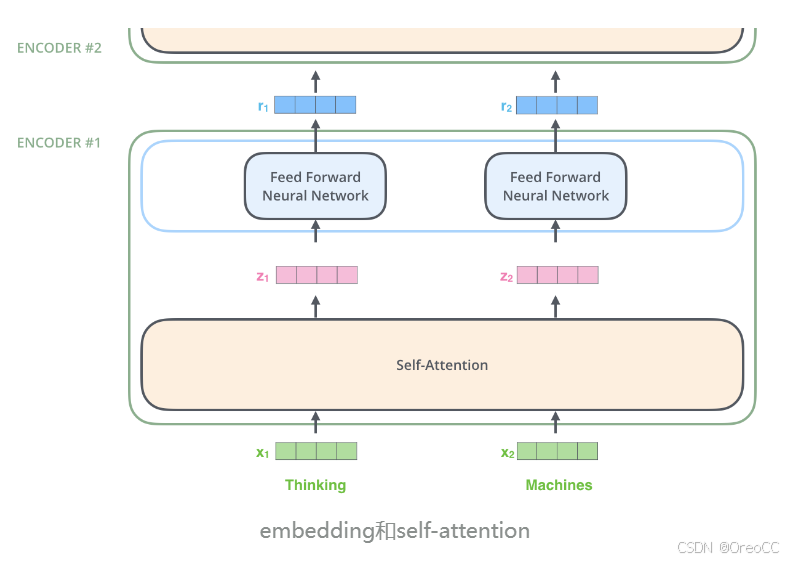
首先,模型需要对输入的数据进行一个embedding操作,embedding结束之后,输入到encoder层,self-attention处理完数据后把数据送给前馈神经网络,前馈神经网络的计算可以并行,得到输出会输入到下一个encoder。
3. Transformer的结构
Transformer 的结构解析出来如下图所示,包括 Input Embedding,Position Embedding,Encoder,Decoder。
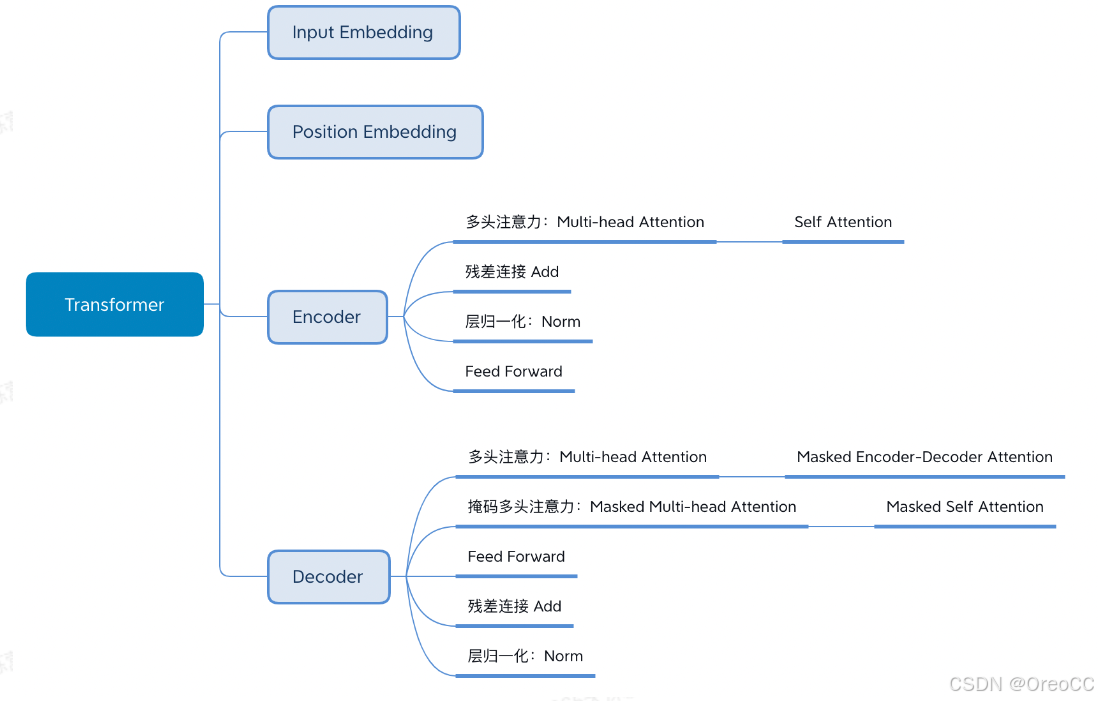
3.1.Embedding
字向量与位置编码的公式表示如下:
3.1.1.Input Embedding
可以将Input Embedding看作是一个 lookup table,对于每个word,进行 word embedding 就相当于一个lookup操作,查出一个对应结果。
3.1.2.Position Encoding
Transformer模型中还缺少一种解释输入序列中单词顺序的方法。为了处理这个问题,transformer给encoder层和decoder层的输入添加了一个额外的向量Position Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,论文中的计算方法如下:
其中pos是指当前词在句子中的位置,是指向量中每个值的
,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
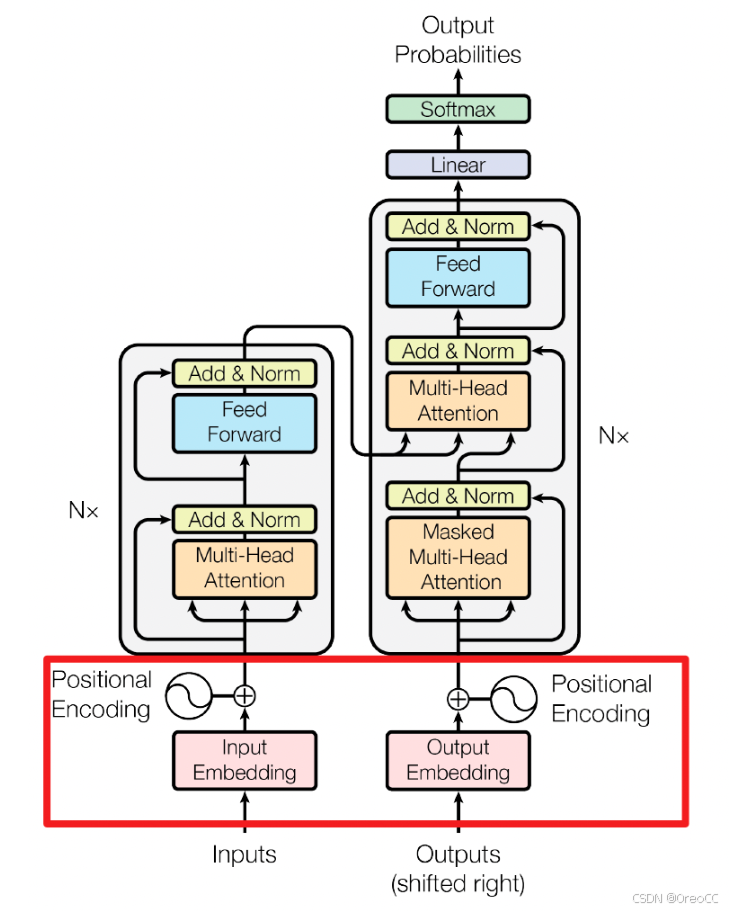
3.2.Encoder
用公式把一个Transformer Encoder block的计算过程整理一下
- 注意力机制
- 注意力机制 残差连接与 Layer Normalization
- FeedForward,其实就是两层线性映射并用激活函数激活,比如说ReLU
- FeedForward 残差连接与 Layer Normalization
其中:
3.2.1.自注意力机制
下节介绍
3.2.2.Multi-head Attention
下节介绍
3.2.3.残差连接
经过 self-attention 加权之后输出,也就是Attention(Q,K,V),然后把他们加起来做残差连接
除了 self-attention 这里做残差连接外,feed forward那个地方也需要残差连接,公式类似:
3.2.4.Layer Normalization
Layer Normalization 的作用是把神经网络中隐藏层归一为标准正态分布,也就是独立同分布,以起到加快训练速度,加速收敛的作用
其中:
LayerNorm的详细操作如下:
上式以矩阵为单位求均值:
上式以矩阵为单位求方差:
然后用每一列的每一个元素减去这列的均值,再除以这列的标准差,从而得到归一化后的数值,加 是为了防止分母为0。此处一般初始化
为全1,而
为全0。
3.2.5.Feed Forward
将Multi-Head Attention得到的向量再投影到一个更大的空间(论文里将空间放大了4倍),在那个大空间里可以更方便地提取需要的信息(使用Relu激活函数),最后再投影回token向量原来的空间
借鉴SVM来理解:SVM对于比较复杂的问题通过将其特征投影到更高维的空间使得问题简单到一个超平面就能解决。这里token向量里的信息通过Feed Forward Layer被投影到更高维的空间,在高维空间里向量的各类信息彼此之间更容易区别。
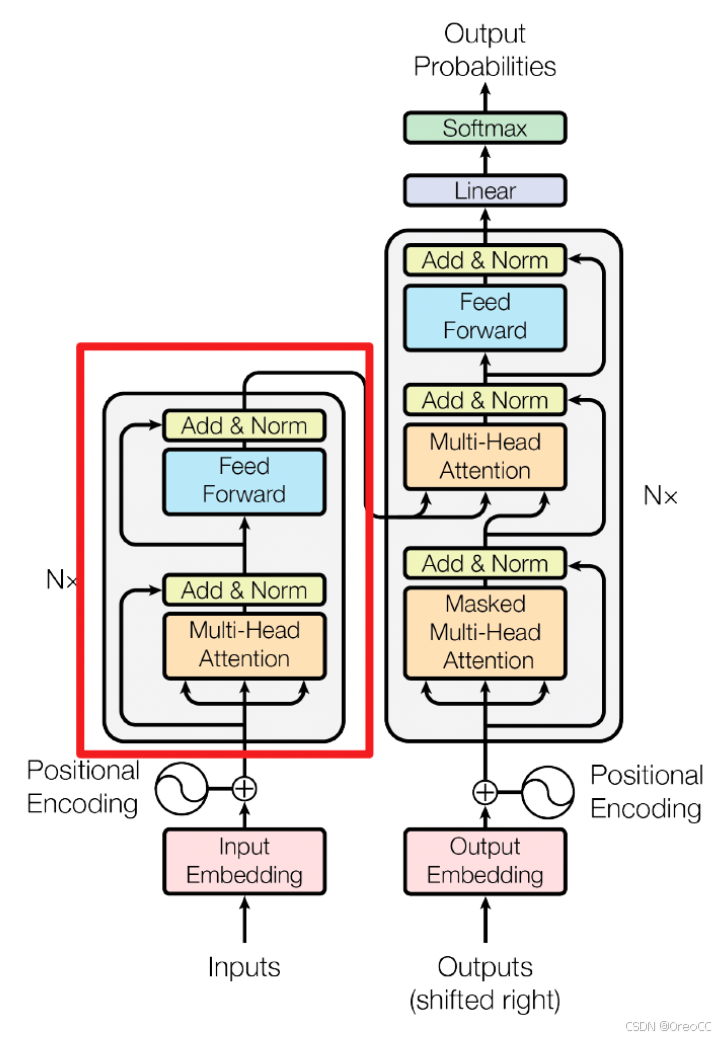
3.3.Decoder
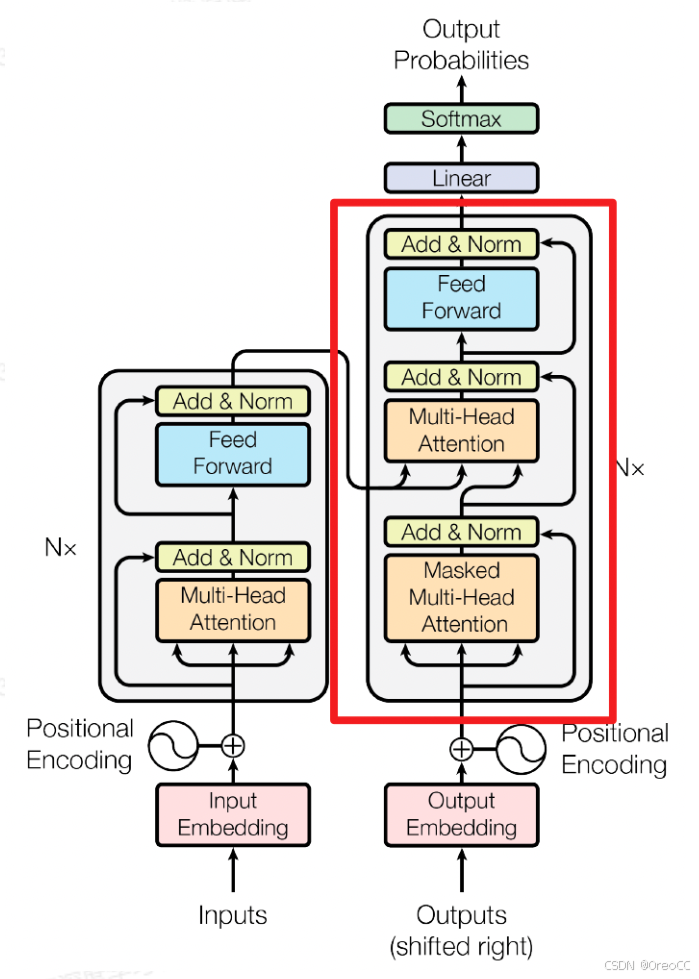
和Encoder一样,上面三个部分的每一个部分,都有一个残差连接,后接一个Layer Normalization。Decoder的中间不见并不复杂,大部分在前面Encoder里我们已经介绍过了,但是Decoder由于其特殊的功能,因此在训练时会涉及到一些细节,下面会介绍Decoder的 Masked Multi-Head Self-Attention 和 Encoder-Decoder Attention 两部分,其结构图如下图所示
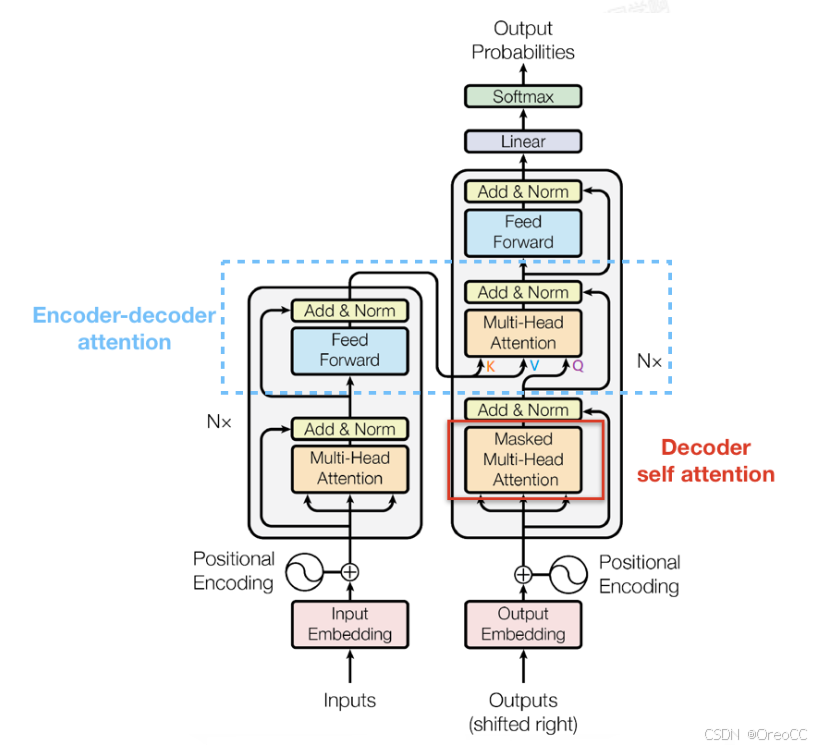
3.3.1.Masked Multi-Head Self-Attention
传统Seq2Seq中Decoder 使用的是RNN模型,因此在训练过程中输入 t 时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当 t 时刻运算结束了,才能看到 t+1 时刻的词。而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 都暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask。
Mask 非常简单,首先生成一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 Scaled Scores 相加即可,之后再做 softmax,就能将 -inf 变为0,得到的这个矩阵即为每个字之间的权重。
3.3.2. Encoder-Decoder Attention
其实这一部分的计算流程和前面 Masked Self-Attention 很相似,结构也一模一样,唯一不同的是这里的 K,V 为Encoder 的输出,Q 为Decoder 中 Masked Self-Attention 的输出。
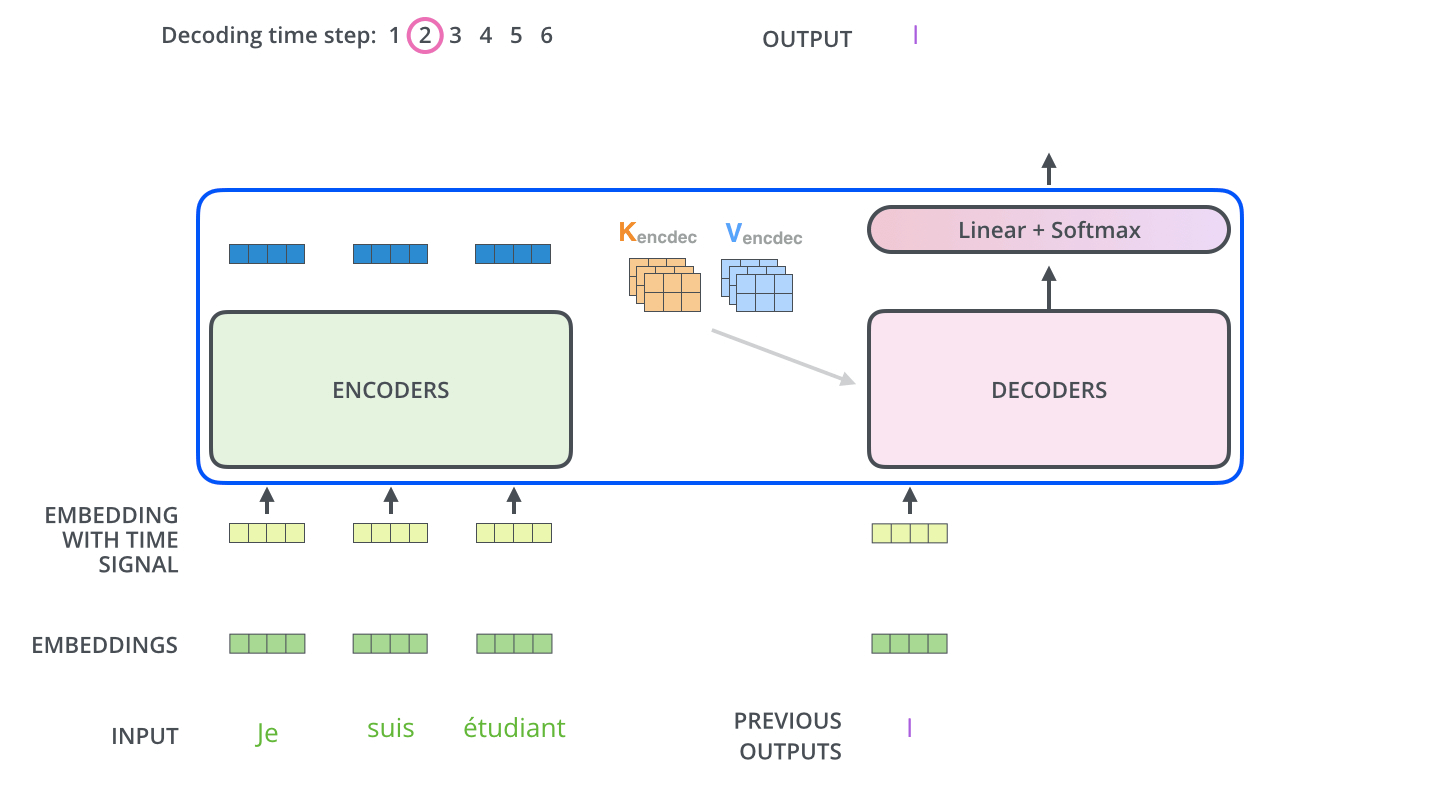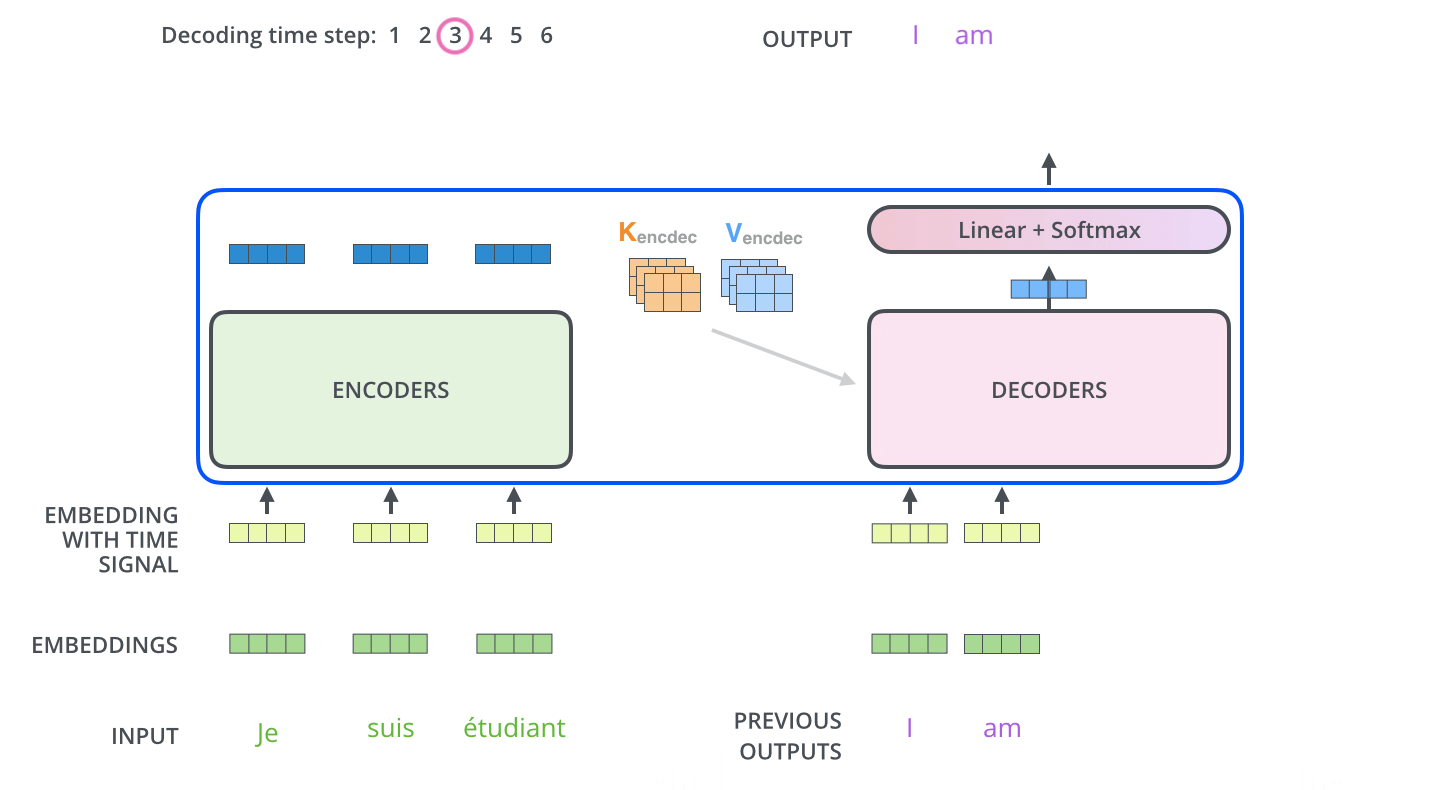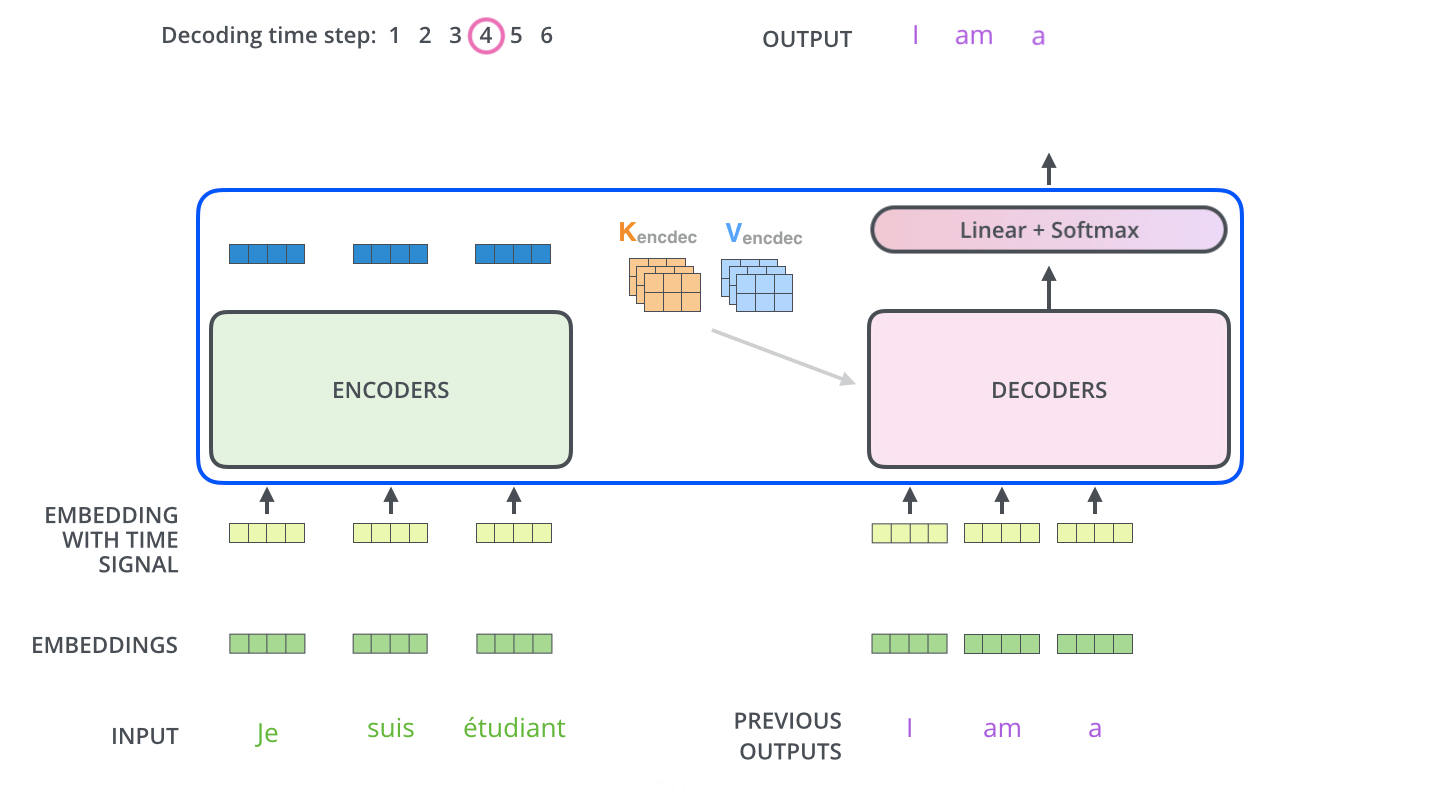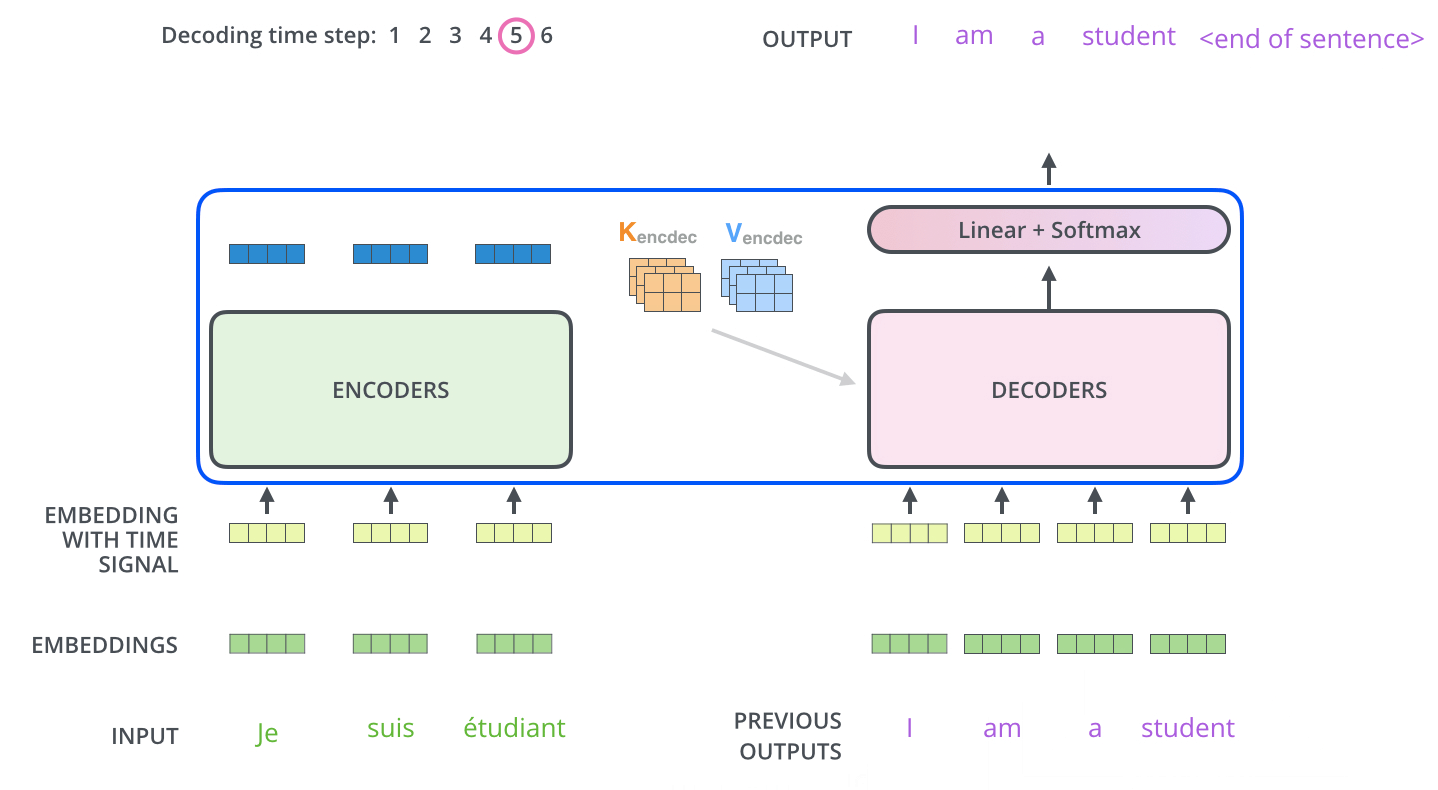
3.3.3.Decoder的编码
下面展示了Decoder的解码过程,Decoder中的字符预测完之后,会当成输入预测下一个字符,直到遇见终止符号为止。
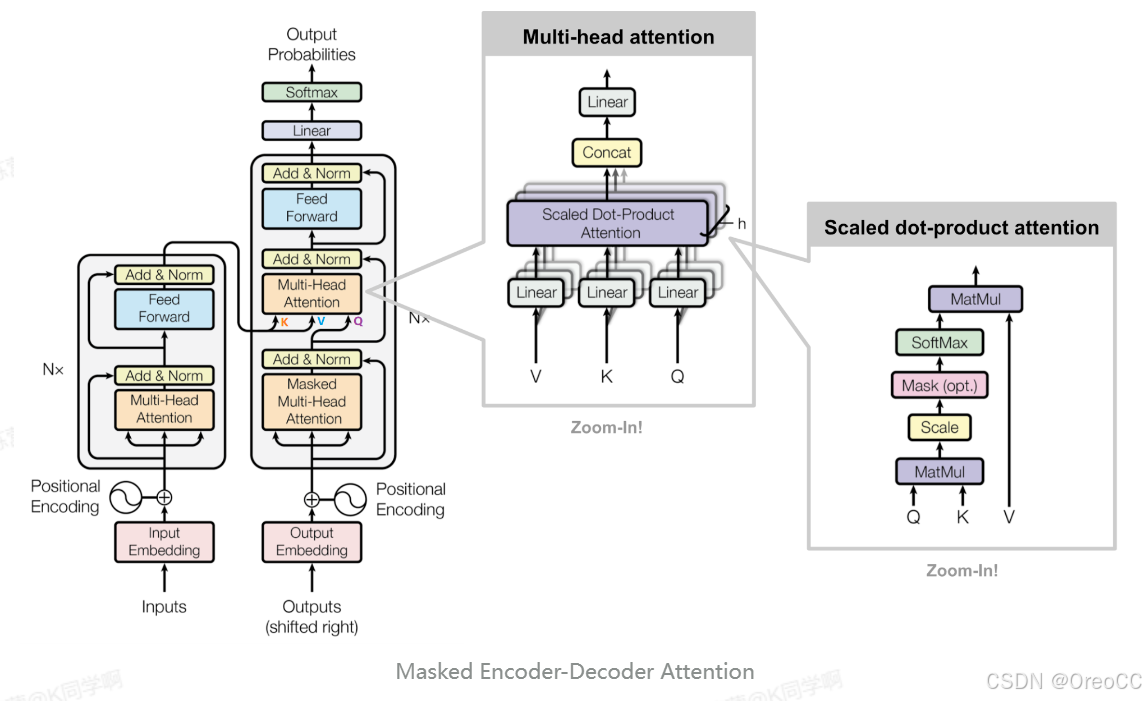
3.3.4.Transformer 的最后一层和 Softmax
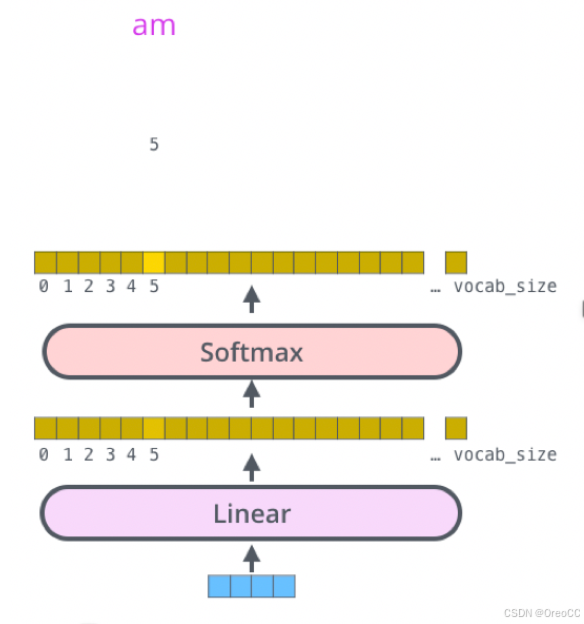
线性层是一个简单的全连接的神经网络,它将解码器堆栈生成的向量投影到一个更大的向量,称为logits向量。如图linear的输出
softmax层将这些分数转换为概率(全部为正值,总和为1.0)。选择概率最高的单元,并生成与其关联的单词作为此时间步的输出。如图softmax的输出。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)